卷积神经网络里的attention机制
参考:
https://arxiv.org/abs/1807.06521
https://arxiv.org/abs/1709.01507
https://zhuanlan.zhihu.com/p/65529934
https://zhuanlan.zhihu.com/p/32702350
https://github.com/luuuyi/CBAM.PyTorch
https://github.com/moskomule/senet.pytorch
1.CBAM: Convolutional Block Attention Module
2.Squeeze-and-Excitation Networks
先来谈SEnet吧,站在2020年看SEnet感觉就是个很容易实现的模块了
利用pytorch提供的nn.AdaptiveAvgPool2d和全连接层完成
原理的话,自己理解,在SEnet网络之前,通道间的信息交流只有通过1*1的卷积,但是1*1的卷积,感受野只有1啊,不能获取全局的信息,无法将通道间的信息权重进行筛选,这个时候作者就想到了一招,对整个特征图做一次全局的采样,获取整张特征图最大值作为该通道的代表,于是我们便得到一个1*1*C通道的特征tensor,再将整个tensor经过两个linear层,最后再过一个sigmoid层,这样就可以得到通道权重系数了
from torch import nn
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
看一下Python代码,就AdaptiveAvgPool2d和Linear两个部件。
最终模型提升效果,提升了0.5%
再来谈CBAM吧,CBAM不仅用了通道attention而且用了空间attention
1.通道attention

相比于SEnet多加了MaxPooling的分支,MLP中也有先做特征压缩再做特征恢复的过程,最后将这两个分支加起来再过attention模型,作为最终的通道注意力
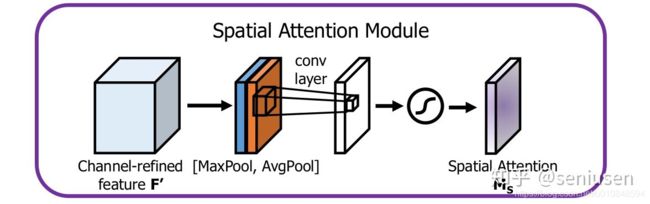
2.空间attention
理解了通道attention,理解空间attention就不难了,对特征图每个位置所在的通道做一次Max和Avg Pooling,这样便得到两个W*H*1的特征图,这个时候怎么把他两合并呢?作者选择做卷积,整了个7*7的卷积核来卷,得到空间attention,W*H*1的权重图,再乘上特征,完成attention
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
通道attention,avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))和max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))分别代表上下两个分支,最后再add起来,过sigmoid
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
再看空间attention, avg_out = torch.mean(x, dim=1, keepdim=True)和 max_out, _ = torch.max(x, dim=1, keepdim=True)分别从C个通道里面取最大值和均值,再cat起来,再过一个卷积和sigmoid完事