学习笔记:特征工程(三)——特征构建
在之前的节中,我们了解了数据类型,数据识别以及数据填充,但这些操作所针对的数据类型都是定量型数据,那么我们如何处理定性型数据呢?本节笔者就开始研究分类数据,分类数据如何构建,如何通过现有的特征构建全新的特征,让模型从中学习。
其实有很多方法可以构建新特征:最简单的办法就是用pandas将现有的特征扩大几倍;当然也可以使用scikit-learn包的很多部分。本节从以下四个方面来探讨:
- 检查数据集
- 填充分类特征
- 编码分类特征
- 扩展数值特征
1、检查数据集
本节我们可以先试试自己创建一个数据集,以便展示不同的数据等级和类型,我们先设置一个数据的DataFrame:
import pandas as pd
x = pd.DataFrame({'城市':['Beijing', None, 'Shanghai', 'Shenzhen', 'Beijing', 'Nanning'],
'一线城市':['yes', 'no', None, 'yes', 'yes', 'no'],
'喜爱等级':['like', 'somewhat like', 'somewhat like', 'like', 'dislike', 'like'],
'定量列':[11, 3, 10, 8, -0.5, None]})
print(x)让我们来查看一下这个数据集输出:

我们观察一下每一列,识别每列的数据类型和等级:
- 城市:分类数据(定类数据)
- 一线城市:此列为二元分类数据(是/否),定类等级
- 喜爱等级:此列是顺序数据,定序等级
- 定量列:定比数据
2、填充分类特征
我们对自己创建的数据已经有了一定的了解了,现在开始看缺失值:

和我们设置的一样,有三列具有缺失值。接下来我们用之前的办法来填充这些数据。笔者之前用的Imputer类用于填充数值数据,Imputer里确实也有一个most_frequent方法可以用在定性数据上,但是只能处理整数型的分类数据。
但我们可以观察到,我们创建的数据集并不是整数型的分类数据,所以我们要写一个自己的转换器,也就是一个填充每列缺失值的方法。
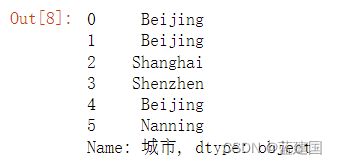
以城市列为例,我们先选出该列最常见的元素:
x['城市'].value_counts().index[0]结果如下:
![]()
我们直接用最常见的元素来填充缺失值:
x['城市'].fillna(x['城市'].value_counts().index[0])结果如下:
那我们就成功处理了城市这一列,我们上述的方法直接粗暴的使用了人工填充。
3、编码分类变量
当然了,除了填充分类变量,我们可能还在想:如何让机器学习算法利用分类数据呢?
简单地说,需要将分类数据转换为数值数据。到目前为止,我们已经用最常见的类别对缺失值进行了填充,现在需要进一步操作。
我们知道,任何一个机器学习算法,需要导入的输入特征都必须是数值。那么问题来了,我们有什么办法可以将分类数据转换为数值数据呢?
3.1、定类等级的编码
主要方法是将分类数据转换为虚拟变量(dummy variable),我们可以直接选用Pandas自动找到分类变量并进行编码。
虚拟变量的取值是1或0,代表某个类别的有无。当然,我们在进行此操作的时候需要小心虚拟变量陷阱,即自变量有多重共线性或高度相关。简单来说,就是这些变量能依据彼此来预测。比如在我们分类性别时,可以将男性设为1,女性设为0,当然也可以将男性设为0,女性设为1,那么就出现重复的类别。
所以为了避免虚拟变量陷阱,我们需要忽略一个常量或者虚拟类别,就假如我们将female = 1代表女性,那么female = 0即等于男性,就没必要在设male这一列变量了。
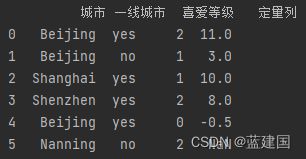
pandas有个非常方便的get_dummies方法,可以找到所有的分类变量,并将其转换为虚拟变量。
pd.get_dummies(x,
columns=['城市', '一线城市'],
prefix_sep='__')这样我们的数据集就会变成:

3.2、定序等级的编码
现在我们来关注定序等级的列。这个等级上仍然存在有用的信息,然而我们需要将字符串转换为数值数据。
标签编码器是指,顺序数据的每个标签都会有一个相关数值。在我们的例子中,这意味着顺序列的指(like、somewhat like、dislike)会用2、1、0来表示。
我们利用下列代码进行替换:
ordering = ['dislike', 'somewhat like', 'like']
x['喜爱等级'] = x['喜爱等级'].map(lambda x: ordering.index(x))查看数据集:
4、拓展数值特征
这一节我们使用一个新的数据集:胸部加速度计识别动作数据集。
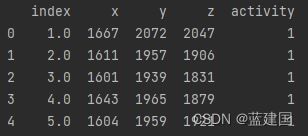
df = pd.read_csv('E:\\特征工程学习\\1.csv')
df.columns = ['index', 'x', 'y', 'z', 'activity']
print(df.head())我们来观察数据:
数据集参数:
- 序号
- x轴加速度
- y轴加速度
- z轴加速度
- 标签
标签列为数字,每个数字代表一种动作(activity),如下所示:
- 在电脑前工作
- 站立、走路和上下楼梯
- 站立
- 走路
- 上下楼梯
- 与人边走边交流
- 站立着讲话
让我们先来查看一下空准确率:
df['activity'].value_counts(normalize=True)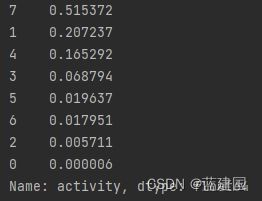
空准确率为51.54%,这就意味着如果我们猜7,正确率便超过一半了 。
我们现在构建一个特征矩阵X和一个响应变量y:
X = df[['x', 'y', 'z']]
y = df['activity']
knn_params = {'n_neighbors':[3, 4, 5, 6]}
knn = KNeighborsClassifier()
grid = GridSearchCV(knn, knn_params)
grid.fit(X,y)
print(grid.best_score_, grid.best_params_)打印最佳准确率以及参数:
![]()
很好,KNN模型已经可以达到73.63%了。
4.1、多项式特征
在处理数值数据、创建更多特征时,一个关键方法是使用scikit-learn的Polynomial-Features类。这个构造函数会创建新的列,它们是原有列的乘积,用于捕获特征交互。
更具体来说,这个类会生成一个新的特征矩阵,即假如输入是二维的,例如[a, b],那么二阶的多项式特征就是[1, a, b, a^2, ab, b^2]。
poly = PolynomialFeatures(degree=2, include_bias=False, interaction_only=False)
#调用fit_transfor函数
x_poly = poly.fit_transform(X)
print(x_poly.shape)查看一下:
![]()
将其放入DataFrame:
pd.DataFrame(x_poly, columns=poly.get_feature_names()).head() 
如此我们便能给输入特征做扩列操作,之后会做相关性分析的笔记,那时候可以来剔除创建出来无用的特征列。