基于无监督对抗学习的时间序列异常检测
1. 文章信息
文章题为《基于无监督对抗学习的时间序列异常检测》,是一篇发表在南京大学学报(自然科学)上的关于网络异常检测的文章。
2. 摘要
时间序列异常检测是类别不均衡问题,异常现象少有发生,所以获取异常标签的成本高昂,因此基于无监督学习的时间序列异常检测方法更具有实用价值。然而,现有的时间序列异常检测方法存在三个缺陷:
1. 难以对复杂的时间序列进行建模:现实中除了简单的周期性时间序列,还有大量的复杂时间序列数据,存在复杂的数据分布和非高斯噪声,导致许多建模能力不足的无监督模型检测异常的效果不佳。
2. 缺乏合理的缺失值处理机制:在时间序列数据中常有数据缺失的现象,以往的做法通常是使用线性插值等简单的插值方法补全数据再用于无监督模型的训练。然而,使用简单插值方法补全的数据用于复杂的无监督模型建模,会对模型建模正常数据分布产生负面的影响。
3. 无法利用先验知识:实际场景中有时会获得少量的有标签数据,然而现有的模型大多忽视这部分数据,例如少量的有标签异常。
为了解决以上问题,提出一种基于生成对抗神经网络和自编码器的无监督时间序列异常检测模型SALAD(Stochastic Adversarial Learned Anomaly Detection)。主要贡献如下:
1. 提出时间序列异常检测模型SALAD,结合自编码器和生成对抗神经网络可以有效地对复杂的时间序列数据进行建模。在自编码器中,隐变量往往表示原始空间在隐空间中的随机变量(Stochastic)表示,通过使用对抗网络对隐变量施加约束,能更加紧凑地在隐空间中表示原始空间的数据分布。
2. 提出缺失值处理方法InT(Imputation in Training),能够随着模型训练的进行使用模型不断增强的生成能力对缺失值进行填充,使生成的数据更接近原始数据分布。
3. 提出对比重构损失,使SALAD能充分利用先验知识来提升异常检测的性能。
4. 在真实数据集上进行了大量实验,结果表明,SALAD的检测效果比其他基线方法更好。
3. 文章结构
1.首先讲解了框架的基本思路及总体框架,分为三个部分:数据预处理、模型训练、异常检测。
2、详细介绍了模型的结构、目标损失函数的构建、缺失值的处理方法,以及异常检测的方法。
3、介绍了数据集的特点,进行了实验,于一些现有的模型进行比对,之后又进行了消融实验,从而证明模型的有效性。
4. 模型结构
模型的总体框架可以分为三个部分:数据预处理、模型训练、异常检测。如下图所示。
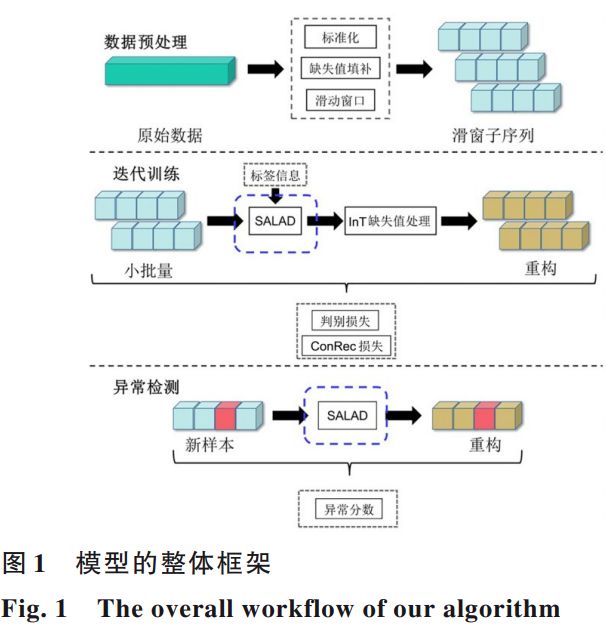
数据预处理模块:
设整体框架的输入为x。数据预处理模块包含三个预处理步骤:数据标准化、缺失值填充、滑动窗口处理。在数据标准化中将输入的时序数据放缩为值在-1到1范围的时间序列;一般的时序数据或多或少都存在某一时刻数据缺失的情况,在预处理阶段将相应的缺失值填充为0;最后使用滑窗大小为W的滑动窗口将填充之后长度为T的时序数据划分成一个大小为 (T - W + 1 )× W的矩阵,矩阵的每一行都作为一个样本输入到后续模型中。矩阵如下图所示。
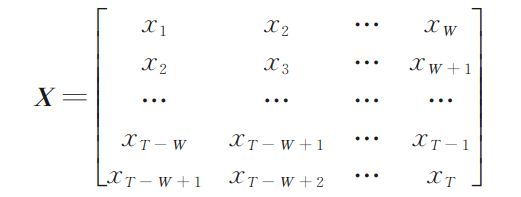
模型训练模块:
SALAD 模型包含四个部分:编码器e、解码器d、原始空间判别器D、隐空间判别器C。模型结构如下图所示。
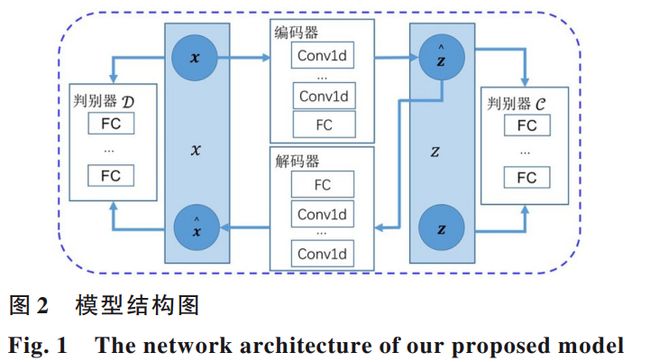
首先,经过预处理的滑窗序列通过编码器e编码到低维隐空间中,表示为z’;随后,解码器d将编码出的隐变量z’重构回原始空间,并输出x’。如前所述,在隐空间中通过一个隐空间判别器施加约束,让编码出的隐变量尽可能接近一个先验分布。
为了使自编码重构过程能够利用可使用的标签信息 ,引入一个全新的损失函数——对比重构损失(ConRec),能够根据标签的比率灵活调整重构参数。对比重构的损失函数定义如下:

重构之后的样本x’同时通过重构损失和原始空间判别器来进行正则化处理。可以看到模型的编码器和解码器都是通过一维卷积层和全连接层实现的,原始空间判别器和隐空间判别器通过全连接层的堆叠形成。
模型的目标损失函数主要由两部分组成:原始空间正则化损失和隐空间正则化损失。这两个损失都引入了对比重构损失。具体定义如下:
原始空间正则化损失,用来在训练过程中使编码器和解码器重构之后的样本尽可能地还原出原始的正常样本。其中,判别器D试着最大化判别损失,而编码器和解码器试着最小化判别损失,二者构成对抗训练。具体定义如下:
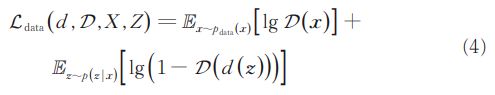
隐空间正则化损失函数:
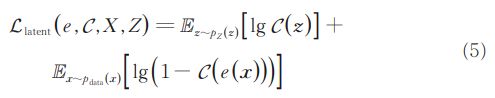
其中,z是从一个预定义的先验分布(如标准正态分布)采样得到的样本,在对抗训练过程中隐空间判别器C的目标是尽可能地判别出编码器e编码出的隐变量样本表示和从先验分布中采样的样本。
此外,值得注意的是,文章提出如果只在数据预处理阶段填充缺失值,会因为缺失值的不准确影响后续训练阶段的效果 . 为了动态地处理缺失值,提出InT动态缺失值填充方法,SALAD模型可以在每一轮的网络迭代训练过程中,使用当前的网络对缺失值进行预测,使用预测值对缺失进行相应的填补,填补完成后继续进行网络训练。填充方式如下。

整个训练过程可以用如下图所示的算法表示。


异常检测模块:
模型训练完成之后将测试样本输入模型,计算相应的异常分数并判断是否异常。SALAD 模型无法获得待测样本的具体分布,无法计算待测样本的似然来判断是否异常,而是使用重构误差和判别误差相结合的方式来得到异常分数,其中重构损失自编码器重构输入样本之后 用来测量输入样本和重构样本之间的距离,因为训练自编码器是用来重构正常模式的,也就是无异常状态下的时间序列,所以如果有一个样本异常,则重构出的样本和原始样本之间的距离会很大。判别损失可以由原始空间判别器直接得到,总体的异常分数 S 定义如下式所示。

得到S后便可以设置一个阈值来判断是否异常,如下式所示。
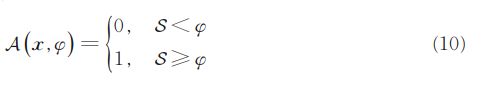
5. 实验
文章用于模型评估的数据集来自AIPOS竞赛第一阶段的KPI数据和来自Yahoo Lab的用于时序异常检测的基准数据集。对于KPI数据集,选择其中四条KPI用于本文的模型评估,分别将其表示为A,B,C,D,数据可视化如下图所示。
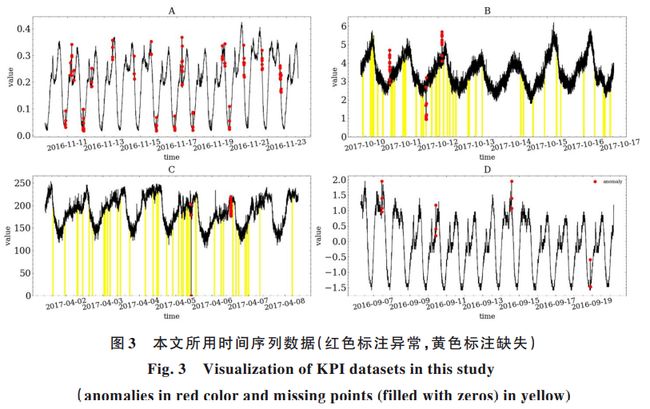
对于Yahoo Lab的数据集,该数据集包含四组带有全标注的时序数据集,分别为一组真实生产流量数据集A1和其他三组合成数据集A2/A3/A4,数据采样间隔为1h。为了验证本文模型在实际场景下建模数据分布的能力,用A1验证模型的异常检测性能,将其标识为E,数据集E含有67条实际流量序列不包含数据缺失值。分别为每一条序列训练一个模型,得到相应的评价指标,最后进行汇总,得到整个数据集的最终评价指标。
用于比较的7个baseline:IF(传统的机器学习异常检测方法)、AEs(传统的基于自编码器的异常检测方法)、VAEs(传统的基于变分自编码器的异常检测方法)、AAEs(基于传统对抗训练的自编码器方法)、Donut(基于变分自编码器的单变量时序异常检测方法)、MAD-GAN(基于对抗训练的多变量时序异常检测方法),Beat-GAN(基于对抗训练的心跳异常检测方法)。
由于已将检测时会存在连续的异常点,用逐点评估的方法不准确,采用另一种评估方法,在这段连续的异常点上,如果在一定的延迟下检测出任何一个异常点,则整段序列都判断为异常。具体来说,对于一段连续的异常点设置一个阈值k,如果这一段上任何一个点被检测为异常,并且检测到的这个点的延迟不超过k,则这一段的所有点都被判别为异常,具体评估方式如下图所示。
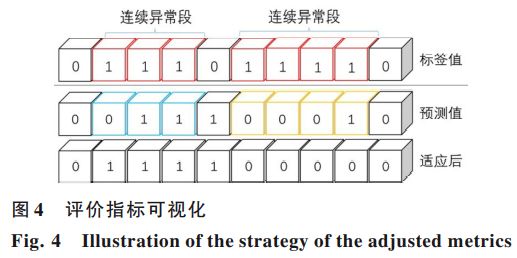
第一行表示两段连续的异常点,分别用红色框标识,第二行表示模型的实际预测结果。假设评估的阈值k = 2,在蓝色框中检测到的异常点的延迟为1,小于设置的阈值,所以整段蓝色框中的点都判断为异常点;黄色框中检测到异常点的延迟为3,大于设置的阈值,所以这一整段都判断为正常点。最终调整之后的异常检测结果显示在第三行中,基于第三行的结果可以得到相应的 F1 score。本文设置阈值k=7。
实验结果如下所示。

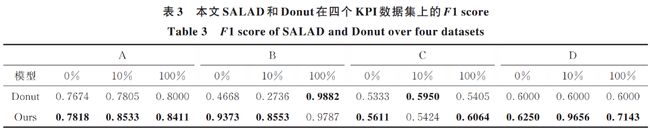
可以看到文章提出的SALAD都取得的很好的效果。
接着针对文章提出的两个创新点:对比重构损失(ConRes)和InT缺失值处理。使用KPI数据集进行了消融实验,结果如下图所示。
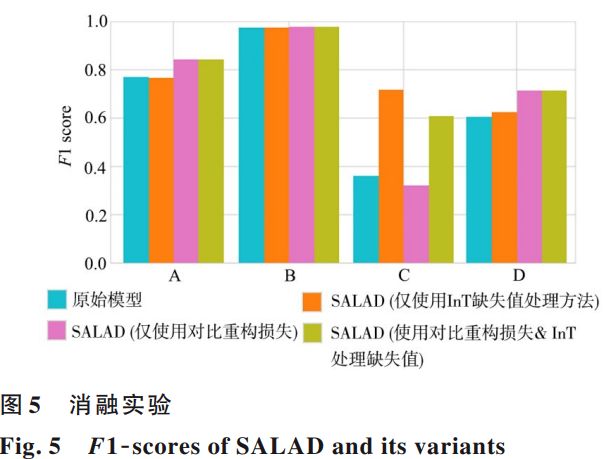
6. 结论
本文提出一种全新的基于自编码器的时序异常检测方法SALAD,引入对抗学习的思想,在对比重构(ConRec)损失函数和InT缺失值处理方法这两种关键技术的加持下,SALAD 能够应对时序异常检测的三个挑战:处理复杂数据分布、解决时序缺失值以及有效利用先验信息。通过大量的实验和推导,充分证明了本文方法的有效性,在公开数据集上的实验证明 SALAD比其他传统方法和一些现有方法具有更好的异常检测性能。
ATTENTION
如果你和我一样是轨道交通、道路交通、城市规划相关领域的,可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!