打印sklearn生成的决策树/GBDT各node方法
打印sklearn生成的DT/GBDT 各node
- 1.生成决策树各node实例
-
- 1.1 sklearn.tree.DecisionTreeClassifier调用例子
- 1.2 决策树打印成文本方法
-
- 1.2.1 方法一:控制台中使用命令打印(本人使用的是spyder)
- 1.2.2 方法二:修改sklearn.tree自带子函数打印结果
- 2.生成GBDT各node实例
-
- 2.1 sklearn.ensemble.GradientBoostingRegressor调用例子
- 2.2 将GBDT打印成文本方法
-
- 2.2.1 方法一:控制台中使用命令打印
- 2.2.2 方法二:修改sklearn.tree自带子函数打印结果
1.生成决策树各node实例
1.1 sklearn.tree.DecisionTreeClassifier调用例子
假设对以下数据通过决策树进行分类:
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
import numpy as np
X=np.array( [[i,j] for i in range(1,5) for j in range(1,5)])
y=np.array( [1,0,0,0,1,0,0,0,1,0,1,1,1,0,1,1])
clf = DecisionTreeClassifier()
clsf=clf.fit(X,y)
tree.plot_tree(clsf)
生成的决策树如下:
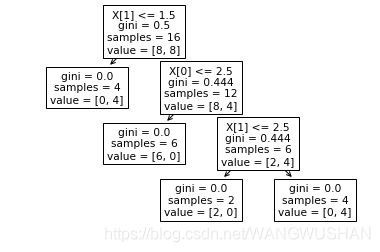
但是如何引用其文本格式(如字符串、字典形式)呢?
1.2 决策树打印成文本方法
1.2.1 方法一:控制台中使用命令打印(本人使用的是spyder)
tree.plot_tree(clsf)
输出:
[Text(113.933,196.385,'X[1] <= 1.5\ngini = 0.5\nsamples = 16\nvalue = [8, 8]'),
Text(56.9667,140.275,'gini = 0.0\nsamples = 4\nvalue = [0, 4]'),
Text(170.9,140.275,'X[0] <= 2.5\ngini = 0.444\nsamples = 12\nvalue = [8, 4]'),
Text(113.933,84.165,'gini = 0.0\nsamples = 6\nvalue = [6, 0]'),
Text(227.867,84.165,'X[1] <= 2.5\ngini = 0.444\nsamples = 6\nvalue = [2, 4]'),
Text(170.9,28.055,'gini = 0.0\nsamples = 2\nvalue = [2, 0]'),
Text(284.833,28.055,'gini = 0.0\nsamples = 4\nvalue = [0, 4]')]
1.2.2 方法二:修改sklearn.tree自带子函数打印结果
from sklearn.tree._export import _BaseTreeExporter
btree=_BaseTreeExporter(max_depth=None, feature_names=None,
class_names=None, label='all', filled=False,
impurity=True, node_ids=False,
proportion=False, rotate=False, rounded=False,
precision=3, fontsize=None)
#nodes= clsf.get_n_leaves()*2-1
# clsf.get_n_leaves():获取决策树的叶子节点个数,总的nodes数正好是其2倍再减1
#或者使用:
nodes= clsf.tree_.node_count
for i in range(nodes):
print(btree.node_to_str(clsf.tree_,i,'gini'))
此时会产生如下错误:
AttributeError: '_BaseTreeExporter' object has no attribute 'characters'
这是因为C:\Python37\Lib\site-packages\sklearn\tree_export.py 文件
class _BaseTreeExporter 的子函数node_to_str中:
characters = self.characters
self.characters没有定义。
将这一句替换为:
characters = ['#', '[', ']', '<=', '\n', '', '']
就可以正常输出了。
结果为:
X[1] <= 1.5
gini = 0.5
samples = 16
value = [8, 8]
gini = 0.0
samples = 4
value = [0, 4]
X[0] <= 2.5
gini = 0.444
samples = 12
value = [8, 4]
gini = 0.0
samples = 6
value = [6, 0]
X[1] <= 2.5
gini = 0.444
samples = 6
value = [2, 4]
gini = 0.0
samples = 2
value = [2, 0]
gini = 0.0
samples = 4
value = [0, 4]
获取文本str格式后,就可以将其转成dic等格式,进行下一步处理了。
2.生成GBDT各node实例
以GradientBoostingRegressor为例。
2.1 sklearn.ensemble.GradientBoostingRegressor调用例子
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor
from sklearn import tree
X=np.array([[5,20],[7,30],[21,70],[30,60]])
y=np.array([[1.1],[1.3],[1.7],[1.8]]).ravel()
clf = GradientBoostingRegressor(n_estimators=3, learning_rate=1.0,
max_depth=1, random_state=0).fit(X, y)
n_estimators=clf.n_estimators_
生成三棵决策树,在控制台分别执行:
tree.plot_tree(clf.estimators_[0][0])
tree.plot_tree(clf.estimators_[1][0])
tree.plot_tree(clf.estimators_[2][0])
在绘图区进行显示。
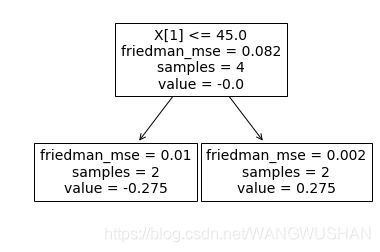
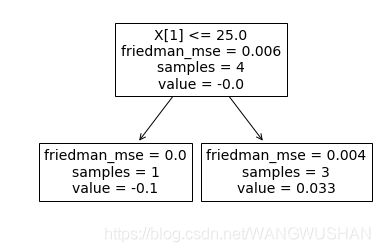
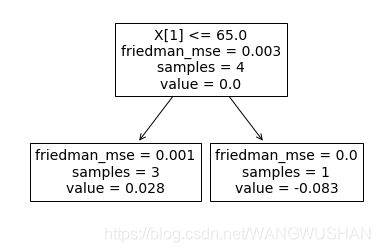
2.2 将GBDT打印成文本方法
与普通决策树类似。
2.2.1 方法一:控制台中使用命令打印
tree.plot_tree(clf.estimators_[0][0])
#Out:
[Text(170.9,168.33,'X[1] <= 45.0\nfriedman_mse = 0.082\nsamples = 4\nvalue = -0.0'),
Text(85.45,56.11,'friedman_mse = 0.01\nsamples = 2\nvalue = -0.275'),
Text(256.35,56.11,'friedman_mse = 0.002\nsamples = 2\nvalue = 0.275')]
tree.plot_tree(clf.estimators_[1][0])
#Out:
[Text(170.9,168.33,'X[1] <= 25.0\nfriedman_mse = 0.006\nsamples = 4\nvalue = -0.0'),
Text(85.45,56.11,'friedman_mse = 0.0\nsamples = 1\nvalue = -0.1'),
Text(256.35,56.11,'friedman_mse = 0.004\nsamples = 3\nvalue = 0.033')]
tree.plot_tree(clf.estimators_[2][0])
#Out:
[Text(170.9,168.33,'X[1] <= 65.0\nfriedman_mse = 0.003\nsamples = 4\nvalue = 0.0'),
Text(85.45,56.11,'friedman_mse = 0.001\nsamples = 3\nvalue = 0.028'),
Text(256.35,56.11,'friedman_mse = 0.0\nsamples = 1\nvalue = -0.083')]
2.2.2 方法二:修改sklearn.tree自带子函数打印结果
与1.2.2大体相同。
from sklearn.tree._export import _BaseTreeExporter
btree=_BaseTreeExporter()
n_estimators=clf.n_estimators_
nodes= clf.estimators_[0][0].tree_.node_count
for i in range(n_estimators):
for j in range(nodes):
print(btree.node_to_str(clf.estimators_[i][0].tree_,j,'friedman_mse'))
print('\n')
生成结果:
X[1] <= 45.0
friedman_mse = 0.082
samples = 4
value = -0.0
friedman_mse = 0.01
samples = 2
value = -0.275
friedman_mse = 0.002
samples = 2
value = 0.275
X[1] <= 25.0
friedman_mse = 0.006
samples = 4
value = -0.0
friedman_mse = 0.0
samples = 1
value = -0.1
friedman_mse = 0.004
samples = 3
value = 0.033
X[1] <= 65.0
friedman_mse = 0.003
samples = 4
value = 0.0
friedman_mse = 0.001
samples = 3
value = 0.028
friedman_mse = 0.0
samples = 1
value = -0.083