NLP硬核入门-隐马尔科夫模型HMM
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要15分钟
跟随小博主,每天进步一丢丢


来自:数论遗珠
作者:阮智昊
1 基本概念
1.1 定义、假设和应用
我们先通过一个简单的例子,来了解隐马尔科夫模型HMM。假设:
(1)小明所在城市的天气有{晴天,阴天,雨天}三种情况,小明每天的活动有{宅,打球}两种选项。
(2)作为小明的朋友,我们只知道他每天参与了什么活动,而不知道他所在城市的天气是什么样的。
(3)这个城市每天的天气情况,会和前一天的天气情况有点关系。譬如说,如果前一天是晴天,那么后一天是晴天的概率,就大于后一天是雨天的概率。
(4)小明所在的城市,一年四季的天气情况都差不多。
(5)小明每天会根据当天的天气情况,决定今天进行什么样的活动。
(6)我们想通过小明的活动,猜测他所在城市的天气情况。
那么,城市天气情况和小明的活动选择,就构成了一个隐马尔科夫模型HMM,我们下面用学术语言描述下:
(1)HMM的基本定义: HMM是用于描述由隐藏的状态序列和显性的观测序列组合而成的双重随机过程。在前面的例子中,城市天气就是隐藏的状态序列,这个序列是我们观测不到的。小明的活动就是观测序列,这个序列是我们能够观测到的。这两个序列都是随机序列。
(2)HMM的假设一:马尔科夫性假设。当前时刻的状态值,仅依赖于前一时刻的状态值,而不依赖于更早时刻的状态值。每天的天气情况,会和前一天的天气情况有点关系。
(3)HMM的假设二:齐次性假设。状态转移概率矩阵与时间无关。即所有时刻共享同一个状态转移矩阵。小明所在的城市,一年四季的天气情况都差不多。
(4)HMM的假设三:观测独立性假设。当前时刻的观察值,仅依赖于当前时刻的状态值。小明每天会根据当天的天气情况,决定今天进行什么样的活动。
(5)HMM的应用目的:通过可观测到的数据,预测不可观测到的数据。我们想通过小明的活动,猜测他所在城市的天气情况。
注一:马尔科夫性:随机过程中某事件的发生只取决于它的上一事件,是“无记忆”过程。
注二:HMM被广泛应用于标注任务。在标注任务中,状态值对应着标记,任务会给定观测序列,以预测其对应的标记序列。
注三:HMM属于生成模型,是有向图。
1.2 三个基本问题
在学习HMM的过程中,我们需要研究三个问题,它们分别是:
概率计算问题:给定模型参数和观测序列,计算该观测序列的概率。是后面两个问题的基础。
学习训练问题:给定观测序列,估计模型参数。
解码预测问题:给定模型参数和观测序列,求概率最大的状态序列。
这三个问题会贯穿我们学习HMM的整个过程,在接下来的三个小节,我们会分别学习这三个问题。
2 概率计算问题
2.1 标记符号和参数
先约定一下HMM的标记符号,并通过套用上文的例子来理解:
(1)状态值集合(一共有N种状态值):
![]()
天气的状态值集合为{晴天,阴天,雨天}。
(2)观测值集合(一共有M种观测值):
![]()
小明活动的观测值集合为{宅,打球}。
(3)状态值序列:
![]()
每一天的城市天气状态值构成的序列。
(4)观测值序列:
![]()
每一天的小明活动的观测值构成的序列。
(5)序列状态值、观测值下标:idx(t),表示t时刻的状态值或观测值,取的是状态值、观测值集合中的第idx(t)个。
再给出HMM模型的三个参数:A,B,π。
A:状态转移概率矩阵。表征转移概率,维度为N*N。
B:观测概率矩阵。表征发射概率,维度为N*M。
π:初始状态概率向量。维度为N*1。
λ=(A,B,π),表示模型的所有参数。
同样通过上文的例子来理解这三个参数。
状态转移概率矩阵A:

观测概率矩阵B:
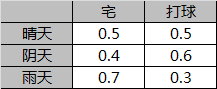
初始概率状态向量π:

2.2 前向后向算法
我们通过前向后向算法,来计算特定观测序列出现的概率。
(2.2节和2.3节涉及大量的公式推导,没有兴趣的童鞋可以跳过不看,不影响文章其它部分的理解)
2.2.1 前向算法模型
定义
![]()
表示在模型参数已知的条件下,预测1~t时刻观测值为特定序列以及t时刻状态值为特定值的概率。
前向算法模型的思路是:利用t时刻的α值,去预测t+1时刻的α值。使用的是迭代的思路。
(1)模型初值:
![]()
(2)迭代公式:

(3)模型终值:
![]()
2.2.2 后向算法模型
定义
![]()
表示在模型参数和t时刻状态值已知的条件下,预测t+1之后所有时刻观测值为特定序列的概率。
后算法模型的思路是:利用t+1时刻的β值,去预测t时刻的β值。使用的是递归的思路。
(1)模型初值:人为地定义
![]()
(2)递归公式:

(3)模型终值:
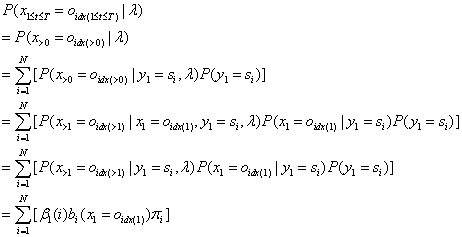
2.2.3 前向后向算法模型公式

这个公式比李航教授书里的公式更容易理解些,《统计学习方法》书里的公式是:
![]()
这两个公式都是正确的,这两个公式在推导过程中获取的以下两个公式,在2.3节有不同的应用:
![]()
![]()
2.3 一些概率和期望的计算
2.3.1 两个常用的概率公式
(1)
![]()
给定模型λ和观测序列,求时刻t处于指定状态的概率。

(2)
![]()
给定模型λ和观测序列,求时刻t和t+1处于指定状态的概率。

2.3.2 三个常用的期望公式
在观测序列O的条件下,状态i出现的期望值:
![]()
在观测序列O的条件下,由状态i转移的期望值:
![]()
在观测序列O的条件下,由状态i转移到状态j的期望值:
![]()
3 学习训练问题
模型参数的学习,可以根据有无标注数据,分为有监督和无监督两类。
在HMM里,如果训练数据包含观测序列和状态序列,即为有监督学习。如果训练数据只包含观测序列,即为无监督学习。
在有监督学习中,可以直接通过统计方法,求得模型的状态转移概率矩阵A、观测概率矩阵B、初始状态概率向量π。
在无监督学习中,模型使用Baum-Welch算法来求得模型参数。Baum-Welch算法是HMM模型中最难的部分,由于本文是“入门”文章,这里就不展开推导了。
注一:其实Baum-Welch算法和EM算法是一样的,只是Baum-Welch算法提出得比较早,当时EM算法还没有被归纳出来。
4 解码预测问题
4.1 贪心算法
贪心算法使用了条件独立性假设,认为不同时刻出现的状态是互相孤立的,是没有相关性的。所以,可以分别求取序列每个时刻最有可能出现的状态,再将各个时刻的状态按顺序组合成状态序列,作为预测结果。
贪心算法使用的公式,是2.3.1节推导出的

贪心算法的优点是计算简单。缺点是不同时刻的状态之间,实际上是概率相关的,这种算法可能导致陷入局部最优点,无法取到全局整体序列的最优值。
实际上,业界极少用贪心算法来解码预测HMM模型的状态序列。
4.2 维特比算法
维特比Viterbi算法使用了动态规划DP的思路,在这一节,我们不列举公式,而是通过一个例子,来呈现维特比算法是怎么工作的。
依旧使用前文的天气和活动的例子,模型参数和2.1节一样:
状态转移概率矩阵A:
观测概率矩阵B:
初始概率状态向量π:
现在已知小明在3天里的活动序列为:[宅,打球,宅],求最有可能的天气序列情况。
维特比算法预测过程:
步骤1:根据模型参数π和B,求得第1天天气的概率分布。
P(D1,晴天,宅)=0.2*0.5=0.1
P(D1,阴天,宅)=0.4*0.4=0.16
P(D1,雨天,宅)=0.4*0.7=0.28
此时我们保存3个序列:
序列最后时刻为晴天的最大概率序列:[晴天:0.1]
序列最后时刻为阴天的最大概率序列:[阴天:0.16]
序列最后时刻为雨天的最大概率序列:[雨天:0.28]
步骤2:根据步骤1的3个序列,模型参数A和B,求得第2天天气的概率分布。
P(D2,晴天,打球)
= max(P(D1,晴天)*P(D2,晴天|D1,晴天)* P(打球|D2,晴天),
P(D1,阴天)*P(D2,晴天|D1,阴天)* P(打球|D2,晴天),
P(D1,雨天)*P(D2,晴天|D1,雨天)* P(打球|D2,晴天))
= max(0.1*0.5*0.5, 0.16*0.3*0.5, 0.28*0.2*0.5) (前一时刻为雨天时,序列概率最大)
= 0.028
序列最后时刻为晴天的最大概率序列:[雨天,晴天:0.028]
P(D2,阴天,打球)
= max(0.1*0.2*0.6, 0.16*0.5*0.6, 0.28*0.3*0.6) (前一时刻为雨天时,序列概率最大)
= 0.0504
序列最后时刻为阴天的最大概率序列:[雨天,阴天:0.0504]
P(D2,雨天,打球)
= max(0.1*0.3*0.3, 0.16*0.2*0.3, 0.28*0.5*0.3) (前一时刻为雨天时,序列概率最大)
= 0.042
序列最后时刻为雨天的最大概率序列:[雨天,雨天:0.042]
步骤3:根据步骤2的3个序列,模型参数A和B,求得第3天天气的概率分布。
P(D3,晴天,宅)
=max(0.028*0.5*0.5, 0.0504*0.3*0.5, 0.042*0.2*0.5) (前一时刻为阴天时,序列概率最大)
= 0.00756
序列最后时刻为晴天的最大概率序列:[雨天,阴天,晴天:0.00756]
P(D3,阴天,宅)
= max(0.028*0.2*0.4, 0.0504*0.5*0.4, 0.042*0.3*0.4) (前一时刻为阴天时,序列概率最大)
= 0.01008
序列最后时刻为阴天的最大概率序列:[雨天,阴天,阴天:0.01008]
P(D3,雨天,宅)
= max(0.028*0.3*0.7, 0.0504*0.2*0.7, 0.042*0.5*0.7)(前一时刻为雨天时,序列概率最大)
= 0.0147
序列最后时刻为雨天的最大概率序列:[雨天,雨天,雨天:0.0147]
步骤4:对比步骤3的3个序列,选出其中概率最大的那个状态序列。
[雨天,阴天,晴天:0.00756],[雨天,阴天,阴天:0.01008],[雨天,雨天,雨天:0.0147]中,概率最大的序列为[雨天,雨天,雨天],概率值为0.0147。
所以最优可能的天气序列情况为:[雨天,雨天,雨天]
最后,简单地描述下维特比算法的思路:
(1)若状态值集合有N个取值,则需维护N个状态序列,以及N个状态序列对应的概率。每个状态序列存储的是:序列最后一个时刻取值为特定状态(共N个状态)时,概率最大的状态序列。本节案例中,就维护晴天、阴天、雨天三个状态序列,及其概率。
(2)自第1个时刻开始,根据状态子序列和模型参数,计算和更新N个状态序列及其概率值。本节的案例中,对于当前时刻的晴天、阴天、雨天3个状态值,分别拼接上一时刻的状态序列和当前时刻的状态。例如D3晴天分别拼接D2状态序列得到:[雨天,晴天]+[晴天],[雨天,阴天]+[晴天],[雨天,雨天]+[晴天]3个新序列。通过计算求得其中概率最大的序列为[雨天,阴天,晴天],最后更新晴天状态序列为[雨天,阴天,晴天],丢弃另外两个序列,并保存概率值0.00756。D3状态为阴天和雨天的状态序列更新流程与此相同。
(3)一直迭代到最后一个时刻,对比所有状态序列的概率值,概率值最大的状态序列即为最大状态概率序列。
注:4.2小节的例子数据,引用自李航《统计学习方法》。
5 HMM的局限性
马尔科夫性(有限历史性):实际上在NLP领域的文本数据,很多词语都是长依赖的。
齐次性:序列不同位置的状态转移矩阵可能会有所变化,即位置信息会影响预测结果。
观测独立性:观测值和观测值(字与字)之间是有相关性的。
单向图:只与前序状态有关,和后续状态无关。在NLP任务中,上下文的信息都是必须的。
标记偏置LabelBias:若状态A能够向N种状态转移,状态B能够向M种状态转移。若N< 在具体实现过程中,为避免多个很小的数相乘导致浮点数下溢,所以可以取对数,使相乘变为相加。 由于HMM的EM算法中存在求和操作(Viterbi算法只有乘积操作),所以不能简单地使用取对数来避免浮点数下溢,采用的方式是设置一个比例系数,将概率值乘以它来放大;当每次迭代结束后,再把比例系数取消掉,继续下一次迭代。 分词任务是NLP的几个基础任务之一,jieba分词是一个应用得很广泛的开源项目。jieba分词使用了好几个不同的分词算法,我们在这一节对其中的HMM分词代码进行解读。 利用HMM算法进行分词,实际上就是执行一个序列标注任务。 我们看到的词语是观测序列,我们要预测一个状态序列,最后通过状态序列,来执行分词操作。 状态序列包括B、M、E、S四种状态。单个字构成的词,被标注为S。多个字构成的词,词语的第一个字被标注为B,最后一个字被标注为E,中间的若干个子被标注为M。 jieba分词通过有监督的方式,获取模型参数A,B,π。 状态转移概率矩阵A被保存在文件prob_trans中: 观测概率矩阵B被保存在文件prob_emit中: 初始状态概率向量π被保存在文件prob_start中: 如截图所示,维特比解码流程同4.2节的描述完全一致,关键的部分我已经添加了注释。 唯一需要注意的是,HMM的工程实践中,大部分概率值都被取了对数,所以乘法操作在代码里体现为加法操作。 根据维特比算法输出的标注状态序列,输出分词结果。 知乎文章地址:https://zhuanlan.zhihu.com/p/87632700 由于微信公众号文章有修改字数的限制,故本文后续的纠错和更新将呈现在知乎的同名文章里。 参考文献 [1] 李航 统计学习方法 清华大学出版社 [2] 隐马尔科夫模型HMM(一/二/三/四) 刘建平Pinard https://www.cnblogs.com/pinard/ 方便交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。 方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。 记得备注呦 推荐阅读: 【ACL 2019】腾讯AI Lab解读三大前沿方向及20篇入选论文 【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing 【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译 【一分钟论文】Semi-supervised Sequence Learning半监督序列学习 【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing 详解Transition-based Dependency parser基于转移的依存句法解析器 经验 | 初入NLP领域的一些小建议 学术 | 如何写一篇合格的NLP论文 干货 | 那些高产的学者都是怎样工作的? 一个简单有效的联合模型 近年来NLP在法律领域的相关研究工作 让更多的人知道你“在看”6 工程实现细节
7 jieba分词源码解读
7.1 HMM分词基本概念
7.2 模型参数
![]()

![]()
7.3 维特比算法

7.4 分词



