Centos7 系统虚拟机之搭建完全分布式Hadoop环境
伪分布式Hadoop的搭建,请见链接: link.
https://blog.csdn.net/qq_45720792/article/details/107333127
以下所有在终端上执行的操作均在root用户下完成!!!
su - //带环境配置文件切换为root用户
一、建立虚拟机群
在VMware中新建4台虚拟机
1、主机名:hadp01、hadp02、hadp03、hadp04
2、镜像文件:Centos7
链接: link.
(https://pan.baidu.com/s/1pqGMlRwC-t5Qp5YF-aowuA 提取码:w3du)
3、内存:1.5G
资源管理器中在此电脑上右键查看属性,要使得四个虚拟机的内存之和要小于本机运存,这样的话,可以同时运行四台虚拟机,避免发生因内存不够而无法打开虚拟机

4、网络连接:NAT
5、记录各虚拟机IP
ip addr //适用于Centos7以上版本
ipconfig //适用于Centos7以下版本
二、配置静态网卡(IP)
(4台虚拟机均需配置该项目)
虚拟机每次开机时都有可能更改IP,我们在搭建Hadoop时,每台虚拟机之间的通信要保持绝对的稳定,因此IP是不可以改变的。
vi /etc/sysconfig/network-scripts/ifcfg-ens33 //编辑网卡文件
该图是一个未修改的网卡文件(即默认网卡文件)
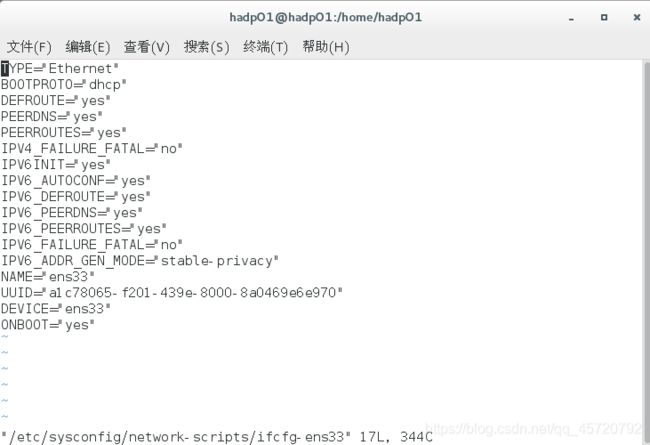
1、将BOOTPROTO的值(默认是dhcp)修改为static,即静态地址
2、添加IPADDR(IP地址)、NETMASK(子网掩码)、GATEWAY(网关)
IPADDR="192.168.137.155"
NETMASK="255.255.255.0"
GATEWAY="192.168.137.0"
vim操作不熟练的小可爱们,见链接: link.(https://blog.csdn.net/qq_45720792/article/details/107300929)
IPADDR:我们可以设置该虚拟机现在时刻的IP,此作用是保持该虚拟机IP不发生改变(查询IP的命令上文已提到);我们也可以设置一个我们想要的IP,使4台虚拟机IP保持相同的格式,便于查看和理解(前提是该IP必须有效且未被占用)
NETMASK、GATEWAY:可以打开VMware→编辑→虚拟网络编辑器,进行查看(NETMASK、GATEWAY要与虚拟机的配置保持一致)
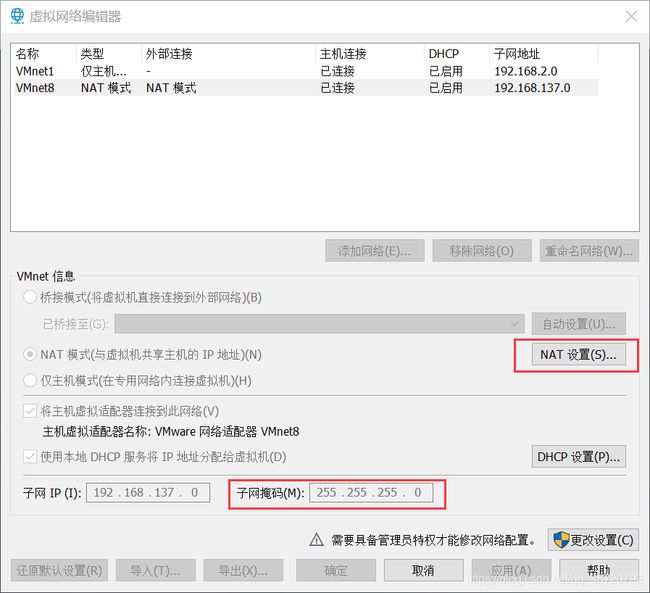
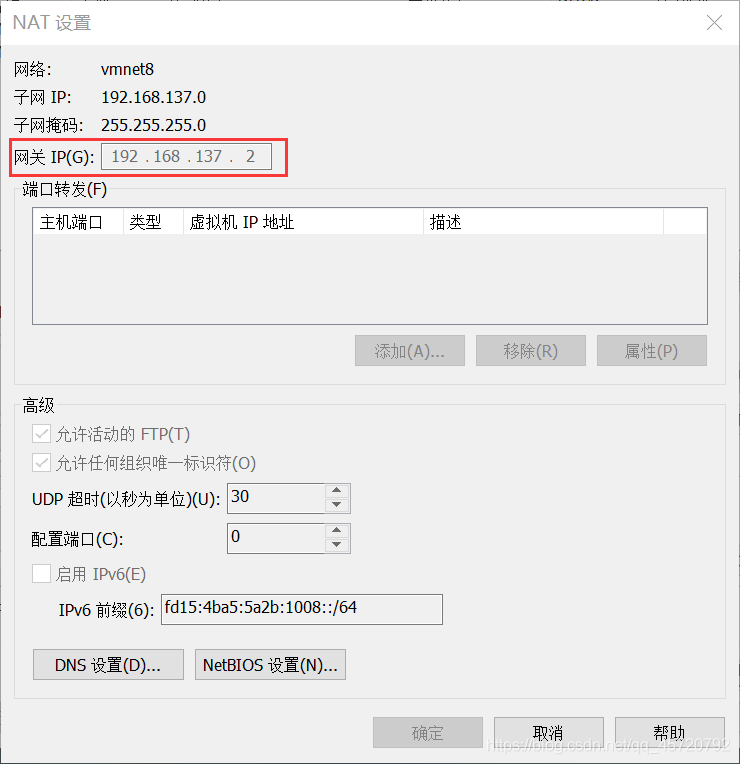
3、重启网卡
service network restart //重启网卡,使设置生效
三、配置host文件
vi /etc/hosts在四台虚拟机上编辑hosts文件
在hosts文件中增加以下内容
192.168.137.153 hadp01
192.168.137.154 hadp02
192.168.137.155 hadp03
192.168.137.156 hadp04

四、配置防火墙
(4台虚拟机均需配置该项目)
systemctl status firewalld.service 查看防火墙状态
active(running) 防火墙为开启状态
disavtive(dead) 防火墙为关闭状态
systemctl stop firewalld.service禁止防火墙服务器
再次查看防火墙状态,确保为disavtive(dead)
reboot 重启CentOS系统,即时生效
防火墙为开启状态

防火墙为开启状态

五、Xshell远程连接虚拟机
在操作多台虚拟机时,使用Xshell可以使操作更加简便,但不使用也可以
新建会话
名称:连接名
主机:虚拟机 IP

用户身份验证
创建完毕后,连接就好
六、Centos系统—jdk的安装
1、下载jdk
Windows系统中下载jdk文件
链接1: link.(https://pan.baidu.com/s/1cna38PQykYN03Hy_bUZ9pw 提取码:a42v)
链接2(oracle官网下载): link.(https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
2、上传jdk
创建目录(置放安装文件)
mkdir -p /home/root/apps //在root目录下创建apps文件夹
将Windows系统中下载好的jdk-8u73-linux-x64.tar.gz上传至/home/root目录下
禁止!!!:此处严禁通过VMware tools工具,从Windows系统中将jdk安装包文件直接拖拽至虚拟机中,这个方法传输的文件很有可能都不完整,在解压的过程中将会出现如下异常提示
tar: 归档文件中异常的 EOF
tar: 归档文件中异常的 EOF
tar: Error is not recoverable: exiting now
这种方法通过后续的安装步骤,尽管jdk安装成功了,但显示的版本却是openjdk(Centos自带的jdk),这种情况就是安装出错,后续启动hadoop时将会出现路径上的问题
解决方法:使用Xftp上传jdk文件
链接: link.(https://pan.baidu.com/s/1oHCoCmxxLuTiE4JOyVZE6w 提取码:ntsi)
3、安装jdk
cd /home/root //进入root目录
tar -zxvf jdk-8u73-linux-x64.tar.gz -C apps // 将jdk解压至指定目录中(/home/root/apps)
4、配置jdk环境变量
vi /etc/profile //编辑/etc/profile文件
在文件的末尾设置JAVA环境变量(添加以下语句)
export JAVA_HOME=/home/root/apps/jdk1.8.0_73
export PATH=$PATH:$JAVA_HOME/bin
(jdk1.8.0_73,可在/home/root/apps路径下查看jdk的版本号,即文件夹名)
vim操作不熟练的小可爱们,见链接: link.(https://blog.csdn.net/qq_45720792/article/details/107300929)
source /etc/profile // 让修改后的/etc/profile文件立即生效
java -version //查看jdk版本信息
若版本信息与安装包一致,则安装成功
番外篇:
如果安装成openjdk,如何再调试为想要安装的jdk版本jdk1.8.0_73(即上传安装包的jdk版本)
1、查看jdk版本信息
java -version //查看jdk版本信息

此时显示的版本为:openjdk1.8.0_102
2、查找openjdk相关文件
rpm -qa |grep java //查出openjdk相关的文件

如图,我们可以看到相关文件有4个:
java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
3、删除openjdk
rpm -e --nodeps+文件名 //删除该文件
把这4个openjdk都删除:
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
4、查看jdk版本信息
java -version //查看jdk版本信息

此时,显示没有安装jdk
5、重新安装
我们将/home/root/apps/目录下的jdk1.8.0_73文件夹删除,可以用Xftp删除(可能会有残留,不过没事,我们重新解压时会覆盖它)
cd /home/root //进入root目录(若在该目录内,忽略该步)
tar -zxvf jdk-8u73-linux-x64.tar.gz -C apps // 将jdk重新解压至指定目录中(/home/root/apps)
source /etc/profile // 刷新/etc/profile文件
java -version //查看jdk版本信息
若版本信息与安装包一致,则安装成功
七、Centos系统—hadoop的安装
1、安装wget
yum install wget
2、下载hadoop安装包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
3、安装hadoop
cd /home/root //进入root目录(若已经在该目录下,则忽略该步)
tar -xzvf hadoop-2.7.7.tar.gz -C apps //将hadoop安装包解压到目录(/home/root/apps)中
4、配置Hadoop环境变量
vi /etc/profile //编辑/etc/profile文件
在文件的末尾设置JAVA环境变量(添加以下语句)
export HADOOP_HOME=/home/root/apps/hadoop-2.7.7 export
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
vim操作不熟练的小可爱们,见链接: link.(https://blog.csdn.net/qq_45720792/article/details/107300929)
source /etc/profile // 让修改后的/etc/profile文件立即生效
hadoop //检查是否安装成功
`
八、配置SSH免密登录
(该项目仅在hadp01上执行)
生成公私钥
ssh-keygen -t rsa //生成公私钥
按三次回车键
执行完毕后,将在用户主目录下生成.ssh文件夹,其中包括公私钥文件。
发送公私钥
把公钥发送到各服务器端(发送前要保证各虚拟机服务器已通过root用户登录)
ssh-copy-id -i ~/.ssh/id_rsa.pub hadp01 //把公钥发送到hadp01
ssh-copy-id -i ~/.ssh/id_rsa.pub hadp02 //把公钥发送到hadp02
ssh-copy-id -i ~/.ssh/id_rsa.pub hadp03 //把公钥发送到hadp03
ssh-copy-id -i ~/.ssh/id_rsa.pub hadp04 //把公钥发送到hadp04
通常情况下,我们只需要保证hadp01可以SSH免密登录其它机器即可。
九、Hadoop集群配置
cd /home/root/apps/hadoop-2.7.7/etc/hadoop///进入至/hadoop-2.7.7/etc/hadoop/目录下
slaves
slaves文件:设置运行datanode的机器
vi slaves //修改slaves文件
hadp01
hadp02
hadp03
hadp04
core-site.xml
vi core-site.xml //修改core-site.xml文件
fs.defaultFS
hdfs://hadp01:9000
hadoop.tmp.dir
/home/root/apps/hadoop-2.7.7/tmp
hdfs-site.xml
vi hdfs-site.xml //修改vi hdfs-site.xml文件
dfs.name.dir
/root/hdfs/name
dfs.data.dir
/root/hdfs/data
dfs.namenode.secondary.http-address
hadp02:50090
dfs.namenode.secondary.https-address
hadp02:50091
mapred-site.xml
vi mapred-site.xml //修改mapred-site.xml文件
mapreduce.framework.name
yarn
yarn-site.xml
vi yarn-site.xml //修改yarn-site.xml文件
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadp01
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.resource.cpu-vcores
2
hadoop-env.sh
vi hadoop-env.sh //修改hadoop-env.sh文件
将默认的export JAVA_HOME=${JAVA_HOME}
替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_73
yarn-env.sh
vi yarn-env.sh //修改yarn-env.sh文件
将默认的# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_73
别忘记删除这一行最前面的#
十、Hadoop的克隆
将hadp01上已经配置好的文件拷贝至hadp02、hadp03、hadp04上。这样做的好处,是节省大量的时间和操作量,并且能够有效的避免每台虚拟机产生的错误。
文件的拷贝
cd /home/root/apps //进入存放jdk和hadooop的目录下
scp -r jdk1.8.0_73 hadp02:$PWD //将hadp01上的jdk拷贝至hadp02
scp -r hadoop-2.7.7 hadp02:$PWD //将hadp01上的hadoop拷贝至hadp02
scp -r /etc/profile hadp02:/etc/ //将hadp01上的profile文件拷贝至hadp02
scp -r jdk1.8.0_73 hadp03:$PWD //将hadp01上的jdk拷贝至hadp03
scp -r hadoop-2.7.7 hadp03:$PWD //将hadp01上的hadoop拷贝至hadp03
scp -r /etc/profile hadp03:/etc/ //将hadp01上的profile文件拷贝至hadp03
scp -r jdk1.8.0_73 hadp04:$PWD //将hadp01上的jdk拷贝至hadp04
scp -r hadoop-2.7.7 hadp04:$PWD //将hadp01上的hadoop拷贝至hadp04
scp -r /etc/profile hadp04:/etc/ //将hadp01上的profile文件拷贝至hadp04

文件的刷新
在虚拟机hadp02、hadp03、hadp04上分别执行source命令
source /etc/profile //使修改后/etc/profile文件立即生效
十一、Hadoop的格式化与启动
(该项目仅在hadp01上执行)
格式化
cd /home/root/apps/hadoop-2.7.7/ //进入至hadoop目录下
bin/hadoop namenode -format //格式化namenode
hadoop version //查看Hadoop版本信息

启动
sbin/start-all.sh //启动Hadoop

在Windows中启动浏览器查看运行情况(即使用外网查询,IP+端口号)
YARN
YARN的Web端口号是8088
http://192.168.137.153:8088/


HDFS
HDFS的Web端口号是50070
http://192.168.137.153:50070/
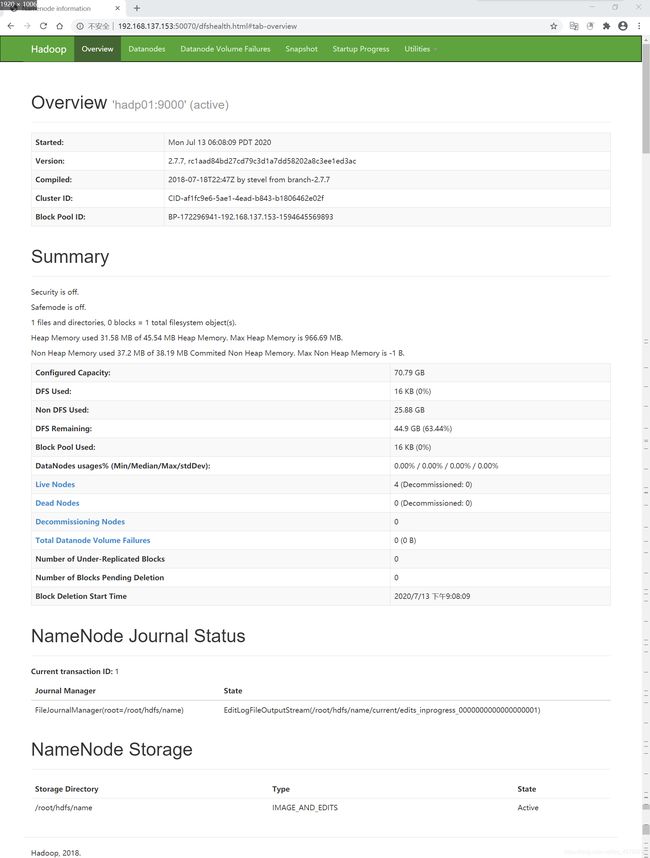
常见错误:可以打开YARN或HDFS任意一端口,但另外一个无法打开,输入jps时,也可以看见相应的节点未开启
解决方法:重新格式化并重启
jps
jps //查看各个虚拟机节点启动的状况

十二、Hadoop的停止
sbin/stop-all.sh //停止Hadoop

伪分布式Hadoop的搭建,请见链接: link.
https://blog.csdn.net/qq_45720792/article/details/107333127