python 基于xgboost预测波士顿房价
一、意义
这是一个机器学习练习项目,旨在熟悉xgboost的建模过程和数据分析的思路,目标数据选取sklearn自带数据集——波士顿房价
二、开始
1. 导入要用的库
from sklearn.datasets import load_boston
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing, metrics
import xgboost as xgb
import warnings
warnings.filterwarnings("ignore")
2. 组装数据
data_boston = load_boston() # 特征数据
clo_names = list(data_boston.feature_names) # 获取特征数据名字
data_dst = data_boston.target # 标签数据
# 把所有数据组装到 DataFrame 里,方便后续数据分析
df = pd.DataFrame(load_boston().data)
for i, n in enumerate(clo_names):
print(i, n)
df.rename(columns={i: n}, inplace=True) # 重命名列名 数字索引 >>> 特征名
df.loc[:, 'MEDV'] = data_dst # 最后一列加入标签数据
print(df.head())
df 数据现在是这样

3. 分析数据
数据分析的过程比较主观,目的就是充分了解数据,为后面的特征工程和建模提供一定的依据
df.info()
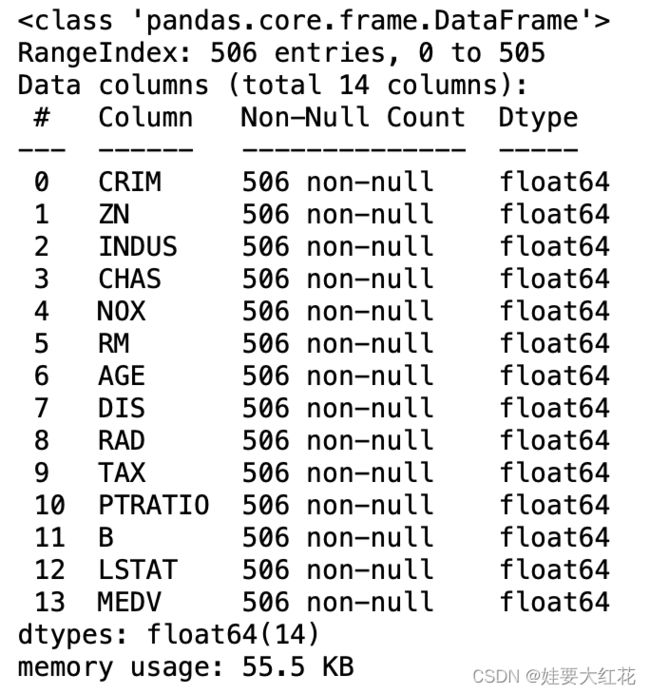
通过观察,当前数据无缺损值,不需要填补数据
下面就可以根据自己所想任意分析了
这里先看看房价数据(MEDV)的分布情况
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
sns.distplot(df['MEDV'], color="r")
# sns.distplot(data_train['GrLivArea'], color="b")
plt.title("MEDV直方图")
plt.show()
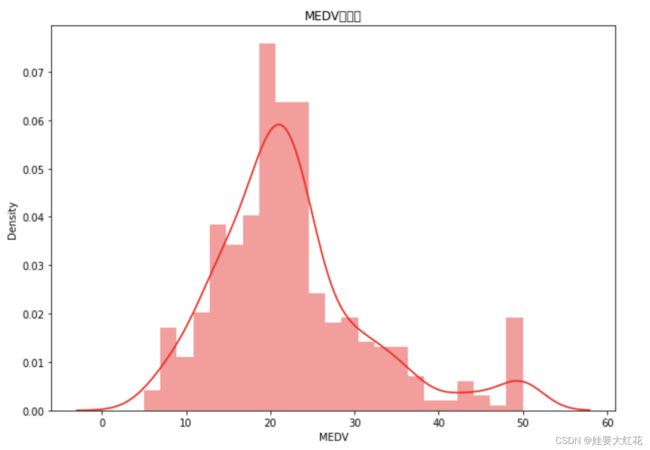
大致呈正态分布,房价为20左右的比较多,50的高房价也有一些,嗯嗯,比较正常,再看看箱型图
plt.figure(figsize=(10, 7))
fig = sns.boxplot(data=df['MEDV'])
plt.title("box")
plt.show()

房价多数集中在20,高房价处有些异常值,等会数据标准化可以尝试用RobustScaler来处理,再看看各特征对标签的重要性吧
plt.figure(figsize=(10, 7))
sns.heatmap(df.corr(), cmap="YlGnBu", annot=True)
plt.title("相关性分析图")
plt.show()
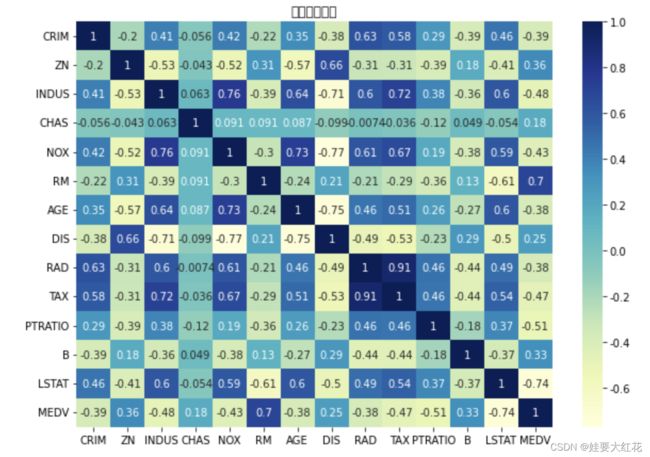
看最下一行,各维度特征有正相关也有负相关,相关性都挺强的(如果相关值过低,可以考虑删除部分特征,可以提高建模训练速度,缩短模型推理时间)
(这里就不展示更多的数据可视化了,感兴趣可以自行分析)
4. 特征工程
根据上面的数据分析发现数据基本正常,存在一定的异常值,首选使用RobustScaler进行数据标准化(RobustScaler常用来处理带离群值数据集标准化)(事实上和树有关的决策算法过程是不需要进行归一标准化的,这里主要是演示)
y = df['MEDV'].values
df = df.drop('MEDV', axis=1)
x = df.values
X_train, X_validation, y_train, y_validation = train_test_split(x, y, test_size=0.2, random_state=42)
ss_X = preprocessing.RobustScaler()# 离散标准化处理
ss_Y = preprocessing.RobustScaler()
X_train_scaled = ss_X.fit_transform(X_train)
y_train_scaled = ss_Y.fit_transform(y_train.reshape(-1, 1))
X_validation_scaled = ss_X.transform(X_validation)
y_validation_scaled = ss_Y.transform(y_validation.reshape(-1, 1))
5. xgboost建模
# 建模,可用网格搜索等方式寻找最佳的建模参数,本文直接靠经验开整
xgb_model = xgb.XGBRegressor(max_depth=3,
learning_rate=0.1,
n_estimators=100,
objective='reg:squarederror',
booster='gbtree',
random_state=0)
6. 拟合与测试
# 拟合
xgb_model.fit(X_train_scaled, y_train_scaled)
y_validation_pred = xgb_model.predict(X_validation_scaled) # 预测
# 画图
plt.figure(figsize=(14, 7))
plt.plot(range(y_validation_scaled.shape[0]), y_validation_scaled, color="blue", linewidth=1.5, linestyle="-")
plt.plot(range(y_validation_pred.shape[0]), y_validation_pred, color="red", linewidth=1.5, linestyle="-.")
plt.legend(['真实值', '预测值'])
plt.title("真实值与预测值比对图")
plt.show() #显示图片
# 模型评估
print('可解释方差值:{}'.format(round(metrics.explained_variance_score(y_validation_scaled, y_validation_pred), 2)))
print('平均绝对误差:{}'.format(round(metrics.mean_absolute_error(y_validation_scaled, y_validation_pred), 2)))
print('均方误差:{}'.format(round(metrics.mean_squared_error(y_validation_scaled, y_validation_pred), 2)))
print('R方值:{}'.format(round(metrics.r2_score(y_validation_scaled, y_validation_pred), 2)))

看上去还算可以吧
7. 显示特征重要性
# 显示重要特征
importances = list(xgb_model.feature_importances_)
data_tmp=df
feature_list = list(data_tmp.columns)
feature_list = feature_list[:-1] # 最后一个是标签,排除掉
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
feature_importances = sorted(feature_importances, key=lambda x: x[1], reverse=True)
x_values = list(range(len(importances)))
print(x_values)
print(feature_list)
plt.figure(figsize=(14, 7))
plt.bar(x_values, importances, orientation='vertical')
plt.xticks(x_values, feature_list, rotation=6)
plt.ylabel('Importance')
plt.xlabel('Variable')
plt.title('Variable Importances')
plt.show()

可以看出影响最多的就是RM(房间数)和LSTAS(人口密度),是比较符合常理的
三、最后
学艺不精,欢迎来拍