无人驾驶动态避障策略调研 | 机器人动态避障策略 | 行人轨迹预测 | 机器人导航
目录
- 1.无人驾驶
- 2.无人驾驶避障
-
- 2.1运动障碍物检测
- 2.2运动障碍物碰撞轨迹预测
- 2.3运动障碍物避障
- 3.机器人导览避障场景
-
- 3.1 机器人动态避障&自主导航
- 4.如何处理行人
-
- 4.1 行人轨迹预测
- 5. 一些重要概念:
-
- 5.1 动态窗口避障
- 5.2 分布式强化学习与集中式强化学习
- 6.个人总结
-
- 6.1 避障步骤:
- 6.2 协同路径规划 VS 机器人动态避障、机器人导航
- 6.2 为什么不直接使用多智能体强化学习算法?
最近在研究机器人协同路径规划策略,发现现有paper中的obstacle都是静态的,但是在实际场景中,常有动态障碍的情形,如走动的行人等等。
为了更好的了解相关技术,我开始调研无人驾驶领域中的动态避障策略:
1.无人驾驶
无人驾驶技术是多个技术的集成,包括了传感器、定位与深度学习、高精地图、路径规划、障碍物检测与规避、机械控制、系统集成与优化、能耗与散热管理等等。虽然现有的多种无人车在实现上有许多不同,但是在系统架构上都大同小异。

上图中,GPS、光学雷达与高精地图主要用来定位,这里主要就是采用一些诸如卡尔曼滤波的滤波算法与高精地图做对比或者Iterative Closest Point(迭代最近点算法),实现定位的功能;光学雷达与照相机主要用来做物体识别,这里我们可以用一些视觉算法来做物体识别;最后通过定位与物体识别,我们根据位置信息以及识别出的图像信息(如红绿灯)实时调节车辆的行车计划,并把行车计划转化成控制信号操控车辆(这里面还会用到增强学习算法来优化决策过程)。全局的路径规划可以用类似A-Star的算法实现,本地的路径规划可以用DWA(局部避障的动态窗口算法)等算法实现。
在UGV领域,通常是先利用视觉方法识别物体,再调整行驶计划。车身周围的定量感知对于无人驾驶技术非常关键,无人驾驶系统采用了大量传感器,其中可视为广义“视觉”的有超声波雷达、毫米波雷达、激光雷达(LiDAR)和摄像头等。
计算机视觉需要进行物体的识别与跟踪,以及车辆本身的定位:
-
物体的识别与跟踪:通过深度学习的方法,我们可以识别在行驶途中遇到的物体,比如行人、空旷的行驶空间、地上的标志、红绿灯以及旁边的车辆等。由于行人以及旁边的车辆等物体都是在运动的,我们需要跟踪这些物体以达到防止碰撞的目的,这就涉及到Optical Flow等运动预测算法。光流估计——从传统方法到深度学习 - 肖泽东 Shon的文章 - 知乎
-
车辆本身的定位:通过基于拓扑与地标算法,或者是基于几何的视觉里程计算法,无人车可以实时确定自身位置,满足自主导航的需求。
2.无人驾驶避障
- 运动障碍物检测:对运动过程中环境中的运动障碍物进行检测,主要由车载环境感知系统完成。(很明显,从常识角度看,避开障碍物的第一步就是检测障碍物。)
- 运动障碍物碰撞轨迹预测:对运动过程中可能遇到的障碍物进行可能性评级与预测,判断与无人驾驶车辆的碰撞关系。(当你检测到障碍物后,你就得让机器判断是否会与汽车相撞)
- 运动障碍物避障:通过智能决策和路径规划,使无人驾驶车辆安全避障,由车辆路径决策系统执行。(判断了可能会与汽车发生碰撞的障碍物后,你就得去让机器做出决策来避障了)
2.1运动障碍物检测
主要有两类传感器,一种是基于激光雷达和毫米波雷达的,一种是基于立体视觉的
- 激光雷达:① 地图差分法。根据在高精度地图上的障碍物在不同时刻与本车的相对位置关系,来求解障碍物的运动信息。即在全局坐标系中,静态障碍物的位置不会随时间变化,而动态障碍物则会随时间变化,发生变化的部分即认为是运动障碍物。② 实体类聚法。将同一个障碍物的点云数据聚成一类,一般采用长方体或多边形体来描述车辆、自行车、行人等。 ③ 目标跟踪法。目标跟踪法指对障碍物进行轨迹跟踪从而获得运动信息。由于在多目标环境下数据的关联性和激光雷达传感器的必然误差,不同时刻的目标关联需要按情况分类讨论。
- 立体视觉:① 将地图划分为多个网格,再判断 ② scene flow segmentation(很火),Optical Flow是图片序列或者视频中像素级的密集对应关系,例如在每个像素上估算一个2维的偏移矢量,得到的Optical Flow以2维矢量场表示。③ 集合聚类,对三维空间中点云形成的几何形状做聚类。
2.2运动障碍物碰撞轨迹预测
无人车的感知系统需要实时识别和追踪多个运动目标(Multi-ObjectTracking,MOT),计算机视觉领域大量使用CNN,物体识别的准确率和速度得到了很大提升,但总的来说物体识别算法的输出一般是有噪音的:物体的识别有可能不稳定,物体可能被遮挡,可能有短暂误识别等。
MOT问题中流行的Tracking-by-detection方法就要解决这样一个难点:如何基于有噪音的识别结果获得鲁棒的物体运动轨迹。在ICCV 2015会议上,斯坦福大学的研究者发表了基于马尔可夫决策过程(MDP)的MOT算法来解决这个问题。

对障碍物的运动轨迹预测,有以下三类方法:
- 静态处理:不考虑任何运动特性,因此效果较差
- 假设状态保持不变:认为障碍物会保持当前运动状态,适用于直道匀速场景
- 概率轨迹模拟法:前一种方法的改进,对障碍物的未来行驶轨迹做了预测,对于高精度地图或结构化道路的先验信息可以获得较好的预测结果。
2.3运动障碍物避障
在路段上有未知障碍物的情况下,按照一定的评价标准,寻找一条从起始状态到目标状态的无碰撞路径。典型的方法有人工势场法、反应式避障法(感知到前方有障碍,就重新规划路线)、区域划分法(将周围划分成安全区域和可能碰撞区域)。。。
路径规划分为两大类,全局规划与局部规划。为了提高全局重规划计算效率,一般在全局规划之外增加局部规划以提高规划系统的实时性。
- 全局规划指已知全局环境信息,在有障碍物的全局地图中按照某种算法寻找合适的从起始位置到目标位置的无障碍无碰撞路径。
- 局部路径规划是指在无法取得全局环境信息的情况下,只能利用多种传感器来获取移动机器人自身的状态信息的周围的局部环境信息,实时地规划理想的不碰撞局部路径,一般只在短时间内有效。
方法:势场法、模糊逻辑法、神经网络法、占据栅格法、空间搜索法和基于数据融合的直接规划方法。
3.机器人导览避障场景
- 与无人驾驶重点关注周围车辆不同,机器人导览场景主要是避免与动态行人发生碰撞。
- 无人驾驶用到了很多传感器(激光、视觉、红外、超声波),雷达,GPS系统,使得汽车能够在未知环境下也能成功避障。但在机器人导览场景中,室内地图是已知的,环境也更加简单,因此实现技术上应避免过于复杂的算法,特别是cv领域的方法。
3.1 机器人动态避障&自主导航
因此,我又专门调研了机器人动态避障和机器人自主导航这个方向,找到了以下论文:
-
移动机器人在复杂环境下的动态避障(哈工大):输入为激光雷达扫描数据、目标位置坐标参数以及机器人本体的速度信息,基于这些参数可直接输出用于机器人灵活避障的速度指令。使用3D激光雷达与超宽带定位系统相结合的导航避障传感系统,同时优化了传感器的连接与供电方案,使得传感器得以顺利部署在莱卡狗机器人上。
-
基于势场法的无人车局部动态避障路径规划算法(北理):建立了包含障碍物和目标点的行车风险场,设置动态避障窗口,在每个避障窗口内对避障路径不断进行规划. 通过改进势场力来解决复杂环境下目标不可达和局部最优的问题.
动态避障策略:根据障碍物的运动方向,建立一条以障碍物当前位置坐标为起点,指向障碍物运动方向的射线借此判断是否会与车辆相撞。
当障碍物车辆靠近点P且到自我车辆的距离大于安全距离,那么自我车辆将维持原状态行驶. 若障碍物到自我车辆的距离小于安全距离,那么自我车辆就需提前减速甚至制动,以此来规避碰撞的发生。 -
移动机器人动态避障算法:利用摄像镜头采集动态障碍物的移动轨迹,提取形心序列,利用RBFNN建立预测模型.在移动机器人实时规划时,根据当前位置在超声波传感器的扫描范围内建立滚动窗口.当检测到动态障碍物进入滚动窗口以后,才开始进行预测计算.根据动态障碍物相邻时刻的三个时间序列值,来预测障碍物下一时刻的运动轨迹,从而把动态障碍物的避障问题转化为瞬时静态障碍物的避障问题,实现实时规划.
-
全向移动机器人动态避障方法 :① 改进人工势场法通过创建水流场坐标系,改善了传统人工势场法易陷入局部极小值点、目标点不可达及轨迹振荡等问题。② 通过斥力场修正方向,解决了改进人工势场法穿 透重叠障碍物的问题,保证了方法的可靠性。
机器人能获取到自身位置、目标点位置以及机器人利用传感器测得的障碍物距离和方向。出现动态障碍物,就改变势场。 -
AS-R移动机器人的动态避障与路径规划研究:利用多传感器结合检测方法,通过红外传感器减少盲区和镜面反射带来的误差,通过间隔采样或分组采样技术避免多路串扰问题;对均值滤波与中值滤波进行实验对比后,提出一种递推型中值滤波方法,从而提高了数据在空间和时间上的连续性,有效地减少了超声波随机串扰信号及其它千扰信号,进而提高了探测模块的准确度。
-
Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning:在学习过程中机器人之间共享奖励、策略网络和值函数网络,通过共享的经验样本来引导相互之间达成隐式的协作机制;传感器级的防碰撞策略,能用于100个机器人的大规模场景;分布式,根据环境信息进行场景分类,从而采取不同的运动策略,以提高效率和保证安全;用到的策略是policy gradient。也涉及到动态障碍物。视频 (经典)

-
Fully Distributed Multi-Robot Collision Avoidance via Deep Reinforcement Learning for Safe and Efficient Navigation in Complex Scenarios:多机器人、复杂环境、分布式,用到的是PG算法,适用于large-scale multi-robot systems;已经在真实机器人上部署过了。
-
DeepMNavigate: Deep Reinforced Multi-Robot Navigation Unifying Local & Global Collision Avoidance
-
Decentralized Non-communicating Multiagent Collision Avoidance with Deep Reinforcement Learning:使用RL,把开销巨大的在线的计算降解为离线的学习过程;(经典)
-
Socially Aware Motion Planning with Deep Reinforcement Learning:考虑到了机器人和人之间的避碰问题,在策略训练是引入一些人类社会的规则,让机器人的策略学习到显式的协调机制,达成机器人与人的行为之间的协作;可以在有许多行人的环境中实现以人类步行速度移动的机器人车辆的完全自主导航 (经典)
github项目:rl-collision-avoidance,Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning的代码。使用的RL算法是PPO。
4.如何处理行人
存在行人时:
- 将行人视为动态障碍,使用特定的反应规则来避免碰撞。但不能理解人类行为,有时会产生不安全、不自然的行为。尤其移速与行人相近时。
- 改进做法:推理行人的意图,并生成预测轨迹,再用传统路径规划算法生成无碰撞的路径。但将预测和规划分离的做法会导致freezing robot problem。
- 考虑协同(account for cooperation),建模并预测附件行人对机器人运动的影响。
4.1 行人轨迹预测
Social LSTM: Human Trajectory Prediction in Crowded Spaces
SocialLSTM:整合了行人自身轨迹和周围人群影响(人们会互相避让),把每个人看作lstm,在每个时刻把每个人周边的人的lstm隐状态拿出来做一个pooling, 这样就能体现这种动态的行人互动。
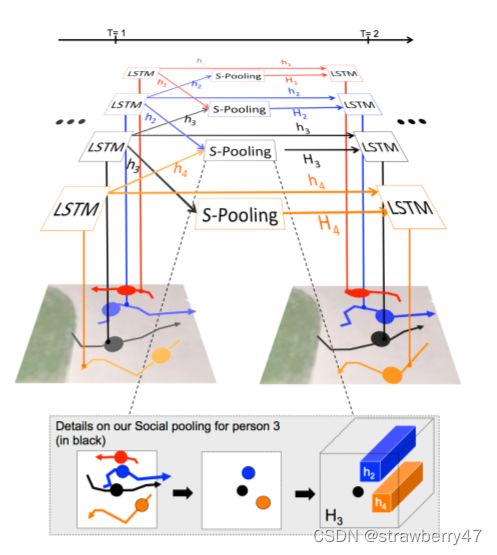
针对的是一群行人(群体行为,行人行走会互相影响),使用到的数据集是 ETH和UCY(两个公开的行人轨迹数据集)。
下图是实验结果,可以明显看出行人间的避障现象:
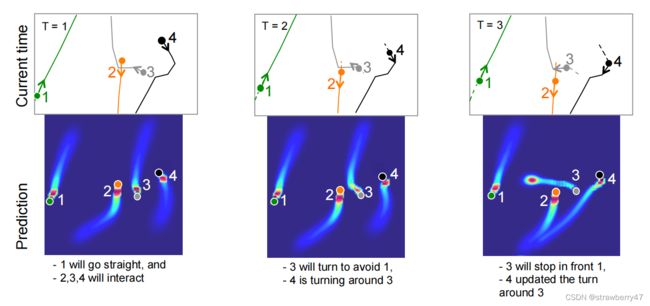
和别的方法相比,可以更好地预测行人轨迹:
关于数据集::是鸟瞰视角(类似监控视角下的轨迹预测)
- EWAP的数据集包括两个sequence:eth和hotel;文件格式:[frame_number pedestrian_ID pos_x pos_z pos_y v_x v_z v_y ]。也存在障碍物,但是在论文中未看见如何避障。
- UCY的数据集包括三个sequence:student、univ和zara,还有分zara01,zara02等,文件格式: [x y frame_number gaze_direction]
评价指标:主要是MSE
思考:我们将机器人看作行人,能获取到轨迹信息,那我们可以基于当前机器人和周围机器人的轨迹信息预测下一步位置。
问题:
① 我们并没有groundtruth来指导整个过程 -> 只能通过reward进行指导?
② 只考虑了agent间的信息,未考虑到行人信息 -> 想办法也获取到行人坐标?
③ 并没有历史运动轨迹信息,让机器人随机走构成初始数据,好像说服力不够。
SA-CADRL(socially aware collision avoidance deep reinforcement learning)更加适合人群防碰撞场景。
Social LSTM 实现代码分析
5. 一些重要概念:
5.1 动态窗口避障
动态窗口避障算法:思想是对可行空间的速度进行采样,并对每一个速度样本进行轨迹预测,然后利用评价函数来对每一条轨迹进行评分,并取最优的速度样本发送给执行器执行。
注意哈,这里的动态窗口并不是xy坐标系的范围,而是动态的线速度v角速度w的范围,因为不同的角速度线速度对应着不同的采样轨迹
5.2 分布式强化学习与集中式强化学习
decentralized and centralized methods,多智能体中一般分为分布式强化学习和集中式强化学习:
① 分布式强化学习系统中的各个agent都是学习的主体,它们分别学习对环境的响应策略和相互之间的协作策略。
② 集中式强化学习通常把整个多agent系统的协作机制看成学习的目标.承担学习任务的是一个全局性的中央学习单元,这个学习单元以整个多agent系统的整体状态为输入.以对各个agent的动作指派为输出.采用标准的强化学习方法进行学习.逐渐形成一个最优的协作机制。
多智能体强化学习和分布式强化学习的区别?
其中分布式强化学习还可以分类:根据系统中的agent进行决策时是否考虑其他agent的动作可以分为,分别命名为独立强化学习(reinforcement learning individually,RLI)和群体强化学习(reinforcement learning ingroups,RLG)。
- RLI方法不采用组合动作(joint-action),其agent仅凭自己的状态输入来决定采取的动作,可以看作是一种松散耦合的分布式强化学习系统,可与社会模型或经济模型结合形成社会强化学习;RLI系统中的agent都是以自我为中心的,所以不易达到全局意义上的最优目标;但是RLI系统中agent的独立性较强,容易动态增减agent的个数,而且agent个数的变化对学习收敛性的影响较小,所以RLI方法较适用于agent个数较多的复杂系统.
- RLG方法采用组合动作,每个agent都必须考虑到其他所有agent将要采取的动作才能决定自己采取的动作,可以看作是一种紧密耦合的分布式强化学习系统;学习速度很慢,这种“紧密耦合”的方法一般只适用于agent很少的情况下,而且需要加速算法的支持.
现在很多方法都是分布式算法,因为集中式的路径规划方法应对大规模智能体时需要很多算力,state-action空间组合爆炸。
虽然是分布式,但也要考虑协同:① 预测别的agent的动作,agent数量多了就不再适用; ② 可以一起训练所有agent的experience,即 集中式学习。
6.个人总结
6.1 避障步骤:
既然要避障,就需要知道周围障碍物的位置和速度,预测是否会相撞。一般分为三个步骤:
- 障碍物检测:一般采用传感器或摄像头,关注到 光流传感器可以估计物体的速度。
- 障碍物轨迹预测: 比较简单的方法是基于行人过去的速度和方向,预测下一时刻的位置坐标,判断是否会与机器相撞。 如果采用摄像头的视觉信息判断,则涉及到图像识别;如果采用传感器,每台机器人配备多个方向的传感器,是不是更容易一点呢?
- 避障:最简单的避障方法就是停下来,也可以选择转弯等方法
因此,整个避障板块的输入应该是传感器or摄像头收集到的信息,根据这些信息预测行人下一时刻的坐标,用于判断是否会相撞,输出机器人应采取的路径。
6.2 协同路径规划 VS 机器人动态避障、机器人导航
三者的任务很类似,不过也有一些区别:
-
MAPF把重点放在路径规划以及多智能体协同上了,很少考虑动态障碍的问题。如:
① conflict-based search (无冲突搜索):低层次搜索负责找出一条路,高层次搜索负责检查路径冲突
② 避障算法ORCA整理–精简版:考虑了速度和方向
③ M*:改造A*算法,先为每个机器人单独规划,然后根据需要协调机器人之间的运动

④ 基于RL的方法:比较经典的RL方法有PRIMAL和PRIMAL2。But,现有方法大多并未用到多智能体强化学习的算法。
这类算法的action一般是 上、下、左、右、停止。 -
机器人动态避障和机器人导航文章中,他们的重点是自主导航;经典方法:Socially Aware Motion Planning with Deep Reinforcement Learning, Decentralized Non-communicating Multiagent Collision Avoidance with Deep Reinforcement Learning, Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning
这类方法的action一般是角速度和速度。
我们的机器人导览场景:集中式训练 + 有动态行人障碍 + 有起始点和终点 + 自主导航(路径规划)
6.2 为什么不直接使用多智能体强化学习算法?
万字长文:详解多智能体强化学习的基础和应用
多智能体路径规划、多智能体动态避障,都涉及到了multi-agent,那为什么不直接将MARL的方法用上来呢?
其实很多用到了MARL的思想,比如MADDPG的集中式训练分布式执行。
个人思考,猜测是MARL的设定(完全竞争关系、完全合作关系、混合)并不能很好地挪用到当前场景?
他们也是基于single-agent方法设计的,那我们也可以根据MAPF场景设计更有针对性的算法。
MARL也只是一个概念吧,我们针对多个机器人的导航场景设计算法,不也是多智能体强化学习嘛
和MADDPG类似,很多multi-robot navigation方法也是集中式学习和分布式执行的机制。