Linux操作系统
第一章 Linux概述
Linux是一种自由和开放源码的操作系统,存在着许多不同的Linux版本,但它们都使用了Linux内核。Linux可安装在各种计算机硬件设备中,比如手机、平板电脑、路由器、台式计算机
1.1.简要介绍
- Linux内核出现于1991年,最初只是由芬兰人林纳斯•托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。
- Linux是一套免费使用和自由传播的类似与Unix操作系统,是一个基于POSIX和UNIX的多用户、多任务、支持多线程和多CPU的操作系统。
- Linux能运行主要的UNIX工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
1.2Linux的特点
- 开源:用户可以通过网络后其他途径免费获得,并可以任意修改其源代码。(!=免费)
- 多用户:各个用户对于自己的文件设备有自己特殊的权利,保证了各用户之间互不影响。
- 多任务:可以多个程序同时独立地运行(类似window系统一边下载大片、一边听着音乐、一边浏览着你“亲爱的她”的空间美照)
- 良好的界面:Linux同时具有字符界面和图像界面。建议大家使用字符界面(也被称为命令行界面)。
- Ubuntu-乌班图——被称为“最美Linux”
- 支持多平台:可以在多种硬件平台上安装和运行,如X86或嵌入式系统(三星、oppo、小米等安装系列的手机底层使用的就是linux系统)
1.3Linux版本
由于Linux是一个开源的操作系统。
所以,世界上任何的人或者公司都可以获得它的代码,构建自己操作系统,这就导致市场上的Linux的版本非常的多。
Linux系统的版本包括:内核版和发行版
1.3.1 Linux内核版本

1、mainline
主线版本
2、stable
稳定版,由mainline在时机成熟时发布,稳定版也会在相应版本号的主线上提供bug修复和安全补丁,但内核社区人力有限,因此较老版本会停止维护,而标记为EOL(End of Life)的版本表示不再支持的版本。
3、longterm(Long Term Support)
长期支持版,长期支持版的内核不再支持时会标记EOL。
4、linux-next,snapshot
代码提交周期结束之前生成的快照 用于给Linux代码贡献者们做测试
1.3.2 Linux发行版本
Linux的发行版说简单点就是将Linux内核与应用软件做一个打包
常用的Linux发行版本如下:
| 个人版 | Ubuntu、Linux Mint |
|---|---|
| 服务器版 | Radhat(小红帽)、CentOS |
在众多发行版本中,我们不考虑个人版。
1.3.3 Linux主要的发行版
1.RedHat Linux:是知名厂商小红帽公司推出的商业版本,功能很强大,需要收费。它有众多的程序支持,同时也可以提供技术服务。
2.CentOS:一款企业级Linux,它使用红帽企业级Linux中的免费源代码重新构建而成。这款重构版完全去掉了注册商标,免费版。市场上Radhat和CentOS是同步发行、同步更新的,学会了CentOS,就等于是学会了Radhat。
3.其他: Ubuntu、Debain、Fedora、SuSE、OpenSUSE、TurboLinux、BluePoint、RedFlag、Xterm、SlackWare等
本次课程使用的是***CentOS版本***。
1.4 Linux系统的应用
1.服务器系统
Linux因为价格低廉、灵活性好,现在使用最广泛的领域就是服务器操作系统。现在以 Linux为基础的LAMP(Linux、Apache、MySQL、Perl/PHP/Python的组合)技术,除了已在开发者群体中广泛流行,也是网站服务供应商最常使用的平台。
2.桌面系统
新版本的Linux系统特别在桌面应用方面进行了改进,达到相当高的水平,完全可以作为一种集办公应用、多媒体应用、网络应用等多方面功能于一体的图形界面操作系统。更重要的是,这样的桌面系统可以免费使用。
3.嵌入式系统
可能很多人没有想到,现在很多移动设备也采用基于 Linux 的嵌入式系统,例如机项盒、移动电话及移动设备等。由于 Linux 的内核是完全公开的,所以基于 Linux 的嵌入式系统研发成本大大降低,而且不受其他非人为因素的干扰。
4.电子政务
随着众多IT知名厂商对Linux软件态度的转变,Linux正在成为一股可以与Windows 抗衡的重要力量。而它在安全性方面的独特优势,又使得 Linux 在政府应用领域大行其道。目前一些国家正在将其电子政务系统向 Linux平台迁移。这些重要举措是:成立Linux 软件标准工作组、建立国家Linux 公共服务平台体系和出台软件政府采购管理办法,如红旗Linux已经获得认可。
总之,从嵌入式设备到超级计算机,并且在服务器领域使用非常多。
1.5 Linux VS Windows
目前国内Linux更多的是应用于服务器上,而桌面操作系统更多使用的是Window(个人电脑常用),目前大多数企业开发的现状是,window下开发,Linux部署。
主要区别如下:
| 比较 | Windows | Linux |
|---|---|---|
| 界 面 | 界面统一,外壳程序固定所有Windows程序菜单几乎一致,快捷键也几乎相同 | 图形界面风格依发布版不同而不同,可能互不兼容。GNU/Linux的终端机是从UNIX传承下来,基本命令和操作方法也几乎一致。 |
| 驱 动 程 序 | 驱动程序丰富,版本更新频繁。默认安装程序里面一般包含有该版本发布时流行的硬件驱动程序,之后所出的新硬件驱动依赖于硬件厂商提供。对于一些老硬件,如果没有了原配的驱动有时很难支持。另外,有时硬件厂商未提供所需版本的Windows下的驱动,也会比较头痛。 | 由志愿者开发,由Linux核心开发小组发布,很多硬件厂商基于版权考虑并未提供驱动程序,尽管多数无需手动安装,但是涉及安装则相对复杂,使得 新用户面对驱动程序问题(是否存在和安装方法)会一筹莫展。但是在开源开发模式下,许多老硬件尽管在Windows下很难支持的也容易找到驱动。HP、 Intel、AMD等硬件厂商逐步不同程度支持开源驱动,问题正在得到缓解。 |
| 比较 | Windows | Linux |
|---|---|---|
| 使用 | 使用比较简单,容易入门。图形化界面对没有计算机背景知识的用户使用十分有利。 | 图形界面使用简单,容易入门。文本界面,需要学习才能掌握。 |
| 学习 | 系统构造复杂、变化频繁,且知识、技能淘汰快,深入学习困难。 | 系统构造简单、稳定,且知识、技能传承性好,深入学习相对容易。 |
| 软件 | 每一种特定功能可能都需要商业软件的支持,需要购买相应的授权。 | 大部分软件都可以自由获取,同样功能的软件选择较少。Vi vim |
课后作业
1.列出你的生活中与Linux相关的应用
2.掌握Linux操作系统的特点
第二章 Linux安装及文件操作shell命令
2.1 环境准备:
1 Windows10
2 VMware Workstation15
3 CentOS7
2.2 VMware简介
VMWare (Virtual Machine ware)是一个虚拟机软件,它可以使你在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。“多启动”系统(如Win10+Win7双系统)开机时只能选择其中一个运行,切换系统则需要重新启动机器。与之相比,VMWare在某种意义上可算是多系统“同时”运行。通过下载安装VMware Workstation,相当于在Windows系统里再安装了一个Windows系统,而且它还可以像应用程序那样进行切换。每个虚拟机操作系统你都可以进行虚拟的分区、配置而不影响真实硬盘的数据,甚至可以通过网卡将几台虚拟机用网卡连接为一个局域网,极其方便
缺点是虚拟机的操作系统性能上比你真实的系统性能低不少,因此,更推荐用于学习和测试。比如你想玩玩苹果的操作系统(Mac OS),就没有必要安装在实体机了。(实体机安装黑苹果步骤繁杂,独显还用不了)
2.3 VMware安装
双击安装包,进入安装页面
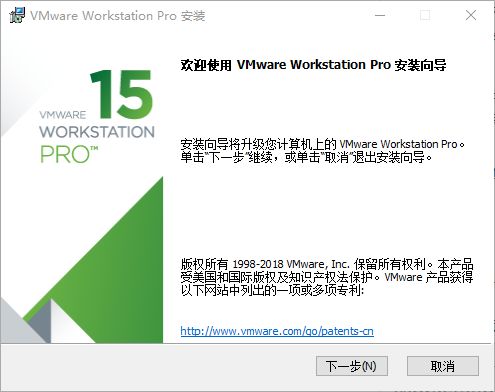
点 下一步

勾选接受协议,点下一步
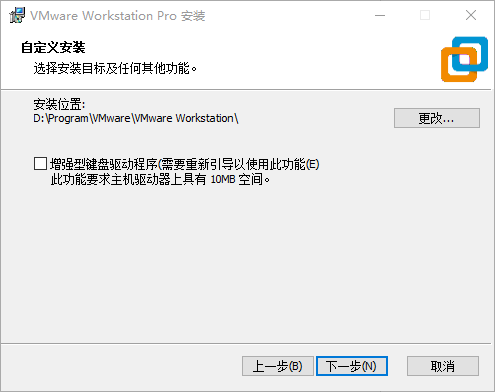
更改安装位置,选择非C盘的文件夹
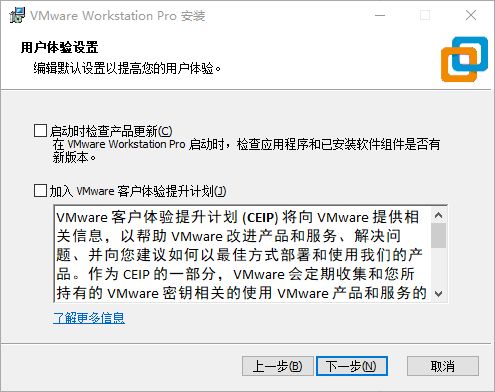
勾不勾选都无所谓,点 下一步
点 下一步
等待安装完成
等待虚拟机软件安装完成;点击许可证,在其中输入软件激活序列号,点击“输入”。
安装向导
 ](https://img2018.cnblogs.com/blog/1488047/201810/1488047-20181019193006755-1518775869.png)
](https://img2018.cnblogs.com/blog/1488047/201810/1488047-20181019193006755-1518775869.png)
虚拟机软件许可验证
安装完成进入VMware Workstation界面。
2.3 CentOS简介
CentOS,英文全称“Community Enterprise Operating System”,译为:社区企业操作系统,是 Linux 的发行版之一。该系统是基于 RHEL(红帽系统)的源代码进行再编译后,得到的产物(修复了RHEL很多已知的漏洞),两者无论是在操作上,还是在使用上,都没有太大的区别。
CentOS 系统版本介绍
安装CentOS系统时,无论哪个版本,官方都会提供多种映像文件,大体分为以下几类:
liveDVD版:DVD镜像,无需安装系统,插入光盘就可以体验 CentOS 的各种功能。
liveCD版: CD光盘映像,和liveDVD一样,唯一的区别就是该版本中包含的软件包会少一点,安装系统时使用 U 盘或者CD光盘进行安装。
bin:完整版,由于整个系统安装文件过大,所以一般会分为多个小文件,在下载时需全部下载。
bin-DVD版:该版本就是一个普通的安装版本,本身文件就比较大,包含了大量的常用软件。
minimal版:该版本同bin-DVD相似,不同之处在于该版本只包含有系统必须的几个基本软件包。
netinstall版:该版本也同 bin-DVD相似,不同在于netinstall的软件包全部需要通过网络下载进行安装。
CentOS 更多的是用于服务器上,也有桌面版本,安装系统时,可根据自己的需要,选择合适的映像。
2.4安装CentOS6.7步骤
1.打开VMware,点击创建新的虚拟机
 ](http://jingyan.baidu.com/album/425e69e61ba667be15fc16a1.html?picindex=1)
](http://jingyan.baidu.com/album/425e69e61ba667be15fc16a1.html?picindex=1)
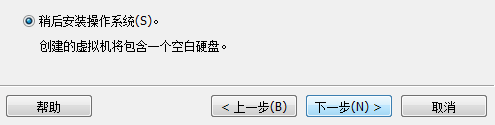
2.点击”下一步“,选择”稍后安装操作系统“后,点击”下一步“

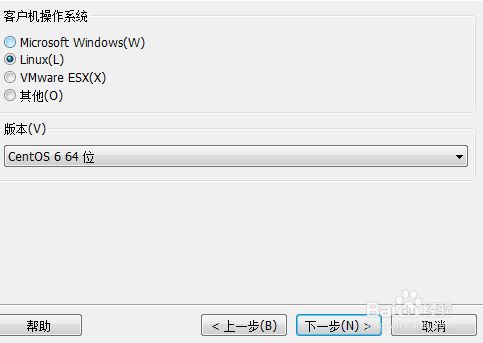
3.选择Linux,CentOS 6 64位后,点击”下一步“
4.选择CentOS的ISO镜像文件所在目录后,点击”下一步“

5.可以直接点击”下一步“,然后点击”自定义硬件“
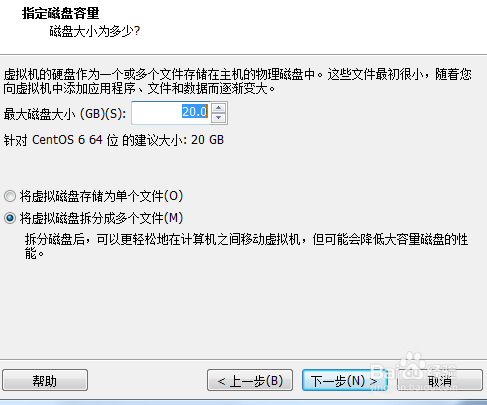
6.如图点击”浏览“,选择ISO镜像文件
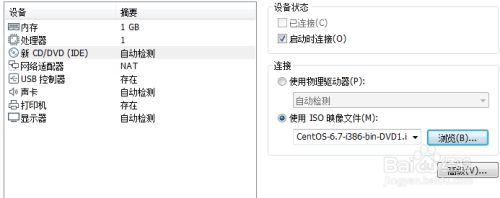
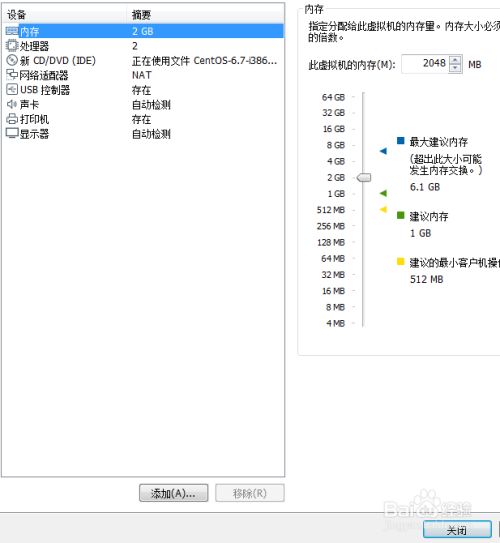
7.按照自己的需求配置好后关闭该窗口,最后点击”完成“即可

点击"开启此虚拟机”后,按Enter确认选择
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C0KP6wEV-1631443904808)(file:///C:/Users/Haos/AppData/Local/Temp/msohtmlclip1/01/clip_image002.png)]
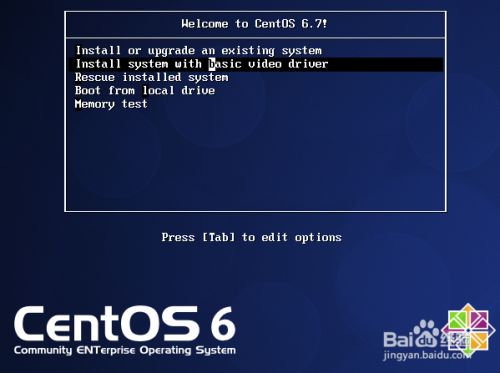
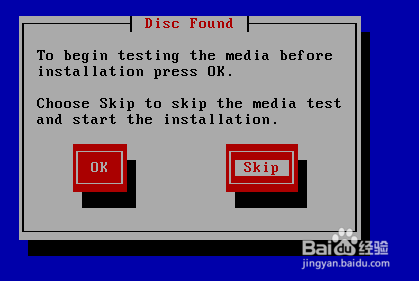
9.按右方向键,选择Skip,再按下Enter跳过检测
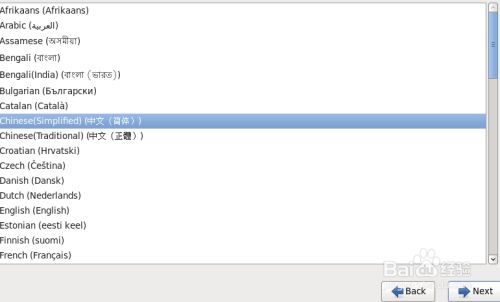
10.点击Next,选择语言后,点击Next

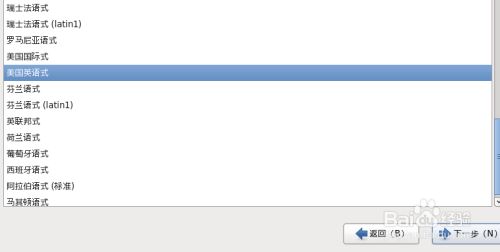
11.点击“下一步”,点击“下一步”
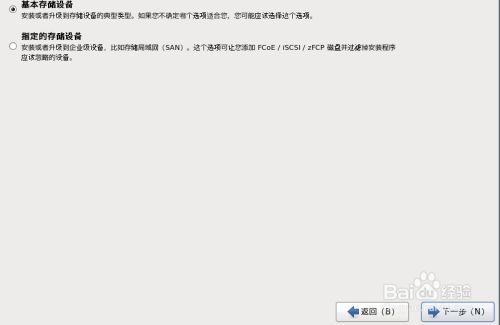
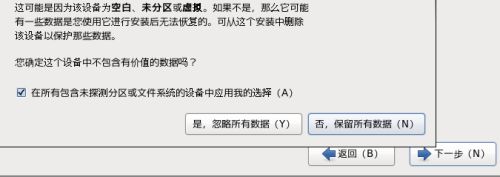
12.选择“是,忽略所有数据”
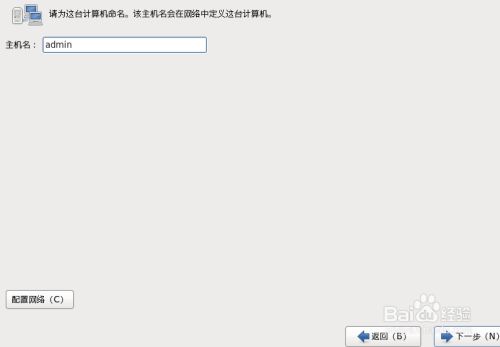
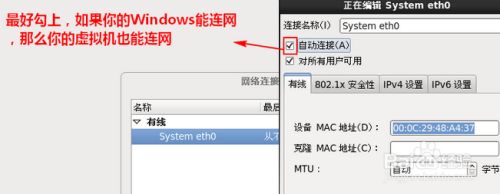
13.取个主机名后,点击“下一步”,点击“下一步”,同时可以配置网络为自动连接
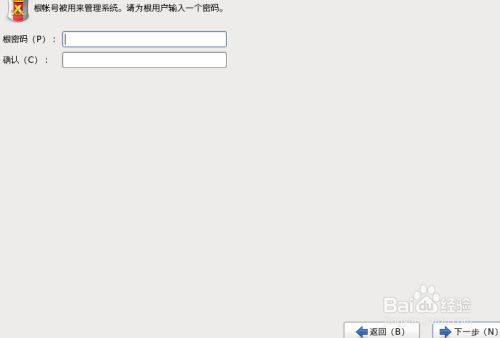
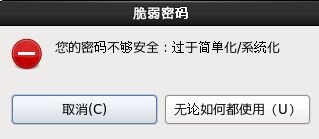
14.创建好密码后,点击“下一步”,选择“无论如何都使用”
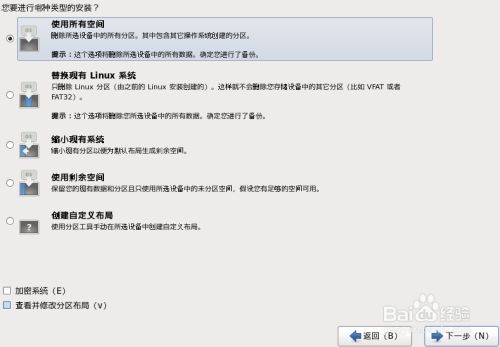
15.选择“使用所有空间”后,点击“下一步”
进阶、分区的创建:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gTiXOPN8-1631443904830)(file:///C:/Users/admin/AppData/Local/Temp/msohtmlclip1/01/clip_image001.png)]
需要创建三个分区,分别是:
1、/boot
2、swap交换分区
3、/ 根分区。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8z3yVoOX-1631443904831)(file:///C:/Users/admin/AppData/Local/Temp/msohtmlclip1/01/clip_image002.png)]
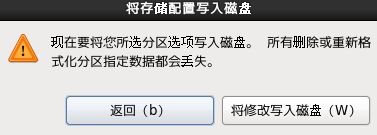
16.点击“将修改写入磁盘”
17.选择Desktop安装带有图形界面的系统,选择Basic Server安装纯命令行操作的系统
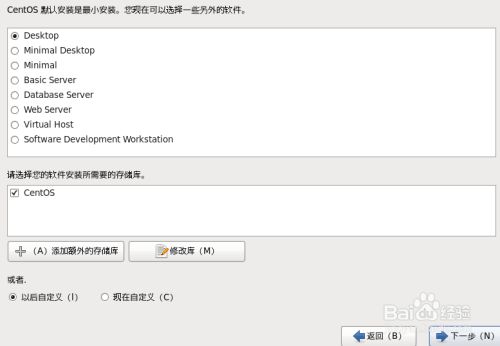
17.1、第一个表示要安装一个桌面系统
17.2、第二个表示要安装一个最小化系统
17.3、第三个表示要安装一个最小化系统
17.4、第四个表示要安装一个基本服务系统
17.5、第五个表示要安装一个数据库服务器
17.6、第六个表示要安装web服务器
17.7、第七个表示要安装一个虚拟机主机
17.8、表示安装一个软件开发工作站。
18.耐心等待系统安装
19.点击”重新引导“即可

20.点击右下角的“前进”


21.创建用户后,点击“前进”
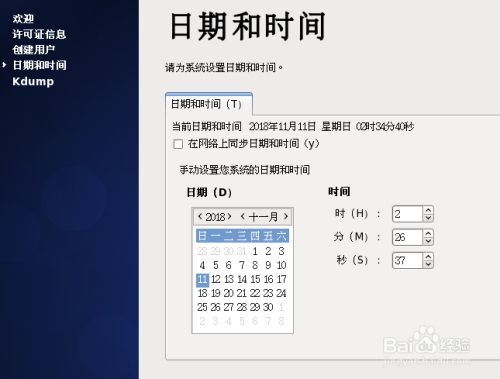
22.设置日期和时间后,点击“前进”
23.点击“完成”后,重新启动系统
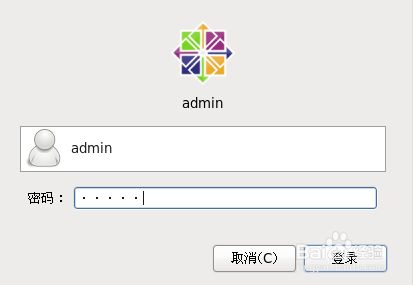
24.选择用户,输入密码登录即可
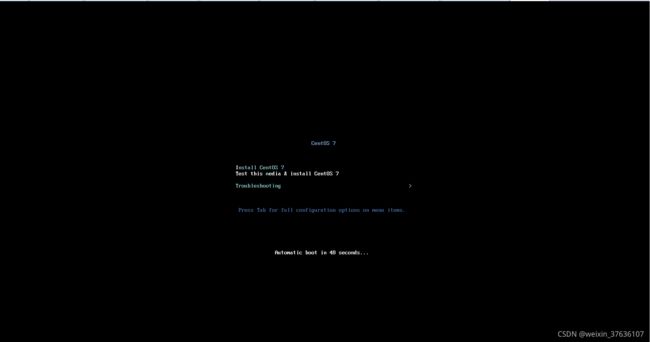
2.5CentOS7安装步骤
进入CentOS安装界面
选择第一项 Install CentOS 7
WELCOME TO CENTOS 7.
设置语言–推荐使用English–点击Continue
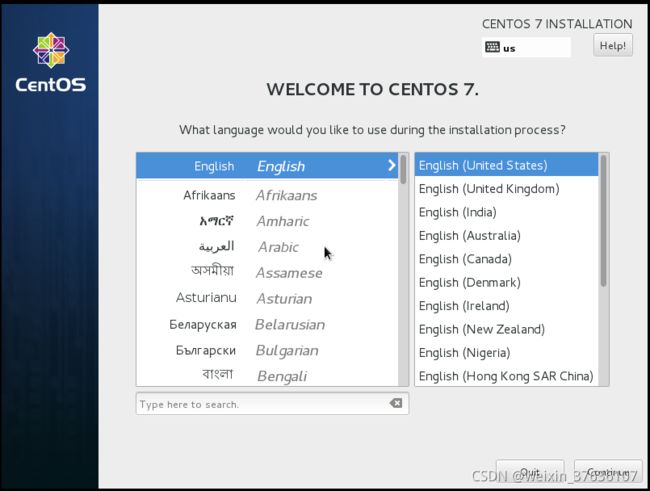
INSTALLATION SUMMARY 安装总览(这里可以完成centos 7 版本Linux的全部设置)
首先,设置时区–DATE & TIME
找到Asia–Shanghai并点击–Done
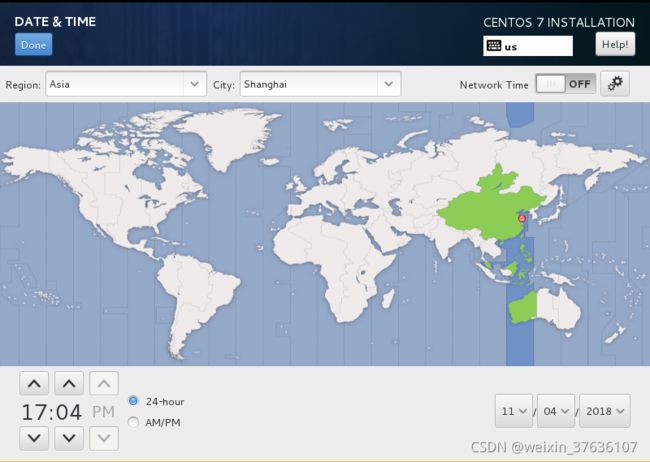
KEYBOARD 键盘就默认是English(US)

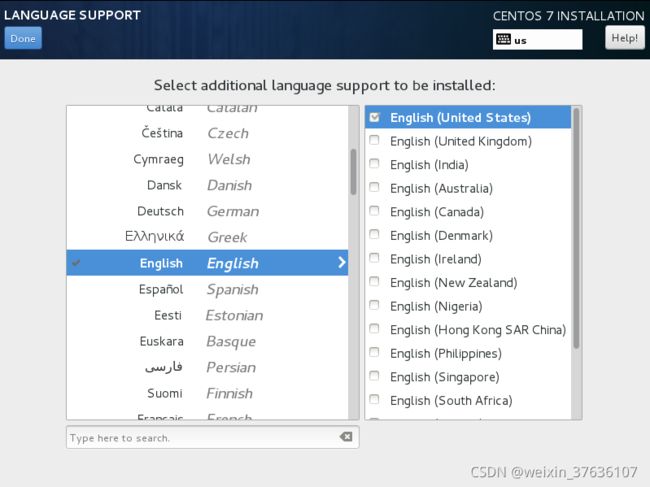
LANGUAGE SUPPORT语言支持

可以是默认的English 也可以自行添加Chinese简体中文的支持
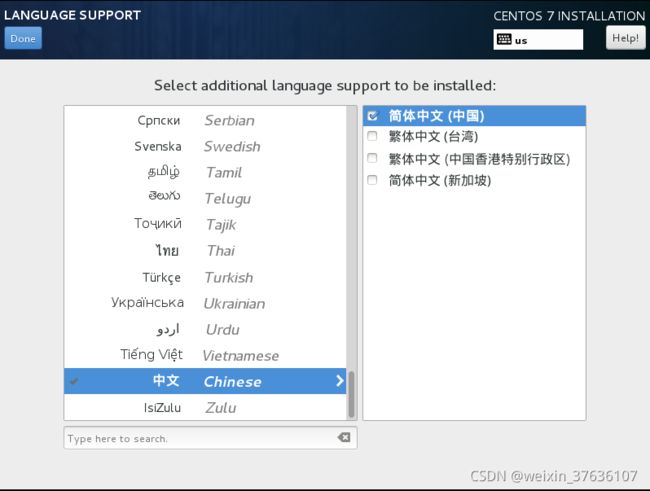
INSTALLATION SOURCE 安装资源
默认选择–Local media 本地媒体文件
SOFTWARE SELECTION软件安装选择
字符界面安装–Minimal install 或者 Basic Web Server

图形界面安装–Server with GUI 或者 GNOME Desktop
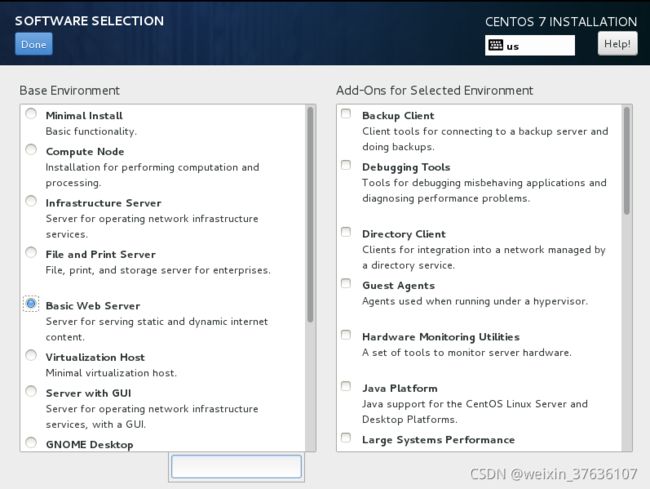
字符界面与图形界面安装过程相同,只在这一步有区分。
点击–Done进入下一步
INSTALLATION DESTINATION 安装位置—即进行系统分区
(1)首先选中我们在创建虚拟机时候的200G虚拟硬盘
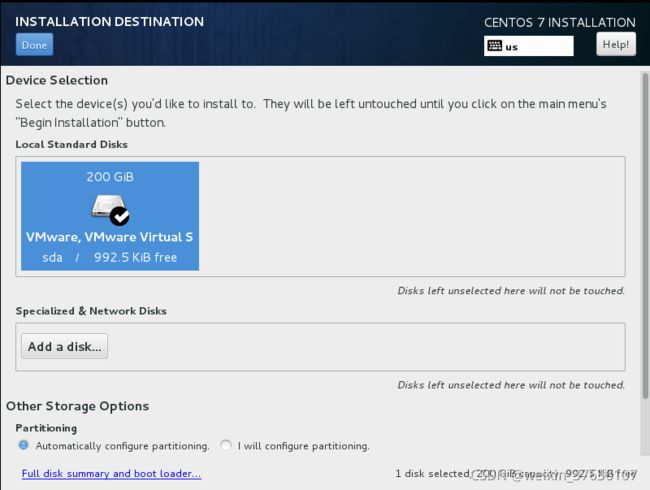
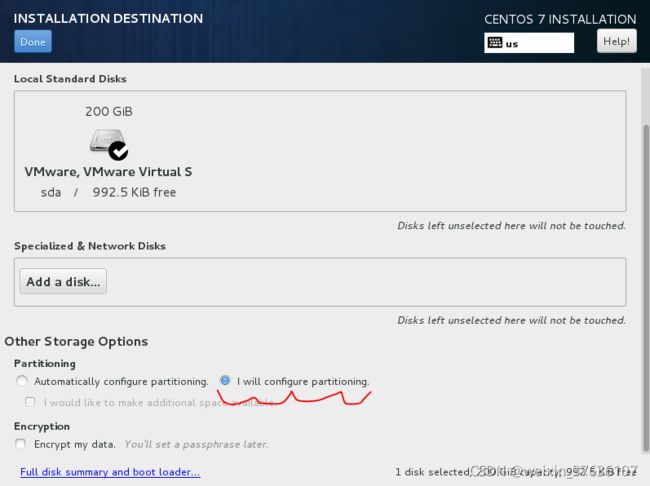
下滑菜单找到Other Storage Options–Partitioning–I will configure partitioning选中
I will configure partitioning 自定义分区
–点击done
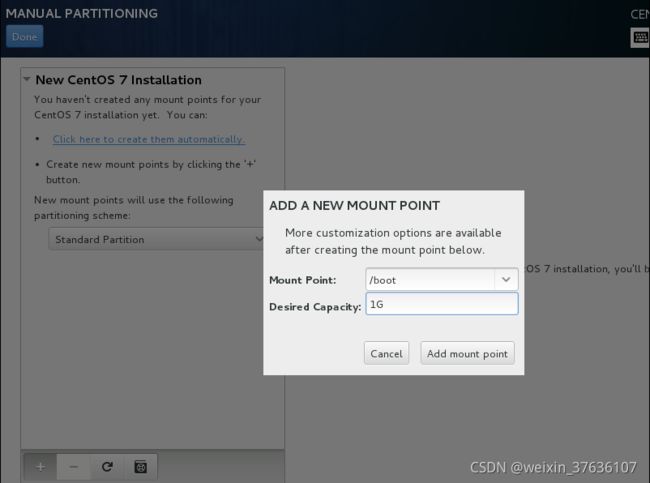
选择Standard Partition 标准分区–点击左下角**+** 添加分区

分区
creat–Standard Partition–creat–mount point(挂载点)和File System Type(系统文件类型)
分别创建/boot区、swap交换分区、根分区/
注释:Linux系统最简单的分区方案:
1、分/boot区,给200M,/boot放启动文件。
2、分交换分区(交换空间)swap,看内存总大小,如果内存足够大,这个空间就要设置太大了。如果内存小于2G。那么这个空间设置成内存的2倍大小。
3、所有空间给/(根分区)
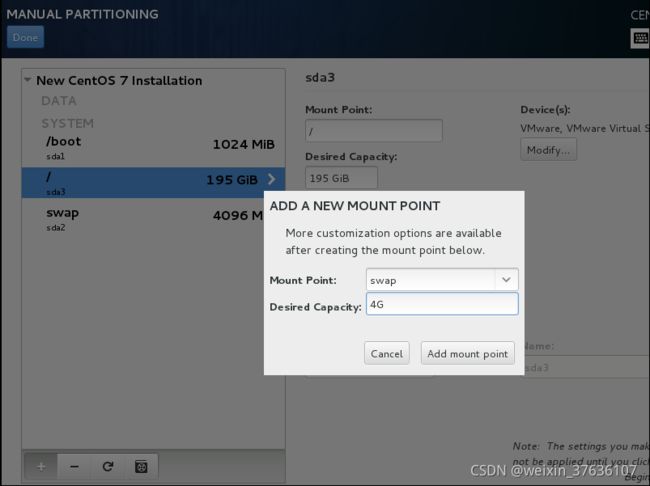
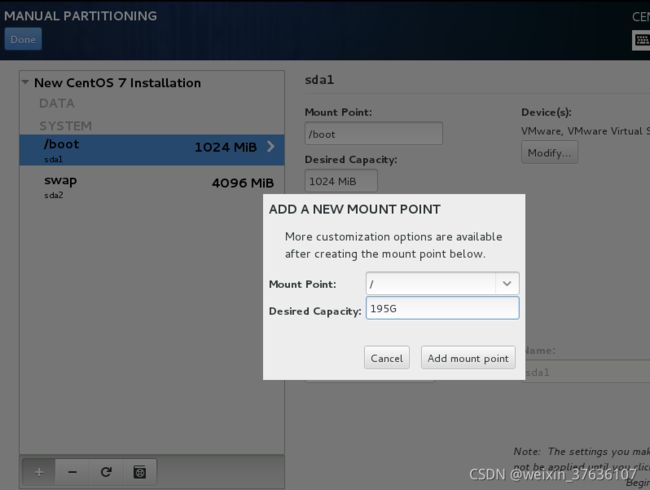
分区完成!
点击Done
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yqCcdk61-1631443904869)(img\0530883e8f6d613d84c521e3279534f6682.jpg)]](http://img.e-com-net.com/image/info8/1a1bc5421005404f99131fec9bb991c3.jpg)
点击Accept Changes
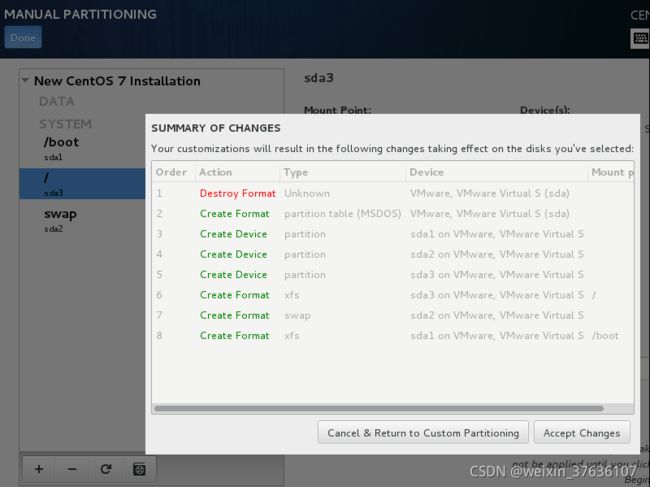
回到 INSTALLTION SUMMARY 中

KDUMP默认选择
NETWORK & HOST NAME 设置网络连接和主机名
在Host name处设置主机名:(例如 centos-7)
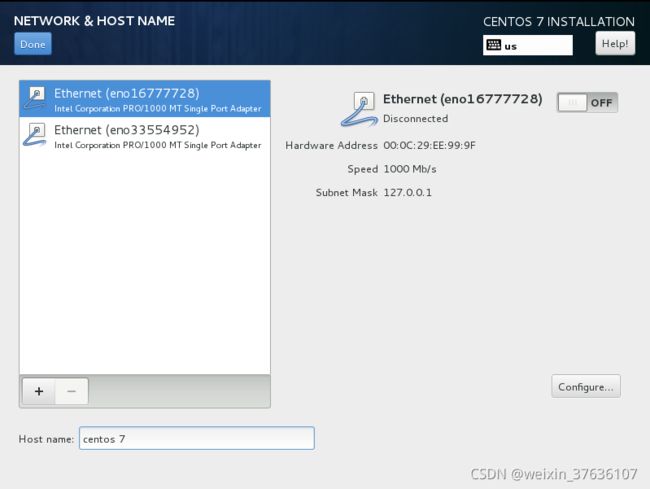
这是我们已完成所有设置
----Begin Installation
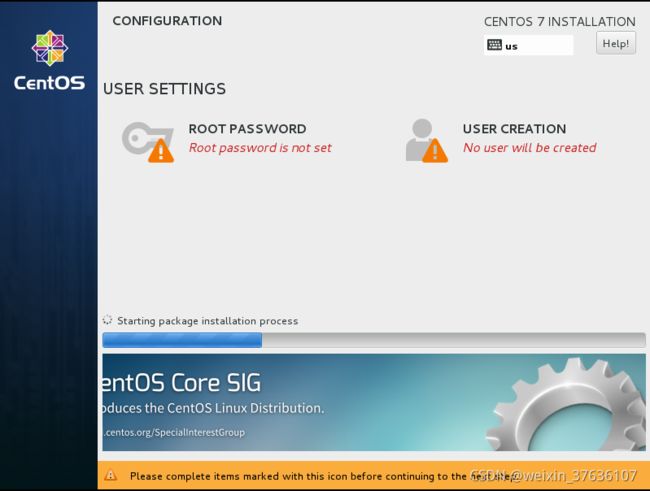
这时需要设置管理员Root Password(务必记住密码!)
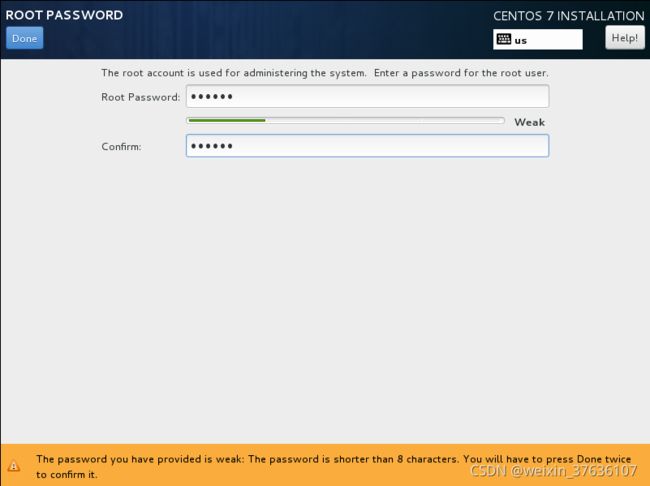
密码设置完成后,点击Done
接下来可以创建用户(此处可以不进行创建,安装完成后进入root也可以重新创建)
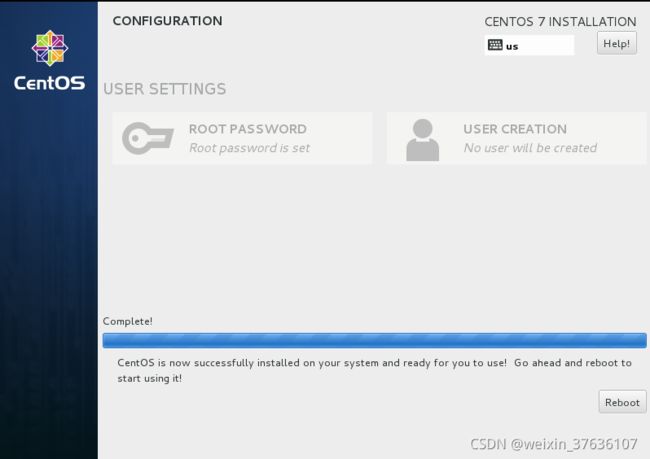
centos 7安装完成–点击reboot重启使用
字符界面见下图

图形界面见下图

2.6Linux常用命令
2.5.1关机命令
1:shutdown
运行状态
init 0关机
halt 关机
语法:shutdown [-efFhknr][-t 秒数][时间][警告信息]
说明:shutdown指令可以关闭所有程序,并以用户的需要,进行重新开机或关机的动作。
使用shutdown命令时在系统将要关机前,系统管理员会通知所有登录的使用者系统将要关闭。而且login指令会被冻结,即新的用户不能再登录。这是最安全的一种关机方法,因为在关机之前所有进程都会收到shutdown所发送的信号。shutdown执行它的工作是送信号给init程序,要求它改变runlevel。runlevel 0 被用来停机(halt),runlevel 6是用来重新启动(reboot)系统,而runlevel 1则是被用来让系统进入管理工作可以进行的状态;这是预设的,假定没有-h也没有-r参数给shutdown。
参 数:
-c Cancel Current Process取消目前正在执行的关机程序。当执行"shutdown -h 11:50"指令时,只要按Ctrl+c键就可以中断关机的指令。
-f 重新启动时不执行fsck(检查修复系统文件)。
-F 重新启动时执行fsck。
-h 将系统关机(halt)。
-k 只是送出信息给所有用户,但不会实际关机。
-n 不调用init程序进行关机,而由shutdown自己进行。不鼓励使用这个选项,而且该选项所产生的后果往往不总是你所预期得到的。
-r shutdown之后重新启动。
-t<秒数> 送出警告信息和删除信息之间要延迟多少秒。
[时间] 设置多久时间后执行shutdown指令。
[警告信息] 要传送给所有登入用户的信息。
演示
–shutdown –h now 立马关机
–shutdown –h 20:25系统会在今天20:25关机
–shutdown –h +10十分钟后关机
–shutdown –r now 系统立马重启
–shutdown –r +10系统十分钟后重启
2:reboot(重启)
语 法:reboot [-dfinw]
说明:执行reboot指令可让系统停止运作,并重新开机。
参 数:
-d 重新开机时不把数据写入记录文件/var/log/wtmp。本参数具有"-n"参数的效果。
-f 强制重新开机,不调用shutdown指令的功能。
-i 在重开机之前,先关闭所有网络界面。
-n 重开机之前不检查是否有未结束的程序。
-w 仅做测试,并不真的将系统重新开机,只会把重开机的数据写入/var/log目录下的wtmp记录文件。
3:init
语 法:init [0-6]
功能说明:转换运行级别(runlevel);init 0为关机,init 6为重启。
init 3 表示进入到终端模式系统
init 5 表示切换运行状态图形界面系统
4.halt 关闭系统
等同于shutdown –h now 和 poweroff
2.5.2文件目录操作命令
目录结构
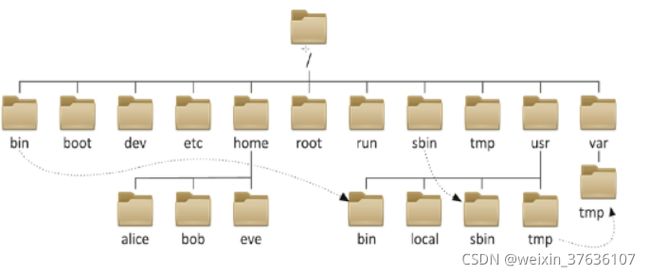
我们知道Linux的目录结构为树状结构,最顶级的目录为根目录 。
其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们。
1.绝对路径:
路径的写法,由根目录 / 写起,例如: /usr/share/doc 这个目录。
2.相对路径:
路径的写法,不是由 / 写起,例如由 /usr/share/doc 要到 /usr/share/man 底下时,可以写成: cd …/man 这就是相对路径的写法啦
Linux系统目录之一些重要的目录:
| (家)目录 | /root,/home/{UserName} |
|---|---|
| 普通用户可执行文件 | /bin,/usr/bin,/usr/local/bin |
| 系统管理员可执行文件 | /sbin,/usr/sbin,/usr/local/sbin |
| 配置文件目录 | /etc |
| 临时文件目录 | /tmp |
| 存放应用程序和文件 | /usr |
| 启动linux的核心文件 | /boot |
| 额外安装软件(mysql)默认为空 | /opt |
| 服务器数据 | /var , /srv |
| 系统信息 | /proc,/sys |
| 共享库 | /lib,/usr/lib,/usr/local/lib |
| 其它挂载点 | /media,/mnt |
注意:文件或目录名:<=255个字符、区分大小写、不能使用“/”,不允许创建与系统已有的相同名字的目录。因为不好区分,第二点,防止某些软件无法自动进行识别。
命令相关概念:
命令提示符:
[root@localhost ~]# #/root
[chenzhe@localhost ~]$ #/home/chenzhe
从上面两个命令提示符可以看的出来中括号后的符号不同,其中#表示超级权限(管理员/root),$表示普通用户的权限
中括号中的内容分别是:
| root | chenzhe | 登录的账户名称 |
|---|---|
| @localhost | 主机名 |
| ~ | 表示当前账户的家目录 |
命令格式:
命令、选项、参数之间,必须有空格!
执行的时候,命令本身必须存在,选项和参数可有可无。
选项和参数也可以有多个的存在。
执行时,如果有多个选项,可以拼在一起写:
ls -a -l 可以写成ls -al
执行时,如果有多个参数,参数之间必须有空格隔开
ls /root /etc
执行时可以没有选项、参数的命令
ifconfig
执行是有参数的命令:
ifup eth0
获取命令帮助:
| man | man 命令,优点是,内核自带,缺点,大部分的帮助都是英文 |
|---|---|
| help | 命令 --help 优点是:部分命令提供中文,缺点:不是所有的命令都有这个帮助文件 |
| 命令大全手册 | |
| 问度娘 |
1、cd:切换目录
(1)cd ~ 和 cd:返回用户目录
[root@izwz94jtz9hbdq165vpxpxz app1]# cd ~
[root@izwz94jtz9hbdq165vpxpxz ~]#
[root@izwz94jtz9hbdq165vpxpxz app1]# cd
[root@izwz94jtz9hbdq165vpxpxz ~]#
(2)cd .:停留在当前目录
[root@izwz94jtz9hbdq165vpxpxz app1]# cd .
[root@izwz94jtz9hbdq165vpxpxz app1]#
(3)cd …返回上一级目录
[root@izwz94jtz9hbdq165vpxpxz app1]# cd a
[root@izwz94jtz9hbdq165vpxpxz a]# cd ..
[root@izwz94jtz9hbdq165vpxpxz app1]#
(4)cd …/…返回上两级目录
[root@izwz94jtz9hbdq165vpxpxz app1]# cd www
[root@izwz94jtz9hbdq165vpxpxz www]# cd carina
[root@izwz94jtz9hbdq165vpxpxz carina]# cd ../..
[root@izwz94jtz9hbdq165vpxpxz app1]#
(5)cd …/目录A:
先返回进入此目录之前所在的目录,然后再进入指定的目录A
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app1/www
[root@izwz94jtz9hbdq165vpxpxz www]# ls
123.jgp 123.txt a2 carina requests-2.18.1.tar.gz root
[root@izwz94jtz9hbdq165vpxpxz www]# cd carina
[root@izwz94jtz9hbdq165vpxpxz carina]#cd ../a2
[root@izwz94jtz9hbdq165vpxpxz a2]#
(6)cd -:返回进入此目录之前所在的目录
[root@izwz94jtz9hbdq165vpxpxz app1]# cd www
[root@izwz94jtz9hbdq165vpxpxz www]# cd -
/app1
(7)cd 路径:进入指定目录
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app1/www
[root@izwz94jtz9hbdq165vpxpxz www]#
(8)cd /:返回到根目录
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /
[root@izwz94jtz9hbdq165vpxpxz /]#
[root@izwz94jtz9hbdq165vpxpxz carina]# cd /
[root@izwz94jtz9hbdq165vpxpxz /]
2、ls:列出目录下的文件(List files)
ls:列出指定路径下的所有文件名、时间及读写权限(文件详细信息)
(1)ls -a:显示所有文件列表(含隐藏文件“.”和“…”) all
[root@izwz94jtz9hbdq165vpxpxz www]# ls -a
. .. carina carina.tar.gz redis-3.0.7.tar.gz root text1.txt text.tx
(2)ls -A:显示除隐藏文件“.”和“…”以外的所有文件列表
[root@izwz94jtz9hbdq165vpxpxz www]# ls -A
carina carina.tar.gz redis-3.0.7.tar.gz root text1.txt text.txt
(3)ls -l:以列表形式显示文件及文件夹的详细信息 long
(从左至右:文件类型、权限、数量、属主、属组、大小、修改/访问时间、文件名)
[root@izwz94jtz9hbdq165vpxpxz www]# ls -l
total 1368
drwxr-xr-x 5 root root 4096 Jun 22 13:23 carina
-rw-r--r-- 1 root root 256 Jun 19 00:27 carina.tar.gz
-rw-r--r-- 1 root root 1375200 Jul 10 09:35 redis-3.0.7.tar.gz
drwxr-xr-x 3 root root 4096 Jun 19 00:40 root
-rw-r--r-- 1 root root 6 Jul 6 18:14 text1.txt
-rw-r--r-- 1 root root 6 Jul 6 18:13 text.txt
ll:ls -l的简写
[root@izwz94jtz9hbdq165vpxpxz app1]# ll
total 36
drwxr-xr-x 2 root root 4096 Jul 14 16:55 a
drwxr-xr-x 2 root root 4096 Jul 16 13:43 aa
drwxr-xr-x 2 root root 4096 Jul 16 13:47 b
drwxrwxrwx 4 root root 4096 Jul 10 13:29 bak
drwxr-xr-x 2 root root 4096 Jul 16 13:47 c
drwxr-xr-x 2 root root 4096 Jul 16 13:47 d
drwxr-xr-x 4 root root 4096 Jul 4 22:56 test
drwxr-xr-x 4 root root 4096 Jul 10 09:35 www
drwxr-xr-x 2 root root 4096 Jul 10 13:02 zyp
3、mv:移动/重命名 文件或目录 (Move file)
(语法:mv 源文件 目标文件)
(1)目标文件不是目录,即重命名
如下是将app1文件夹内的a文件夹重命名为a1
(mv 原文件名 新文件名)
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app1
[root@izwz94jtz9hbdq165vpxpxz app1]# ls
a aa b bak c d test www zyp
[root@izwz94jtz9hbdq165vpxpxz app1]# mv a a1
[root@izwz94jtz9hbdq165vpxpxz app1]# ls
a1 aa b bak c d test www zyp
(2)目标文件是目录
- 单文件移动(mv 移动前文件 移动后文件路径)
[root@izwz94jtz9hbdq165vpxpxz ~]# mv /app1/www/text1.txt /app2/app21
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app2/app21
[root@izwz94jtz9hbdq165vpxpxz app21]# ls
text1.txt
- 多文件移动,使用 -t(含文件及文件夹)
[root@izwz94jtz9hbdq165vpxpxz www]# mv carina/ carina.tar.gz text1.txt text.txt -t /app2/app21
[root@izwz94jtz9hbdq165vpxpxz www]# cd /app2/app21
[root@izwz94jtz9hbdq165vpxpxz app21]# ls
carina carina.tar.gz text1.txt text.txt
**将文件text.tx、text1.txt、redis-3.0.7.tar.gz、a3文件夹移动到app2文件夹下的app21文件夹**
(文件夹后的/省去效果一样)
[root@izwz94jtz9hbdq165vpxpxz www]# mv -t /app2/app21 text.txt text1.txt redis-3.0.7.tar.gz a3/
(3)将上级目录的文件 拷贝到当前目录 (mv …/文件名 ./)
提示:./ 和…/ 都是相对地址,./ 是当前目录,…/是上一级目录
[root@izwz94jtz9hbdq165vpxpxz app1]# ls
file2.txt file3.txt file4.txt file.txt
[root@izwz94jtz9hbdq165vpxpxz app1]# cd www
[root@izwz94jtz9hbdq165vpxpxz www]# ls
test text1.txt text3.txt text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# mv ../file.txt ./
[root@izwz94jtz9hbdq165vpxpxz www]# ls
file.txt test text1.txt text3.txt text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cd ..
[root@izwz94jtz9hbdq165vpxpxz app1]# ls
file2.txt file3.txt file4.txt
4、mkdir:创建目录(Make directory )
(需注意相对路径和绝对路径)
(1)在目录名前没有加任何路径名,则在当前目录下创建
[root@izwz94jtz9hbdq165vpxpxz ~]# mkdir a
(2)在目录名前有一个已经存在的路径,将会在该目录下创建
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app1
[root@izwz94jtz9hbdq165vpxpxz app1]# mkdir aa
(3)创建多级目录及多文件夹,使用 -p(文件夹之间用空格隔开)
(若上层目录没找到,则会一并创建)
绝对路径:
[root@izwz94jtz9hbdq165vpxpxz app2]# mkdir -p /app2/a1 b1 c1 d1
[root@izwz94jtz9hbdq165vpxpxz app2]# ls
a1 b1 c1 d1
相对路径:
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app1/www
[root@izwz94jtz9hbdq165vpxpxz www]# mkdir -p carina/a1 carina/a2 carina/a3
[root@izwz94jtz9hbdq165vpxpxz www]# cd carina
[root@izwz94jtz9hbdq165vpxpxz carina]# ls
a1 a2 a3
若不使用 -p,文件夹创建会失败
[root@izwz94jtz9hbdq165vpxpxz ~]# mkdir test/test1 test2 test3
mkdir: cannot create directory ‘test/test1’: No such file or directory
(4)创建多级目录,也可以使用 --parents
[root@izwz94jtz9hbdq165vpxpxz ~]# mkdir --parents /a2/a
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /a2
[root@izwz94jtz9hbdq165vpxpxz a2]# ls
a
(5)创建带权限的文件夹,使用 -m
- 目录已存在,创建成功
[root@izwz94jtz9hbdq165vpxpxz ~]# mkdir -m 700 /a2/a/aa
(文件属主拥有读、写和执行权限,其他人无权访问)
- 目录不存在,创建失败
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /a2
[root@izwz94jtz9hbdq165vpxpxz a2]# mkdir -m 700 /a3/a/aa
mkdir: cannot create directory ‘/a3/a/aa’: No such file or directory
此时需要使用 -p-m
[root@izwz94jtz9hbdq165vpxpxz ~]# mkdir -p -m 700 /a3/a/aa
注意事项:
在创建目录时,应保证新建的目录与它所在目录下的文件没有重名
[root@izwz94jtz9hbdq165vpxpxz app1]# mkdir a
mkdir: cannot create directory ‘a’: File exists (已有文件夹存在)
5、cat:显示文件的内容 (Concatenate)
(1)输出多个文件内容
cd /home
touch test.txt
vim test.txt
a
hello world
hello liunx
Esc
shift+:
:wq!
hello linux
/home
test.txt --hello wrold
test2.txt --hello java
test3.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cat text1.txt text.txt
hello world /*text1.txt内容*/
dgdfgfhfdgh /*text.txt内容*/
(2)将2个文件合并新文件
[root@izwz94jtz9hbdq165vpxpxz www]# cat text1.txt text.txt > text2.txt
[root@izwz94jtz9hbdq165vpxpxz www]# ls
text1.txt text2.txt text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cat text2.txt
hello world
dgdfgfhfdgh
注:若新文件有内容,则原数据会被清空,因此需要小心操作
[root@izwz94jtz9hbdq165vpxpxz www]# cat text2.txt
testtesttedgdkljsdhfkld
[root@izwz94jtz9hbdq165vpxpxz www]# cat text1.txt text3.txt > text2.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cat text2.txt
hello world
hihihihihihi
(3)将file1.txt追加到file2.txt的末尾
cat file1.txt >> file2.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cat text2.txt
gdgdg
[root@izwz94jtz9hbdq165vpxpxz www]# cat text1.txt >> text2.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cat text2.txt
gdgdg
hello world
(4)文件夹不能合并
[root@izwz94jtz9hbdq165vpxpxz app1]# ls
a1 a2
[root@izwz94jtz9hbdq165vpxpxz app1]# cat a1 a2 a3
cat: a1: Is a directory
cat: a2: Is a directory
cat: a3: No such file or directory
6、find:在指定目录下查找文件
find 目录 参数
(1)单文件匹配
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/www -name "*.txt"
/app1/www/root/carina/a/test.txt
/app1/www/text3.txt
/app1/www/text1.txt
/app1/www/text.txt
(2)多文件匹配
目录下以.txt结尾的文件、含字母a的文件 : 使用 -o
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/www -name "*.txt" -o -name "*a*"
/app1/www/a2
/app1/www/root/carina
/app1/www/root/carina/a
/app1/www/root/carina/a/test.txt
/app1/www/text3.txt
/app1/www/text1.txt
/app1/www/text.txt
/app1/www/carina
/app1/www/carina/aa
/app1/www/carina/carina
/app1/www/carina/carina/a2
/app1/www/carina/carina/a1
/app1/www/carina/carina/a3
(3)查找除XX外的
**使用 “!” or “-not” **
如查找app1文件夹下www文件夹,文件名不含a
find /app1/www ! -name "*a*"
查找当前目录下 文件不含a的信息
[root@izwz94jtz9hbdq165vpxpxz ~]#find /app1/www -maxdepth 1 -not -name "*a*"
(4)查找文件,忽略大小写
使用 -i
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1 -iname "*test*"
/app1/www/a2/test
/app1/www/test
/app1/TEST /*大写文件夹*/
(5)只查找某层目录下含XX的文件(夹)
使用 mindepth 和 maxdepth
“-maxdepth 1” :限制只查找1层目录深度,当前目录即为1层
查找当前目录下,含test的文件及文件夹
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1 -maxdepth 1 -name "*test*"
/app1/test1.txt
/app1/zyptest
/app1/test
如下 “ /app1/www/ ” 即为1层目录深度
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/www -maxdepth 1 -name "*test*"
/app1/www/test
查找当前目录 及其 1层深的子目录中,含test的文件及文件夹,即 maxdepth 2
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1 -maxdepth 2 -name "*test*"
/app1/www/test
/app1/test1.txt
/app1/zyptest
/app1/test
在第1层子目录和第2层子目录之间查找文件(第一层子目录就是2层目录)
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1 -mindepth 2 -maxdepth 3 -name "*test*"
/app1/www/a2/test
/app1/www/test
(6)查找空文件(-empty)
只列出当前目录下的非隐藏空文件
[root@izwz94jtz9hbdq165vpxpxz ~]#find . -maxdepth 1 -empty -not -name ".*"
查找指定目录下的所有目录 -type d
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/www -type d
/app1/www
/app1/www/a2
/app1/www/a2/test
/app1/www/root
/app1/www/root/carina
/app1/www/root/carina/b
/app1/www/root/carina/a
/app1/www/carina
/app1/www/carina/aa
查找指定目录下的所有文件 -type f
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/www -type f
/app1/www/root/carina/config.xml
/app1/www/requests-2.18.1.tar.gz
/app1/www/text.txt
/app1/www/123.jgp
7、pwd:以绝对路径的方式显示用户当前工作目录
Print working directory
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app1/www
[root@izwz94jtz9hbdq165vpxpxz www]# pwd
/app1/www
8、rm -参数:删除N个文件或整个目录
使用rm命令要格外小心。因为一旦删除了一个文件,就无法再恢复。建议用-i选项,删除时会有提示
相对路径:
[root@izwz94jtz9hbdq165vpxpxz www]# rm -i text2.txt
rm: remove regular file ‘text2.txt’? /*回车键不删除,效果同输入n*/
[root@izwz94jtz9hbdq165vpxpxz www]# ls
text2.txt text3.txt text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# rm -i text2.txt
rm: remove regular file ‘text2.txt’? y /*文件删除成功*/
[root@izwz94jtz9hbdq165vpxpxz www]# ls
text3.txt text.txt
绝对路径:
[root@izwz94jtz9hbdq165vpxpxz www]# rm /app1/c/text1.txt
rm: remove regular file ‘/app1/c/text1.txt’? y
[root@izwz94jtz9hbdq165vpxpxz www]#
注:rm不能删除文件夹
[root@izwz94jtz9hbdq165vpxpxz /]# rm app3
rm: cannot remove ‘app3’: Is a directory
rm -r(
或rm -R):删除当前目录下除隐含文件外的所有文件和子目录
应注意,这样做是非常危险的!
[root@izwz94jtz9hbdq165vpxpxz app21]# ls -a
. .. a3 redis-3.0.7.tar.gz text1.txt
[root@izwz94jtz9hbdq165vpxpxz app21]# cd ..
[root@izwz94jtz9hbdq165vpxpxz app2]# rm -r app21
rm: descend into directory ‘app21’? y /*输入y删除*/
rm: remove regular empty file ‘app21/text1.txt’? y
rm: descend into directory ‘app21/a3’? y
rm: remove regular empty file ‘app21/a3/a3.png’? y
rm: remove regular empty file ‘app21/a3/a3.txt’? y
rm: remove directory ‘app21/a3’? y
rm: remove regular empty file ‘app21/redis-3.0.7.tar.gz’? y
rm: remove directory ‘app21’? y
[root@izwz94jtz9hbdq165vpxpxz app2]# ls -a
. ..
rm -®f:强制删除,f 可理解为force
[root@izwz94jtz9hbdq165vpxpxz ~]# cd /app1/aa
[root@izwz94jtz9hbdq165vpxpxz aa]# ls
aa1
[root@izwz94jtz9hbdq165vpxpxz aa]# cd ..
[root@izwz94jtz9hbdq165vpxpxz app1]# rm -rf aa
[root@izwz94jtz9hbdq165vpxpxz app1]#
删除某个目录下所有带有test的文件夹及文件
- 结合find命令删除:
find 目录 -name "*file*" -exec rm -rf {} \;
语法解析
-exec 找到后执行命令execute
rm -rf {} 就是删除文件
\; 命令 属于格式要求的,没有具体含义
举例
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/ -name "*test*"
/app1/www/test1.txt
/app1/www/test
/app1/test.txt
/app1/zyptest
/app1/test
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/ -name "*test*" -exec rm -rf {} \;
find: ‘/app1/www/test’: No such file or directory /*文件已被删除所以会提示找不到*/
find: ‘/app1/zyptest’: No such file or directory
find: ‘/app1/test’: No such file or directory
[root@izwz94jtz9hbdq165vpxpxz ~]# find /app1/ -name "*test*"
[root@izwz94jtz9hbdq165vpxpxz ~]#
练习:
1.先进入cd /home
2. mkdir demo01
mkdir demo02
mkdir demo03
3.touch demo.txt
touch demo.png
touch demo.jpg
4.删除跟demo相关的文件或目录
find /home -name "*demo*" -exec rm -rf {} \;
9、touch:创建新的空文件
(用ls-l查看文件大小为0)
[root@izwz94jtz9hbdq165vpxpxz www]# touch text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# ls -l
total 0
-rw-r--r-- 1 root root 0 Jul 16 17:02 text.txt
批量创建文件
[root@izwz94jtz9hbdq165vpxpxz a1]# touch a{1..10}.text
[root@izwz94jtz9hbdq165vpxpxz a1]# ls
a10.text a1.text a2.text a3.text a4.text a5.text a6.text a7.text a8.text a9.text
10、cp:复制文件/目录(Copy file)
(1)默认情况下,cp命令不能复制目录
[root@izwz94jtz9hbdq165vpxpxz app1]# cp a1 /app2
cp: omitting directory ‘a1’
如果要复制目录,则必须使用-R选项
- 目标目录存在,直接复制
[root@izwz94jtz9hbdq165vpxpxz app1]# cp -R a1 /app2
[root@izwz94jtz9hbdq165vpxpxz app1]# find / -name "a1"
/app1/a1
/app2/a1
-
目标目录不存在,先自动创建目标目录再复制源目录
[root@izwz94jtz9hbdq165vpxpxz app1]# ls test www zyp [root@izwz94jtz9hbdq165vpxpxz app1]# cd www [root@izwz94jtz9hbdq165vpxpxz www]# ls 123.jgp a2 carina root text1.txt text3.txt text.txt [root@izwz94jtz9hbdq165vpxpxz www]# cp -R carina /app1/zyptest /*拷贝到不存在的目录*/ [root@izwz94jtz9hbdq165vpxpxz www]# cd .. [root@izwz94jtz9hbdq165vpxpxz app1]# ls test www zyp zyptest /*目录创建成功*/
练习:
1.复制文件
cd /home
touch copy.txt
-
创建一个目录app1
mkdir app1
cp copy.txt /home/app1
分别ls
/home
/home/app1
copy.txt
-
复制目录
app1
cd /home
cp -R app1 /root 查 ls /root
-
(2)复制文件
[root@izwz94jtz9hbdq165vpxpxz www]# cp text1.txt /app1/c
[root@izwz94jtz9hbdq165vpxpxz www]# find / -name "text1.txt"
/app1/www/text1.txt
/app1/c/text1.txt
绝对路径:
[root@izwz94jtz9hbdq165vpxpxz ~]# cp /app1/www/text1.txt /app1/c
(3)复制文件并重命名文件
如下将www文件夹下的text1.txt 复制到目录 /app1,并改名为text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cp text1.txt /app1/text.txt
(4)复制特定类型的文件
[root@izwz94jtz9hbdq165vpxpxz www]# ls
123.txt carina text1.txt text3.txt text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# cp t*.txt /app1/bak
[root@izwz94jtz9hbdq165vpxpxz www]# cd /app1/bak
[root@izwz94jtz9hbdq165vpxpxz bak]# ls
text1.txt text3.txt text.txt
复制前可能已经有文件存在了,那么不想进行每个选项都输入 y 确认的话,需要在 cp 前加 \,没有空格
[root@izwz94jtz9hbdq165vpxpxz www]# cp t*.txt /app1/bak
cp: overwrite ‘/app1/bak/text1.txt’? y
cp: overwrite ‘/app1/bak/text3.txt’? y
cp: overwrite ‘/app1/bak/text.txt’? y
[root@izwz94jtz9hbdq165vpxpxz www]# \cp t*.txt /app1/bak /*没有提示按y*/
[root@izwz94jtz9hbdq165vpxpxz www]#
11、vi:修改文件内容
先按键盘字母I,编辑内容后,保存(按esc键后输入:wq)
[root@izwz94jtz9hbdq165vpxpxz www]# vi text.txt
dgdfgfhfdgh
12、echo:创建/覆盖文件
(1)使用>覆盖指令
若文件不存在则创建文件
[root@izwz94jtz9hbdq165vpxpxz a1]# echo 'hello world' > hw.text
[root@izwz94jtz9hbdq165vpxpxz a1]# ls
hw.text
[root@izwz94jtz9hbdq165vpxpxz a1]# cat hw.text
hello world
(2)若文件存在,覆盖文件原内容并重新输入内容
[root@izwz94jtz9hbdq165vpxpxz a1]# cat hh.text
hello hello
[root@izwz94jtz9hbdq165vpxpxz a1]# echo 'hi hi' > hh.text
[root@izwz94jtz9hbdq165vpxpxz a1]# cat hh.text
hi hi
(3)使用 >>,向文件追加内容,原内容不变
[root@izwz94jtz9hbdq165vpxpxz a1]# cat hw.text
hello world
[root@izwz94jtz9hbdq165vpxpxz a1]# echo 'yeah yeah' >> hw.text
[root@izwz94jtz9hbdq165vpxpxz a1]# cat hw.text
hello world
yeah yeah
13、tar:文件打包、解压(Tape archive)
(1)文件打包:tar -zcvf 打包名 文件
[root@izwz94jtz9hbdq165vpxpxz www]# ls
123.txt a2 carina requests-2.18.1.tar.gz text1.txt text3.txt text.txt
[root@izwz94jtz9hbdq165vpxpxz www]# tar -zcvf text.tar.gz 123.txt a2 text1.txt
123.txt
a2/
text1.txt
[root@izwz94jtz9hbdq165vpxpxz www]# ls
123.txt a2 carina requests-2.18.1.tar.gz text1.txt text3.txt text.tar.gz text.txt
(2)文件解压:tar -zxvf 文件名
[root@izwz94jtz9hbdq165vpxpxz app1]# tar -zxvf text.tar.gz
语 法:grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][–help][范本样式][文件或目录…]
说明:查找文件里符合条件的字符串。grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为“-”,则grep指令会从标准输入设备读取数据。
参 数:
-a或–text 不要忽略二进制的数据。
-A<显示列数>或–after-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之后的内容。
-b或–byte-offset 在显示符合范本样式的那一列之前,标示出该列第一个字符的位编号。
-B<显示列数>或–before-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前的内容。
-c或–count 计算符合范本样式的列数。
-C<显示列数>或–context=<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作>或–directories=<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式>或–regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
-E或–extended-regexp 将范本样式为延伸的普通表示法来使用。
-f<范本文件>或–file=<范本文件> 指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。
-F或–fixed-regexp 将范本样式视为固定字符串的列表。
-G或–basic-regexp 将范本样式视为普通的表示法来使用。
-h或–no-filename 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H或–with-filename 在显示符合范本样式的那一列之前,表示该列所属的文件名称。
-i或–ignore-case 忽略字符大小写的差别。
-l或–file-with-matches 列出文件内容符合指定的范本样式的文件名称。
-L或–files-without-match 列出文件内容不符合指定的范本样式的文件名称。
-n或–line-number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
-q或–quiet或–silent 不显示任何信息。
-r或–recursive 此参数的效果和指定“-d recurse”参数相同。
-s或–no-messages 不显示错误信息。
-v或–revert-match 反转查找。
-V或–version 显示版本信息。
-w或–word-regexp 只显示全字符合的列。
-x或–line-regexp 只显示全列符合的列。
-y 此参数的效果和指定“-i”参数相同。
–help 在线帮助。
14:clear
说明:清除终端屏幕。
2.5.3课后作业
1.使用shell命令,查看根目录下所有文件
2.在根目录下创建文件myfile
3.使用shell命令“ls”,查看/src下的目录,解释每一行
4.练习课上所有常用命令
第三章 用户与组管理
3.1用户
Linux系统是一个多用户多任务的分时操作系统,
任何一个要使用系统资源的用户,
都必须首先向系统管理员申请一个账号,
然后以这个账号的身份进入系统。
用户的账号的作用:
-
一方面可以帮助系统管理员对使用系统的用户进行跟踪,
并控制他们对系统资源的访问; -
另一方面也可以帮助用户组织文件,
并为用户提供安全性保护。 -
每个用户账号都拥有一个唯一的用户名和各自的口令。
用户在登录时键入正确的用户名和口令后,
就能够进入系统和自己的主目录。
| 用户 | 一个户口本的户主 |
|---|---|
| 用户组 | 户口本中的其他成员 |
| 其他人 | 除用户本人(户主)和用户组(户口本中的成员)外的成员都是其他人 |
每一个用户都可以拥有多个用户组。
每一个用户组都可以容纳多个用户。
用户UID
在Linux系统中,每一个用户默认都对应了一个UID,
而这个UID可以理解是用户的身份证号。
CentOS系统中:
| UID 0 | root |
|---|---|
| UID 1-499 | 系统预留,作为系统用户来使用 |
| UID 500 - 65535 | 自定义账户 (注意,此处仅指的是CentOS6.5系统,其他系统的自定义账户则不一定是从500开始,例如Ubuntu系统是从1000开始。)CentOS7从1000开始 |
用户存储位置
| 用户信息 | /etc/passwd |
|---|---|
| 密码信息 | /etc/shadow |
| 用户组信息 | /etc/group |
passwd、shadows、group这三个文件不要随意的进行修改,如果想要进行文件内容的查看,建议大家copy出一份,对copy的文件进行修改。
或
把文件copy出来之后,进行保存,再去修改原文件。这样做即便是写错了文件也可以通过单用户的方式将文件恢复。
3.1.1创建用户
useradd [选项] UserName
参数
useradd tom 表示以默认方式创建tom用户,用户组名也是tom。
3.1.2 修改用户名
只修改登录名没有修改用户目录
usermod -l 新用户名 老用户名
即修改登录又修改用户目录
usermod -l 新用户名 -d /home/新用户名 -m 老用户名 :(英文L)
案例:
修改用户gm,指定他属于主用户组"tom1",附加组“apache、root”,登 录使用的shell是/bin/bash
创建用户gm,指定他属于主用户组“jerry”,附加组“adm、root”,登录 使用的shell是/bin/sh
useradd -g jerry -G adm,root -s /bin/sh gm
usermod -g tom1 -G apache,root -s /bin/bash gm
3.1.3 删除用户
userdel [选项] UserName
-r 表示在删除用户的同时,也删除用户的家目录
案例:
userdel tom 表示删除用户tom
userdel -r tom 表示删除用户tom和家目录
其他命令
usermod -g 组名 用户名** :修改用户的组
usermod -aG 组名 用户名** :将用户添加到组
groups test** :查看test用户所在的组
cat /etc/group |grep test** :查看test用户详情:用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
3.1.4 修改密码(如果root用户密码忘了怎么办?)
passwd [选项] 用户名** :用户改自己密码,不需要输入用户名,
选项
| -l | 锁定用户密码 |
|---|---|
| -u | 解锁用户密码 |
| -d | 删除用户密码 |
passwd 直接回车的情况下,表示修改当前用户的密码
passwd UserName 表示修改此用户的密码
管理员修改他人的密码,不需要满足密码策略。
普通账户修改密码时,必须满足密码安全策略。
3.1.5 用户切换
-
su - 用户名:完整的切换到一个用户环境(相当于登录)(建议用这个)(退出用户:exit)
-
su 用户名 :切换到用户的身份(环境变量等没变,导致很多命令要加上绝对路径才能执行)
-
sudo 命令 :以root的身份执行命令(输入用户自己的密码,而su为输入要切换用户的密码,普通用户需设置/etc/sudoers才可用sudo)
su {UserName} 表示切换用户之后,依然停留在当前目录 su - {UserName} 表示切换用户之后,去到该用户的家目录
3.2 用户组
3.2.1 创建用户组
语法:groupadd [选项] {groupName}
选项:
| -g GID | 指定新用户组的GID |
|---|---|
| -o | 通常与-g同时使用,使新用户组可以与系统已有的组ID系统。 |
系统底层会将两个GID相同用户组识别为同一个用户组,这样做的目的是让两个用户组的权限相同。识别规则,后者遵循前者。
案例: 新建一个用户组
#groupadd group1
此命令向系统中增加了一个新组"group1"
新组的组标识号,在当前已有的最大组标识号的基础上加1
# groupadd -g 101 group2
此命令向系统中增加了一个新组group2,
同时指定新组的组标识号是101。
创建一个普通的用户组,并将该组添加为tom账户的附加组
usermod -aG group1 tom
创建一个与上面案例GID相同的用户组
groupadd -g 1000 -o group2
-
groupdel 用户组 :删除组
语法:groupdel {groupName}
案例:
groupdel big1902注:
如果删除的用户组,已经被用户追加为附加件组,对应的所有用户的该附件组会被撤销掉。
如果被删除的用户组,已经被用户指定为主组,则该用户组无法被删除。(可以理解为像Windows中文件被占用时不能被删除。)
-
groupmod :修改用户组
语法:groupmod [选项] {groupName}
选项:
-g GID 指定新用户组的GID -o 通常与-g同时使用,使新用户组可以与系统已有的组ID系统。 -n 用来修改组ID groupmod -n newGroupName oldGroupName 案例:
将组group2的组标识号修改为102。
# groupmod -g 102 group2
新建一个group3,并将其组名修改成big1902
# bash
groupadd group3
groupmod -n big1902 group3
练习:
1.创建一个新的用户组 g1
2.创建一个新的用户组g2并指定其GID为555 (-g)
3.将g2用户组的GID改为777
4.将g1用户组的名改为king (-n)
5.将两个(king、g2)组删掉。
3.3.权限管理
在Linux系统对于权限的设定非常的敏感,如果某个用户执行一个操作时,提示权限不足,那么根据Linux系统的权限设定的思想(没有权限绝对不会睁一只眼闭一只眼),就能够判断出该用户不具备此文件的执行权限。
在Linux系统中,有以下的权限表示。业内人士称之为:
-
逻辑权限
-
物理权限
-
普通用户的root的权限。
逻辑权限:
在Linux系统中不管是文件还是目录。(在Linux系统中,将所有的东西都视为文件。)都有固定权限表示。
例:
drwxr-xr-x. 2 root root 4096 5月 13 15:27 home
-rw-r–r--. 1 root root 45537 5月 13 11:15 install.log
两个文件分别是:第一个是目录,第二个是普通文件
根据信息的第一个字母(文件类型)来查看,d表示该文件是一个目录文件,-表示该文件是一个普通文件。
后面每三个权限成为一组,每组中分别有三个权限:
字符 权限 数字 r 读 4 w 写 2 x 执行 1 除了第一个字母不参与权限的表示,其他的都为权限标识符。
每三个为一组,共有三组:
第一组 用户 user 第二组 用户组 group 第三组 其他人 other 说明:Linux系统中,不管是什么系统,权限的标识符号的位置是不会发生任何的改变,也就是说,
第1个永远是文件类型
第2-4(第一组)永远是读、写、执行,用户的权限
第5-7(第二组)永远是读、写、执行,用户组的权限,
第8-10(第三组)永远是读、写、执行,其他人的权限
如果某个文件权限标识为----------,那么则说明此文件不允许任何的读取、写入、执行
修改文件/夹的权限:
chmod命令可以用来修改某个文件或文件夹的权限。
选项
-R 递归处理 修改文件/夹的权限时,可以使用字符权限,也可以使用数字权限。
案例:
touch test_1 # 当前文件的权限是-rw-r--r--将此文件的权限修改为----------
chmod 000 test_1为此文件,每组都增加一个读的权限
chmod 444 test_1 or chmod +r test_1 # a=all,u=user,g=group,o=other为此文件的用户增加一个rw-,组增加一个r-x,其他人—。
chmod u+rw,g+rx test_1 or chmod 650 test_10表示没有权限
chmod在修改文件权限的时候,哪个便捷用哪个方法。
比如:
如果要是给三组增加执行权限的时候,+x就数字计算要快。字符权限就比数字要便捷(不需要计算)
如果是为每组增加不同权限的时候,用数字比较便捷(书写便捷)。
物理权限:
修饰某个文件/夹不允许被修改。注意:不能给/ /tmp /dev /var 加保护
即便是root权限也不一定所有的文件都可以删
chattr [选项] file/dir
选项:
i 表示不能以任何方式进行文件/夹的修改,增加,删除 S 即时更新文件或 目录 s 保密性删除文件或目录 a 表示文件/夹只能追加,不能修改,删除 + <属性> 表示开启某文件/夹的权限 - <属性> 表示关闭某文件/夹的权限 R 表示递归处理。 案例:
touch big2021 chattr +i big2021 # 表示该文件不允许修改,删除,增加。测试指令:
echo "hello" > big2021 (>覆盖) echo "hello" >> big1902 (>>追加) 查看文件内容 cat big1902touch big2021 chattr +a big1902_1 # 表示该文件只允许追加内容,不允许删除和修改。a、i的使用场景:
通常情况,log文件用a的属性。如果是cfg(配置文件)文件用i的属性。
练习:
1.新建文件 4.txt
2.添加物理权限 不可以删除,不可以修改 ,不能添加
3.查看其物理权限
4.将其物理去除,可以追内容,删除内容,修改内容。
lsattr 查看文件的物理权限(属性)
lsattr [选项] 文件/夹
选项:
| R | 表示递归处理 |
|---|---|
| a | 表示查看所有文件的属性,包括隐藏 |
| d | 显示目录的属性,而不是目录下的文件的属性 |
chown修改所有者:
chown 所有者 目录/文件
chown 所有者:所属组 目录/文件
案例:
chown admin test1
#同时修改所属者和所属组
chown root:xiaoming test1(注意没有物理权限限定方可成功)
普通用户的超级权限:
sudo(SuperUser Do),它可以让普通用户执行root的权限。
sudo可以限制用户执行部分root的权限。
sudo会记录用户执行过的每一条命令,便于查阅服务起出事之前的状态。
好处:
使用自己配置好的用户环境
不需要知道root密码,保证root的密码安全
可以限制用户执行有限的root权限
sudo执行的每条命令都会被记录,便于日后的日志审计,例如用户执行过高危操作命令。
步骤:
vim /etc/sudoers
vim 指令 :set nu 显示行号
将98行复制,并修改为用户名为要给超级权限的用户
普通用户在使用root用户权限指令前加sudo指令
sudo service network restart
3.3磁盘管理
磁盘
Ext*、NTFS和FAT32这三个都是文件系统格式
Linux kernel自2.6.28开始正式支持新的文件系统Ext4
Ext4是Ext3的改进版,修改了Ext3中部分重要的数据结构
Ext3对Ext2,只是增加了一个日志功能
Ext4可以提供更佳的性能和可靠性,还有更为丰富的功能,更大的文件系统和更大的文件。
-
较之Ext3所支持的最大16TB文件系统和最大2TB文件,Ext4分别 支持1EB(1,048,576TB,1EB=1024PB,1PB=1024TB)的文件系统,以及16TB的文件。
无限数量的子目录
Ext3只支持32,000个子目录,而Ext4支持理论值的无限数量的子目录
-
延迟分配
Ext3的数据块分配策略是尽快分配,而Ext4是尽可能地延迟分配,直到文件在cache中写完才开始分配数据块并写入磁盘。
如此能优化整个文件的数据块分配,显著提升性能。
-
快速fsck(文件系统检查)
老的fsck会很慢,因为它要检查所有的索引节点(inode)
Ext4给每个组的索引节点表中添加了一份未使用inode的列表,执行fsck就可以跳过它们而只去检查那些在用的索引
-
持久预分配(Persistentpreallocation)
常常会预先创建 一个与所下载文件大小相同的空文件,以免未来的数小时或数天 之内磁盘空间不足导致下载失败。Ext4在文件系统层面实现了持久预分配并提供相应的API,比应用软件自己实现更有效率。
SWAP(交换分区)概述
/boot
/
swap 2048
使用磁盘来存储内存不够而“溢出来”的内容(拿硬盘空间来存储内存“溢出”的数据)。
当系统的物理内存不够用的时候,就需要将物理内存中的一部分 空间释放出来,以供当前运行的程序使用。
最容易成为被释放的对象:一些很长时间没有什么操作的程序。 –被 保存到Swap空间中。等到那些被换出的程序要继续运行时,再从Swap中恢复保存的数据到内存中。
一般来说可以按照如下规则设置swap大小:
8G以内的物理内存,SWAP 设置为内存的2倍。
8G-16G以内的的物理内存,SWAP 等于内存大小或者设置为8G。
16G-256G 的物理内存,SWAP 设置为实际内存的1/2即可。
系统什么时候会使用swap?
实际上,并不是等所有的物理内存都消耗完毕之后,才去使用 swap的空间,什么时候使用是由swappiness 参数值控制。
[root@localhost ~] cat /proc/sys/vm/swappiness
60
[root@localhost ~]
默认值是60。swappiness=0的时候表示最大限度使用物理内存 ,然后才是 swap空间,swappiness=100的时候表示积极的使 用swap分区,并且把内存上的数据及时的搬运到swap空间里面。
如何修改swap参数
临时性修改:
[root@localhost ~] sysctl vm.swappiness=10
[root@localhost ~] cat /proc/sys/vm/swappiness
10
这里我们的修改已经生效,但是如果我们重启了系统,又会变成60.
永久修改:
在/etc/sysctl.conf
文件里添加如下参数: vm.swappiness=10
磁盘相关指令:
df -h /var/log :(显示log所在分区(挂载点)、目录所在磁盘及可用的磁盘容量)!T
du -sm /var/log/* | sort -rn : 根据占用磁盘空间大小排序(MB)某目录下文件和目录大小
fdisk -l :查所有分区及总容量,加/dev/sda为查硬盘a的分区)
fdisk /dev/sdb :对硬盘sdb进行分区
3.4 挂载
为什么要挂载,因为文件系统并不能够直接使用。
Windows的文件系统需要盘符来表示
Linux的文件系统需要目录作为入口。
分区的格式就是文件系统。
挂载:
mount 文件系统 目录(挂载点)
案例:
挂载光盘镜像文件
# bash
mkdir /home/cdrom # 此处创建目录cdrom并不是非要这个名称,是因为想做到见名知意。
mount /dev/cdrom /home/cdrom
挂载U盘:
需要注意:U盘的格式如果为NTFS,那么需要安装一个插件之后才能够进行挂载,否则无法识别。
yum install ntfs-3g
如果是fat32的,那么可以直接进行挂载。
mkdir /home/udisk # 此处创建目录udisk并不是非要这个名称,是因为想做到见名知意。
lsblk # 用来查看文件系统
mount -o iocharset=utf8 /dev/sdb1 /home/udisk
上面的命令,其中 “-o iocharset=utf8” 是用于解决U盘挂载之后的字符乱码问题。
取消挂载:
umount 挂载点
可以通过df -h的命令查看当前文件系统的状态。如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P92xFvyF-1631443904889)(img\df-h.png)]
umount /home/udisk
无法取消挂载:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mtchwQne-1631443904890)(img\umount.png)]
图中出现的情况是由于当前root账户处于cdrom目录中,所以导致无法取消挂载。还有其他可能是由于别的用户或软件仍在使用该目录中的文件所导致。
3.5课后作业
1.什么是用户的工作目录
2.修改当前用户的密码
3.创建新的用户和用户组,并加入新的用户组
4.切换用户
5.挂在光盘镜像
6.挂在U盘
第四章 网络及web服务器配置
4.0VIM编辑器
什么是VIM:
是一个类似vi的文本编辑器,不过在vi的基础上增加了很多新特性,vim被公认为vi编辑器中最好用的一个。
为什么要学习VIM,vi不够?
vim在vi的基础之上增加了很多的小功能。可以有效的帮助程序员快速的排查问题。
很多系统都内建vi编辑器,其他的文本编辑器不一定有,很多软件都会主动调用vi的接口。
vim的三种模式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tbPl97ER-1631443904891)(\img\vimStatus.png)]
实例:
vim 1.txt 一般模式
i 进入编辑模式
Esc 一般模式
4.0.1一般模式:
h或←光标左移一个字符。如果是20h,表示左移20个字符。
L或→光标下移一个字符 同上
k或↑光标上移一个字符 同上
J或↓光标右移一个字符 同上
**注意:**必须在一般模式下进行2分钟练习。
[Ctrl]+[f]屏幕向下移动一页 Page Down!!
[Ctrl]+[b]屏幕向上移动一页 Page Up !!
1分钟练习
0或[Home]移动到此行最前面字符处!!
$或[End]移到光标所在行的行尾!!
1分钟感受
H 光标移到当前屏幕最上方行的第一个字符!!
M光标移到当前屏幕中间行的第一个字符!!
L光标移动到当前屏幕最下方行第一个字符!!
G移到此文件最后一行!!!
nG移到第n行(从0开始)
gg相当于1G,即移到第一行!!!
n[Enter]光标下移n行
2分钟练习
进入指令模式:
Shift+:
/word向下查找单词“word”(!!!)
?word向上查找单词“word”(!!!)
n表示重复前一个查找操作
N与n相反(反向查找)
yy复制光标所在行(!!)
nyy复制光标所在向下n行(n为数字)
y1G复制光标所在行到第一行所有数据
yG复制光标所在行到最后一行所有数据
y$复制光标所在处到同行最后一个字符
y0复制光标所在处到同行第一个字符
p将已复制的数据粘贴到光标所在下一行
P将已复制的数据粘贴到光标所在上一行
u复原前一个操作(类似于windows中的ctrl+z)!!!
Ctrl+r****恢复一个操作。
x向后删除一个字符
nx向后删除n个字符(n为数字)
X向前删除一个字符
dd删除光标所在行(!!!)
ndd删除光标所在行以下n行(n为数字,包含当前行在内)
d1G删除光标所在行到第一行所有数据(包括所在的行)
dG删除光标所在行到最后一行(!!)
d$或d end删除光标所在处到同行最后一个字符(!!)
d0或d home删除光标所在处到同行第一个字符。(!!)
练习:
在home目录下新建一个文件夹 homework.txt
通vim 编辑内容
张三 复制 粘贴三行 yy 复制当前行 p p p
再一次性的复制这四行 y4G 粘贴 合计8行
删除最后一行 dd
删除第一行 dd
4.0.2编辑模式:
进入编辑模式:
i从光标所在处插入(!!!)
I从所在行第一个非空白字符处插入(!!)
a从光标所在下一个字符处插入
A从光标所在行最后一个字符处插入(!!)
o在光标所在处下一行插入新的一行(!!)
O在光标所在处上一行插入新的一行(!!)
r替换光标所在处字符一次
R一直替换光标所在处文字直到按下Esc(!!!)
4.0.3命令模式:
如何进入命令模式:
| : ? / | 三个符号任意都可以进入命令模式 |
|---|---|
:w [filename] 另存为filename
:r [filename] 读取filename指定文件中的内容到光标所在的行。
:n1,n2 w [filename] 将n1到n2行另存为filename
:! command(命令) 临时切换到命令行 模式下执行command命令。
例如 “:!find / -name Helllo.java”即可在vim当中执行命令。
:wq 保存后离开
:q 不保存离开(未改可以离开,如果修改了需要q!强制离开)
:q! 不保存离开
:set nu 显示行号 (number)
:set nonu 取消显示行号 (noNumber)
练习:
自己创建一个文本文档 4.txt touch 4.txt
vim 4.txt
按 i
编辑:“姓名+兴趣爱好”
:w my.txt
:wq
里面键入自己的姓名+兴趣爱好 i 编辑
将里面的内容另存为 my.txt文档中。:w my.txt
在创建一个文本文档,you.txt touch you.txt
同桌名和他的优点 i ,
下面键入my.txt的内容。 :r my.txt
set nu
set nonu
/word1/word2/g 在当前行将word1替换成word2(!!)
:%s /word1/word2/g 在当前文件将word1替换成word2(!!)
:n1,n2 s /word1/word2/g在n1到n2行查找word1替换成word2 (n1、n2为数字)
:0,$ s/word1/word2/g从第一行到最后一行查找word1替换成word2
:% s/word1/word2/gc 同上,在替换前确认是否替换。(!!!)只能单行确认,需要逐个确认。
替换为 b (y/n/a/q/l/E/Y)?
y表示yes,n表示no,a表示all(限光标当前到最后一行),q表示quit,l表示替换后移动光标到行首,E(Ctrl+E)表示向下翻,y(Ctrl+Y)表示向上翻。
4.1网络配置
交换机:组建的是内网 本地网络
路由器:负责转发内网中的数据到公众网络(互联网)中。
ip地址:
192.168.0.2 computer2
192.168.0.3 computer1
192.157.0.4 computer3
分为:网络位+主机位 相同的网络,网络位肯定相同,主机位不一样 不同的网络,网络位肯定不同,主机位可能一样
例:网络位可以理解为是电话的区号。
主机位可以理解为是电话号码。
029 - 8888888
0911-8888888
子网掩码:
唯一作用是用来划分IP地址中的网络位和主机位。
网关:指的是一个网络的的出口,所有访问互联网的数据都要通过此出口,该出口是一个IP地 址,通常也指网络环境中的路由器。
DNS:域名解析系统
工作中一般对网络安全要求过高的公司会使用公司自己的搭建的DNS服务器。 如果没有特殊要求的情况下,一般使用通用的DNS服务区。国内使用114.114.114.114,国 外使用8.8.8.8
虚拟机的几种连接方式:
桥接网络:
| 优点 | 同一个网络内的任意一台主机只要拥有账户密码,都可以对其进行访问 |
|---|---|
| 缺点 | 占用物理环境中的ip地址,且宿主主机更换网络后,虚拟机也必须要手动调试网 络 |
NAT网络:
| 优点 | 不需要使用物理环境中的IP地址,并且无视宿主主机的网络环境 |
|---|---|
| 缺点 | 外部主机(除宿主主机外的所有主机)想要访问虚拟机的时候比较麻烦。需要做端 口的映射。并且有可能会收到防火墙的干扰 |
仅主机网络:
仅宿主主机可以访问。
免密登录:使用的是RSA非对称加密算法生成的公/私钥对儿证书。
| 公钥负责加密内容 | 天王盖地虎 |
|---|---|
| 私钥负责解开加密 | 小鸡炖蘑菇 |
4.1.0 启动网卡
CentOS系统的一个小特点:
安装完成之后,系统启动时,默认不会启动网络连接,需要手动开启。
启动网卡:
ifup eth0
ifup ens33
表示启动CentOS系统中名为eth0的网卡。
设置CentOS的网卡开机自启:
vi /etc/sysconfig/network-scripts/ifcfg-eth0
vi /etc/sysconfig/network-scripts/ifcfg-ens33
火狐浏览器:免费而且是CentOS默认浏览器(下载)*
360浏览器:可以卸载了
谷歌:
Chrome: 下载*
IE:*
注释:
| vi | linux系统内核自带的文本编辑器 |
|---|---|
| etc | Linux系统中所有的配置文件存放目录 |
| sysconfig | 系统配置文件的存放目录 |
| network-scripts | 网络配置文件的存放目录 |
| ifcfg-ens33 | 具体的网卡配置文件 ifconfig:用来查看当前系统的网络连接,类似于Windows的ipconfig |
修改文件内容:
按下键盘的"i",进入到了编辑模式,通过方向键移动到该行,将内容修改:
ONBOOT=no ==> ONBOOT=yes
按键盘esc键,退出编辑模式。输入":wq",保存退出。如果不想保存,可以输入q!,来强制退出。
以上操作就是完成了CentOS系统的网卡开机自启。
网络地址相关
配置网络的时候需要配置哪些信息:
| IP地址 | PC在网络中的通信地址。 |
|---|---|
| 子网掩码 | 子网掩码有且只有这一个功能,用于划分网络,将一个IP地址中的网络位和主机位进行划分。 是一个32位的地址。 |
| 网关 | 网络的关口,用于数据转发,通常理解为路由器的地址, 大部分硬件厂家的出厂默认地址是,192.168.0.1 | 192.168.1.1 |
| DNS | 用于解析域名的作用,Domain Name System 域名解析系统。 |
IP地址分析
IP地址=网络位+主机位
相同的网络,网络位肯定相同,主机位不一样
不同的网络,网络位肯定不同,主机位可能一样
比如:电话号码
网络 主机
北京:010-88889999
上海:021-12345678
021-88889999
在网络中,一般来说.0这个IP被用来当作网段的标识。
255这个IP被用来当作广播地址使用,正常使用的IP范围中,
其中一个IP地址要被拿来当作网关(路由器)使用。
一个网络中有多少个IP地址,取决于子网掩码。
比如:家用网络中,一般都是
192.168.1.2-254
255.255.255.0 24位 255.255.0.0 16位 255.0.0.0 8位
192.168.1.1
其中,192.168.1.2-254为主机IP地址。255.255.255.0子网掩码(用于划分网络,子网掩码可以计算IP地址的数量。)。
192.168.1.1作为网关使用。
192.168.1.0用来表示网段。
案例:
公司建立机房,决定投资建设10000台服务器的机房,那么设计网络时,掩码应该如何设计,网关应该如何设计。
16位掩码有效IP地址65534个。完全可以满足10000台服务器的需求。
网关建议大家紧贴广播地址。当前这个网络中,网关地址是192.168.255.254。
网络传输过程:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IADv8NyX-1631443904893)(img\网络传输过程.png)]
DNS:
域名系统(Domain Name System,DNS)是
Internet上解决网上机器命名的一种系统。就像拜访朋友要先知道别人家怎么走一样,Internet上当一台
主机要访问另外一台主机时,必须首先获知其地址,
TCP/IP中的
IP地址是由四段以“.”分开的数字组成(此处以IPv4的地址为例,IPv6的地址同理),记起来总是不如名字那么方便,所以,就采用了
域名系统来管理名字和IP的对应关系。
静态:
| 优点 | 可以使我们PC/服务器有一个更快的解析速度。维护方式是手动配置服务器上/etc/hosts文件。 |
|---|---|
| 缺点 | hosts一般都是为本机系统所有,维护一台服务器还好说。 如果是上千台集群,那么维护的工作很困难 |
动态:
| 优点 | 只需要给服务器指明DNS服务器地址即可,无需手动配置hosts文件 |
|---|---|
| 缺点 | 有一定响应时间,(延迟)。若DNS服务器宕机,那么我们就立即失去访问域名的能力。 |
4.1.1 设置静态IP
为什么要设置一个静态IP:
服务器拥有一个静态IP是因为方便客户端的访问和提供服务,企业中的所有服务器都是一个固定IP(静态IP)地址。
设置静态IP:
Centos下的网卡设置是在 vim /etc/sysconfig/network-scripts/ifcfg-ens33这个文件夹下,进入该文件夹,前缀为ifcfg-后面跟的就是网卡的名称。
默认的话是开启dhcp(动态自动分配IP)的,首先把BOOTPROTO="dhcp"改成BOOTPROTO="static"表示静态获取。之后在写进以下配置:
IPADDR=192.168.87.6 10.172.111.221
NETMASK=255.255.255.0
GATEWAY=192.168.87.2
DNS1=192.168.87.2
114.114.114.114
8.8.8.8
BROADCAST设置的是局域网广播地址,IPADDR就是静态IP,NETMASK是子网掩码, GATEWAY就是网关或者路由地址,DNS就是域名系统地址, 这里用的就是本地网关,也可以设置其它,比如谷歌、360DNS地址。
systemctl restart network //重启网络服务
ip addr或者ifconfig //查看ip地址
service network restart
或
/etc/init.d/network restart
上述两条命令都能实现网络服务的重启。需要注意当前账户是否有执行权限。
4.1.2 NAT和桥接
桥接:
| 优点: | 同一个局域网中的任意一台物理机想要访问虚拟机时, 只要拥有账户和密码,就可以直接进行通信。 |
|---|---|
| 缺点: | 如果宿主主机没有连接网络,那么虚拟机也就不存在与该真实网络环境中,换句话, 虚拟机使用桥接模式的时候,它的网络依赖于宿主的网络环境。 ip不够用 |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l8c0Znsl-1631443904895)(D:\tarena\延职院\讲义\img\qiaojie.png)]
NAT:
| 优点: | 可以无视物理机(宿主主机)网络环境。即便是物理机没有网络,也不影响本机和虚拟机进行通信,也不影响本机上的其他虚拟机之间互相通信。 NAT模式。真正和互联网通信的网卡是VMnet8(192.168.245.2), VMware network Adapter VMnet8它是本机用来和虚拟级进行通信:例如通过本地xshell连接我们的虚拟机 |
|---|---|
| 缺点: | 其他物理机想要访问NAT模式下的虚拟机时,比较麻烦。 |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zf2DIA9E-1631443904896)(D:\tarena\延职院\讲义\img\nat.png)]
4.1.3 找不到设备eth0
vim /etc/sysconfig/network-scripts/ifcfg-eth0
删除 UUID 和 HWADDR保存退出
修改本机名
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=newName
但是默认还是使用eth1,所以我们要切换到eth0
rm -rf/etc/udev/rules.d/70-persistent-net.rules
重启后生效:
reboot
4.1.4 远程拷贝
通过域名查看IP:
host www.baidu.com
返回的结果中有该域名的IP地址。
远程拷贝:
从本机拷贝数据到远程的服务器上
要求:必须知道对方的账户和密码,且具备相应的权限。
语法:scp [-r] [path]/fie | dir {UserName}@Host_IP:/[path]
| -r | 该选项用于传输文件夹的时候使用。 |
|---|---|
案例:
将本机的文件拷贝到远程服务器上
scp /root/install.log [email protected]:/home
注意, 如果是第一次访问该服务器,那么会询问,是否要继续连接。每次访问都需要输入远程服务器的密码。
从远程服务器上拷贝数据到本机:
要求:必须知道对方的账户和密码,且具备相应的权限。
语法:scp {UserName}@Host_IP:/[path]/file /[path]
案例:
将远程服务器中/home目录下的install.log拷贝到本地的root目录下
scp [email protected]:/home/install.log /root
4.1.5 登录远程服务器:
语法:ssh {UserName}@Host_IP
回车之后,如果首次访问,会提示是否继续连接。接下来要求输入远程服务器的密码。
案例:
ssh [email protected]
如果想退出当前登录
exit
Linux系统下,ssh服务的默认端口是22。如果在访问时没有指明端口,
默认按照22端口访问,如果远程服务器,提供的端口不是22,
那么就需要在访问的时候指定远程服务器的端口:
ssh [-p port] {UserName}@Host_IP
4.1.6 免密登录
Linux免密登录使用的RSA算法。
RSA本身是一种非对称加密算法,会生成公钥和私钥。
| 公钥 | 使用公钥对内容进行加密 | 天王盖地虎 |
|---|---|---|
| 私钥 | 持有私钥的PC才能正常访问公钥加密的内容 | 宝塔镇河妖 |
只要持有私钥就能访问公钥加密的内容,这种事情本身就是存在风险的。
一旦私钥丢失,那么服务器上的数据就存在被窃取的风险。
但是Linux生成公钥和私钥的时候支持对私钥证书文件添加密码。
证书使用场景:
场景一:只是单纯的使用证书来登录服务器。
使用证书的登录方式可以避免密码遗忘、泄漏的问题。
使用证书登录服务器的方式也是服务器加固(服务器安全相关问题)的方式。
服务器可以设置不允许使用密码进行远程登录。只允许证书的方式登录。
证书本身支持加密,就算证书丢失,再不知道证书密码的情况,证书属于无效文件。
**场景二:**集群中使用证书进行免密登录。
因为但凡设计到集群的时候,一般都不会是小数目的服务器数量。众多的服务器之间进行互相访问,频繁的输 入密码的事情将会成为开发工程师噩梦。
所以,使用证书管理集群的时候,可以免除集群中的服务器互相访问时工程师手工输入密码的问题。
证书的生成:
ssh-keygen
第一次提示:你的证书文件存放位置
第二次提示:对私钥加密,输入密码。如果不需要输入密码,直接回车。
第三次提示:私钥证书的密码确认操作。
证书文件会存放在当前账户的家目录下的隐藏目录".ssh"目录下,在该目录下会有以下4个文件:
| id_rsa | 私钥 | 执行证书生成命令才会有 |
|---|---|---|
| id_rsa.pub | 公钥 | 执行证书生成命令才会有 |
| known_hosts | 曾经访问过的服务器信息 | 每次ssh、scp、ssh-copy-id到远程服务器时就会保存记录到此文件中,以后再此访问该服务器时就不会再提示那一句"你确定要继续访问吗 yes/NO?" |
| authorized_keys | 记录来访服务器的公钥文件内容 | 该文件会记录访问本机的远程服务器的公钥证书文件内容,只有对应的私钥才能进行验证。 |
证书注册:
将本机的公钥证书文件注册到远程服务器上,此后就可以使用私钥证书进行登录。
ssh-copy-id {UserName}@Host_IP
执行此命令,会要求输入远程服务器的对应账户的密码。
这一步就是向远程服务器注册本机的id_rsa.pub文件(公钥)内容。此后只有本机上与公钥文件共同生成的私钥才能够进行免密登录。
配置两台服务器通过hostname进行连接
1.hostname Hadoop001
2.vim /etc/sysconfig/network -->HOSTNAME-Hadoop001
3./etc/hosts
scp /etc/hosts [email protected] /etc
hosts文件修改
| 192.168.41.20 | hadoop001 |
|---|---|
| 192.168.41.4 | hadoop002 |
4.1.7Linux防火墙
它具备一定的防护功能,比如说端口的开放和禁止,也可做数据的转发(类似路由功能),策略及其他功能。
临时处理防火墙:如果系统重启,那么防火墙将恢复到之前的状态。
| 开启 | service iptables start or /etc/init.d/iptables start |
|---|---|
| 关闭 | service iptables stop or /etc/init.d/iptables stop |
| 重启 | service iptables restart or /etc/init.d/iptables restart |
| 查看 | service iptables status or /etc/init.d/iptables status |
查看防火墙的状态CentOS7
firewall-cmd --state
关闭防火墙
systemctl stop firewalld.service
启动
systemctl starte firewalld.service
永久处理防火墙:(需重启系统后才能生效)
| 开启: | chkconfig iptables on |
|---|---|
| 查看状态 | chkconfig iptables --list |
| 关闭: | chkconfig iptables off |
centOS7
永久处理防火墙开机禁用自启命令
systemctl disable firewalld.service
4.2 web服务器配置
4.2.0 下载工具wget
wget
用于从网络上下载资源,没有指定目录,下载资源默认存储到当前目录。
wget [参数] [URL地址]
–支持断点下载功能
–同时支持FTP和HTTP下载方式
–支持代理服务器
使用wget下载单个文件
wget http://www.tedu.cn
使用wget -O下载并以不同的文件名保存
wget -O NewName.new http://www.tedu.cn
使用wget --limit-rate限速下载(单位,byte/秒)
wget --limit-rate=300k http://mirrors.hust.edu.cn/apache/httpd/httpd-2.4.46.tar.bz2
使用wget -c断点续传
wget -c http://mirrors.hust.edu.cn/apache/httpd/httpd-2.4.25.tar.bz2
使用wget -b后台下载
wget -b [http://mirrors.hust.edu.cn/apache//httpd/mod_fcgid/mod_fcgid-2.3.9.tar.gz
wget [http://mirrors.hust.edu.cn/apache//httpd/mod_fcgid/mod_fcgid-2.3.9.tar.gz
使用wget -i下载多个文件
wget -i urlfile.txt # urifile文件名称仅仅为了见名知意。
urlfile.txt内容为
http://www.tedu.cn
http://big.tedu.cn/index.html
4.2.1压缩和打包概念
压缩:
指通过某些算法,将文件尺寸进行相应的缩小,同时不损失文件的内容。
打包:
指将多个文件(或目录)合并成一个文件,方便传递或部署。
在Linux系统中,文件的后缀名不重要,但是针对于压缩文件的后缀名是必须的,因为可以让其他的程序员根据文件的后缀名使用对应的算法进行解压。
Linux常见的压缩文件后缀名:
| *.gz | gzip程序压缩的文件 |
|---|---|
| *.bz2 | bzip2 程序压缩的文件 |
| *.Z | compress(旧的加密算法,目前基本不用) 程序压缩的文件 |
| *.tar | tar命令打包的数据,并没有压缩过 |
| *.tar.gz | tar程序打包的文件,并且经过 gzip 的压缩 |
| *.tar.bz2 | tar程序打包的文件,并且经过 bzip2 的压缩 |
压缩命令
gzip:
压缩/解压命令
选项:
| -c : | 将压缩的数据输出到标准输出(stdout)上 |
|---|---|
| -d : | 解压缩 |
| -t : | 可以用来检验一个压缩文件的一致性,看看文件有无错误 |
| -v : | 可以显示出原文件/压缩文件的压缩比等信息 |
| -(1,2,…,9): | 压缩等级,1最快,但是压缩比最差;9最慢,但是压缩比最好,默认是6。 |
| -l : | 查看压缩文件的压缩比: gzip –l *.gz |
案例:
cp /root/install.log /home/gzip
1,gzip -c install.log //将压缩的数据输出到标准输出
2,gzip –v install.log //压缩完显示这时发现源文件不在了,如果想保留源文件,可以用数据重导向技术
3,gzip -d install.log.gz //解压
4,gzip -c install.log > install.log.gz
5,gzip -t install.log.gz //检查文件是否有误
6,gzip -c9v install.log //提高压缩比(文件如果本身很小可能体现不出来)
bzip2:
压缩/解压命令:
选项:
| -c : | 将压缩的过程产生的数据输出到标准输出(stdout) |
|---|---|
| -d : | 解压缩的参数 |
| -k : | 保留源文件,而不会删除原始的文件 |
| -f : | 强制压缩 |
| -v : | 可以显示出原文件/压缩文件案的压缩比等信息; |
| -(1,2,…,9): | 与gzip同样的,都是在计算压缩比的参数,-9最佳,-1最快 |
gzip拥有更快的压缩性能。
bzip2拥有更高的压缩比。
单纯从压缩比方面来说,那么bzip2 > gzip > compress
查看压缩文件中的内容:
cat:可以用来查看文本文件中的内容。
zcat:可以用来查看gzip算法压缩的压缩文件内容。
bzcat:可以用来查看bzip2算法压缩的压缩文件内容。
打包、解包命令
tar:
可以将一个文件/夹打包成一个文件。可以结合gzip、bzip2的算法对包文件进行相应的压缩和解压。
语法:
压缩: tar [选项] newFileName.tar.gz sourceFileName
解压: tar [选项] fileName.tar.gz [-C /path]
选项:
| -c : | 建立打包文件 |
|---|---|
| -t : | 查看打包文件的内容含有哪些文件 |
| -x : | 解打包或解压缩的功能,可以搭配-C(大写)在指定目录解开 |
| -j : | 通过bzip2的支持进行压缩/解压缩:此时文件最好为 *.tar.bz2 |
| -z : | 通过gzip的支持进行压缩/解压缩:此时文件最好为 *.tar.gz |
| -v : | 在压缩/解压缩的过程中,将正在处理的文件名显示出来 |
| -f filename: | -f 后面跟处理文件的全名称(路径+文件名+后缀名) |
| -C 目录: | 这个选项用在解压的时候,若要在特定目录解压,可以使用这个选项 |
注:
使用命令进行打包、压缩的时候,使用了什么算法,文件后缀名就一定要与其对应。
案例:
压缩:
1、使用gzip的算法进行打包压缩。
tar -zcvf install.log.tar.gz install.log
注意tar的语法,tar -zcvf newFile sourceFile
2、使用bzip2的算法进行打包压缩。
tar -jcvf install.log.tar.bz2 install.log
3、如果想要压缩指定目录中的内容是,可以考虑使用绝对路径。
tar -zcvf [path]/newFileName.tar.gz [path]/sourceFile
解压:
在centOS7 版本中已经安装了jdk 而且是一个open版本,被阉割之后的jdk版本。
将原来的jdk open版本先卸载掉
#查看当前jdk query all
rpm -qa |grep jdk
copy-jdk-configs-2.2-3.el7.noarch
java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64
#分别将三个跟jdk有关的都卸载掉
rpm -ev --nodeps copy-jdk-configs-2.2-3.el7.noarch
rpm -ev --nodeps java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64
rpm -ev --nodeps java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64
再次查看是否还有jdk
rpm -qa |grep jdk
FileZilla_3.17.0.0_win64_setup.exe 工具用于windows和linux传递文件的
1、将一个压缩包文件解压到当前目录下
tar -zxvf install.log.tar.gz
执行完成之后,文件会在当前的目录下。
2、将一个压缩包文件解压到指定目录下
tar -zxvf install.log.tar.gz -C /
3、只解压包中的某个文件
tar -zxvf etc.tar.gz etc/shells
4、配置jdk环境变量:
tar -zxvf jdk-8u131-linux-x64.tar.gz
cd jdk1.8.0_131
pwd # 复制路径
vim /etc/profile # profile文件是系统环境变量的配置文件
在该文件的最后一行添加内容:
export JAVA_HOME=[path]
export PATH=$JAVA_HOME/bin:$PATH
保存退出
source /etc/profile
使环境变量生效
4.2.2软件管理
最初只有.tar.gz的打包文件,用户必须编译每个他想在Linux上运行的软件。用户们普遍认为系统很有必要提供一种方法来管理这些安装在机器上的软件包,当Debian诞生时,这样一个管理工具也就应运而生,它被命名为dpkg。稍后RedHat(红帽)才决定开发自己的“rpm”包管理系统。
优点:
自带编译后的文件,免除用户对软件编译的过程
可以自动检测文件系统(硬盘)的容量、系统的版本。避免软件被错误的安装。
自带软件的版本信息、帮助文档、用途说明等信息。
缺点:
无论安装还是卸载,RPM都有一个恶心人的依赖关系。
安装的软件需要依赖,那么优先安装依赖。
卸载的软件存在依赖,那么优先卸载依赖。
默认路径:
| /etc | 一些配置文件放置的目录,例如/etc/crontab ,etc/profile |
|---|---|
| /usr/bin | 一些可执行文件 |
| /usr/lib | 一些程序使用的动态链接库 |
| /usr/share/doc | 一些基本的软件使用手册与说明文件 |
| /usr/share/man | 一些man page(Linux命令的随机帮助说明)文件 |
安装:
语法:rpm -ivh packageName.rpm
选项:
| i | 表示安装 |
|---|---|
| v | 表示处理过程 |
| h | 显示处理进度(进度条) |
案例:
软件包在资料中提供:
D:\work\PPT\linux\01 资料\rpm
安装软件:
单个安装:
rpm -ivh pack1.rpm
多个安装:
rpm -ivh pack1.rpm pack2.rpm *.rpm
安装网络上的RPM包
课后作业
rpm -ivh "https://网络地址/package.rpm"
查询:
rpm -[选项]
选项:
| -q : | 仅查询,后面接的软件名称是否有安装(query) |
|---|---|
| -qa : | 列出所有的,已经安装在本机Linux系统上面的所有软件名称 !!! |
| -ql : | 列出该软件所有的文件与目录所在完整文件名 !! |
| -qc : | 列出该软件的所有配置文件 ! |
| -qd : | 列出该软件的所有说明文件 |
| -qR : | 列出和该软件有关的相依软件所含的文件 |
| -qf : | 由后面接的文件名,找出该文件属于哪一个已安装的软件 |
https://download.oracle.com/otn/java/jdk/8u291-b10/d7fc238d0cbf4b0dac67be84580cfb4b/jdk-8u291-linux-aarch64.rpm
案例1:查找是否安装jdk
rpm -qa |grep jdk
案例2:查找所有系统已经安装的包,并只查看前3个
rpm -qa |head -n 3
案例3:查询lrzsz所包含的文件及目录
rpm -ql lrzsz
案例4:查看lrzsz包的相关说明
rpm -qi lrzsz
列出iptables的配置文件
rpm -qc iptables
案例7:查看apr需要的依赖
rpm -qR apr
4.2.2.1RPM安装mysql
- 下载mysql安装包
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zMyORwYc-1631443904898)(img\mysqlDown.png)]
- 确认当前虚拟机之前是否有安装过mysql
执行:rpm -qa 查看linux安装过的所有rpm包
执行:rpm -qa | grep mysql
如果出现下图,证明已经安装了mysql,需要删除
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b3JbqPYp-1631443904899)(img\qaMysql.png)]
- 删除mysql
执行:rpm -ev --nodeps mysql-libs-5.1.71-1.el6.x86_64
此时,再执行:rpm -qa | grep mysql 发现没有相关信息了
-
新增mysql用户组,并创建mysql用户
groupadd mysql useradd -r -g mysql mysql -
安装mysql server rpm包和client包,执行:
rpm -ivh MySQL-server-5.6.29-1.linux_glibc2.5.x86_64.rpm rpm -ivh MySQL-client-5.6.29-1.linux_glibc2.5.x86_64.rpm -
安装后,mysql文件所在的目录
Directory Contents of Directory
/usr/bin Client programs and scripts
/usr/sbin The mysqld server
/var/lib/mysql Log files, databases
/usr/share/info MySQL manual in Info format
/usr/share/man Unix manual pages
/usr/include/mysql Include (header) files
/usr/lib/mysql Libraries
/usr/share/mysql Miscellaneous support files, including error messages, character set files, sample configuration files, SQL for database installation
/usr/share/sql-bench Benchmarks
-
修改my.cnf,默认在/usr/my.cnf,执行:vim /usr/my.cnf,添加如下内容:
[client] default-character-set=utf8 [mysql] default-character-set=utf8 [mysqld] character_set_server=utf8 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES -
将mysqld加入系统服务,并随机启动
执行:cp /usr/share/mysql/mysql.server /etc/init.d/mysqld
说明:/etc/init.d 是linux的一个特殊目录,放在这个目录的命令会随linux开机而启动。
-
启动mysqld,执行:
service mysqld start[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mQjZneZR-1631443904900)(D:\tarena\延职院\讲义\img\mysqlID.png)]
-
查看初始生成的密码,执行:
vim /root/.mysql_secret这个密码随机生成的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k1HU1d0F-1631443904902)(img/mysql_secret.png)]
-
修改初始密码
第一次安装完mysql后,需要指定登录密码
执行:45qiucH6BU5v7x5y
mysqladmin -u root -p password root此时,提示要输入初始生成的密码,拷贝过来即可
-
进入mysql数据库
执行:
mysql -u root -p输入:root进入
执行:\s查看mysql数据配置信息
4.2.2.2 YUM安装
mysql卸载:
1,查询
rpm -qa | grep mysql
2,yum 卸载
find / -name mysql
rm -rf mysql /usr/share
下载的时候注意,centos的版本
yum的由来,是因为rpm的缺点所导致,因为rpm无论安装还是卸载都需要解决依赖关系,并且比较繁琐,所以诞生yum的技术。
yum通过分析rpm的信息来进行软件的安装、升级、卸载。
| 优点: | 可以一键解决rpm的依赖关系。 |
|---|---|
| 缺点: | yum的所有执行操作全都都需要repo文件(YUM源)。 使用yum安装软件,中招几率高达90%。 |
所有的yum源都存放在/etc/yum.repos.d/目录下。
工作环境中,一般都会屏蔽系统自带的yum源,而选择权威机构的yum源。
yum的查询:
| search | 查询某个软件名称或者是描述的关键字 |
|---|---|
| list | 列出目前yum所管理的所有的软件名称与版本,有点类似 rpm -qa |
yum的安装:
yum install package_Name
案例:
yum install lrzsz
期间会提示y/N
输入y即可。
yum的卸载:
yum remove package_Name
案例
yum remove lrzsz
课堂练习:
1. yum search lrzsz
2. yum remove lrzsz-0.12.20-36.el7.x86_64
3. yum search lrzsz
1. lrzsz.x86_64
4. yum install lrzsz-0.12.20-36.el7.x86_64
yum的更新:
yum update package_Name
yum安装、卸载、更新的过程中出现的y/N,可以通过在命令的结尾出 -y,表示全部过执行yes操作。
yum客户端运行机制
客户端每次使用yum调用 install或者search的时候,都会去解析/etc/yum.repos.d/下面所有以.repo结尾的文件,这些配置文件指定了yum服务器的地址。
yum需要定期去“更新”yum服务器上的rpm “清单” ,然后把“清单”下载保存到yum自己的cache里面,根据/etc/yum.conf里配置(默认是在/var/cache/yum/ b a s e a r c h / basearch/ basearch/releasever下、即/var/cache/yum/x86_64/6),每次调用yum安装包的时候都会去这个cache目录下去找“清单”,根据“清单”里的rpm包描述从而来确定安装包的名字,版本号,所需要的依赖包等,如果rpm包的cache不存在,就去yum服务器下载rpm包安装。
3.清理yum缓存,并生成新的缓存
yum clean all
yum makecache
加入hadoop组件相关yum源
- 查看当前系统中yum支持的所有软件包中是否存在hadoop
[root@tedu yum.repos.d]# yum list|grep hadoop #发现没有
- 如果想要当前系统的yum支持hadoop软件包,需要本地/etc/yum.repos.d下创建cloudera-cdh5.repo文件
http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh
centos6系列更换阿里yum源
1.首先备份原来的cent os官方yum源
cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
2.获取阿里的yum源覆盖本地官方yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
3.清理yum缓存,并生成新的缓存
yum clean all
yum makecache
RPM和YUM的取舍
如果安装、卸载、更新的软件是单个独立的离线安装包,那么建议使用RPM的方式进行安装、卸载、更新。
如果安装一个软件时,发现此软件有众多的依赖环境,那么首选就是yum的方式进行处理。
例如:
安装一个jdk,那么首选rpm的方式。
安装tomcat的话就可以考虑使用yum。
4.2.2.3Tomcat安装
从官网上下载tomcat安装包(可用wget命令下载)
https://tomcat.apache.org/download-80.cgi
-
在centos的/usr/local/下创建tomcat文件夹,用winscp将下载的tomcat拖到该文件夹


-
解压tomcat安装包


4) 修改Tomcat的环境变量,vi /etc/profile 在最后添加:(单个tomcat可以不用配置profile)
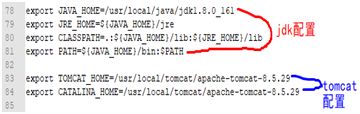
-
关闭centos防火墙,否则tomcat在centos虚拟机外无法访问;或者开启8080端口

-
开启tomcat

-
外部访问tomcat
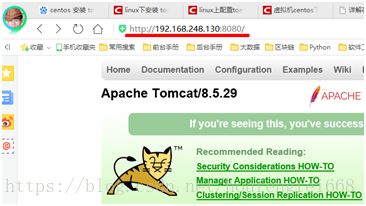
8)部署项目
将在windows开发的web项目打包成war包并拷贝到tomcat的webapps目录中并启动tomcat服务器
# cd 到tomcat安装目录的bin目录,启动tomcat
./startup.sh
#关闭tomcat的命令
./shutdown.sh
访问项目:
ip地址(域名):port8080/TestTomcat/资源index.html
远程的计算机 端口号 项目访问名 具体的资源文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wEKlOp7o-1631443904905)(img\image-20210531155400214.png)]
4.3FTP服务器搭建
应用场景 本地windows作为客户端,虚拟机CentOS7作为服务器端,搭建FTP服务器,本地访问虚拟机实现文件的上传下载。
一、vsftpd简介
FTP,File transfer protocol的缩写,中文叫文本传输协议,是用于在网络上进行文件传输的一套标准协议,属于网络传输协议的应用层。注意,它是协议,不是软件,今天搭建的vsftpd是基于FTP开发的一套程序,也是一款在Linux发行版中最受推崇的FTP服务器程序,特点是小巧轻快,安全易用。
二、安装vsftpd服务
1、安装vsftpd: yum install vsftpd -y
2、启动vsftpd: systemctl start vsftpd
3、设置开机启动:systemctl enable vsftpd
三、关闭防火墙
在虚拟机上使用没必要一个一个端口放行,直接关闭防火墙,一劳永逸
systemctl stop firewalld 停止防火墙运行
systemctl disable firewalld 禁止开机启动
四、添加访问用户
useradd -g root -d /usr/local/src/ftp -s /sbin/nologin user1
#/usr/local/src/ftp为ftp文件目录 可自定义
#-s /sbin/nologin只是不允许系统login,可以使用其他ftp等服务
#user1 为添加的用户名
passwd #设置用户密码,执行命令
五、运行,登录
ftp localhost
输入账号密码,成功登录。
六、局域网测试
Centos下的网卡设置是在/etc/sysconfig/network-s/这个文件夹下,进入该文件夹,前缀为ifcfg-后面跟的就是网卡的名称。
默认的话是开启dhcp的,首先把BOOTPROTO="dhcp"改成BOOTPROTO="static"表示静态获取。之后在写进以下配置:
IPADDR=192.168.1.6
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=192.168.1.1
BROADCAST设置的是局域网广播地址,IPADDR就是静态IP,NETMASK是子网掩码, GATEWAY就是网关或者路由地址,DNS就是域名系统地址, 这里用的就是本地网关,也可以设置其它,比如谷歌、360DNS地址。
systemctl restart network //重启网络服务
ip addr或者ifconfig //查看ip地址
接下来在windows平台用FileZilla Client软件登陆。
这里有些朋友会使用虚拟机测试,但是按照上面配置后发现连接不了,那是因为虚拟机的网络连接模式的影响。这里有一个简单的方法,就是直接获取虚拟机里面系统的ip地址,然后在FileZilla客户端填入。

系统账号默认登陆是在账号的家目录,可以切换到其它目录。
到这里,基本的vsftpd搭建成功。
七、认识vsftpd配置文件vsftpd.conf
主程序:/usr/sbin/vsftpd
主配置文件:/etc/vsftpd/vsftpd.conf
数据根目录:/var/ftp
就算是经验丰富的老手也会做好备份工作
cp /etc/vsftpd/vsftpd.conf /etc/vsftpd/vsftpd.conf.bak
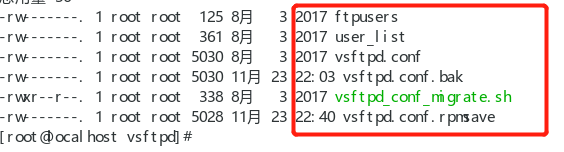
anonymous_enable=NO //设定不允许匿名访问
local_enable=YES //设定本地用户可以访问
write_enable=YES //设定可以进行写操作
local_umask=022 //设定上传后文件的权限掩码
anon_upload_enable=NO //禁止匿名用户上传
anon_mkdir_write_enable=NO //禁止匿名用户建立目录
dirmessage_enable=YES //设定开启目录标语功能
xferlog_enable=YES //设定开启日志记录功能
connect_from_port_20=YES //设定端口20进行数据连接(主动模式)
chown_uploads=NO //设定禁止上传文件更改宿主
#chown_username=whoever
xferlog_file=/var/log/xferlog //设定Vsftpd的服务日志保存路径。
xferlog_std_format=YES //设定日志使用标准的记录格式。
#idle_session_timeout=600 //设定空闲连接超时时间,单位为秒,这里默认
#data_connection_timeout=120 //设定空闲连接超时时间,单位为秒,这里默认。
#nopriv_user=ftptest
async_abor_enable=YES //设定支持异步传输功能。
ascii_upload_enable=YES
ascii_download_enable=YES //设定支持ASCII模式的上传和下载功能。
ftpd_banner=Welcome to blah FTP service. //设定Vsftpd的登陆标语。
#deny_email_enable=YES // (default follows)
#banned_email_file=/etc/vsftpd/banned_emails
chroot_local_user=YES
chroot_list_enable=YES //禁止用户登出自己的FTP主目录。
chroot_list_file=/etc/vsftpd/chroot_list //这个文件里的用户不受限制,不限制在本目录。
ls_recurse_enable=NO //禁止用户登陆FTP后使用"ls -R"的命令。
该命令会对服务器性能造成巨大开销。
#listen=NO
#listen_ipv6=YES
userlist_enable=YES //设定userlist_file中的用户将不得使用FTP。
tcp_wrappers=YES //设定支持TCP Wrappers
allow_writeable_chroot=YES //这个可以解决chroot权限问题
systemctl restart vsftpd //重启vsftpd服务

八、vsftpd虚拟用户的使用
vsftpd提供了三种认证方式,分别是:匿名用户认证、本地用户认证和虚拟用户认证。上面test用户就是本地用户。从安全的角度来说,虚拟用户最安全,接下来,我们开始配置虚拟用户。
虚拟用户配置步骤:
1) 建立虚拟FTP用户数据库文件。
2) 创建FTP根目录及虚拟用户映射的系统用户。
3) 建立支持虚拟用户的PAM认证文件。
4) 在vsftpd.conf中添加支持配置。
5) 为虚拟用户设置权限。
6) 虚拟账号登录。
1.建立虚拟FTP用户数据库文件
建立一个虚拟用户名单文件,这个文件就是来记录vsftpd虚拟用户的用户名和口令的数据文件,我这里给它命名为vuser.list,保存在/etc/vsftpd/目录下。
vim vuser.list
一行账号,一行密码
vuser1
1234
安装Berkeley DB
yum install compat-db47.x86_64 -y
安装后
db_load -T -t hash -f vuser.list vuser.db//生成用户加密文件
chmod 600 vuser.db //敏感文件限制只允许属主读写
2.创建虚拟用户及虚拟用户的家目录
useradd -d /var/vusers -s /sbin/nologin vftp //创建系统用户vftp,并制定其家目录为/var/vusers
chmod -Rf 755 /var/vusers/ //修改目录的权限使得其他用户也可以访问。
3.建立支持虚拟用户的PAM认证文件
vsftpd的pam文件在/etc/pam.d/目录下,先做备份工作。
cp vsftpd vsftpd.bakvim vsftpd
先注释掉所有的内容后添加以下内容:
auth required /lib64/security/pam_userdb.so db=/etc/vsftpd/vuser //此句用于检查用户密码,数据库文件不要写后缀.db
account required /lib64/security/pam_userdb.so db=/etc/vsftpd/vuser //此句用于检查用户是否在有效期内,数据库支持虚拟用户的PAM认证文件。
4.在vsftpd.conf中添加支持配置
guest_enable=YES //开启虚拟用户模式
guest_username=vftp //指定虚拟用户账号
pam_service_name=vsftpd.virtual //指定pam文件
user_config_dir=/etc/vsftpd/vusers_profile //指定虚拟用户的权限配置目录。
virtual_use_local_privs=NO //虚拟用户和匿名用户有相同的权限
5.为虚拟用户设置不同的权限。
mkdir /etc/vsftpd/vusers_profile //新建虚拟用户目录
vim /etc/vsftpd/vusers_profile/vuser//新建虚拟用户配置文件,文件名要和上面的虚拟用户名单里的账号名字对等。
local_root=/var/vusers/vuser //虚拟账号的家目录
anonymous_enable=NO
local_umask=022
anon_upload_enable=YES //上传权限
anon_mkdir_write_enable //创建文件和目录的权限
anon_other_write_enable //删除文件和目录的权限
anon_world_readable_only=YES //当文件的“其他人”有读权限的时候可以下载
download_enable=YES //下载权限
保存配置,重启服务。
systemctl restart vsftpd


4.配置ftp相关内容
[root@localhost 20190425]# getsebool -a | grep ftp
ftp_home_dir --> on
ftpd_anon_write --> off
ftpd_connect_all_unreserved --> off
ftpd_connect_db --> off
ftpd_full_access --> on
ftpd_use_cifs --> off
ftpd_use_fusefs --> off
ftpd_use_nfs --> off
ftpd_use_passive_mode --> off
httpd_can_connect_ftp --> off
httpd_enable_ftp_server --> off
sftpd_anon_write --> off
sftpd_enable_homedirs --> off
sftpd_full_access --> off
sftpd_write_ssh_home --> off
tftp_anon_write --> off
tftp_home_dir --> off
#修改ftp_home_dir和sftpd_full_access状态,可通过一下命令执行
setsebool -P allow_ftpd_full_access on #允许ftp访问外网
setsebool -P tftp_home_dir on #允许ftp访问home
5.配置用户权限
到这里已经可以使用访问FTP了,我们也可以自定义修改ftp相关配置
#执行vim /etc/vsftpd/vsftpd.conf查看
listen=NO
listen_address=172.16.0.236 #绑定本机IP
anonymous_enable=NO #禁止匿名访问
anon_upload_enable=NO
anon_mkdir_write_enable=NO
anon_other_write_enable=NO
allow_writeable_chroot=YES #允许写入
我只对匿名访问,允许访问做了更改,anonymous_enable=NO、allow_writeable_chroot=YES
现在可以在在windows资源管理器或者浏览器,输入ftp://IP PORT 进行访问
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v42DKrlB-1631443904919)(D:\tarena\延职院\讲义\img\ftp浏览器.png)]
也可以在命令行访问
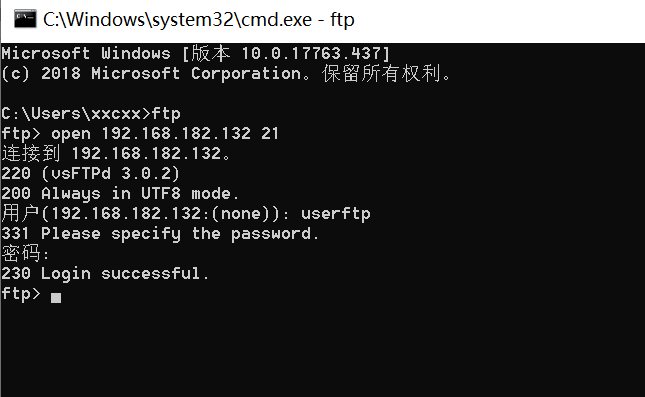
登陆成功。
6.常用命令
下载文件可以通过命令行执行
pwd #打印当前目录
ls #查看文件
lcd #设定本地下载目录
get filename #文件下载
mget * #文件批量下载
put filename #文件上传
mput * #批量上传
到此我们的ftp服务器搭建就结束了。
4.4课后作业
练习Tomcat服务器的配置
第五章 shell编程
5.1什么是Shell?
shell是外壳的意思,就是操作系统的外壳。我们可以通过shell命令来操作和控制操作系统,比如Linux中的Shell命令就包括ls、cd、pwd等等。总结来说,Shell是一个命令解释器,它通过接受用户输入的Shell命令来启动、暂停、停止程序的运行或对计算机进行控制。
5.2什么是脚本?
脚本就是由Shell命令组成的文件,这些命令都是可执行程序的名字,脚本不用编译即可运行。它通过解释器解释运行,所以速度相对来说比较慢。
5.3第一个shell脚本
打开文本编辑器(可以使用 vi/vim 命令来创建文件),新建一个文件 hello.sh,扩展名为 sh(sh代表shell)
#!/bin/bash
echo "Hello World !"
5.4运行脚本的两种方式
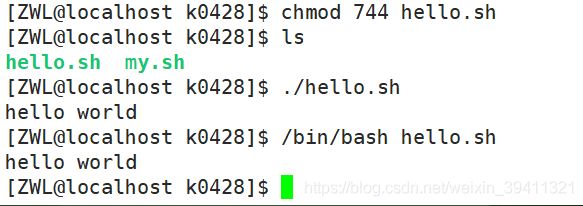
5.4.1.作为可执行程序
将上面的代码保存为 hello.sh,并 cd 到相应目录:
chmod 744 hello.sh 使脚本具有执行权限
./hello.sh 执行脚本
注意:一定要写成 ./hello.sh,而不是 hello.sh,运行其它二进制的程序也一样,直接写 hello.sh,linux 系统会去 PATH 里寻找有没有叫 hello.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 hello.sh 是会找不到命令的,要用 ./hello.sh 告诉系统说,就在当前目录找。
5.4.2.作为命令解释器
这种运行方式是,直接运行解释器,其参数就是 shell 脚本的文件名,如:
/bin/bash hello.sh
注意:这种方式运行的脚本,不需要在第一行指定解释器信息
5.5shell变量
5.5.1定义变量
变量名不加美元符号($),如:
your_name="jzf love zwl"
**注意:**变量名和等号之间不能有空格,同时,变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
5.5.2使用变量
-
使用一个定义过的变量,只要在变量名前面加美元符$即可
-
变量值可以用“”括起来也可以不用 但是如果值的中间有空格必须用“”括起来
-
#是用来加注释 相当于C语言里的//
- #!/bin/bash str="hello world" str1=hello val=100 echo "str=$str" echo "val=$val"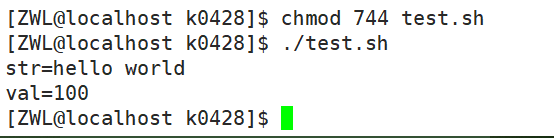
5.6Shell 传递参数
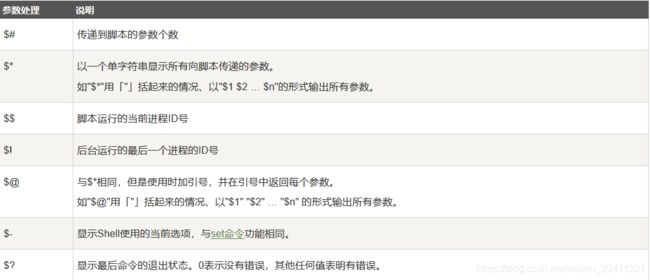
我们可以在执行 Shell 脚本时,向脚本传递参数,脚本内获取参数的格式为:$n, 其中n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推……
其他参数如下表所示
示例
#!/bin/bash
echo "Shell 传递参数实例!";
echo "第一个参数为:$1";
echo "第一个参数为:$2";
echo "第一个参数为:$3";
echo "参数个数为:$#";
echo "传递的参数作为一个字符串显示:$*";
5.7环境变量
#!/bin/bash
echo "HOME=$HOME"
echo "PATH=$PATH"

5.8条件语句 if else
语句结构如下
if
then
.....
elif
then
....
else
.....
fi
注意:
-
read line语句为读取输入的数据 line名字可以自己取 使用时在前边加$符号
-
if语句必须用[ ]括起来并且[ ]两边必须要有空格空开
-
if语句的结束标志为fi
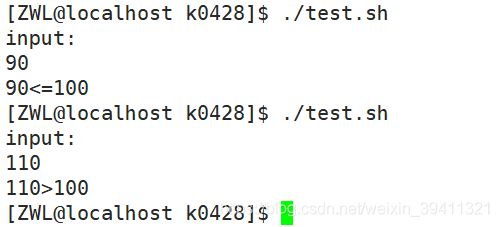
示例1判断一个数是否大于100
#!/bin/bash
echo "input:"
read line
if [ "$line" -gt 100 ]
then
echo "$line>100"
else
echo "$line<=100"
fi
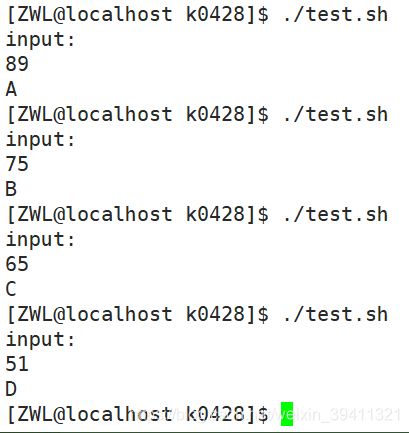
示例2根据输入的成绩进行划分等级
#!/bin/bash
echo "input:"
read line
if [ "$line" -gt 100 ] || [ "$line" -lt 0 ]
then
echo "argc error"
exit 0
fi
if [ "$line" -ge "80" ]
then
echo "A"
elif [ "$line" -ge 70 ]
then
echo "B"
elif [ "$line" -ge 60 ]
then
echo "C"
else
echo "D"
fi
5.9循环语句 while
5.9.1while 语句
while循环用于不断执行一系列命令,也用于从输入文件中读取数据其格式为:
while condition
do
command
done
以下是一个基本的while循环,测试条件是:如果int小于等于5,那么条件返回真。int从0开始,每次循环处理时,int加1。运行上述脚本,返回数字1到5,然后终止。
#!/bin/bash
int=1
while(( $int<=5 ))
do
echo $int
let “int++”
done
另外:while循环可用于读取键盘信息。下面的例子中,输入信息被设置为变量FILM,按结束循环。
#!/bin/bash
echo -n '输入你最喜欢的明星: ’
while read person
do
echo “是的!$person 是一个好人”
done
示例1
模拟密码验证过程
如果密码输入正确显示success
如果输入错误则继续输入,若连着三次都没有输入正确的密码,则退出程序显示failed。
#!/bin/bash
i=0
while [ : ]
do
echo "input"
read line
if [ "$line" = 123 ]
then
break
fi
let "i+=1"
if [ "$i" -eq 3 ]
then
printf "failed\n"
exit 0
fi
done
echo "success"
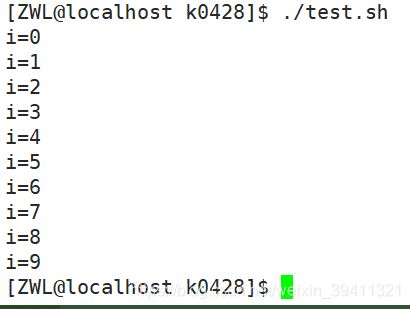
示例2
输出小于10的数
#!/bin/bash
i=0
while [ $i -lt 10 ]
do
echo "i=$i"
let "i+=1"
done
5.9.2for语句
for循环一般格式为:
for var in item1 item2 … itemN
do
command1
command2
…
commandN
done
案例:
#!/bin/bash
for num in 1 2 3 4 5
do
echo “The value is: $num”
done
顺序输出字符串中的字符:
str=“this is a string”
for ((i=0; i < = i<= i<={#str}; i=$i+1))
do
echo KaTeX parse error: Expected '}', got 'EOF' at end of input: {str:i:1}
done
5.9.3无限循环
无限循环语法格式:
while :
do
command
done
或者
while true
do
command
done
5.9.4until 循环
until 循环执行一系列命令直至条件为 true 时停止。
until 循环与 while 循环在处理方式上刚好相反。
以下实例我们使用 until 命令来输出 0 ~ 9 的数字:
#!/bin/bash
a=0
until [ ! $a -lt 10 ]
do
echo $a
let a+=1
done
5.9.5 case
Shell case语句为多选择语句。可以用case语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令
下面的脚本提示输入1到4,与每一种模式进行匹配:
echo '输入 1 到 4 之间的数字:'
echo '你输入的数字为:'
read num
case $num in
1) echo '你选择了 1'
;;
2) echo '你选择了 2'
;;
3) echo '你选择了 3'
;;
4) echo '你选择了 4'
;;
*) echo '你没有输入 1 到 4 之间的数字'
;;
esac
5.9.6break命令
break命令允许跳出所有循环(终止执行后面的所有循环)。
下面的例子中,脚本进入死循环直至用户输入数字大于5。要跳出这个循环,返回到shell提示符下,需要使用break命令。
#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字:"
read num
case $num in
1|2|3|4|5) echo "你输入的数字为 $aNum!"
;;
*) echo "你输入的数字不是 1 到 5 之间的! 游戏结束"
break
;;
esac
done
5.10运算符
Shell 和其他编程语言一样,支持多种运算符,包括:
- 算数运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
算术运算符
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b 结果为 30。 |
| - | 减法 | expr $a - $b 结果为 -10。 |
| * | 乘法 | expr $a \* $b 结果为 200。 |
| / | 除法 | expr $b / $a 结果为 2。 |
| % | 取余 | expr $b % $a 结果为 0。 |
| = | 赋值 | a=$b 将把变量 b 的值赋给 a。 |
| == | 相等。用于比较两个数字,相同则返回 true。 | [ $a == $b ] 返回 false。 |
| != | 不相等。用于比较两个数字,不相同则返回 true。 | [ $a != $b ] 返回 true。 |
实例
#!/bin/bash
a=10
b=20
val=`expr $a + $b`
echo "a+b : $val"
#乘号(*)前边必须加反斜杠(\)才能实现乘法运算;
val=`expr $a \* $b`
echo "a*b : $val"
if [ $a == $b ]
then
echo "a等于b"
fi
if [ $a != $b ]
then
echo "a 不等于b"
fi
**注意:**条件表达式要放在方括号之间,并且要有空格,例如: [ a = = a== a==b] 是错误的,必须写成 [ $a == $b ]。
#`expr $a + $b`等于$(($a+$b))
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
#!/bin/bash
a=10
b=20
if [ $a -eq $b ]
then
echo " a 等于 b"
else
echo " a 不等于 b"
fi
if [ $a -gt $b ]
then
echo “a 大于 b”
else
echo “a 不大于 b”
fi
if [ $a -lt $b ]
then
echo “a 小于 b”
else
echo “a 不小于 b”
fi
逻辑运算符
以下介绍 Shell 的逻辑运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] 返回 true |
实例
逻辑运算符实例如下:
实例
#!/bin/bash
a=10
b=20
if [[ $a -lt 100 && $b -gt 100 ]]
then
echo “返回 true”
else
echo “返回 false”
fi
if [[ $a -lt 100 || $b -gt 100 ]]
then
echo “返回 true”
else
echo “返回 false”
fi
字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0,为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否为0,不为0返回 true。 | [ -n “$a” ] 返回 true。 |
| $ | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
实例
字符串运算符实例如下:
实例
#!/bin/bash
a=“abc”
b=“efg”
if [ $a = $b ]
then
echo “a 等于 b”
else
echo " a 不等于 b"
fi
if [ -z $a ]
then
echo “字符串长度为 0”
else
echo " 字符串长度不为 0"
fi
if [ $a ]
then
echo “$a : 字符串不为空”
else
echo “$a : 字符串为空”
fi
文件测试运算符
文件测试运算符用于检测 Unix 文件的各种属性。
属性检测描述如下:
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件,如果是,则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件,如果是,则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。 |
实例
变量 file 表示文件/root/install.log,它的大小为 20k,具有 rwx 权限。下面的代码,将检测该文件的各种属性:
实例
#!/bin/bash
file="/root/install.log"
if [ -r $file ]
then
echo “文件可读”
else
echo “文件不可读”
fi
if [ -w $file ]
then
echo “文件可写”
else
echo “文件不可写”
fi
if [ -f $file ]
then
echo “文件为普通文件”
else
echo “文件为特殊文件”
fi
if [ -d $file ]
then
echo “文件是个目录”
else
echo “文件不是个目录”
fi
if [ -e $file ]
then
echo “文件存在”
else
echo “文件不存在”
fi
5.11test判断
test判断:
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
数值测试
| 参数 | 说明 |
|---|---|
| -eq | 等于则为真 |
| -ne | 不等于则为真 |
| -gt | 大于则为真 |
| -ge | 大于等于则为真 |
| -lt | 小于则为真 |
| -le | 小于等于则为真 |
实例演示:
#!/bin/bash
num1=100
num2=100
if test $[num1] -eq $[num2]
then
echo ‘两个数相等!’
else
echo ‘两个数不相等!’
fi
字符串测试
| 参数 | 说明 |
|---|---|
| = | 等于则为真 |
| != | 不相等则为真 |
| -z 字符串 | 字符串的长度为零则为真 |
| -n 字符串 | 字符串的长度不为零则为真 |
实例演示:
#!/bin/bash
num1=“piaolaoshi”
num2=“PIAOLAOSHI”
if test $num1 = $num2
then
echo ‘两个字符串相等!’
else
echo ‘两个字符串不相等!’
fi
文件测试
| 参数 | 说明 |
|---|---|
| -e 文件名 | 如果文件存在则为真 |
| -r 文件名 | 如果文件存在且可读则为真 |
| -w 文件名 | 如果文件存在且可写则为真 |
| -x 文件名 | 如果文件存在且可执行则为真 |
| -s 文件名 | 如果文件存在且至少有一个字符则为真 |
| -d 文件名 | 如果文件存在且为目录则为真 |
| -f 文件名 | 如果文件存在且为普通文件则为真 |
| -c 文件名 | 如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 | 如果文件存在且为块特殊文件则为真 |
实例演示:
#!/bin/bash
cd /bin
if test -e ./bash
then
echo ‘文件已存在!’
else
echo ‘文件不存在!’
fi
另外,Shell还提供了与( -a )、或( -o )、非( ! )三个逻辑操作符用于将测试条件连接起来,其优先级为:"!“最高,”-a"次之,"-o"最低。例如:
#!/bin/bash
cd /bin
if test -e ./notFile -o -e ./bash
then
echo ‘至少有一个文件存在!’
else
echo ‘两个文件都不存在’
fi
5.12函数
Shell 函数
linux shell 可以用户定义函数,然后在shell脚本中可以随便调用。
举例:
#!/bin/bash
sayHi(){
echo “hello 1906”
}
sayHi
下面定义一个带有return语句的函数:
#!/bin/bash
funWithReturn(){
echo “这个函数会对输入的两个数字进行相加运算…”
echo "输入第一个数字: "
read num1
echo "输入第二个数字: "
read num2
echo "两个数字分别为 $num1 和 $num2 "
return ( ( (( ((num1+$num2))
}
funWithReturn
echo "输入的两个数字之和为 $? "
函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数…
带参数的函数示例:
#!/bin/bash
funWithParam(){
echo "第一个参数为 $1 "
echo "第二个参数为 $2 "
echo "第十个参数为 $10 "
echo "第十个参数为 ${10} "
echo "第十一个参数为 ${11} "
echo “参数总数有 $# 个”
echo "作为一个字符串输出所有参数 $* "
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
注意: 10 不 能 获 取 第 十 个 参 数 , 获 取 第 十 个 参 数 需 要 10 不能获取第十个参数,获取第十个参数需要 10不能获取第十个参数,获取第十个参数需要{10}。当n>=10时,需要使用${n}来获取参数。
第六章 大数据开发平台
6.1Hadoopl简介
6.1.1概述
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7GnQ5Cnm-1631443904923)(oopImg\1614066084594.png)]
-
Hadoop是Apache提供的一个开源的、可靠的、可扩展的系统架构,可以利用分布式架构来进行海量数据的存储以及计算
-
需要注意的是Hadoop处理的是离线数据,即在数据已知以及不要求实时性的场景下使用
-
Hadoop发行版:
-
Apache版本最基本的版本,入门学习较好。原生版本管理相对比较混乱
2. CDH版本是Cloudera提供的商业版本,相对Apache Hadoop更加的稳定和安全
3. Hortonworks文档相对完善友好
6.1.2版本
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y0cglCfn-1631443904924)(oopImg\1614066157302.png)]
- Hadoop1.0:只包含HDFS以及MapReduce两个模块
- Hadoop2.0:完全不同于1.0的架构,包含HDFS、MapReduce以及Yarn三个模块
- Hadoop3.0:包含HDFS、MapReduce、Yarn、Ozone以及Submarine五个模块
6.1.3模块
- Common:在Hadoop1.0中,包含HDFS、MapReduce和其他项目公共内容,从Hadoop2.0开始,HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
- HDFS:用于分布式环境下数据的存储
- Yarn:Hadoop2.0版本中出现,用于进行资源管理和任务调度的框架
- MapReduce:从Hadoop2.0开始,基于Yarn,用于在海量数据的场景下进行并行计算
- Ozone:基于HDFS进行对象的存储
- Submarine:基于Hadoop进行机器学习的引擎
6.1.4相关组件
- HBase: 类似Google BigTable的分布式NoSQL列数据库。(HBase和Avro已经于2010年5月成为顶级 Apache 项目)
- Hive:数据仓库工具,由Facebook贡献
- Zookeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献
- Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
- Pig: 大数据分析平台,为用户提供多种接口
- Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群
- Sqoop:于在Hadoop与传统的数据库间进行数据的传递
6.2 Hadoop安装
6.2.1 步骤
1.关闭防火墙
临时关闭:service iptables stop
永久关闭:chkconfig iptables off
2.配置主机名。需要注意的是Hadoop的集群中的主机名不能有_。如果存在_会导致Hadoop集群无法找到这群主机,从而无法启动!
1.编辑network文件:vim /etc/sysconfig/network
2.将HOSTNAME属性改为指定的主机名,例如:HOSTNAME=hadoop01
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PaS4ot7j-1631443904926)(img\1614066514339.png)]
3.让network文件重新生效:source /etc/sysconfig/network
3.配置hosts文件,将主机名和ip地址进行映射
1.编辑hosts文件:vim /etc/hosts
2.将主机名和ip地址对应,例如:192.168.234.190 hadoop01
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RAKmxwLU-1631443904928)(img\1614066569276.png)]
4.配置ssh进行免密互通
1.生成自己的公钥和私钥,生成的公私钥将自动存放在/root/.ssh目录下:ssh-keygen
2.把生成的公钥拷贝到远程机器上,格式为:ssh-copy-id [user]@host,例如:ssh-copy-id root@hadoop01
5.重启Linux让主机名的修改生效:reboot
6.安装JDK
7.上传或者下载Hadoop安装包到Linux中
8.解压安装包:tar -xvf hadoop-2.7.1_64bit.tar.gz
9.进入Hadoop的安装目录的子目录etc/hadoop,配置Hadoop:cd hadoop2.7.1/etc/hadoop
10.配置hadoop-env.sh
1.编辑hadoop-env.sh:vim hadoop-env.sh
2.修改JAVA_HOME的路径,修改成具体的路径。例如:export JAVA_HOME=/home/software/jdk1.8
3.修改HADOOP_CONF_DIR的路径,修改为具体的路径,
例如:export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
4.保存退出文件
5.重新加载生效:source hadoop-env.sh
11.配置 core-site.xml
1.编辑core-site.xml:vim core-site.xml
2.添加如下内容:
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop01:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/software/hadoop-2.7.1/tmpvalue>
property>
3.保存退出
-
配置 hdfs-site.xml
-
编辑hdfs-site.xml:vim hdfs-site.xml
-
添加如下配置:
<property> <name>dfs.replicationname> <value>1value> property>
3.保存退出
-
13.配置 mapred-site.xml
1.将mapred-site.xml.template复制为mapred-site.xml:cp mapred-site.xml.template mapred-site.xml
2.编辑mapred-site.xml:vim mapred-site.xml
3.添加如下配置:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
4.保存退出
14.配置 yarn-site.xml
1.编辑yarn-site.xml:vim yarn-site.xml
2.添加如下内容:
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
3.保存退出
15.配置slaves
1.编辑slaves:vim slaves
2.添加从节点信息,例如:hadoop01
3.保存退出
16.配置hadoop的环境变量
1.编辑profile文件:vim /etc/profile
2.添加Hadoop的环境变量,例如:
export HADOOP_HOME=/home/software/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.保存退出
4.重新生效:source /etc/profile
17.格式化namenode:hadoop namenode -format
18.启动hadoop:start-all.sh
6.1.2 注意事项
1.如果Hadoop的配置没有生效,那么需要重启Linux
2.在格式化的时候,会有这样的输出:Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted。如果出现这句话,说明格式化成功
3.Hadoop如果启动成功,会出现5个进程:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OG70AzTB-1631443904929)(img\1614066716348.png)]
4.Hadoop启动成功后,可以通过浏览器访问HDFS的页面,访问地址为:IP地址:50070
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dp2su3xV-1631443904931)(img\1614066753458.png)]
5.Hadoop启动成功后,可以通过浏览器访问Yarn的页面,访问地址为:http://IP地址:8088
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bUgHZ7f7-1631443904932)(img\clip_image010.png)]
6.1.3 常见问题
1.执行Hadoop指令,比如格式化:hadoop namenode -format 出现:command找不到错误
解决方案:检查:/etc/profile的Hadoop配置
2.少HFDS相关进程,比如少namenode,datanode
解决方案:可以去Hadoop 安装目录下的logs目录,查看对应进程的启动日志文件。
方式一:①先停止HDFS相关的所有的进程(stop-all.sh 或 kill -9)②再启动HDFS(start-dfs.sh)
echo "第二个参数为 $2 "
echo "第十个参数为 $10 "
echo "第十个参数为 ${10} "
echo "第十一个参数为 ${11} "
echo "参数总数有 $# 个"
echo "作为一个字符串输出所有参数 $* "
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
注意: 10 不 能 获 取 第 十 个 参 数 , 获 取 第 十 个 参 数 需 要 10 不能获取第十个参数,获取第十个参数需要 10不能获取第十个参数,获取第十个参数需要{10}。当n>=10时,需要使用${n}来获取参数。
第六章 大数据开发平台
6.1Hadoopl简介
6.1.1概述
[外链图片转存中…(img-7GnQ5Cnm-1631443904923)]
-
Hadoop是Apache提供的一个开源的、可靠的、可扩展的系统架构,可以利用分布式架构来进行海量数据的存储以及计算
-
需要注意的是Hadoop处理的是离线数据,即在数据已知以及不要求实时性的场景下使用
-
Hadoop发行版:
-
Apache版本最基本的版本,入门学习较好。原生版本管理相对比较混乱
2. CDH版本是Cloudera提供的商业版本,相对Apache Hadoop更加的稳定和安全
3. Hortonworks文档相对完善友好
6.1.2版本
[外链图片转存中…(img-y0cglCfn-1631443904924)]
- Hadoop1.0:只包含HDFS以及MapReduce两个模块
- Hadoop2.0:完全不同于1.0的架构,包含HDFS、MapReduce以及Yarn三个模块
- Hadoop3.0:包含HDFS、MapReduce、Yarn、Ozone以及Submarine五个模块
6.1.3模块
- Common:在Hadoop1.0中,包含HDFS、MapReduce和其他项目公共内容,从Hadoop2.0开始,HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
- HDFS:用于分布式环境下数据的存储
- Yarn:Hadoop2.0版本中出现,用于进行资源管理和任务调度的框架
- MapReduce:从Hadoop2.0开始,基于Yarn,用于在海量数据的场景下进行并行计算
- Ozone:基于HDFS进行对象的存储
- Submarine:基于Hadoop进行机器学习的引擎
6.1.4相关组件
- HBase: 类似Google BigTable的分布式NoSQL列数据库。(HBase和Avro已经于2010年5月成为顶级 Apache 项目)
- Hive:数据仓库工具,由Facebook贡献
- Zookeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献
- Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
- Pig: 大数据分析平台,为用户提供多种接口
- Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群
- Sqoop:于在Hadoop与传统的数据库间进行数据的传递
6.2 Hadoop安装
6.2.1 步骤
1.关闭防火墙
临时关闭:service iptables stop
永久关闭:chkconfig iptables off
2.配置主机名。需要注意的是Hadoop的集群中的主机名不能有_。如果存在_会导致Hadoop集群无法找到这群主机,从而无法启动!
1.编辑network文件:vim /etc/sysconfig/network
2.将HOSTNAME属性改为指定的主机名,例如:HOSTNAME=hadoop01
[外链图片转存中…(img-PaS4ot7j-1631443904926)]
3.让network文件重新生效:source /etc/sysconfig/network
3.配置hosts文件,将主机名和ip地址进行映射
1.编辑hosts文件:vim /etc/hosts
2.将主机名和ip地址对应,例如:192.168.234.190 hadoop01
[外链图片转存中…(img-RAKmxwLU-1631443904928)]
4.配置ssh进行免密互通
1.生成自己的公钥和私钥,生成的公私钥将自动存放在/root/.ssh目录下:ssh-keygen
2.把生成的公钥拷贝到远程机器上,格式为:ssh-copy-id [user]@host,例如:ssh-copy-id root@hadoop01
5.重启Linux让主机名的修改生效:reboot
6.安装JDK
7.上传或者下载Hadoop安装包到Linux中
8.解压安装包:tar -xvf hadoop-2.7.1_64bit.tar.gz
9.进入Hadoop的安装目录的子目录etc/hadoop,配置Hadoop:cd hadoop2.7.1/etc/hadoop
10.配置hadoop-env.sh
1.编辑hadoop-env.sh:vim hadoop-env.sh
2.修改JAVA_HOME的路径,修改成具体的路径。例如:export JAVA_HOME=/home/software/jdk1.8
3.修改HADOOP_CONF_DIR的路径,修改为具体的路径,
例如:export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
4.保存退出文件
5.重新加载生效:source hadoop-env.sh
11.配置 core-site.xml
1.编辑core-site.xml:vim core-site.xml
2.添加如下内容:
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop01:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/software/hadoop-2.7.1/tmpvalue>
property>
3.保存退出
-
配置 hdfs-site.xml
-
编辑hdfs-site.xml:vim hdfs-site.xml
-
添加如下配置:
<property> <name>dfs.replicationname> <value>1value> property>
3.保存退出
-
13.配置 mapred-site.xml
1.将mapred-site.xml.template复制为mapred-site.xml:cp mapred-site.xml.template mapred-site.xml
2.编辑mapred-site.xml:vim mapred-site.xml
3.添加如下配置:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
4.保存退出
14.配置 yarn-site.xml
1.编辑yarn-site.xml:vim yarn-site.xml
2.添加如下内容:
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
3.保存退出
15.配置slaves
1.编辑slaves:vim slaves
2.添加从节点信息,例如:hadoop01
3.保存退出
16.配置hadoop的环境变量
1.编辑profile文件:vim /etc/profile
2.添加Hadoop的环境变量,例如:
export HADOOP_HOME=/home/software/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.保存退出
4.重新生效:source /etc/profile
17.格式化namenode:hadoop namenode -format
18.启动hadoop:start-all.sh
6.1.2 注意事项
1.如果Hadoop的配置没有生效,那么需要重启Linux
2.在格式化的时候,会有这样的输出:Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted。如果出现这句话,说明格式化成功
3.Hadoop如果启动成功,会出现5个进程:
[外链图片转存中…(img-OG70AzTB-1631443904929)]
4.Hadoop启动成功后,可以通过浏览器访问HDFS的页面,访问地址为:IP地址:50070
[外链图片转存中…(img-dp2su3xV-1631443904931)]
5.Hadoop启动成功后,可以通过浏览器访问Yarn的页面,访问地址为:http://IP地址:8088
[外链图片转存中…(img-bUgHZ7f7-1631443904932)]
6.1.3 常见问题
1.执行Hadoop指令,比如格式化:hadoop namenode -format 出现:command找不到错误
解决方案:检查:/etc/profile的Hadoop配置
2.少HFDS相关进程,比如少namenode,datanode
解决方案:可以去Hadoop 安装目录下的logs目录,查看对应进程的启动日志文件。
方式一:①先停止HDFS相关的所有的进程(stop-all.sh 或 kill -9)②再启动HDFS(start-dfs.sh)
方式二:①先停止HDFS相关的所有的进程 ②删除元数据目录 ③重新格式化:hadoop namenode -format④启动Hadoop:start-all.sh