奇异值分解(SVD)(Singular Value Decomposition)
奇异值分解在机器学习中经常碰到,今天详细讲讲。本文章中说的"矩阵" / "向量" 都指的是实数矩阵/实数向量,我们只说实数域内的情况。
整数有质因子分解,比如12=2*2*3。分解成2*2*3后,比单单研究12这个数,我们会容易得到一些信息,比如,12这个数不能整除5;一个数 n 乘12后,会整除 2 和 3;等等。
那么矩阵呢,我们是否可以像整数的质因子分解一样进行分解?这样比单单研究这个矩阵也许就会获得很多有用的信息。答案是任何一个矩阵都可以进行奇异值分解,并且奇异值分解很有用。
本篇文章的目录如下:
目录
特征分解(Eigendecomposition)
特征向量与特征值
有n个线性独立特征向量的方阵性质,包括几何解释
什么样的矩阵有n个线性独立特征向量
奇异值分解(Singular Value Decomposition)
左奇异向量、右奇异向量、奇异值
奇异值分解的几何解释
紧奇异值分解和截断奇异值分解
奇异值分解与矩阵近似
奇异值分解的应用
我们在说奇异值分解之前,需要先说说特征值分解。
特征分解(Eigendecomposition)
特征向量与特征值
首先,特征分解只适用于方阵。
我们可以定义特征向量。如果一个非0向量 ![]() 满足
满足 ![]() ,那么这个非0向量
,那么这个非0向量 ![]() 就是
就是 ![]() 的特征向量。
的特征向量。
一个矩阵 ![]() 可能没有特征向量,也可能有特征向量。如果有特征向量,也可能有
可能没有特征向量,也可能有特征向量。如果有特征向量,也可能有 ![]() 个线性独立的特征向量,或者
个线性独立的特征向量,或者 ![]() 个线性独立的特征向量。
个线性独立的特征向量。
有n个线性独立特征向量的方阵性质,包括几何解释
如果一个矩阵 ![]() 有特征向量,并且有
有特征向量,并且有 ![]() 个线性独立的特征向量,我们可以分析出来一些有用的信息,那可以分析出来什么信息呢?我们可以简单地推导一下:
个线性独立的特征向量,我们可以分析出来一些有用的信息,那可以分析出来什么信息呢?我们可以简单地推导一下:
一、代数性质
我们记这![]() 个线性独立的特征向量为
个线性独立的特征向量为![]() ,并且对应的特征值为
,并且对应的特征值为![]() 。我们将每一个特征向量作为一列拼起来,形成特征向量矩阵
。我们将每一个特征向量作为一列拼起来,形成特征向量矩阵![]() ,同理我们把相应的特征值拼成一个向量
,同理我们把相应的特征值拼成一个向量![]() ,那么我们可以得到:
,那么我们可以得到:
![]()
由于 ![]() 是 n 阶方阵,并且所有列都相互线性独立,所有
是 n 阶方阵,并且所有列都相互线性独立,所有![]() 的逆
的逆![]() 存在,所有可得:
存在,所有可得:
![]()
如果我们将![]() 中的每一列都化为单位向量并且和其他向量都正交,当然此时的
中的每一列都化为单位向量并且和其他向量都正交,当然此时的![]() 也发生了改变,那么可以得到一个正交矩阵
也发生了改变,那么可以得到一个正交矩阵 ![]() ,由于正交矩阵
,由于正交矩阵 ![]() ,可以得到:
,可以得到:
![]()
这个式子是我们经常见到的式子,用这个式子推导其他式子都很方便。
二、几何性质
上述都是基于公式推导理解,有没有特征值分解的几何理解呢?我们不妨先基于二维平面做一下分析。
假设![]() 有2个线性独立的特征向量
有2个线性独立的特征向量 ![]() 和
和 ![]() (假设我们已经将这两个特征化简成了正交单位向量),以及对应的特征值
(假设我们已经将这两个特征化简成了正交单位向量),以及对应的特征值 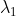 和
和 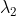 。我们可以分析二维平面单位圆上的点,设这个单位圆上每一个点的坐标是
。我们可以分析二维平面单位圆上的点,设这个单位圆上每一个点的坐标是  ,每一个点的点向量是
,每一个点的点向量是 ![]() ,我们都知道
,我们都知道 ![]() 且
且 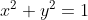 。
。
如果我们给 ![]() 左乘
左乘![]() 得到
得到 ![]() 向量,该点坐标为
向量,该点坐标为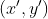 ,那么
,那么
根据推导出来的式子我们得知![]() 的点坐标为
的点坐标为 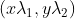 ,
, ![]() 向量的两个点坐标相等,故而
向量的两个点坐标相等,故而![]() 。由于 ,所以得
。由于 ,所以得![]() ,这是个椭圆呀~,可以下结论了,一个圆上所有点左乘一个
,这是个椭圆呀~,可以下结论了,一个圆上所有点左乘一个 ![]() 会使得这个圆变成椭圆,并且哪个特征向量的特征值越大,原向量就越偏向哪个特征向量,与这个特征值大的特征向量之间的夹角就会变小,如下图所示:
会使得这个圆变成椭圆,并且哪个特征向量的特征值越大,原向量就越偏向哪个特征向量,与这个特征值大的特征向量之间的夹角就会变小,如下图所示:
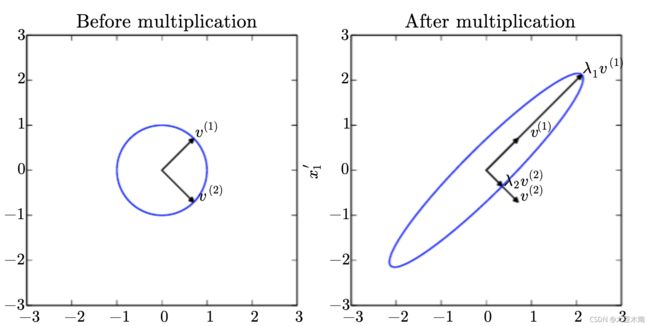
我们将单位圆上的点推广到二维平面的所有圆上的点(也就是二维平面上的所有点),该点对应的向量左乘![]() 都会使该向量发生转变(方向和模都变),
都会使该向量发生转变(方向和模都变),![]() 的哪个特征向量的特征值大,转变后的向量就越偏向那个特征向量,与其夹角会变小,并且转变后的向量的模大程度受
的哪个特征向量的特征值大,转变后的向量就越偏向那个特征向量,与其夹角会变小,并且转变后的向量的模大程度受![]() 的最大特征值的影响。
的最大特征值的影响。
什么样的矩阵有n个线性独立特征向量
实对称矩阵一定有n个线性独立特征向量,但是有n个线性独立特征向量的矩阵不一定是实对称矩阵。具体的证明就不在这里说啦,想找证明的话书上找找叭~
奇异值分解(Singular Value Decomposition)
左奇异向量、右奇异向量、奇异值
只有方阵可以进行特征分解。对于一般的矩阵,可以用奇异值分解进行分解。一个一般的矩阵可以被分解成这样:
![]() (把各个矩阵的维度标出来的话就是
(把各个矩阵的维度标出来的话就是 ![]() )
)
其中 :
1、![]() 是
是 ![]() 的特征向量矩阵(是正交矩阵);
的特征向量矩阵(是正交矩阵); ![]() 的列向量称为左奇异向量(left singular vector)。
的列向量称为左奇异向量(left singular vector)。
2、![]() 是
是 ![]() 的特征向量矩阵(是正交矩阵);
的特征向量矩阵(是正交矩阵); ![]() 的列向量称为右奇异向量(right singular vector)。
的列向量称为右奇异向量(right singular vector)。
3、![]() 是对角矩阵,
是对角矩阵,![]() 中对角线上的非0值是
中对角线上的非0值是 ![]() 的非0特征值的平方根 ,同时也是
的非0特征值的平方根 ,同时也是![]() 的非0特征值的平方根。(
的非0特征值的平方根。(![]() 中对角线上的值从大到小降序排列;
中对角线上的值从大到小降序排列;![]() 对角线上非0值的个数是
对角线上非0值的个数是![]() 的秩,其<=min(m,n) )。
的秩,其<=min(m,n) )。![]() 中非0值称为奇异值(singular value)。
中非0值称为奇异值(singular value)。
至于奇异值分解基本定理的证明,可以参考李航老师的统计学习方法第二版 第15章 奇异值分解~,写的真的很明白!这里就不证明了。
奇异值分解的几何解释
实对称矩阵的特征值分解的几何解释是:对任意向量 ![]() 左乘一个实对称矩阵
左乘一个实对称矩阵![]() ,则
,则![]() 在同一个空间内会发生缩放变换。当时我们做了推导。
在同一个空间内会发生缩放变换。当时我们做了推导。
一般矩阵的奇异值分解我们就不仔细推导了,我们简单了解一下。先说结论, 的矩阵
的矩阵![]() 表示从 n 维空间
表示从 n 维空间![]() 到 m 维空间
到 m 维空间 ![]() 的一个线性变换。
的一个线性变换。
给一个向量![]() 左乘一个任意矩阵
左乘一个任意矩阵 ![]() ,
,![]() ,我们从后往前看,先对
,我们从后往前看,先对![]() 左乘
左乘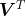 ,做相同维度 n 上的旋转变换;再在其基础上左乘
,做相同维度 n 上的旋转变换;再在其基础上左乘![]() ,做之前维度 n 上的缩放变换然后拔高/降低维度至 m ;再在其基础上左乘
,做之前维度 n 上的缩放变换然后拔高/降低维度至 m ;再在其基础上左乘 ![]() ,做m维度上的旋转变换。
,做m维度上的旋转变换。
紧奇异值分解和截断奇异值分解
之前说的奇异值分解的式子![]() 又称为矩阵
又称为矩阵![]() 的完全奇异值分解,实际上为了压缩矩阵存储空间,常用的是奇异值分解的紧凑形式和截断形式。紧奇异值分解是与原始矩阵等秩的奇异值分解,截断奇异值分解是比原始矩阵低秩的奇异值分解。
的完全奇异值分解,实际上为了压缩矩阵存储空间,常用的是奇异值分解的紧凑形式和截断形式。紧奇异值分解是与原始矩阵等秩的奇异值分解,截断奇异值分解是比原始矩阵低秩的奇异值分解。
1、紧奇异值分解:
若一般矩阵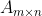 ,其秩为 rank(
,其秩为 rank(![]() ) = r , r <=min(m,n),那么
) = r , r <=min(m,n),那么 ![]() 的紧奇异值分解就是:
的紧奇异值分解就是:
![]()
注意这里是等号哦,其实![]() 就是将 原来的
就是将 原来的 ![]() 中的 0 项都去掉,只保留 r 个非 0 奇异值构成的对角方阵,其
中的 0 项都去掉,只保留 r 个非 0 奇异值构成的对角方阵,其 ![]() 是
是 ![]() 的前 r 列,其
的前 r 列,其 ![]() 是
是 ![]() 的前 r 列。
的前 r 列。
2、截断奇异值分解:
若一般矩阵,其秩为 rank(![]() ) = r , r <=min(m,n),且 0
) = r , r <=min(m,n),且 0
![]()
注意这里是约等号哦,这里的![]() 是原来的
是原来的![]() 取前 k 行前 k 列的对角方阵,其
取前 k 行前 k 列的对角方阵,其 ![]() 是
是 ![]() 的前 k 列,其
的前 k 列,其 ![]() 是
是 ![]() 的前 k 列。
的前 k 列。
奇异值分解与矩阵近似
奇异值分解是一种矩阵近似的方法,这个近似是在(Frobenius norm)意义下的对矩阵的最优近似。
矩阵 A 的 Frobenius norm :
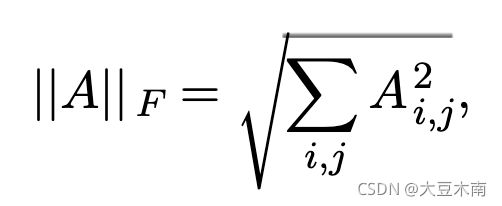
具体的证明有点复杂,可参考 李航老师的统计学习方法第二版 第15章 奇异值分解。
奇异值分解的应用
有关奇异值分解的应用,有PCA 主成分计算、 LSA 等。
可参考:
主成分分析(PCA)(principal component analysis)
潜在语义分析(LSA)(latent semantic analysis)
呼,终于完事了,今天的奇异值分解到这里就结束啦,欢迎各位大佬留言吖~