开源开放 | DeepKE发布新版本:支持低资源、长篇章、多任务的图谱抽取开源框架(浙江大学)...
OpenKG地址:http://openkg.cn/tool/deepke
GitHub地址:https://github.com/zjunlp/deepke
Gitee地址:https://gitee.com/openkg/deepke
DeepKE网站:http://deepke.zjukg.org/CN/index.html
开放许可协议:GPL 3.0
贡献者:浙江大学(张宁豫、陶联宽、徐欣、余海洋、叶宏彬、谢辛、陈想、黎洲波、李磊、梁孝转、姚云志、乔硕斐、邓淑敏、张文、郑国轴、陈华钧),阿里巴巴(熊飞宇、陈辉、陈强),阿里巴巴达摩院(张珍茹、谭传奇、黄非)

知识图谱以结构化的形式描述真实世界中实体间的复杂关系,是人工智能的底层支撑。依托于行业数据和深度学习技术,知识图谱已被广泛应用于诸多产业核心的场景。知识抽取是构建知识图谱的基石,一般由多个任务组成,包含如实体识别、关系抽取、属性抽取等具体抽取任务。现有的知识图谱构建工作大多假设知识图谱中的实体或关系有充足的三元组实例来训练向量表示,因此需要大量的人工标注样本。但在实际场景的知识图谱中,大量的实体或关系仅具有非常少的三元组,即存在低资源问题。对于大量垂直领域如医疗健康、金融风控等,大量的实体关系三元组知识蕴含在长篇章中不同句子的,且文档中的多个实体之间,往往存在复杂的相互关系。
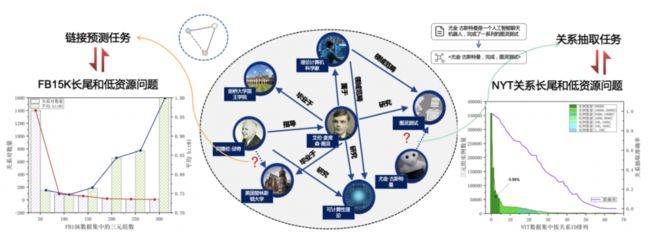
针对以上挑战,基于原DeepKE工具,本文发布知识抽取工具包新版本。新增低资源、长篇章抽取能力,并扩展到实体识别、属性抽取等多个任务,以统一的接口实现了实体识别、关系抽取、属性抽取模型:
工具新增的主要功能有:
1. 重新封装了全新的Pytorh训练测试接口,并提供了详细的Notebook Tutorial
2. 新增低资源、长篇章(关系)抽取功能
3. 新增实体抽取、属性抽取功能,覆盖更多的知识抽取任务

工具总体设计架构图如下:

1、应用场景
1.1 实体识别
实体识别的目的是从非结构化的文本中抽取出实体。比如对于句子“秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一。”“秦始皇”为人物实体,“陕西省西安市”为地点实体。本文提供常规和少样本这两个模块。
常规模块,即常用的预训练语言模型。少样本模块借鉴Prompt-tuning的思想,对于实体识别任务采用了低资源生成式的框架LightNER,通过增加模版来识别出实体,并且提出了一个全新的模版导向注意力层,即将模版加入到原有的自注意力层中。
1.2 关系抽取
关系抽取是从非结构化的文本中抽取出实体之间的关系。比如对于句子“《岳父也是爹》是王军执导的电视剧”“岳父也是爹”和“王军”这两个实体所抽取出来的关系是导演。本文提供了常规、少样本和文档级这三个模块。
常规模块,包括了六种常用的深度学习模型,有CNN、RNN、Capsule、GCN、Transformer以及预训练语言模型。
少样本模块借鉴prompt-tuning的思想,对于关系抽取任务采用KnowPrompt模型,将实体及其关系的这些知识注入到可学习的模版和答案的构造中,并且通过知识约束来协同优化模版和答案的表示。
文档级模块采用了DocuNet,首先将文本进行编码并基于实体之间的相关性来计算实体之间的初始关系矩阵。然后该初始关系矩阵通过U形分割模块得到最终的实体间关系矩阵,两实体以及该关系矩阵能够得到最终的关系。
1.3 属性抽取
属性抽取是从非结构化的文本中抽取出实体和属性值之间的属性。比如对于句子“杨缨,字绵公”需要抽取“杨缨”的属性为“绵公”。本文提供了常规抽取模块。常规抽取模块包括了六种常用的深度学习模型,有CNN、RNN、Capsule、GCN、Transformer以及预训练语言模型。
2、总体结构
DeepKE整体代码结构如下图所示:

3、基本用法
pip install deepke
1. 关系抽取
cd example/re/standard
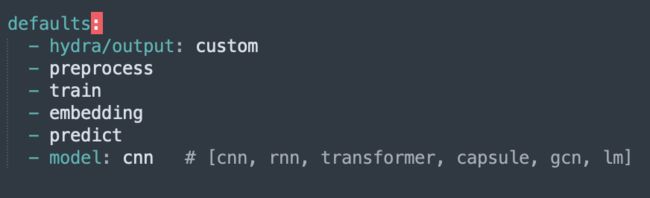
模型配置
可根据自己需求修改conf文件夹中的参数,修改config.yaml中的model可以选择使用的模型,model文件夹中可以修改具体模型的参数。
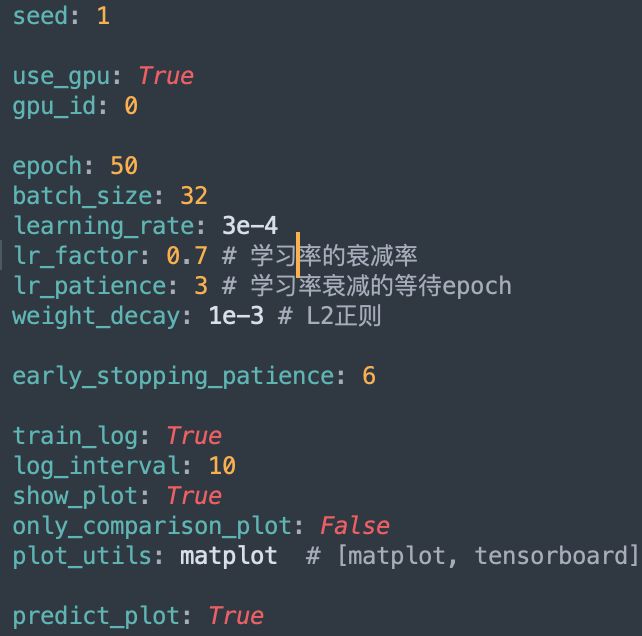
训练模型
conf文件夹中各参数可修改,训练过程可修改train.yaml中的参数,python run.py进行训练。
预测
修改predict.yaml中的参数,python predict.py进行预测
2. 属性抽取
cd example/ae/standard
剩下的流程同关系抽取
3. 实体抽取
cd example/ner/standard
剩下流程同关系抽取
4、实验效果
我们对新版本的DeepKE在多个实体识别、关系抽取、属性抽取数据集上进行了常规设定、低资源设定和长篇章设定测试,如下表所示,我们的工具可以达到甚至超越不少传统的基线模型的效果。
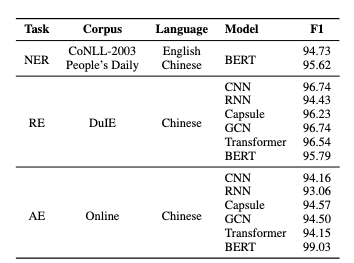
如上表所示,DeepKE可以使用和各种不同的编码器进行抽取。DeepKE还能够基于优秀的低资源抽取模型实现较好的少样本抽取性能和支持篇章级的关系抽取。如下表所示,DeepKE可以取得较好的少样本和篇章级抽取性能。


5、小结和展望
新版本的DeepKE是一个基于Pytorch实现命名实体识别、关系抽取和属性抽取功能,支持低资源、长篇章的知识抽取工具。我们同时也开发了一个在线demo展示页面,对于部分功能,无需训练和部署即可满足实时的在线知识抽取功能。在使用过程中有任何问题或是意见和建议都欢迎提出,在今后我们还将继续开发丰富模型,支持多模态知识抽取,使得未来的DeepKE功能变得更丰富更强大。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。