【云计算与大数据技术】Hadoop MapReduce的讲解(图文解释,超详细必看)
一、Hadoop MapReduce架构
MapReduce 是一种分布式计算框架,能够处理大量数据 ,并提供容错 、可靠等功能 , 运行部署在大规模计算集群中,MapReduce计算框架采用主从架构,由 Client、JobTracker、TaskTracker组成
Client的作用
用户编写 MapReduce程序,通过Client提交到JobTracker
JobTracker的作用
JobTracker负责管理运行的 TaskTracker节点;负责Job的调度与分发
TaskTracker的作用
JobTracker发送具体的任务给 TaskTracker节点执行

在 MapReduce框架中,所有的程序执行最后都转换成task来执行
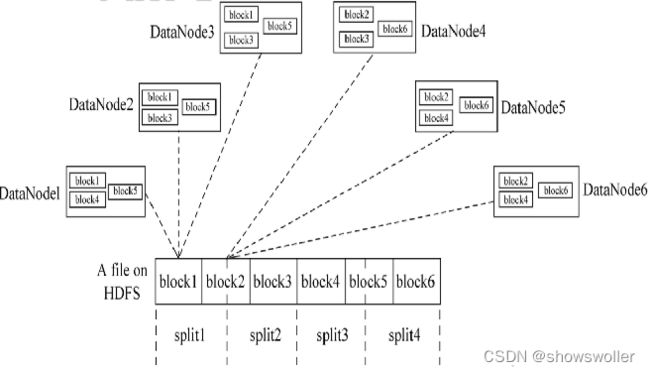
下图显示了 HDFS 作为 MapReduce 任务的数据输入源 ,每个 HDFS 文件切分成多个 ,Block 将其作为 MapReduce任务的数据输入源,执行计算任务
二、Hadoop MapReduce 与高效能计算、 网格计算的区别
高性能计算的思想是将计算作业分散到集群机器上,集群计算节点访问存 储区域网络SAN 系统构成的共享文件系统获取数据,这种设计比较适合计算密集型作业,当需要访问像PB级别的数据的时候,由于存储设备网络带宽的显示,很多集群计算节点只能空闲等待数据
由于 Hadoop使用专门为分布 式计算设计的文件系统 HDFS,在计算的时候只需要将计算代码推送到存储节点上即可在存储节点上完成数据的本地化计算,Hadoop中的集群存储节点也是计算节点
在分布式编程方面,MPI属于比较底层的开发库,它赋予了程序员极大的控制能力;Hadoop的MapReduce却是一个高度抽象的并行编程模型,它将分布式并行编程抽象为两个原语操作,即Map操作和Reduce操作
网格计算通常是指通过现有的互联网,利用大量来自不同地域,资源异构的计算机空闲的CPU和磁盘来进行分布式存储和计算
三、MapReduce工作机制
MapReduce计算模式的工作原理是把计算任务拆解成Map和Reduce两个过程来执行
 在数据被分割后通过Map函数的程序将数据映射成不同的区块,分配给计算机集群处理达到分布式运算的效果,再通过Reduce函数的程序将结果汇整,最后输出运行计算结果
在数据被分割后通过Map函数的程序将数据映射成不同的区块,分配给计算机集群处理达到分布式运算的效果,再通过Reduce函数的程序将结果汇整,最后输出运行计算结果
1:Map
Map - MapReduce会根据输入文件计算输入分片(inputsplit),每个输入分片针对一个Map任务,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组,输入分片往往和HDFS的block块的关系很密切
接着执行Map函数,操作一般由用户指定,Map 函数产生输出结果时并不是直接写入到磁盘,而是采用缓冲方式写入到内存中,并对数据按关键字进行预排序
2:Reduce
执行用户指定的 Reduce函数,输出计算结果到 HDFS集群上。Reduce执行数据的归并,数据是以key,list(value1,value2... ) 的方式存储
3:Combine
Comine-Combine 是在本地进行的一个在Map端做的Reduce的过程,其目的是提高Hadoop的效率
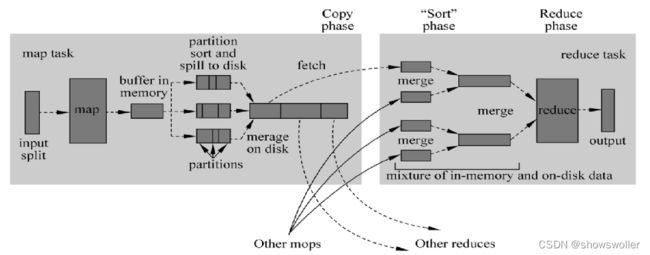
4:Shuffle
Shuffle描述数据从 Map Task输出到Reduce Task输入的这段过程
Reducer真正运行之前,所有的时间都是在拉取数据,做merge,且不断重复地做,下面描述Reduce端的Shuffle细节
copy 过 程 - 其 用 于 简 单 地 拉 取 数 据 。Reduce 进 程 启 动 一 些 数 据 copy 线 程(Fetcher),通过HTTP请求文件数据
merge 阶段 - 这里的 merge 如 Map 端的 merge 动作
Reducer 的输入文件 - 不 断 地 merge,最后会生成一个“最 终 文 件
5:Speculative Task
存在这样的计算任务,它的运行时间远远长于其他任务的计算任务,减少该任务的运行时间就可以提高整体作业的运行速度,这种任务也称为“拖后腿”任务
导致任务执行缓慢的原因有很多种,包括软件和硬件原因
为了解决上述“拖 后 腿 ”任务导致的系统性能下降问题,Hadoop 为该task启动Speculative Task,与原始的 task同时运行,以最快运行结束的结果返回,加快Job的执行,当为一个task启动多个重复的task时,必然导致系统资源的消耗,因此采用Speculative Task的方式是一种以空间换时间的方式
四、任务容错
MapReduce是一种通用的计算框架,有着非常健壮的容错机制,容错粒度包括 JobTracker、TaskTracker、Job、Task、Record等级别
对于任务的容错机制,MapReduce 采用最简单的方法进行处理
如果是一个 Map任务或 Reduce任务失败了,那么调度器会将这个失败的任务分配到其他节点重新执行
如果是一个节点死机了,那么在这台死机的节点上已经完成运行的 Map任务及正在运行中的 Map和 Reduce任务都将被调度重新执行,同时在其他机器上正在运行的 Reduce任务也将被重新执行
五、MapReduce的缺陷与不足
MapReduce 是一种离线处理框架,比较适合大规模的离线数据处理
MapReduce在实时处理性能方面比较薄弱,不适合处理事务或者单一处理请求
创作不易 觉得有帮助请点赞关注收藏~~~