DeepKE发布新版本:支持低资源、长篇章、多任务的图谱抽取开源框架,开源开放

OpenKG地址:http://openkg.cn/tool/deepke
GitHub地址:https://github.com/zjunlp/deepke
Gitee地址:https://gitee.com/openkg/deepke
DeepKE网站:http://deepke.zjukg.org/CN/index.html
开放许可协议:GPL 3.0
贡献者:浙江大学(张宁豫、陶联宽、徐欣、余海洋、叶宏彬、谢辛、陈想、黎洲波、李磊、梁孝转、姚云志、乔硕斐、邓淑敏、张文、郑国轴、陈华钧),阿里巴巴(熊飞宇、陈辉、陈强),阿里巴巴达摩院(张珍茹、谭传奇、黄非)
正在上传…重新上传取消正在上传…重新上传取消
针对以上挑战,基于原DeepKE工具,本文发布知识抽取工具包新版本。新增低资源、长篇章抽取能力,并扩展到实体识别、属性抽取等多个任务,以统一的接口实现了实体识别、关系抽取、属性抽取模型:
工具新增的主要功能有:
1. 重新封装了全新的Pytorh训练测试接口,并提供了详细的Notebook Tutorial
2. 新增低资源、长篇章(关系)抽取功能
3. 新增实体抽取、属性抽取功能,覆盖更多的知识抽取任务
正在上传…重新上传取消正在上传…重新上传取消
工具总体设计架构图如下:
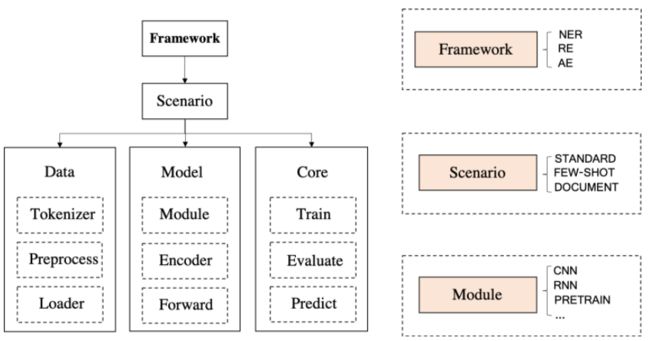
1、应用场景
1.1 实体识别
实体识别的目的是从非结构化的文本中抽取出实体。比如对于句子“秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一。”“秦始皇”为人物实体,“陕西省西安市”为地点实体。本文提供常规和少样本这两个模块。
常规模块,即常用的预训练语言模型。少样本模块借鉴Prompt-tuning的思想,对于实体识别任务采用了低资源生成式的框架LightNER,通过增加模版来识别出实体,并且提出了一个全新的模版导向注意力层,即将模版加入到原有的自注意力层中。
1.2 关系抽取
关系抽取是从非结构化的文本中抽取出实体之间的关系。比如对于句子“《岳父也是爹》是王军执导的电视剧”“岳父也是爹”和“王军”这两个实体所抽取出来的关系是导演。本文提供了常规、少样本和文档级这三个模块。
常规模块,包括了六种常用的深度学习模型,有CNN、RNN、Capsule、GCN、Transformer以及预训练语言模型。
少样本模块借鉴prompt-tuning的思想,对于关系抽取任务采用KnowPrompt模型,将实体及其关系的这些知识注入到可学习的模版和答案的构造中,并且通过知识约束来协同优化模版和答案的表示。
文档级模块采用了DocuNet,首先将文本进行编码并基于实体之间的相关性来计算实体之间的初始关系矩阵。然后该初始关系矩阵通过U形分割模块得到最终的实体间关系矩阵,两实体以及该关系矩阵能够得到最终的关系。
1.3 属性抽取
属性抽取是从非结构化的文本中抽取出实体和属性值之间的属性。比如对于句子“杨缨,字绵公”需要抽取“杨缨”的属性为“绵公”。本文提供了常规抽取模块。常规抽取模块包括了六种常用的深度学习模型,有CNN、RNN、Capsule、GCN、Transformer以及预训练语言模型。
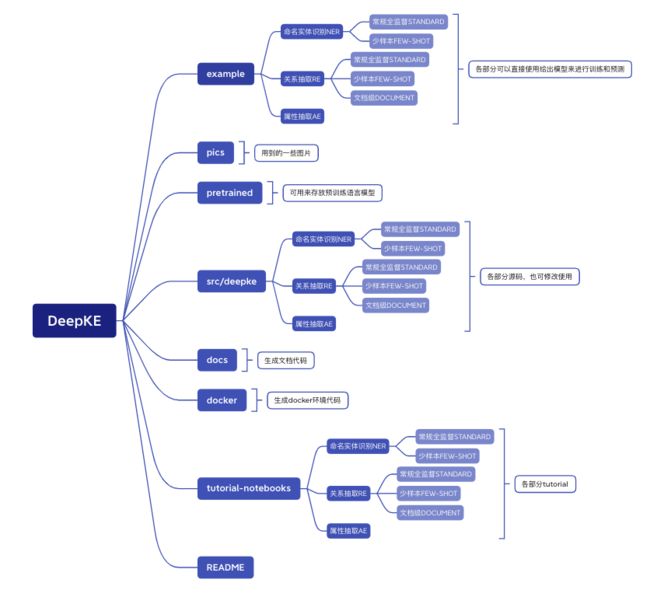
2、总体结构
DeepKE整体代码结构如下图所示:
3、基本用法
pip install deepke
1. 关系抽取
cd example/re/standard
模型配置
可根据自己需求修改conf文件夹中的参数,修改config.yaml中的model可以选择使用的模型,model文件夹中可以修改具体模型的参数。
训练模型
conf文件夹中各参数可修改,训练过程可修改train.yaml中的参数,python run.py进行训练。

预测
修改predict.yaml中的参数,python predict.py进行预测
2. 属性抽取
cd example/ae/standard
剩下的流程同关系抽取
3. 实体抽取
cd example/ner/standard
剩下流程同关系抽取
4、实验效果
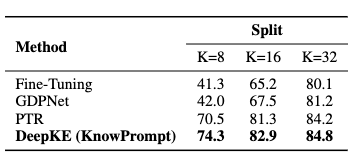
我们对新版本的DeepKE在多个实体识别、关系抽取、属性抽取数据集上进行了常规设定、低资源设定和长篇章设定测试,如下表所示,我们的工具可以达到甚至超越不少传统的基线模型的效果。

如上表所示,DeepKE可以使用和各种不同的编码器进行抽取。DeepKE还能够基于优秀的低资源抽取模型实现较好的少样本抽取性能和支持篇章级的关系抽取。如下表所示,DeepKE可以取得较好的少样本和篇章级抽取性能。

5、小结和展望
新版本的DeepKE是一个基于Pytorch实现命名实体识别、关系抽取和属性抽取功能,支持低资源、长篇章的知识抽取工具。我们同时也开发了一个在线demo展示页面,对于部分功能,无需训练和部署即可满足实时的在线知识抽取功能。在使用过程中有任何问题或是意见和建议都欢迎提出,在今后我们还将继续开发丰富模型,支持多模态知识抽取,使得未来的DeepKE功能变得更丰富更强大。
二、万物皆可Graph | 当信息检索遇上图神经网络
GraphCM

-
A Graph-Enhanced Click Model for Web Search
-
https://dl.acm.org/doi/10.1145/3404835.3462895
图方法结合点击模型,不做过多科普。作者认为现有的点击模型无法应对
-
稀疏性。现有的模型通常会出现数据稀疏性问题,即对查询文档对缺乏有用的用户交互反馈。
-
冷启动。现有的模型在冷启动环境中易受到攻击。
因此从不同用户发布的不同会话(即会话间信息)的查询或文档或会话之间的交互中提取用户的行为模式具有丰富的潜力,可以同时解决以上问题。因此提出图增强点击模型(GraphCM),模型图如下:


FNPS
-
Group based Personalized Search by Integrating Search Behaviour and Friend Network
-
https://dl.acm.org/doi/abs/10.1145/3404835.3462918
这一篇的任务是个性化搜索。一般常见的个性化搜索在数据少时会合并一些相似用户,即有相似的搜索词。但当行为少时,这种相似用户的行为不一定可靠,因此引入朋友网络来共同建模,即相似的信息需求+多样的朋友关系。
作者提出模型FNPS的架构如上图,比较直观
-
首先,利用朋友网络和用户的历史搜索行为,从两个角度形成朋友圈。即图中的relation-based circles(友谊伴随这共享的经验,因此拿到朋友关系来分组)和behavior-based circles(历史搜索行为可以在一定程度上反映用户的兴趣,所以利用行为来分组)。
-
其次,利用图注意网络GAT对不同权重的朋友信息进行聚合。
-
第三,将两种朋友圈的表征输入交叉注意层Cross-Attention,相互增强。
-
最后,为了响应当前的查询意图,使用查询感知的注意力来突出相关的朋友圈。其中长短期Transformer建模历史记录得到动态的个人profile信息。
GRAPH4DIV
-
Modeling Intent Graph for Search Result Diversification
-
https://dl.acm.org/doi/10.1145/3404835.3462872
这一篇研究搜索多样性问题。搜索结果多样化旨在提供包含尽可能多意图的不同文档。一些常见的多样性检索方法博主在过往文章有过整理了,传送门:多样性检索[5]。
一般都是使用逐个选最多样的某个item,但作者认为现有多样化的方法仍然存在的问题有:
-
多样性排序loss是唯一的。因此就不知道排错的结果是因为特征的组合问题导致,还是多样性的特征不够。同时只用初始化特征来计算新颖性也是不准确的,文档的内容是推导文档多样性信息的重要来源,应该被重点关注。
-
候选文档的多样性是通过其与所选文档的不同性来衡量的,而忽略了所选文档对查询的意图覆盖范围和候选文档之间的相似性。
总体来说作者认为文档的内容和查询的意图是重要的两个衡量点。但会各自遇到两大困难:
-
如何同时考虑内容和意图覆盖来计算文档相似度。文档的意图很重要,相似的内容一定也共享很多的意图。同时对于结果来说,返回文档中的意图越多则多样性越好,但用户意图通常隐藏在文档内容中。
-
如何在文档选择过程中考虑查询和文档的复杂和动态关系。这里的动态博主个人理解是在一个一个挑选过程中,选择队列中对意图多样性的需求是不断变动的,因此候选文件的多样性不是独立的。
因此作者提出可以直接通过文档意图覆盖范围的相似性,而不是仅仅文档表示特征的相似性来建模,同时讨论复杂的意图关系。最终提出的方案GRAPH4DIV如下图所示:
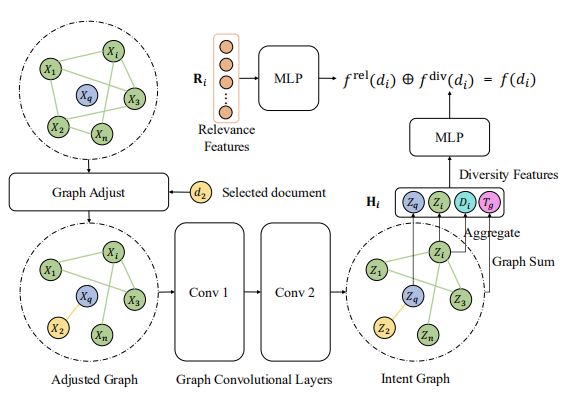
首先看一下ranking分数 的计算,如上图的右上角的地方:
其中当前查询 、文档集 和候选文档 。 和 分别是相关性和多样性分数。然后这俩的计算分别为:
相关性分数比较好计算,而多样性分数由于选择文档的动态性,因此计算会复杂一些,如图的其他部分都是在获得这里的多样性特征 。
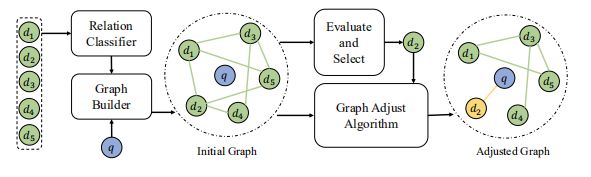
具体的做法分为以下几步。
-
文档关系图。为了充分利用文档内容的丰富信息,作者设计了一个文档关系分类器,其根据文档内容的内容来判断两个文档是否包含相同的意图。然后构建意图图,其中如果两个文档共享相同的意图,则它们是连接的。
-
图卷积层。用GCN适应这个动态意图图来学习意图感知文档表示和上下文感知查询表示。动态的意思是当选择完分数最高的文档后,图的结果将会变化即Adjusted Graph,然后在用GCN学习表示。
-
多样性特征。由query表示 ,文档表示 ,度表示 和全局图表示 组成。
本文参考资料
[1]
图神经网络用于推荐系统问题(PinSage,EGES,SR-GNN): https://nakaizura.blog.csdn.net/article/details/106413118
[2]
图神经网络用于推荐系统问题(NGCF,LightGCN): https://nakaizura.blog.csdn.net/article/details/106970194
[3]
图神经网络用于推荐系统问题(IMP-GCN,LR-GCN): https://nakaizura.blog.csdn.net/article/details/114320157
[4]
图神经网络用于推荐系统问题(SURGE,GMCF,TASRec): https://nakaizura.blog.csdn.net/article/details/121549056
[5]
多样性检索: https://blog.csdn.net/qq_39388410/article/details/109706683
知识图谱AI大本营
知识图谱AI大本营 是一个追踪、解读、讨论和报道知识图谱、深度学习、机器学习等AI前沿成果的学术平台,致力于让人工智能领域的国内外优秀科研工作者们得到交流学习v
DeepKE发布新版本:支持低资源、长篇章、多任务的图谱抽取开源框架,开源开放 | (qq.com)