机器学习课设Part2---U-Net云朵识别
U-Net标签的制作
使用之前写过的KMeans聚类来辅助标注,将二聚类的结果以8位彩色png存储,方便U-Net训练
import cv2
from pylab import *
def img2array(img):
img = cv2.resize(img, (300, 300))
# 由BGR改为RGB防止颜色偏差
img = img[:, :, [2, 1, 0]]
features = list()
for x in range(300):
for y in range(300):
features.append([img[x][y][0], img[x][y][1], img[x][y][2]])
features = np.array(features, 'f') # 变为数组
return img, features
# 定义距离(使用RGB的值之间的距离)
def dist(vecA, vecB):
sum = 0
for i in range(3):
if vecA[i] != vecA[i]:
vecA[i] = 0
if vecB[i] != vecB[i]:
vecB[i] = 0
sum += (int(vecA[i]) - int(vecB[i])) ** 2
return sqrt(sum)
def rand_cent(data_mat, k):
n = shape(data_mat)[1] # 获取坐标维数
centroids = mat(zeros((k, n))) # k个n维的点
for j in range(n):
minJ = min(data_mat[:, j]) # 本维最小值
rangeJ = float(max(data_mat[:, j]) - minJ) # 本维的极差
centroids[:, j] = mat(minJ + rangeJ * np.random.rand(k, 1)) # 随机值
return centroids
# print(centroids)
def kMeans(data_mat, k):
m = shape(data_mat)[0]
# 初始化点的簇
cluster_assment = mat(zeros((m, 2))) # 类别,距离
# 随机初始化聚类初始点
centroid = rand_cent(data_mat, k)
cluster_changed = True
# 遍历每个点
while cluster_changed: # 等到迭代不发生变化即停止
cluster_changed = False
for i in range(m):
min_index = -1
min_dist = inf
for j in range(k):
distance = dist(data_mat[i], np.array(centroid)[j])
if distance < min_dist:
min_dist = distance
min_index = j
if cluster_assment[i, 0] != min_index:
cluster_changed = True
cluster_assment[i, :] = min_index, min_dist ** 2
# 计算簇中所有点的均值并重新将均值作为质心
for j in range(k):
per_data_set = data_mat[nonzero(cluster_assment[:, 0].A == j)[0]]
centroid[j, :] = mean(per_data_set, axis=0)
t=[0,0,0]
if (sum(centroid[0,:])<sum(centroid[1,:]))and(sum(centroid[0,:])>300):
for i in range(3):
t[i] = centroid[0,i]
centroid[0,i] = centroid[1,i]
centroid[1,i] = t[i]
return centroid, cluster_assment
以上是实验2时的KMeans聚类函数,用于辅助生成标签文件,接下来将标签存为png格式以便U-Net训练
from scipy.cluster.vq import *
from PIL import Image
import os
def kMeansSave(Img, filename):
Img, Features = img2array(Img)
# 聚类
centroids, variance = kMeans(Features, 2)
# 使用scipy.cluster.vq绘制聚类结果
code, distance = vq(Features, np.nan_to_num(centroids))
# 用聚类标记创建图像
codeimg = code.reshape(300, 300)
# np_array = np.zeros((300, 300, 3), dtype=np.uint8)
image = Image.fromarray(codeimg)
image.save(f'./TestDataSet(resized)/labels/{filename}.png')
imgpath = 'D:/JupyterProject/ML_CurriculumDesign/TestDataSet(resized)/cloud/'
image_list = os.listdir(imgpath)
i= 0
for name in image_list:
print(os.path.join(imgpath, name))
img = cv2.imread(os.path.join(imgpath, name))
filename = os.path.basename(name).split('.')[0]
kMeansSave(img, filename)
D:/JupyterProject/ML_CurriculumDesign/TestDataSet(resized)/cloud/cloud (1).jpeg
...
D:/JupyterProject/ML_CurriculumDesign/TestDataSet(resized)/cloud/cloud (1389).jpeg
...
U-Net训练
此处使用网上下载的U-Net源码进行,GitHub地址:https://github.com/bubbliiiing/unet-pytorch
Unet介绍
Unet是一个优秀的语义分割模型,其主要执行过程与其它语义分割模型类似。
Unet可以分为三个部分,如下图所示:
第一部分是主干特征提取部分,我们可以利用主干部分获得特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。
第二部分是加强特征提取部分,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合,获得一个最终的,融合了所有特征的有效特征层。
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。
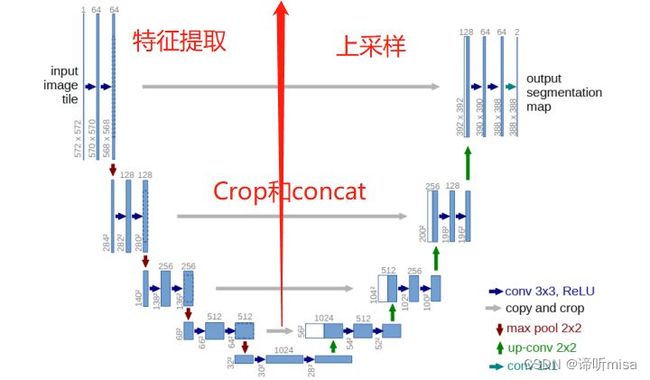
该网络由收缩路径(contracting path)和扩张路径(expanding path)组成。其中,收缩路径用于获取上下文信息(context),扩张路径用于精确的定位(localization),且两条路径相互对称。
U-Net网络能从极少的训练图像中,依靠数据增强将有效的标注数据更为有效地使用。
5个pooling layer实现了网络对图像特征的多尺度特征识别。
上采样部分会融合特征提取部分的输出,这样做实际上是将多尺度特征融合在了一起,以最后一个上采样为例,它的特征既来自第一个卷积block的输出(同尺度特征),也来自上采样的输出(大尺度特征),这样的连接是贯穿整个网络的,可以看到上图的网络中有四次融合过程。
训练步骤
1、将标注好的数据放到特定的文件夹下,训练集和验证集的所有图片放在一个目录,训练集和验证集的所有标签放在一个目录
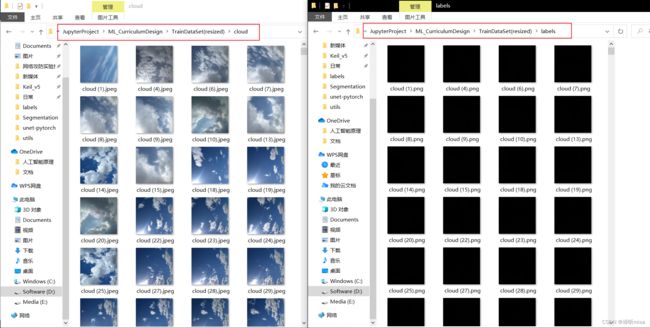
此处标签全黑是由于8位灰度图有256级灰(0~255),人眼无法分辨0和1之间的区别,可以使用看图工具等分辨
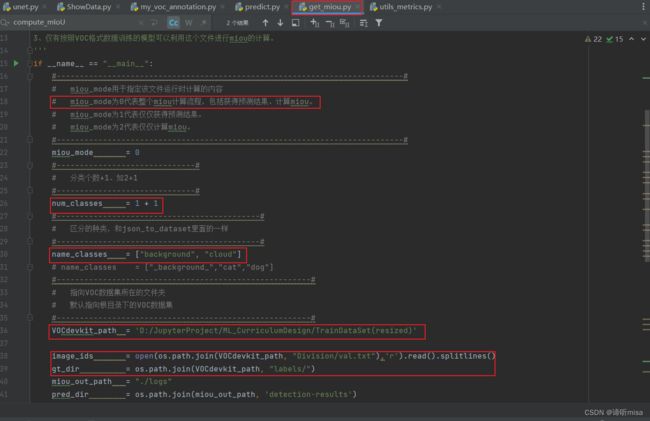
2、将train.py、voc_annotation.py、utils/callback.py、utils/dataloder.py中的对应文件路径、分类类别等修改为正确的路径和分类预期结果,注意修改train.py的num_classes为分类个数+1(此处我新建了一个文件在原基础上修改,比如my_voc_annotation.py)

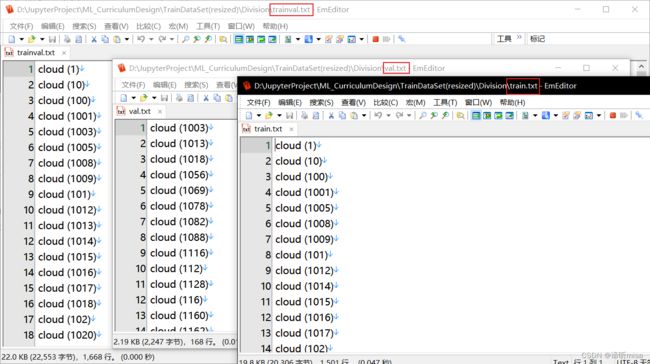
4、在训练前利用my_voc_annotation.py文件生成对应的txt,用于训练时辨别训练集和验证集。
生成的txt如下图,train:val = 9:1
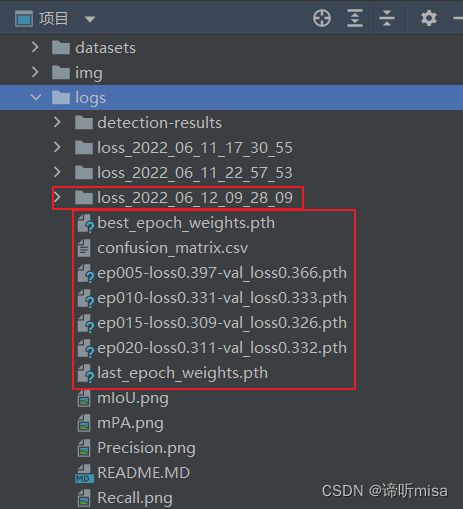
5、运行train.py即可开始训练,训练输出:
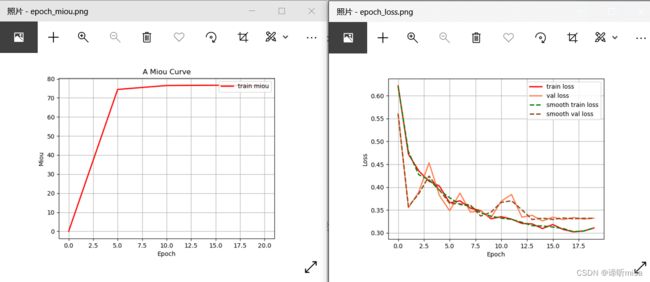
预测步骤
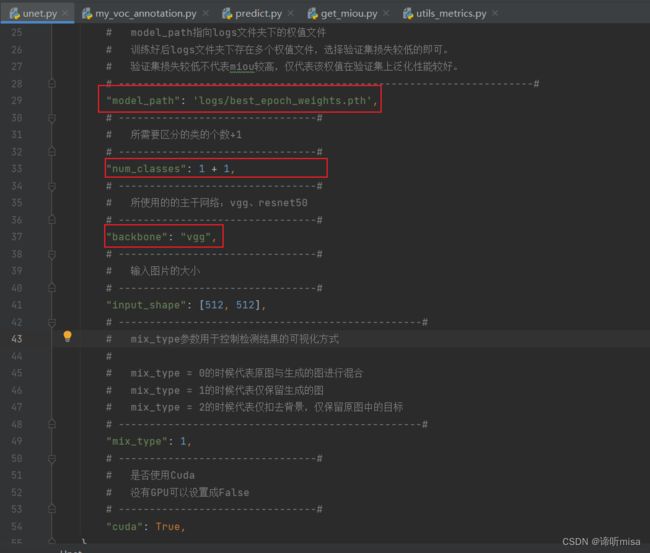
1、修改predict.py、unet.py中的权重模型、分类类别和数据集路径等
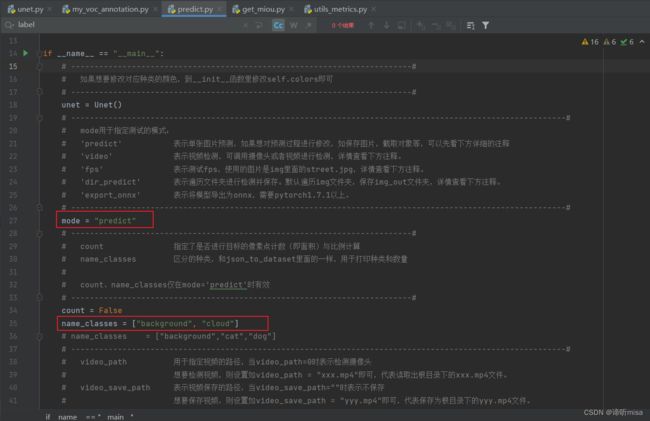
2、改写predict.py的predict情况下的函数和unet.py中的detect_image函数,使其输出更加直观
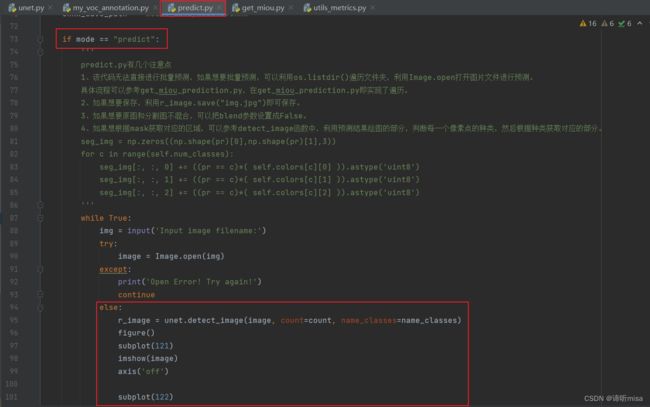
if mode == "predict":
'''
predict.py有几个注意点
1、该代码无法直接进行批量预测,如果想要批量预测,可以利用os.listdir()遍历文件夹,利用Image.open打开图片文件进行预测。
具体流程可以参考get_miou_prediction.py,在get_miou_prediction.py即实现了遍历。
2、如果想要保存,利用r_image.save("img.jpg")即可保存。
3、如果想要原图和分割图不混合,可以把blend参数设置成False。
4、如果想根据mask获取对应的区域,可以参考detect_image函数中,利用预测结果绘图的部分,判断每一个像素点的种类,然后根据种类获取对应的部分。
seg_img = np.zeros((np.shape(pr)[0],np.shape(pr)[1],3))
for c in range(self.num_classes):
seg_img[:, :, 0] += ((pr == c)*( self.colors[c][0] )).astype('uint8')
seg_img[:, :, 1] += ((pr == c)*( self.colors[c][1] )).astype('uint8')
seg_img[:, :, 2] += ((pr == c)*( self.colors[c][2] )).astype('uint8')
'''
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = unet.detect_image(image, count=count, name_classes=name_classes)
figure()
subplot(121)
imshow(image)
axis('off')
subplot(122)
imshow(r_image)
axis('off')
show()
# r_image.show()
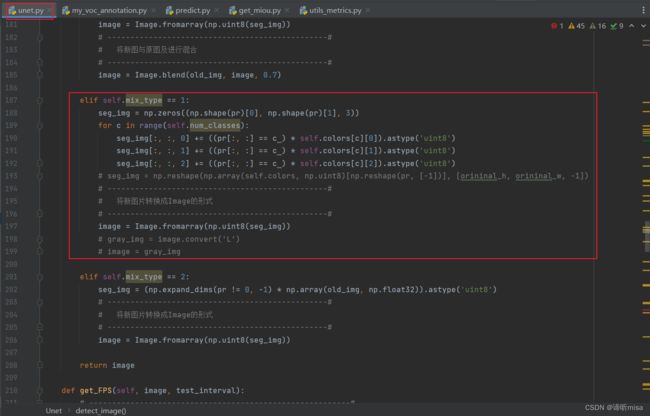
elif self.mix_type == 1:
seg_img = np.zeros((np.shape(pr)[0], np.shape(pr)[1], 3))
for c in range(self.num_classes):
seg_img[:, :, 0] += ((pr[:, :] == c ) * self.colors[c][0]).astype('uint8')
seg_img[:, :, 1] += ((pr[:, :] == c ) * self.colors[c][1]).astype('uint8')
seg_img[:, :, 2] += ((pr[:, :] == c ) * self.colors[c][2]).astype('uint8')
# seg_img = np.reshape(np.array(self.colors, np.uint8)[np.reshape(pr, [-1])], [orininal_h, orininal_w, -1])
# ------------------------------------------------#
# 将新图片转换成Image的形式
# ------------------------------------------------#
image = Image.fromarray(np.uint8(seg_img))
# gray_img = image.convert('L')
# image = gray_img
3、写一个脚本用于显示原图与标签来与预测结果对比
from pylab import *
from PIL import Image
import os
while True:
print('Please input image filename like \'233\'')
img = input('Input image filename(\'q\' to exit):')
# print('D:/JupyterProject/ML_CurriculumDesign/TrainDataSet(resized)/cloud/' + img + '.jpeg')
# print('D:/JupyterProject/ML_CurriculumDesign/TrainDataSet(resized)/labels/' + img + '.png')
if img == 'q':
os._exit(0)
try:
# 此处按需要更改
image1 = Image.open('D:/JupyterProject/ML_CurriculumDesign/TrainDataSet(resized)/cloud/cloud (' + img + ').jpeg')
image2 = Image.open('D:/JupyterProject/ML_CurriculumDesign/TrainDataSet(resized)/labels/cloud (' + img + ').png')
except:
print('Open Error! Try again!')
continue
else:
figure()
subplot(121)
imshow(image1)
axis('off')
gray_img = image2.convert('L')
subplot(122)
imshow(gray_img)
axis('off')
show()
4、训练集预测
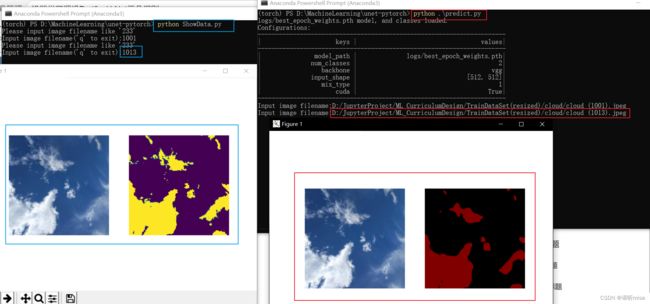
由上面的划分结果可以看到1001号为训练集中图片

4、验证集预测
由上面的划分结果可以看到1013号为验证集中图片
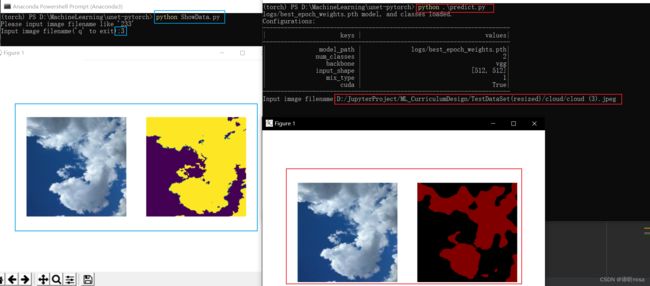
5、测试集预测
由上面的划分结果可以看到5号不在TrainDataSet(resized)中,为测试集中图片
6、全验证集评估
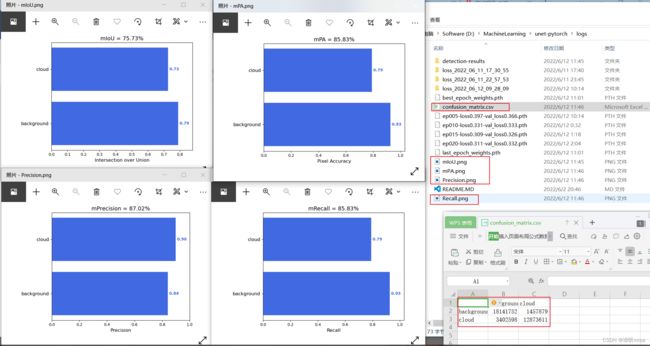
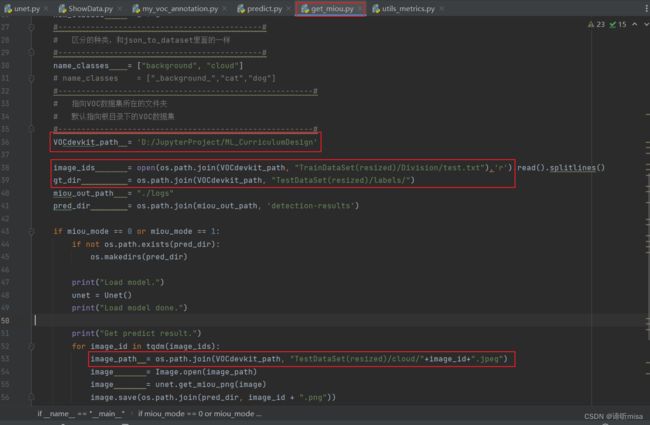
修改设置get_miou.py里面的num_classes为预测的类的数量加1。设置get_miou.py里面的name_classes为需要去区分的类别。运行get_miou.py即可获得miou大小。
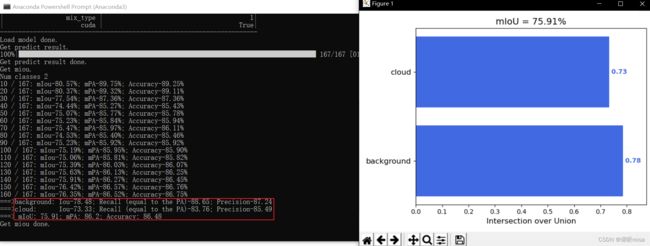
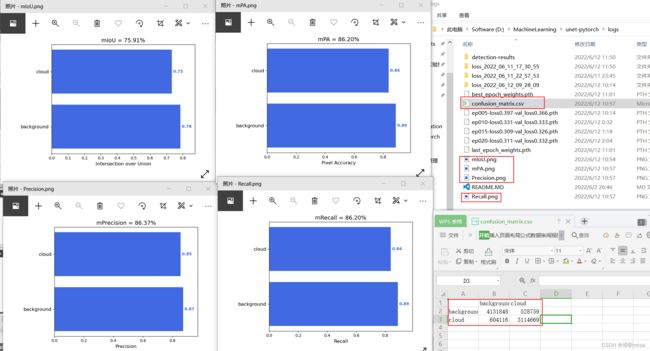
完整结果和混淆矩阵如下:
7、测试集评估
类似上面,将get_miou.py路径改为测试集路径,其中test.txt内容可以用voc_annotation.py对测试集操作后获得
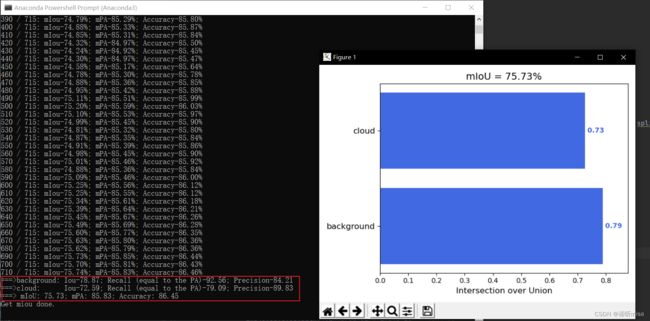
完整结果和混淆矩阵如下: