如何使用决策树来预测(2)--sklearn建模实操
本文是决策树系列的第二篇,主要是代码实操,以汽车违约贷款数据集accepts.csv为例,详细讲解如何在sklearn中使用决策树进行建模、可视化、参数调优等。附数据集下载链接:逻辑回归介绍及statsmodels、sklearn实操数据集--accepts.csv-数据挖掘文档类资源-CSDN下载
目录
一、DecisionTreeClassifier参数详解
二、决策树建模案例及可视化
2.1、引入建模所需要的包
2.2、读入数据并进行处理
2.3、建模及预测
2.4、对建模结果进行可视化
三、决策树的调优
3.1 单个参数的学习曲线
3.2 网格搜索
一、DecisionTreeClassifier参数详解
引入sklearn的DecisionTreeClassifier模块后,使用快捷键shift+tab查看其参数及其使用方法。如下是决策树中较为重要的参数,主要分为建树参数、剪枝参数,参数说明如下:
| 参数分类 | 参数名 | 参数说明 |
| 建树参数 | criterion | 决策树的建树的准则,也就是决策树找最佳节点和分枝的方法,有信息熵和gini系数两种,即 entropy 和 gini, 默认为gini |
| splitter | 每个节点分裂的策略,有best 和 random两个参数, 默认为bset | |
| class_weight | 正负样本的权重,取值示例 {0:1, 1:3} | |
| 剪枝参数 | max_depth | 前剪枝参数:设置数的最大深度 |
| min_samples_split | 每个节点分裂的最小样本数 | |
| min_samples_leaf | 每个叶子节点存在至少需要的样本数 | |
| min_weight_fraction_leaf | 一个叶节点要存在所需要的权重占输入模型的数据集的总权重的比例,基于权重来剪枝,使用class_weight 时,可用该参数进行剪枝,比 min_samples_leaf 更偏向主导类 | |
| max_features | 限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃,和max_depth作用类似,但方法比较暴力。 | |
| max_leaf_nodes | 最大的叶子结点数量,在最佳分枝下,以该值来限制树的生长 | |
| min_impurity_decrease | 当一个节点分枝后不纯度下降大于或者等于 min_impurity_decrease 时,则这个分枝会保留 | |
| min_impurity_split | 结点分裂往下分裂的最小不纯度 |
二、决策树建模案例及可视化
2.1、引入建模所需要的包
必备基础包numpy、pandas、matplotlib,其次是sklearn建模必备测试/训练集划分、决策树、模型效果评估等模块。
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 划分训练集与测试集
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn import metrics # 模型评估模块
import graphviz # 图形可视化,用户可视化决策树
from sklearn import tree # sklearn中的树模块,用于导出决策数的dot格式
from sklearn.model_selection import ParameterGrid, GridSearchCV # 网格搜索2.2、读入数据并进行处理
该数据集为车贷违约数据,目标变量为bad_ind 是否违约,其余是特征变量,挑选和目标变量相关性较强的特征,并对贷款金额和收入进行加工处理,生成新变量贷款月数,并对离散变量bankruptcy_ind曾经是否破产字段进行0-1转化。sklearn中只实现连续变量的重要性计算,没有名义变量的重要性计算方式,因此当有名义变量时,需要将其进行WOE转化,转为等级类型。如果是二分变量将其转为0-1变量即可。
accepts = pd.read_csv('./data/accepts.csv', skipinitialspace = True)
accepts = accepts.dropna(axis = 0, how = 'any') # 删除空行
target = accepts['bad_ind']
x = ['bankruptcy_ind','tot_derog','tot_tr','age_oldest_tr','tot_open_tr','tot_rev_tr','tot_rev_debt','tot_rev_line','rev_util','fico_score','purch_price','msrp','down_pyt','loan_term','loan_amt','ltv','tot_income','veh_mileage','used_ind']
data = accepts[x]
data['lti_temp'] = data['loan_amt'] / data['tot_income'] # 贷款月数:贷款金额/收入
data['lti_temp'] = data['lti_temp'].map(lambda x: 10 if x >= 10 else x) # 月数大于10
del data['loan_amt']
data['bankruptcy_ind'] = data['bankruptcy_ind'].replace({'N': 0, 'Y': 1}) # 转为0-1变量
data.head()2.3、建模及预测
首先划分训练集、测试集,在训练集上进行训练,在测试集上预测并用classification_report输出模型分类报告,该方法能看到预测模型在正负样本上的准确率、查全率、f1分数、支持度等,能够更全面的了解模型的预测效果。
# 划分训练集/测试集
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size = 0.2, random_state = 1234)
# 引入决策树模型
clf = DecisionTreeClassifier(criterion = 'gini'
, max_depth = 3
, random_state = 20)
clf.fit(x_train, y_train) # 模型训练
y_pred = clf.predict(x_test) # 在测试集上做预测
print(metrics.classification_report(y_test, y_pred)) # 输出分类报告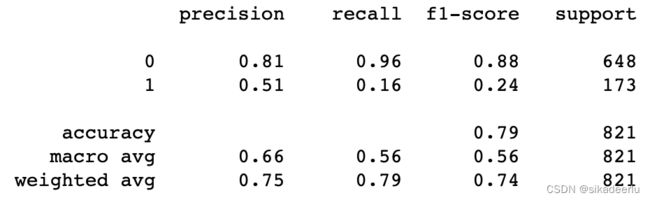
2.4、对建模结果进行可视化
对决策树可视化,首先要用tree.export_graphviz生成dot格式,然后用graphviz包对其进行可视化,可视化结果在jupyter中可直接显示。使用pydotplus包,可将可视化结果保存为pdf文件,存储到本地。
feature_name = data.columns # 特征对应的字段名
# 生成决策树的dot格式
dot_data = tree.export_graphviz(clf
,feature_names= feature_name
,class_names=["0","1"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data) # 将决策树进行可视化
graph # 在jupyter 中输出决策树可视化图形
import pydotplus # 是graphviz的点语言提供了一个python接口
graph1 = pydotplus.graph_from_dot_data(dot_data)
graph1.write_pdf('tree.pdf') # 将决策树保存到pdf中下图是决策树的
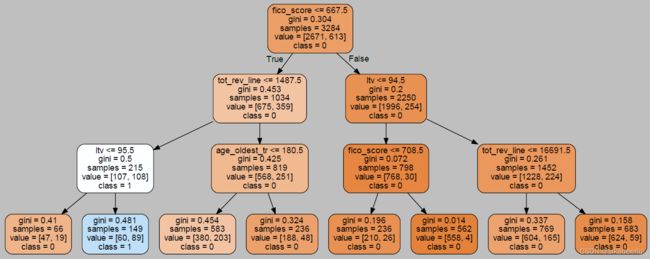
三、决策树的调优
在讲模型调优时,第一步就是要明确我们的目标是什么,对预测来说一般我们追求的是模型在新的样本集上,预测的准确率要高;其次是这个准确率受什么影响,怎么才能优化它。
一般来说我们模型评估的指标有查准率(预测为正样本中有多少预测对了)、查全率(所有正样本中有多少被预测出来了)、f1-score(查准率与查全率的调和平均)、auc(roc曲线构成的面积)等,可以根据业务场景挑选不同的指标作为主要调优的目标。在本案例中,主要以f1-score为主进行调优,通过调整建树参数、剪枝参数来优化测试集上模型的预测效果。
在进行参数调优时,可以对单个参数画学习曲线的方式寻找最优参数,也可以运用网格搜索的方式找到最优的参数组合,以下是代码示例。
3.1 单个参数的学习曲线
max_depth = np.arange(2, 10) # max_depth参数的取值范围
train_f1_scores = [] # 训练集f1-score结果
test_f1_scores = [] # 测试集f1-score结果
for i in max_depth:
clf = DecisionTreeClassifier(criterion = 'gini'
, max_depth = i
, class_weight = {0:1, 1:3}
, random_state = 20)
clf.fit(x_train, y_train)
y_pred_train = clf.predict(x_train)
train_f1_scores.append(metrics.f1_score(y_train, y_pred_train))
y_pred = clf.predict(x_test)
test_f1_scores.append(metrics.f1_score(y_test, y_pred))
# 画出训练、测试集上f1-score随着max_depth的变化趋势
plt.plot(max_depth, train_f1_scores, color = 'red')
plt.plot(max_depth, test_f1_scores)
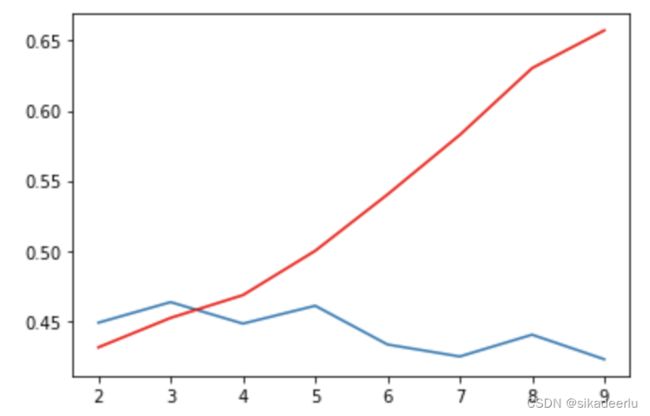
红色曲线是训练集上得分,蓝色是测试集得分,可以看到随着树的深度增加,训练集上的得分不断提升,但测试集得分不断下降,在树深度为3时,测试集得分最高。
3.2 网格搜索
网格搜索是一种暴力寻找参数最优值的方法,使用交叉验证来计算模型效果
clf = DecisionTreeClassifier(max_depth = 3, class_weight = {0: 1, 1: 3}, criterion = 'gini')
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size = 0.2, random_state = 1234)
max_depth = [None, ]
max_leaf_nodes = np.arange(5, 10, 1)
class_weight = [{0: 1, 1: 2}, {0: 1, 1: 3}]
param_grid = {
'max_depth': max_depth
, 'max_leaf_nodes': max_leaf_nodes
, 'class_weight': class_weight
}
clf_cv = GridSearchCV(
estimator = clf
, param_grid = param_grid
, cv = 5
, scoring = 'roc_auc'
)
clf_cv.fit(x_train, y_train)
print(metrics.classification_report(y_test, clf_cv.predict(x_test))) # 输出网格搜索最优参数所得到的模型验证报告
clf_cv.best_params_ # 输出网格搜索得到的最优参数
![]()
以上就是决策树建模的基本用法~