对于自己爬取数据的可视化
上一篇博客我爬取了豆瓣top100的各种元素,那么如何来做一个数据分析呢,这很重要。俗话说文不如表,表不如图,用图像可以让人们更加快速和准确的发现隐藏在数据底下的规律。
首先还是导入模块
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from pylab import mpl
先设置一下中文字体的显示,matplotlib是无法正常显示中文字体的,因此要把字体设置更改一下。
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
mpl.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
这里很重要的一点是SimHei这个字体mac里没有,需要自己下载然后导入到matplotlib的字体库里就行。
然后原来的画图主题太难看了,这里换一下
plt.style.use("ggplot")
好了下面导入数据
names=["index","name","img","director","time","score","info"]
ref=pd.read_csv("********",header=None,encoding="utf-8",names=names,index_col="index")
#这里names指定列名,index_col用index这一列作为序数
现在画图了,第一个我们想知道评分排名前十的电影是哪几部,它们的差别又多大
def score_figure(df):
df=df.sort_values("score",ascending=False)#降序排列
names=df["name"][:10]
plt.bar(range(10),df["score"][:10],tick_label=names)
plt.title("评分top10电影“)
plt.xlabel("名称“)
plt.ylabel(“评分”)
plt.xticks(rotation=270)
plt.ylim(9.2,9.7)
plt.show()
看看效果
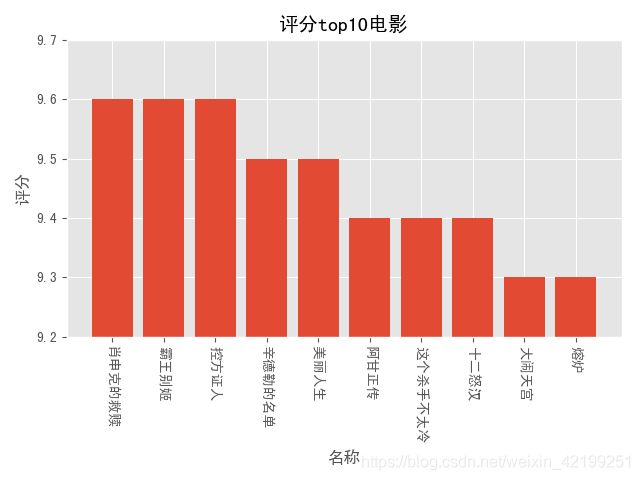
好像还不错,但是我希望柱子上能显示数字,这也很简单,可以参考之前的博客
def add_numer_to_bar(height):
for x,y in enumerate(list(height)):
plt.text(x,y+0.02, y, ha="center", va="bottom")
看一看效果
还可以,不错。
除了评分我还想看一下年份和作品数量有什么样的关系
def time_number_film(df):
res=df.groupby("time")
ref=res.time.count().sort_values(ascending=False)
ref.plot(kind="bar")
plt.title("年份电影发行量")
plt.xlabel("年份")
plt.ylabel("数量")
看一看效果
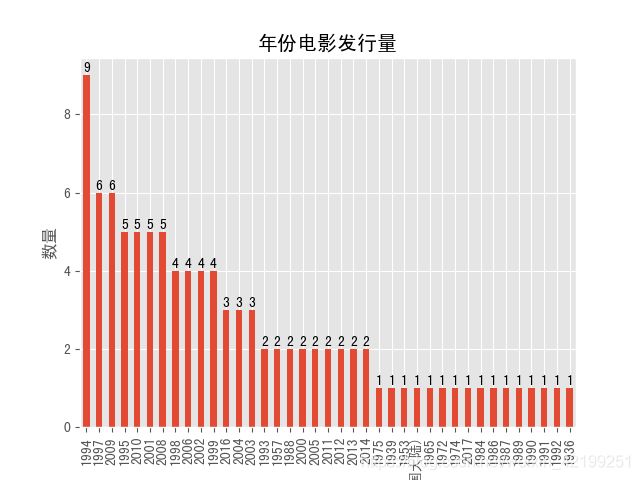
还可以,图像出来之后就更加简单明了,可视化看着挺舒服的,下面几篇我会写下用beautifulsoup来解析源代码,这种方法更为简单且不易出错。
以上。