机器学习实战演练 波士顿房价预测与模型评估
介绍数据集:
本数据集共有506个样本,每个样本有13个特征及标签MEDV
特征信息:
CRIM 城镇人均犯罪率
ZN 占地面积超过2.5万平方英尺的住宅用地比例
INDUS 城镇非零售业务地区的比例
CHAS 查尔斯河虚拟变量 (= 1 如果土地在河边;否则是0)
NOX 一氧化氮浓度(每1000万份)
RM 平均每居民房数
AGE 在1940年之前建成的所有者占用单位的比例
DIS 与五个波士顿就业中心的加权距离
RAD 辐射状公路的可达性指数
TAX 每10,000美元的全额物业税率
PTRATIO 城镇师生比例
B 1000(Bk - 0.63)^2 其中 Bk 是城镇的黑人比例
LSTAT 人口中地位较低人群的百分数
MEDV 以1000美元计算的自有住房的中位数
实战演练:
1.导入所需要的包
from sklearn.datasets import load_boston
import numpy as np
import pandas as pd
import matplotlib.pyplot as pl
2.加载数据集
boston = load_boston()#加载数据集
print(type(boston))
print(boston.data.shape)#(506,13)
#初始化一个DataFrame
data = pd.DataFrame(boston.data)
print(type(data))
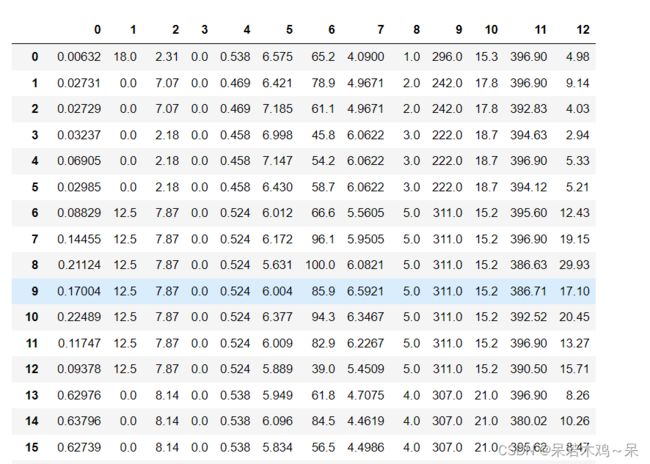
display(data)#如下图1所示
#给DataFrame加载一个变量
data.columns = boston.feature_names
print(type(data.columns))
print(data.shape)
display(data)#如下图二所示
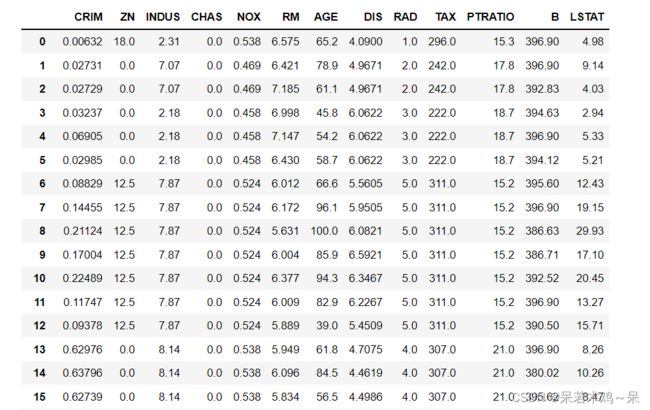
3、给DataFrame加载一个变量
#加载一个可变的target给DataFrame
data['PRICE'] = boston.target
print(data.shape)(506,14)
data.columns
'''
Index(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'PRICE'],
dtype='object')
'''
data.dtypes
'''
CRIM float64
ZN float64
INDUS float64
CHAS float64
NOX float64
RM float64
AGE float64
DIS float64
RAD float64
TAX float64
PTRATIO float64
B float64
LSTAT float64
PRICE float64
dtype: object
'''
data.nunique()#每一列中不重复的数据个数
'''
CRIM 504
ZN 26
INDUS 76
CHAS 2
NOX 81
RM 446
AGE 356
DIS 412
RAD 9
TAX 66
PTRATIO 46
B 357
LSTAT 455
PRICE 229
dtype: int64
'''
4.数据的检测
#检查错误值
print(type(data.isnull()))
#i返回布尔值;该处为缺失值,返回True,该处不为缺失值,则返回False
#data.isnull()
#每列缺失值的个数
print(data.isnull().sum())
#print(type(data.isna()))
#检测缺失值
#print(data.isna().sum())#每列中缺失值的个数
# print(data.isnull().any(axis=1))#检查每行的缺失值
'''
CRIM 0
ZN 0
INDUS 0
CHAS 0
NOX 0
RM 0
AGE 0
DIS 0
RAD 0
TAX 0
PTRATIO 0
B 0
LSTAT 0
PRICE 0
dtype: int64
'''
5、分析数据
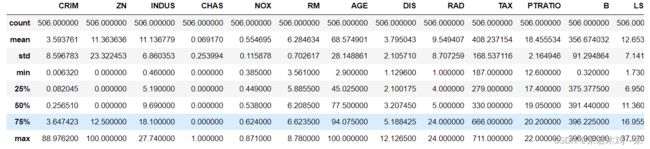
data.describe()#统计数据
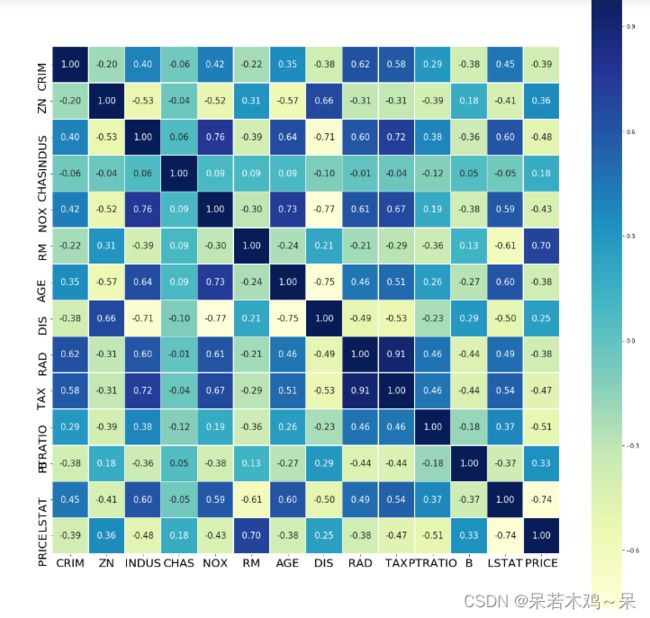
import seaborn as sn
#计算数据的相关性
corr = data.corr()
corr.shape
#print('corrlation matrix')
#print(type(corr))
#print(corr)
plt.figure(figsize=(20,20))
ax = sn.heatmap(corr,square=True,fmt='.2f',annot=True,linewidths=.5,annot_kws={'size':15},cmap='YlGnBu')
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(labelsize=20)
6、切分数据集
#trainData+features
X = data.drop(['PRICE'],axis=1)
#testData+label
y = data['PRICE']
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=4)
7、线性回归算法
1、调用模型
#线性回归算法
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(X_train,y_train)
2、模型评估
“斜率”参数(w,也叫作权重或系数)被保存在coef_属性中,而便宜或截距(b)被保存在intercept_属性中。
# 例如:g(x) = w1x1 + w2x2 + w3x3 + w0
print(lm.intercept_)#即为W0
print('---------------')
print(lm.coef_)#即为W1、W2、W3
print(lm.coef_.shape)
'''
36.35704137659441
---------------
[-1.22569795e-01 5.56776996e-02 -8.83428230e-03 4.69344849e+00
-1.44357828e+01 3.28008033e+00 -3.44778157e-03 -1.55214419e+00
3.26249618e-01 -1.40665500e-02 -8.03274915e-01 9.35368715e-03
-5.23477529e-01]
(13,)
'''
#转换成一个DataFrame
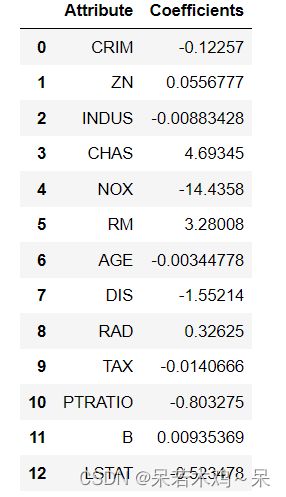
coeffcients = pd.DataFrame([X_train.columns,lm.coef_]).T
coeffcients = coeffcients.rename(columns={0:'Attribute',1:'Coefficients'})
coeffcients
R方(R-squared):衡量模型拟合度的一个量,用来度量未来的样本是否可能通过模型被很好地预测。分值为1表示最好,它可以是负数(因为模型可以很糟糕);
调整R方(Adjusted R-Square):用r square的时候,不断添加变量能让模型的效果提升,而这种提升是虚假的。用adjusted r square,能对添加的非显著变量给出惩罚,也就是说随意添加一个变量不一定能让模型拟合度上升。
平均绝对误差(Mean absolute error):该指标对应于绝对误差loss(absolute error loss)或l1范式loss(l1-norm loss)的期望值。
均方误差(Mean squared error):该指标对应于平方(二次方)误差loss(squared (quadratic) error loss)的期望值。
均方根误差(RMSE):RMSE其实是MSE开根号,两者实质一样,但RMSE能更好的描述数据。
#模型预测train data
y_pred = lm.predict(X_train)
#模型评估
from sklearn import metrics
print('R^2:',metrics.r2_score(y_train,y_pred))#决定系数
print('Adjusted R^2',1-(1-metrics.r2_score(y_train,y_pred))*(len(y_train)-X_train.shape[1]-1))#校正决定系数
print('MAE:',metrics.mean_absolute_error(y_train,y_pred))
print('MSE:',metrics.mean_squared_error(y_train,y_pred))
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_train,y_pred)))
'''
R^2: 0.7465991966746854
Adjusted R^2 -85.15627313060695
MAE: 3.0898610949711287
MSE: 19.073688703469035
RMSE: 4.367343437774162
'''
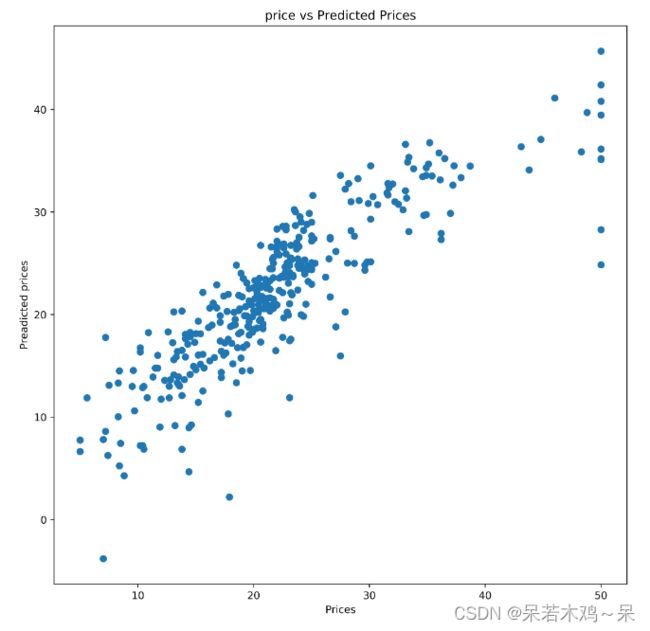
#比较精确的 PRICE 和 预测值
plt.figure(figsize=(10,10),dpi=500)
plt.scatter(y_train,y_pred)
plt.xlabel('Prices')
plt.ylabel("Preadicted prices")
plt.title("price vs Predicted Prices")
plt.show()
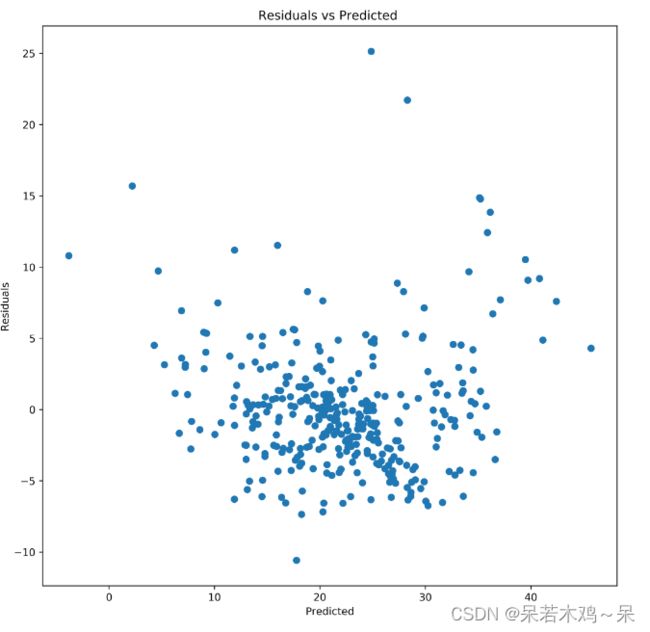
#检查剩余误差
plt.figure(figsize=(10,10),dpi=500)
plt.scatter(y_pred,y_train-y_pred)
plt.xlabel('Predicted')
plt.ylabel("Residuals")
plt.title("Residuals vs Predicted ")
plt.show()
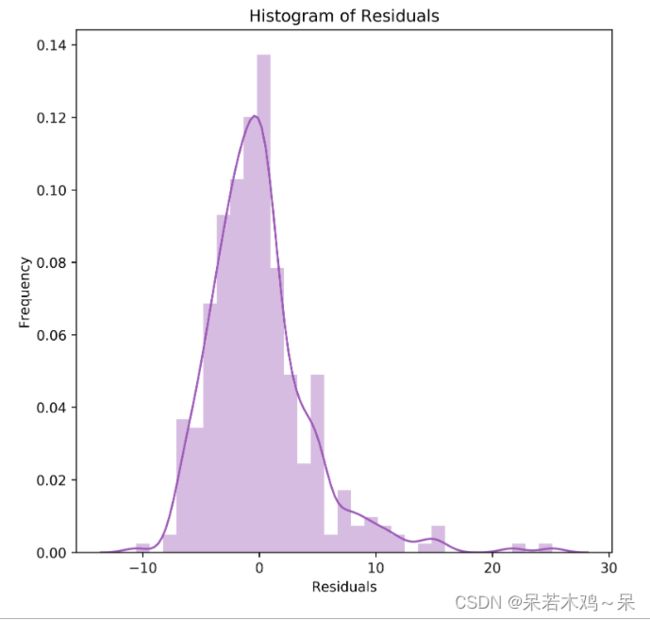
#检测误差
plt.figure(figsize=(7,7),dpi=500)
sn.distplot(a=y_train - y_pred,color='#9b59b6')
plt.title('Histogram of Residuals')
plt.xlabel("Residuals")
plt.ylabel("Frequency")
plt.show()
#预测test data
y_test_pred = lm.predict(X_test)
#衡量模型拟合度的一个量,用来度量未来的样本是否可能通过模型被很好地预测。分值为1表示最好,它可以是负数(因为模型可以很糟糕)
print('R^2:',metrics.r2_score(y_test,y_test_pred))#决定系数
print('Adjusted R^2',1-(1-metrics.r2_score(y_test,y_test_pred))*(len(y_train)-X_train.shape[1]-1))#校正决定系数
print('MAE:',metrics.mean_absolute_error(y_test,y_test_pred))
print('MSE:',metrics.mean_squared_error(y_test,y_test_pred))
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_test,y_test_pred)))
'''
R^2: 0.7120461624218637
Adjusted R^2 -96.90430477656635
MAE: 3.8670693946558057
MSE: 30.068160533746802
RMSE: 5.483444221814133
'''
8、模型改进
1、对数据进行标准化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
2、引如xgboost模型
# Import XGBoost Regressor
from xgboost import XGBRFRegressor
xg = XGBRFRegressor()
xg.fit(X_train,y_train)
3、模型评估
#模型预测 train data
y_pred = xg.predict(X_train)
#模型评估
from sklearn import metrics
#衡量模型拟合度的一个量,用来度量未来的样本是否可能通过模型被很好地预测。分值为1表示最好,它可以是负数(因为模型可以很糟糕)
print('R^2:',metrics.r2_score(y_train,y_pred))#决定系数
print('Adjusted R^2',1-(1-metrics.r2_score(y_train,y_pred))*(len(y_train)-X_train.shape[1]-1))#校正决定系数
print('MAE:',metrics.mean_absolute_error(y_train,y_pred))
print('MSE:',metrics.mean_squared_error(y_train,y_pred))
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_train,y_pred)))
'''
R^2: 0.9610761807415549
Adjusted R^2 -12.234098547871342
MAE: 1.338177258011985
MSE: 2.929828169220753
RMSE: 1.7116740838199171
'''
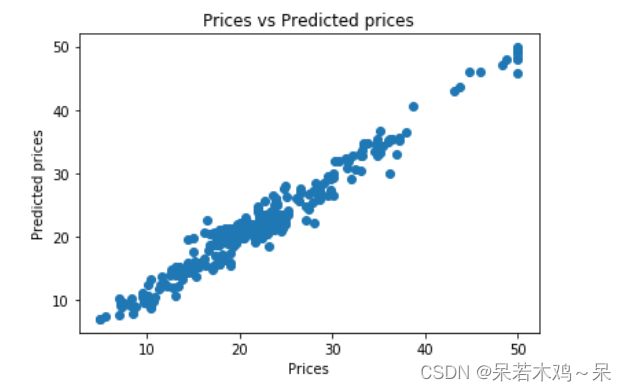
plt.scatter(y_train, y_pred)
plt.xlabel("Prices")
plt.ylabel("Predicted prices")
plt.title("Prices vs Predicted prices")
plt.show()
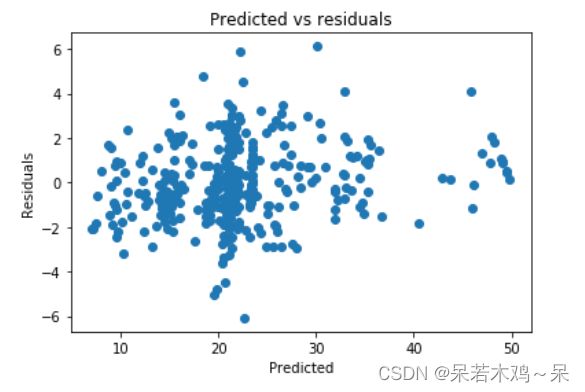
plt.scatter(y_pred,y_train-y_pred)
plt.title("Predicted vs residuals")
plt.xlabel("Predicted")
plt.ylabel("Residuals")
plt.show()
y_test_pred = xg.predict(X_test)
print('R^2:',metrics.r2_score(y_test,y_test_pred))#决定系数
print('Adjusted R^2',1-(1-metrics.r2_score(y_test,y_test_pred))*(len(y_train)-X_train.shape[1]-1))#校正决定系数
print('MAE:',metrics.mean_absolute_error(y_test,y_test_pred))
print('MSE:',metrics.mean_squared_error(y_test,y_test_pred))
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_test,y_test_pred)))
'''
R^2: 0.8280047551811247
Adjusted R^2 -57.4783832384176
MAE: 2.716848931814495
MSE: 17.95975589612247
RMSE: 4.23789522004998
'''