近似最近邻搜索ANN(Approximate Nearest Neighbor)
目录
一、随机投影森林-一种近似最近邻方法(ANN)
1. 随机投影森林介绍
2、LSHForest/sklearn
二、Kd-Tree的最近邻查找
参考阅读:
annoy 源码阅读 (近似最近邻搜索 ANN)
https://blog.csdn.net/KIDGIN7439/article/details/76599027?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
KNN(二)--近似最近邻算法ANN
https://blog.csdn.net/ccblogger/article/details/60480446?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
最近邻检索(NN)和近似最近邻(ANN)检索
https://blog.csdn.net/zijikanwa/article/details/85604689
最近邻检索(Nearest Neighbor Search)的简单综述
https://blog.csdn.net/lovego123/article/details/67638789
本文主要介绍两种近似最近邻算法,随机投影森林算法和K-D树
一、随机投影森林-一种近似最近邻方法(ANN)
相关参考:
http://yongyuan.name/blog/approximate-nearest-neighbor-search.html
https://blog.csdn.net/sinat_26917383/article/details/70243066
http://blog.sina.com.cn/s/blog_7103b28a0102w1ny.html
https://blog.csdn.net/sinat_26917383/article/details/70243066
1. 随机投影森林介绍
当数据个数比较大的时候,线性搜索寻找KNN的时间开销太大,而且需要读取所有的数据在内存中,这是不现实的。因此,实际工程上,使用近似最近邻也就是ANN问题。
其中一种方法是利用随机投影树,对所有的数据进行划分,将每次搜索与计算的点的数目减小到一个可接受的范围,然后建立多个随机投影树构成随机投影森林,将森林的综合结果作为最终的结果。
建立一棵随机投影树的过程大致如下(以二维空间为例):

随机选取一个从原点出发的向量,与这个向量垂直的直线将平面内的点划分为了两部分,将属于这两部分的点分别划分给左子树和右子树。在数学计算上,是通过计算各个点与垂直向量的点积完成这一步骤的,点积大于零的点划分到左子树,点积小于零的点划分到右子树。注意一点,图中不带箭头的直线是用于划分左右子树的依据,带箭头的向量是用于计算点积的。这样,原有的点就划分为了两部分

但是此时一个划分结果内的点的数目还是比较多,因此继续划分。再次随机选取一个向量,与该向量垂直的直线将所有点进行了划分。
注意一点,此时的划分是在上一次划分的基础上进行的。也就是说现在图中的点已经被划分成了四部分,对应于一棵深度为2,有四个叶节点的树。以此类推继续划分下去,直到每个叶节点中点的数目都达到一个足够小的数目。注意这棵树并不是完全树。
利用这棵树对新的点进行最近邻计算时,首先通过计算该点与每次划分所用向量的点积,来找到其所属于的叶节点,然后利用这个叶节点内的这些点进行最近邻算法的计算。这个过程是一棵随机投影树的计算过程,利用同样的方法,建立多个随机投影树构成随机森林,将森林的总和结果作为最终的结果。
python中可以完成这个功能的模块包括RPForest和sklearn.neighbors中的LSHForest。
2、LSHForest/sklearn
参考:python实现局部敏感随机投影森林——LSHForest/sklearn
https://blog.csdn.net/sinat_26917383/article/details/70243066
>>> from sklearn.neighbors import LSHForest
>>> X_train = [[5, 5, 2], [21, 5, 5], [1, 1, 1], [8, 9, 1], [6, 10, 2]]
>>> X_test = [[9, 1, 6], [3, 1, 10], [7, 10, 3]]
>>> lshf = LSHForest(random_state=42)
>>> lshf.fit(X_train)
LSHForest(min_hash_match=4, n_candidates=50, n_estimators=10,
n_neighbors=5, radius=1.0, radius_cutoff_ratio=0.9,
random_state=42)
>>> distances, indices = lshf.kneighbors(X_test, n_neighbors=2)
>>> distances
array([[ 0.069..., 0.149...],
[ 0.229..., 0.481...],
[ 0.004..., 0.014...]])
>>> indices
array([[1, 2],
[2, 0],
[4, 0]])LSHForest(random_state=42)树的初始化,
lshf.fit(X_train)开始把数据载入初始化的树;
lshf.kneighbors(X_test, n_neighbors=2),找出X_test每个元素的前2个(n_neighbors)相似内容。
其中,这个是cos距离,不是相似性,如果要直观,可以被1减。
二、Kd-Tree的最近邻查找
参考:
https://blog.csdn.net/si894438380/article/details/101535804?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
https://blog.csdn.net/zrh_CSDN/article/details/80626722
输入:已经构造的kd树,目标点x;
输出:x的最近邻
1在kd树中找出包含目标点x的叶节点:从根结点出发,递归地向下访问kd树。若目标点x当前维的坐标小于切分点的坐标,则移动到左叶子结点,否则移动到右叶子结点。直到子节点为叶节点为止。
2以此叶节点为“当前最近点”
3递归地向上回退,在每个结点进行以下操作:
a.如果该结点保存的实例点比当前最近点距离目标点更近,则以该实例点为“当前最近点”
b.当前最近点一定存在于该结点一个子结点对应的区域。检查该子结点的父结点的另一子结点对应的区域是否有更近的点。具体来说,检查另一子结点对应的区域是否与以目标点为球心,以目标点与“当前最近点”间的距离为半径的超球体相交。
如果相交,可能在另一子结点对应的区域内存在距离目标点更近的点,移动到另一个子结点。接着,递归地进行最近邻搜索;
如果不相交,向上回退。
4当回退到根结点使,搜索结束,最后的“当前最近点”即为x的最近邻点。
实现过程举例,如下:
下面用一个简单的例子来演示基于Kd-Tree的最近邻查找的过程。
数据点集合:(2,3), (4,7), (5,4), (9,6), (8,1), (7,2) 。
已建好的Kd-Tree:

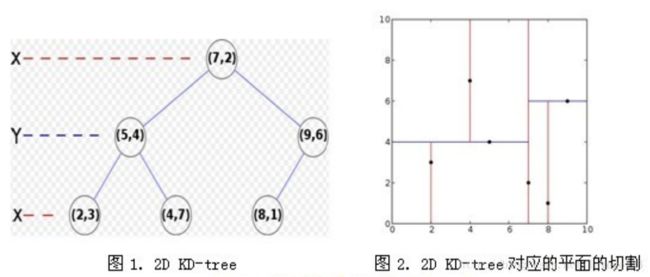
假设我们的k-d tree就是上面通过样本集{(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)}创建的。
我们来查找点(2.1,3.1),在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后search_path中的结点为<(7,2), (5,4), (2,3)>,从search_path中取出(2,3)作为当前最佳结点nearest, dist为0.141;
然后回溯至(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和超平面y=4相交,如下图,所以不必跳到结点(5,4)的右子空间去搜索,因为右子空间中不可能有更近样本点了。
于是在回溯至(7,2),同理,以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆并不和超平面x=7相交,所以也不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2.1,3.1)的最近邻点,最近距离为0.141。