用 BeautifulSoup 解析器分析 RSS
用 BeautifulSoup 解析器分析简易信息聚合RSS
- 运行代码
- 它是如何工作的
- 分析地址
- 遍历所有资讯
- 安装解析器
- 检查打印
运行代码
虽然今天传来不好的消息,京城新增数十例,但是调试程序的工作依然需要进行。运行下面区区十几代码,您可以立即得到自己想要的简易信息聚合RSS信息片段。代码运行是 Python 3.8 ,用 BeautifulSoup(v4.4.0)库 (点击获取库)
import urllib.request
from bs4 import BeautifulSoup
f = urllib.request.urlopen("https://www.cnbeta.com/backend.php")
soup = BeautifulSoup(f.read(), "html.parser")
for i in soup.find_all('item'):
for child in i.children:
if (child.name == 'title'):
print(child.string)
else:
if (child.name == 'description'):
desc_str = BeautifulSoup(child.string,'lxml')
print(desc_str.text)
print('---------------------------')
else:
pass
如果一切正常,应该看到:
工信部委托机构检测“偷窥”App:存频繁自启动等问题
近日,央视新闻报道手机App“偷窥”乱象调查,有App十几分钟内访问照片和文件两万多次,涉及移动教学软件“优学院”、 办公软件“TIM”等多款产品。6月18日,澎湃新闻记者从工
信部旗下中国信通院泰尔终端实验室获悉,该实验室受工信部委托,已经对曝光的问题App进行了检测。 阅读全文
---------------------------
软银:将投资14家非白人创始人企业
北京时间6月19日早间消息,据外媒报道,软银愿景基金负责人拉吉夫·米斯拉(Rajeev Misra)表示,软银将对14家由非白人创始人所成立的初创企业进行投资。这是软银Emerge加
速器项目的一部分,该项目为来自代表性不足全体的创业者提供指导。在未来一年中,软银将把该项目的范围扩大至欧洲。本周四,在Emerge项目的线上活动上米斯拉发表了讲话,
在此次线上活动上,出创企业创始人向投资人介绍了自己的企业,软银还介绍了第一批完成了该项目的企业。 阅读全文
---------------------------
如果遇到提示:No module named lxml ,先别急,默认的 BeautifulSoup 安装不带 lxml HTML 解析器。后面会说明安装方法。
它是如何工作的
工作过程是这样的:首先分析目标地址的结构,然后分别用了解析器 html.parser 和lxml 来获取每篇资讯的 title 标题和 description 摘要描述,最后通过循环全部展现出来。
分析地址
cnBeta.com 中文业界资讯网是我很爱看的资讯网站。它免费提供订阅的简易信息聚合RSS(点击查看什么是RSS) 地址如下:
https://www.cnbeta.com/backend.php
在浏览器输入后,我们见到:
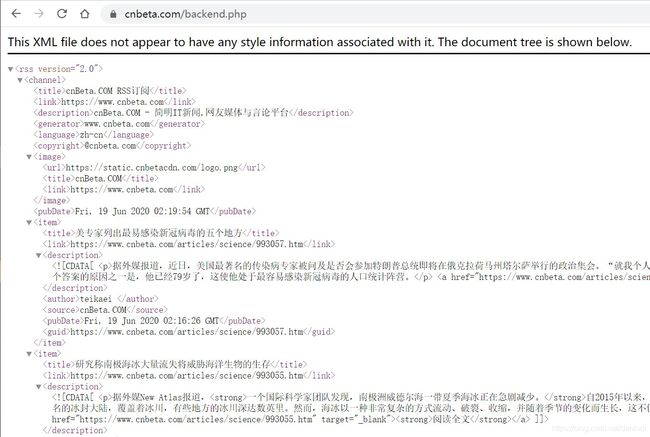
不难看出,这是一个标准的XML格式文件。结构清晰,每一个 item 节点下,有 title link description author source pubDate guid 七个子节点信息。
<rss version="2.0">
<channel>
<item>
<title></title>
<link></link>
<description><![CDATA[...]]></description>
<author></author>
<source></source>
<pubDate></pubDate>
<guid></guid>
</item>
<item>
...
</item>
</channel>
</rss>
通过解析器 html.parser ,我们可以就可以获得很理想的完整结构集 soup:
f = urllib.request.urlopen("https://www.cnbeta.com/backend.php")
soup = BeautifulSoup(f.read(), "html.parser")
遍历所有资讯
在 soup 里面用 find_all 方法查询获得所有 item 节点。然后循环 for…in 就可以得到每一篇文章。在每篇文章,子节点 title 和 description 是我们想要的标签内容,其他不是。
for i in soup.find_all('item')
通过观察,发现还有个难点,子节点 description 里面包含 格式字符串。(点击查看 XML CDATA 概念)
<description>
<![CDATA[ <p>近日,央视新闻报道手机App“偷窥”乱象调查,有App十几分钟内访问照片和文件两万多次,涉及移动教学软件“优学院”、 办公软件“TIM”等多款产品。6月18日,澎湃新闻记者从工信部旗下中国信通院泰尔终端实验室获悉,<strong>该实验室受工信部委托,已经对曝光的问题App进行了检测。</strong></p> <a href="https://www.cnbeta.com/articles/tech/993033.htm" target="_blank"><strong>阅读全文</strong></a> ]]>
</description>
以前常用处理 方法是使用正则表达式。但是今天,我们交给 Beautifusoup 支持 Python 的第三方 lxml 解析器进行操作,处理起来就会变得简单。根据操作系统不同,可以选择下列方法来安装 lxml:
安装解析器
Linux 下安装,类似:
$ apt-get install Python-lxml
$ easy_install lxml
Windows 下安装,类似:
C:\Python\>pip install lxml
检查打印
遍历过程检查 .children 属性,即 item 下七个子节点。当遇到 description摘要描述,使用解析器 lxml 处理 ,获得的字符串保存到 desc_str后再打印出来:
if (child.name == 'description'):
desc_str = BeautifulSoup(child.string,'lxml')
print(desc_str.text)
print('---------------------------')
至此,我们以最少的代码完成最核心的事情。
总结
1、使用了 BeautifulSoup 库从HTML或XML文件中提取数据。
2、使用 lxml 库处理 CData 格式