一、家庭电力消耗分析
1.背景描述
本数据集包含了一个家庭6个月的用电数据,收集于2007年1月至2007年6月。
这些数据包括全球有功功率、全球无功功率、电压、全球强度、分项计量1(厨房)、分项计量2(洗衣房)和分项计量3(电热水器和空调)等信息。该数据集共有260,640个测量值,可以为了解家庭用电情况提供重要的见解。
我们要感谢databeats团队提供这个数据集。如果你在你的研究中使用这个数据集,请注明原作者:Georges Hébrail 和 Alice Bérard
数据说明
| 列名 | 说明 |
|---|---|
| Date | 日期 |
| Time | 时间 |
| Globalactivepower | 该家庭所消耗的总有功功率(千瓦) |
| Globalreactivepower | 该家庭消耗的总无功功率(千瓦) |
| Voltage | 向家庭输送电力的电压(伏特) |
| Global_intensity | 输送到家庭的平均电流强度(安培) |
| Submetering1 | 厨房消耗的有功功率(千瓦) |
| Submetering2 | 洗衣房所消耗的有功功率(千瓦) |
| Submetering3 | 电热水器和空调所消耗的有功功率(千瓦) |
2.数据来源
www.kaggle.com/datasets/th…
3.问题描述
本数据集可以用于机器学习的目的,如预测性建模或时间序列分析。例如,人们可以使用这个数据集,根据过去的数据来预测未来的家庭用电量。
分析不同类型的电气设备对耗电量的影响
研究电力消耗如何随时间和地点而变化
构建一个预测模型来预测未来的电力消耗
二、数据加载
!pip install prophet -i https://pypi.tuna.tsinghua.edu.cn/simple
data_path="/home/mw/input/Household_Electricity4767/household_power_consumption.csv"
import pandas as pd import seaborn as sns import numpy as np from tqdm.auto import tqdm from prophet import Prophet
df=pd.read_csv(data_path)
df.head()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| index | Date | Time | Global_active_power | Global_reactive_power | Voltage | Global_intensity | Sub_metering_1 | Sub_metering_2 | Sub_metering_3 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1/1/07 | 0:00:00 | 2.58 | 0.136 | 241.97 | 10.6 | 0 | 0 | 0.0 |
| 1 | 1/1/07 | 0:01:00 | 2.552 | 0.1 | 241.75 | 10.4 | 0 | 0 | 0.0 |
| 2 | 1/1/07 | 0:02:00 | 2.55 | 0.1 | 241.64 | 10.4 | 0 | 0 | 0.0 |
| 3 | 1/1/07 | 0:03:00 | 2.55 | 0.1 | 241.71 | 10.4 | 0 | 0 | 0.0 |
| 4 | 1/1/07 | 0:04:00 | 2.554 | 0.1 | 241.98 | 10.4 | 0 | 0 | 0.0 |
df.describe()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| index | Sub_metering_3 | |
|---|---|---|
| count | 260640.000000 | 256869.000000 |
| mean | 130319.500000 | 5.831825 |
| std | 75240.431418 | 8.186709 |
| min | 0.000000 | 0.000000 |
| 25% | 65159.750000 | 0.000000 |
| 50% | 130319.500000 | 0.000000 |
| 75% | 195479.250000 | 17.000000 |
| max | 260639.000000 | 20.000000 |
df.dtypes
index int64 Date object Time object Global_active_power object Global_reactive_power object Voltage object Global_intensity object Sub_metering_1 object Sub_metering_2 object Sub_metering_3 float64 dtype: object
df['Date']=pd.DatetimeIndex(df['Date'])
make_em_num = ['Global_active_power', 'Global_reactive_power', 'Voltage', 'Global_intensity', 'Sub_metering_1', 'Sub_metering_2', 'Sub_metering_3']
def floating(string):
try:
return float(string)
except:
return float(0)
for column in tqdm(make_em_num):
df[column] = df[column].apply(lambda item: floating(item))
HBox(children=(FloatProgress(value=0.0, max=7.0), HTML(value='')))
df.dtypes
index int64 Date datetime64[ns] Time object Global_active_power float64 Global_reactive_power float64 Voltage float64 Global_intensity float64 Sub_metering_1 float64 Sub_metering_2 float64 Sub_metering_3 float64 dtype: object
df.head()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| index | Date | Time | Global_active_power | Global_reactive_power | Voltage | Global_intensity | Sub_metering_1 | Sub_metering_2 | Sub_metering_3 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2007-01-01 | 0:00:00 | 2.580 | 0.136 | 241.97 | 10.6 | 0.0 | 0.0 | 0.0 |
| 1 | 2007-01-01 | 0:01:00 | 2.552 | 0.100 | 241.75 | 10.4 | 0.0 | 0.0 | 0.0 |
| 2 | 2007-01-01 | 0:02:00 | 2.550 | 0.100 | 241.64 | 10.4 | 0.0 | 0.0 | 0.0 |
| 3 | 2007-01-01 | 0:03:00 | 2.550 | 0.100 | 241.71 | 10.4 | 0.0 | 0.0 | 0.0 |
| 4 | 2007-01-01 | 0:04:00 | 2.554 | 0.100 | 241.98 | 10.4 | 0.0 | 0.0 | 0.0 |
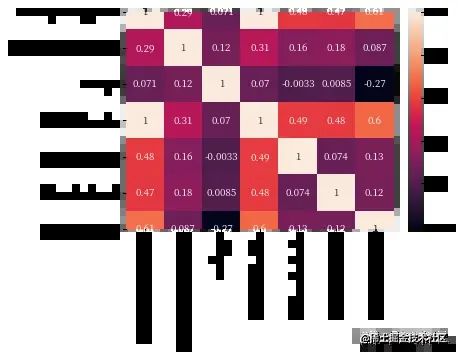
sns.heatmap(df.drop(['index','Date','Time'], axis=1).corr(), annot=True)
三、预测
1.Prophet介绍
github.com/facebook/pr…
Prophet是一种基于可加性模型预测时间序列数据的程序,其中非线性趋势可以按年度、每周和每日的季节性,以及假日效应进行拟合。它最适合于具有强烈季节效应的时间序列和有几个季节的历史数据。Prophet对于缺失的数据和趋势的变化是稳健的,并且通常能够很好地处理异常值。
2.模型介绍
Prophet模型如下:
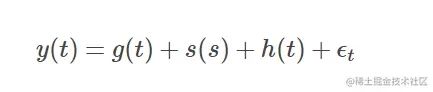
- g(t) 表示趋势函数,拟合非周期性变化;
- s(s)表示周期性变化,比如说每周,每年,季节等;
- h(t)表示假期变化,节假日可能是一天或者多天;
- ϵt为噪声项,用他来表示随机无法预测的波动,我们假设ϵt是高斯的。
趋势中有两个增长函数,分别是分段线性函数(linear)和非线性逻辑回归函数(logistic)拟合增长曲线趋势。通过从数据中选择变化点,Prophet自动探测趋势变化;
使用傅里叶级数建模每年的季节分量;
使用虚变量代表过去,将来的相同节假日,属于节假日就为1,不属于就是0;
用户提供的重要节假日列表
- Modeling:建立时间序列模型。分析师根据预测问题的背景选择一个合适的模型。
- Forecast Evaluation:模型评估。根据模型对历史数据进行仿真,在模型的参数不确定的情况下,我们可以进行多种尝试,并根 据对应的仿真效果评估哪种模型更适合。
- Surface Problems:呈现问题。如果尝试了多种参数后,模型的整体表现依然不理想,这个时候可以将误差较大的潜在原因呈现给分析师。
- Visually Inspect Forecasts:以可视化的方式反馈整个预测结果。当问题反馈给分析师后,分析师考虑是否进一步调整和构建模型。
3.Prophet优点
- 准确,快速,拟合非常快,可以进行交互式探索
- 全自动,无需人工操作就能对混乱的数据做出合理的预测
- 可调整的预测,预测模型的参数非常容易解释,可以用业务知识改进或调整预测
- 对缺失值和变化剧烈的时间序列和离散值能做很好有很好的鲁棒性,不需要填补缺失值;
import matplotlib.pyplot as plt
df.shape
(260640, 10)
df=df.sample(n=10000)
def prophet_forecaster(data, x, y, period=100):
new_df = pd.DataFrame(columns=['ds', 'y'])
new_df['ds']= data[x]
new_df['y'] = data[y]
model = Prophet()
model.fit(new_df)
future_dates = model.make_future_dataframe(periods=period)
forecast = model.predict(future_dates)
model.plot(forecast)
plt.title(f"Forecasting on the next {period} days for {y}")
prophet_forecaster(df, x='Date', y='Global_active_power', period=100)
prophet_forecaster(df, x='Date', y='Voltage', period=100)
INFO:prophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this. INFO:prophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.

以上就是kaggle数据分析家庭电力消耗过程详解的详细内容,更多关于kaggle数据分析电力消耗的资料请关注脚本之家其它相关文章!