16_NLP stateful CharRNN_window_Tokenizer_stationary_colab_ResetState_character word level_regex_IMDb
When Alan Turing imagined his famous Turing test (Alan Turing, “Computing Machinery and Intelligence,” Mind 49 (1950): 433–460.) in 1950, his objective was to evaluate a machine’s ability to match human intelligence. He could have tested for many things, such as the ability to recognize cats in pictures, play chess, compose music, or escape a maze, but, interestingly, he chose a linguistic task. More specifically, he devised a chatbot capable of fooling its interlocutor([ˌɪntərˈlɑkjətə(r)]对话者) into thinking it was human. This test does have its weaknesses: a set of hardcoded rules can fool unsuspecting or naive humans (e.g., the machine could give vague([veɪɡ](表达或感知)含糊的) predefined answers in response to some keywords; it could pretend that it is joking or drunk, to get a pass on its weirdest answers; or it could escape difficult questions by answering them with its own questions), and many aspects of human intelligence are utterly[ˈʌtərli]彻底地 ignored (e.g., the ability to interpret nonverbal communication such as facial expressions, or to learn a manual task). But the test does highlight the fact that mastering language is arguably Homo sapiens’s greatest cognitive ability. Can we build a machine that can read and write natural language?
A common approach for natural language tasks is to use recurrent neural networks. We will therefore continue to explore RNNs (introduced in Chapter 15 https://blog.csdn.net/Linli522362242/article/details/114941730 ), starting with a character RNN, trained to predict the next character in a sentence. This will allow us to generate some original text, and in the process we will see how to build a Tensor‐Flow Dataset on a very long sequence. We will first use a stateless无状态的 RNN (which learns on random portions of text at each iteration, without any information on the rest of the text), then we will build a stateful RNN (which preserves the hidden state between training iterations and continues reading where it left off, allowing it to learn longer patterns). Next, we will build an RNN to perform sentiment analysis (e.g., reading movie reviews and extracting the rater’s feeling about the movie), this time treating sentences as sequences of words, rather than characters. Then we will show how can be used to build an Encoder–Decoder architecture capable of performing neural machine translation (NMT). For this, we will use the seq2seq API provided by the TensorFlow Addons project.
In the second part of this chapter, we will look at attention mechanisms. As their name suggests, these are neural network components that learn to select the part of the inputs that the rest of the model should focus on at each time step. First we will see how to boost the performance of an RNN-based Encoder–Decoder architecture using attention, then we will drop RNNs altogether and look at a very successful attentiononly architecture called the Transformer. Finally, we will take a look at some of the most important advances in NLP in 2018 and 2019, including incredibly powerful language models such as GPT-2 and BERT, both based on Transformers.
Let’s start with a simple and fun model that can write like Shakespeare (well, sort of).
Generating Shakespearean Text Using a Character RNN
In a famous 2015 blog post titled “The Unreasonable Effectiveness of Recurrent Neural Networks,” Andrej Karpathy showed how to train an RNN to predict the next character in a sentence. This Char-RNN can then be used to generate novel text, one character at a time. Here is a small sample of the text generated by a Char-RNN model after it was trained on all of Shakespeare’s work:
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain’d into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Not exactly a masterpiece, but it is still impressive that the model was able to learn words, grammar, proper punctuation, and more, just by learning to predict the next character in a sentence. Let’s look at how to build a Char-RNN, step by step, starting with the creation of the dataset.
Char-RNN
Splitting a sequence into batches of shuffled windows
For example, let's split the sequence 0 to 14 into windows of length 5, each shifted by 2 (e.g.,[0, 1, 2, 3, 4], [2, 3, 4, 5, 6], etc.), then shuffle them, and split them into inputs (the first 4 steps) and targets (the last 4 steps) (e.g., [2, 3, 4, 5, 6] would be split into [[2, 3, 4, 5], [3, 4, 5, 6]]), then create batches of 3 such input/target pairs:
n_steps = 5
# tf.range(15)
#
dataset = tf.data.Dataset.from_tensor_slices( tf.range(15) )
# dataset :
# The window() method creates a dataset that contains windows,
# each of which is also represented as a dataset. It’s a nested dataset,
# similar to a list of lists.
# drop_remainder=True
# To ensure that all windows are exactly n_steps characters long
dataset = dataset.window( n_steps, shift=2, drop_remainder=True )
for ds in dataset:
print( [elem.numpy() for elem in ds])  # iterations = ( len(text) - 1 - window_size +1 )/shift +1=( len(text)-window_size )/shift +1=(15-5)/2=5 +1=6 windows, each_window_size=5=n_steps
# iterations = ( len(text) - 1 - window_size +1 )/shift +1=( len(text)-window_size )/shift +1=(15-5)/2=5 +1=6 windows, each_window_size=5=n_steps
# we cannot use a nested dataset directly for training,
# as our model will expect tensors as input, not datasets.
# So, we must call the flat_map() method: it converts a nested dataset into
# a flat dataset (one that does not contain datasets).
# If you flatten the nested dataset {{1, 2}, {3, 4, 5, 6}},
# you get back the flat dataset {1, 2, 3, 4, 5, 6}.
# if you pass the function lambda ds: ds.batch(2) to flat_map(),
# then it will transform the nested dataset {{1, 2}, {3, 4, 5,6}} into the
# flat dataset {[1, 2], [3, 4], [5, 6]}: it’s a dataset of tensors of size 2
# Notice that we call batch(n_steps) on each window: since all windows have
# exactly that length, we will get a single tensor for each of them.
dataset = dataset.flat_map( lambda window: window.batch( n_steps) )
for ds in dataset:
print( [elem.numpy() for elem in ds]) # n_steps=5
# n_steps=5
########################
dataset = dataset.flat_map( lambda window: window.batch( 2 ) )
for ds in dataset:
print( [elem.numpy() for elem in ds])  # n_steps=2
# n_steps=2
########################
# X # y_target
dataset = dataset.shuffle(10).map( lambda window: (window[:-1], window[1:]) )
dataset = dataset.batch(3).prefetch(1)
for index, (X_batch, Y_batch) in enumerate(dataset):
print( "_"*20, "Batch", index,
"\nX_batch")
print( X_batch.numpy() )
print( "="*5,
"\nY_batch" )
print( Y_batch.numpy() ) 
Creating the Training Dataset
First, let’s download all of Shakespeare’s莎士比亚 work, using Keras’s handy get_file() function and downloading the data from Andrej Karpathy’s Char-RNN project:
from tensorflow import keras
shakespeare_url = "https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt"
filepath = keras.utils.get_file( "shakespeare.txt",
shakespeare_url )
with open( filepath ) as f:
shakespeare_text = f.read()![]()
print( shakespeare_text[:148] )
"".join( sorted( set(
shakespeare_text.lower()
)
) )![]()
#####################################Tokenizer
help(keras.preprocessing.text.Tokenizer)tf.keras.preprocessing.text.Tokenizer https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer
tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' ', char_level=False, oov_token=None,
document_count=0, **kwargs
)char_level : if True, every character will be treated as a token
fit_on_texts(
texts
)Updates internal vocabulary based on a list of texts.
In the case where texts contains lists, we assume each entry of the lists to be a token.
Required before using texts_to_sequences or texts_to_matrix.
#####################################
Next, we must encode every character as an integer. One option is to create a custom preprocessing layer, as we did in Cp13 (https://blog.csdn.net/Linli522362242/article/details/107933572). But in this case, it will be simpler to use Keras’s Tokenizer class. First we need to fit a tokenizer to the text: it will find all the characters used in the text and map each of them to a different character ID, from 1 to the number of distinct characters (it does not start at 0, so we can use that value for masking, as we will see later in this chapter):
tokenizer = keras.preprocessing.text.Tokenizer( char_level=True )
tokenizer.fit_on_texts(shakespeare_text)We set char_level=True to get character-level encoding rather than the default word-level encoding. Note that this tokenizer converts the text to lowercase by default (but you can set lower=False if you do not want that). Now the tokenizer can encode a sentence (or a list of sentences) to a list of character IDs and back, and it tells us how many distinct characters there are and the total number of characters in the text:
tokenizer.texts_to_sequences(["First"])![]()
tokenizer.sequences_to_texts( [[20, 6, 9, 8, 3]] )![]()
tokenizer.word_index from 1 to the number of distinct characters (it does not start at 0
from 1 to the number of distinct characters (it does not start at 0
max_id = len(tokenizer.word_index) # number of distinct characters
# max_id # 39
dataset_size = tokenizer.document_count # total number of characters
# dataset_size # 1115394Let’s encode the full text so each character is represented by its ID (we subtract 1 to get IDs from 0 to 38, rather than from 1 to 39):
# np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1
# array([[19, 5, 8, ..., 20, 26, 10]])
[encoded] = np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1
encoded![]() <==[encoded]<==
<==[encoded]<==![]()
Before we continue, we need to split the dataset into a training set, a validation set, and a test set. We can’t just shuffle all the characters in the text, so how do you split a sequential dataset?
How to Split a Sequential Dataset
It is very important to avoid any overlap between the training set, the validation set, and the test set. For example, we can take the first 90% of the text for the training set, then the next 5% for the validation set, and the final 5% for the test set. It would also be a good idea to leave a gap between these sets to avoid the risk of a paragraph overlapping over two sets.
When dealing with time series,
- you would in general split across time,:
for example, you might take the years 2000 to 2012 for the training set, the years 2013 to 2015 for the validation set, and the years 2016 to 2018 for the test set. However, in some cases you may be able to - split along other dimensions, which will give you a longer time period to train on.
For example, if you have data about the financial health of 10,000 companies from 2000 to 2018, you might be able to split this data across the different companies. It’s very likely that many of these companies will be strongly correlated, though (e.g., whole economic sectors may go up or down jointly), and if you have correlated companies across the training set and the test set your test set will not be as useful, as its measure of the generalization error will be optimistically biased.
So, it is often safer to split across time—but this implicitly assumes that the patterns the RNN can learn in the past (in the training set) will still exist in the future. In other words, we assume that the time series is stationary (at least in a wide sense)###By definition, a stationary time series’s mean, variance, and autocorrelations (i.e., correlations between values in the time series separated by a given interval) do not change over time. This is quite restrictive; for example, it excludes time series with trends or cyclical patterns. RNNs are more tolerant in that they can learn trends and cyclical patterns.###. For many time series this assumption is reasonable (e.g., chemical reactions should be fine, since the laws of chemistry don’t change every day), but for many others it is not (e.g., financial markets are notoriously not stationary since patterns disappear as soon as traders spot them and start exploiting them). To make sure the time series is indeed sufficiently stationary, you can plot the model’s errors on the validation set across time: if the model performs much better on the first part of the validation set than on the last part, then the time series may not be stationary enough, and you might be better off training the model on a shorter time span.
In short, splitting a time series into a training set, a validation set, and a test set is not a trivial task, and how it’s done will depend strongly on the task at hand.
Now back to Shakespeare! Let’s take the first 90% of the text for the training set (keeping the rest for the validation set and the test set), and create a tf.data.Dataset that will return each character one by one from this set:
train_size = dataset_size * 90 //100
dataset = tf.data.Dataset.from_tensor_slices( encoded[:train_size] )Chopping the Sequential Dataset into Multiple Windows
The training set now consists of a single sequence of over a million characters, so we can’t just train the neural network directly on it: the RNN would be equivalent to a deep net with over a million layers, and we would have a single (very long) instance to train it. Instead, we will use the dataset’s window() method to convert this long sequence of characters into many smaller windows of text. Every instance in the dataset will be a fairly short substring of the whole text, and the RNN will be unrolled only over the length of these substrings. This is called truncated backpropagation through time. Let’s call the window() method to create a dataset of short text windows:
n_steps = 100 # the inputs=windows[:, :-1], targets=windows[:, 1:], the lengths of both of them are 100
window_length = n_steps+1 # target=input shifted 1 character ahead
dataset = dataset.repeat().window( window_length, shift=1, drop_remainder=True)You can try tuning n_steps: it is easier to train RNNs on shorter input sequences, but of course the RNN will not be able to learn any pattern longer than n_steps, so don’t make it too small.
By default, the window() method creates nonoverlapping windows, but to get the largest possible training set we use shift=1 so that the first window contains characters 0 to 100, the second contains characters 1 to 101, and so on. To ensure that all windows are exactly 101 characters long (which will allow us to create batches without having to do any padding), we set drop_remainder=True (otherwise the last 100 windows will contain 100 characters, 99 characters, and so on down to 1 character).
The window() method creates a dataset that contains windows, each of which is also represented as a dataset. It’s a nested dataset, analogous to a list of lists. This is useful when you want to transform each window by calling its dataset methods (e.g., to shuffle them or batch them). However, we cannot use a nested dataset directly for training, as our model will expect tensors as input, not datasets. So, we must call the flat_map() method: it converts a nested dataset into a flat dataset (one that does not contain datasets). For example, suppose {1, 2, 3} represents a dataset containing the sequence of tensors 1, 2, and 3.
- If you flatten the nested dataset {{1, 2}, {3, 4, 5, 6}}, you get back the flat dataset {1, 2, 3, 4, 5, 6}. Moreover, the flat_map() method takes a function as an argument, which allows you to transform each dataset in the nested dataset before flattening.
- For example, if you pass the function lambda ds: ds.batch(2) to flat_map(), then it will transform the nested dataset {{1, 2}, {3, 4, 5, 6}} into the flat dataset {[1, 2], [3, 4], [5, 6]}: it’s a dataset of tensors of size 2. With that in mind, we are ready to flatten our dataset:
dataset = dataset.flat_map( lambda window: window.batch( window_length ) )Notice that we call batch(window_length) on each window: since all windows have exactly that length, we will get a single tensor for each of them. Now the dataset contains consecutive windows of 101 characters each. Since Gradient Descent works best when the instances in the training set are independent and identically distributed (see Cp4 https://blog.csdn.net/Linli522362242/article/details/104005906), we need to shuffle these windows. Then we can batch the windows and separate the inputs (the first 100 characters) from the target (the last character):
np.random.seed(42) tf.random.set_seed(42) batch_size = 32 dataset = dataset.shuffle(10000).batch(batch_size) dataset = dataset.map( lambda windows: (windows[:, :-1], windows[:, 1:]) ) # X_inputs, Y_targetFigure 16-1 summarizes the dataset preparation steps discussed so far (showing windows of length 11 rather than 101, and a batch size of 3 instead of 32).
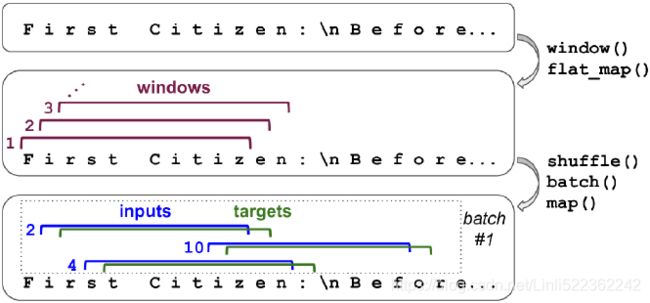 Figure 16-1. Preparing a dataset of shuffled windows
Figure 16-1. Preparing a dataset of shuffled windows
As discussed in Cp13 https://blog.csdn.net/Linli522362242/article/details/107933572, categorical input features should generally be encoded, usually as one-hot vectors or as embeddings. Here, we will encode each character using a one-hot vector because there are fairly few distinct characters (only 39): https://blog.csdn.net/Linli522362242/article/details/107933572
https://blog.csdn.net/Linli522362242/article/details/107933572
# max_id = len(tokenizer.word_index) # number of distinct characters
# max_id # 39
# X_batch is the text characters' indices-1(means the index is start from 0)
# [encoded] = np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1
# so the actual max_id=38
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch)
) # note: num_oov_buckets=0Finally, we just need to add prefetching:
dataset = dataset.prefetch(1)for X_batch, Y_batch in dataset.take(1):
print( X_batch.shape, Y_batch.shape ) ![]()
That’s it! Preparing the dataset was the hardest part. Now let’s create the model.
Building and Training the Char-RNN Model
To predict the next character based on the previous 100 characters, we can use
- an RNN with 2 GRU layers of 128 units each and 20% dropout on both the inputs (drop out, the dropout rate to apply to the inputs~feature neurons (at each time step)) and the hidden states (recurrent_dropout, dropout rate for the hidden states (also at each time step)). We can tweak these hyperparameters later, if needed. ### input_shape=[None, max_id] since a recurrent neural network can process any number of time steps (this is why we set the first input dimension to None) ###
- The output layer is a time-distributed Dense layer like we saw in Cp15 https://blog.csdn.net/Linli522362242/article/details/114941730. This time this layer must have 39 units (max_id) because there are 39 distinct characters in the text, and we want to output a probability for each possible character (at each time step). The output probabilities should sum up to 1 at each time step, so we apply the softmax activation function to the outputs of the Dense layer.
- We can then compile this model, using the "sparse_categorical_crossentropy" loss(since for classfication and dataset is a sparse matrix) and an Adam optimizer. Finally, we are ready to train the model for several epochs (this may take many hours, depending on your hardware):
from tensorflow import keras shakespeare_url = "https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt" filepath = keras.utils.get_file( "/content/drive/MyDrive/Colab Notebooks/data/shakespeare.txt", shakespeare_url ) # filepath # '/content/drive/MyDrive/Colab Notebooks/data/shakespeare.txt' with open( filepath ) as f: shakespeare_text = f.read() filepath
tokenizer = keras.preprocessing.text.Tokenizer( char_level=True ) tokenizer.fit_on_texts(shakespeare_text) import numpy as np max_id = len(tokenizer.word_index) # number of distinct characters # max_id # 39 dataset_size = tokenizer.document_count # total number of characters # dataset_size # 1115394 # np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1 # array([[19, 5, 8, ..., 20, 26, 10]]) [encoded] = np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1 encoded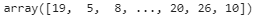 #convert the whole shakespeare text to a encoded list(1D array: batch_size=1, time_steps=1, features=len(encoded) )
#convert the whole shakespeare text to a encoded list(1D array: batch_size=1, time_steps=1, features=len(encoded) ) - a encoded list ==> window()==> (windows, window_size)==> window.batch(window_length) ==>(new instances, window_size)==>batch(32)
import tensorflow as tf train_size = dataset_size * 90 //100 # 90% for training # 1003854 dataset = tf.data.Dataset.from_tensor_slices( encoded[:train_size] ) #len(encoded[:train_size])=1003854 n_steps = 100 window_length = n_steps+1 # target=input shifted 1 character ahead~~feature columns dataset = dataset.repeat().window( window_length, shift=1, drop_remainder=True) # ( len(text)-window_size )/shift +1 = (1003854-101)//1 + 1=1003754 # (1003754 windows, each_window_size=101) dataset = dataset.flat_map( lambda window: window.batch( window_length )#==>a nested dataset ) # flap_map() converts a nested dataset in to a flat dataset # (1003754 instances(windows), each_instance_is_a_window_size=101)#since the above batch_size=window_length np.random.seed(42) tf.random.set_seed(42) batch_size = 32 dataset = dataset.shuffle(10000).batch(batch_size)#31367 batches dataset = dataset.map( lambda windows: (windows[:, :-1], windows[:, 1:]) ) # X, Y_target # X : (batch_size=32, each_batch_is_window_size=100) # Y_target : (batch_size=32, each_window_size=100) # each X is one batch, each Y_target is also one batch # max_id = len(tokenizer.word_index) # number of distinct characters # max_id # 39 # X_batch is the text characters' indices-1(means the index is start from 0) # [encoded] = np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1 # so the actual max_id=38 dataset = dataset.map( lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch) ) # note: num_oov_buckets=0 dataset = dataset.prefetch(1) for X_batch, Y_batch in dataset.take(1):# take 1 batch print( X_batch.shape, Y_batch.shape )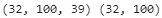 ( batch_size=32, time_steps_OR_characters=100=window_length-1, probabities on (max_id)=39 characters(dict) OR 39 features )
( batch_size=32, time_steps_OR_characters=100=window_length-1, probabities on (max_id)=39 characters(dict) OR 39 features )
Note: themodel = keras.models.Sequential([ keras.layers.GRU( 128, return_sequences=True, input_shape=[None, max_id], # dropout=0.2, recurrent_dropout=0.2 ), dropout=0.2), keras.layers.GRU( 128, return_sequences=True, # dropout=0.2, recurrent_dropout=0.2 ), dropout=0.2), keras.layers.TimeDistributed( keras.layers.Dense( max_id, activation="softmax") ) ]) model.compile( loss="sparse_categorical_crossentropy", optimizer="adam") history = model.fit( dataset, steps_per_epoch=train_size//batch_size,#batch_size=32 epochs=10 )GRUclass will only use the GPU (if you have one) when using the default values for the following arguments:activation,recurrent_activation,recurrent_dropout,unroll,use_biasandreset_after(means I would spend more hours to run this code). This is why I commented outrecurrent_dropout=0.2 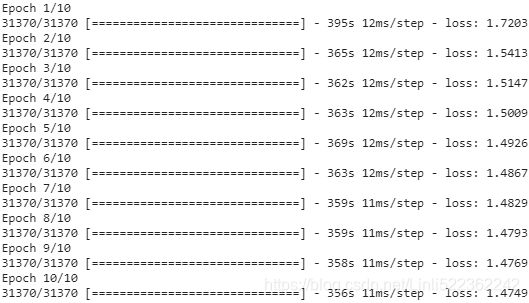 =1003854//32=31370 but we only have 31367 batches, so the program has to retake 3 batches from dataset.shuffle(10000).batch(batch_size)
=1003854//32=31370 but we only have 31367 batches, so the program has to retake 3 batches from dataset.shuffle(10000).batch(batch_size)
Using the Char-RNN Model
Now we have a model that can predict the next character in text written by Shakespeare. To feed it some text, we first need to preprocess it like we did earlier, so let’s create a little function for this:
def preprocess(texts):
X = np.array( tokenizer.texts_to_sequences(texts) )-1
return tf.one_hot(X, max_id)
# Now let’s use the model to predict the next letter in some text:
X_new = preprocess(["How are yo"])
Y_pred = np.argmax( model(X_new), axis=-1 ) # axis=-1 for feature/character
tokenizer.sequences_to_texts(Y_pred+1)[0][-1] # 1st sentence([0]), last char
# len(tokenizer.sequences_to_texts(Y_pred+1)[0]) # ['e u t e t o u']![]() why is last char(the predicted target char)? since len("How are Yo")=10 and # total characters in ['e u t e t o u'] is 10 except some space.
why is last char(the predicted target char)? since len("How are Yo")=10 and # total characters in ['e u t e t o u'] is 10 except some space.
X_new = preprocess(["I love yo"])
Y_pred = np.argmax( model(X_new), axis=-1 ) # axis=-1 : all estimated probabilities on (max_id)=39 characters and the length of first target(Y_pred[0]) is equal to len("I love yo")
tokenizer.sequences_to_texts(Y_pred+1)[0] # 1st sentence([0])![]() # model(X_new) ==> ( batch_size, time_steps_OR_characters, probabities on (max_id)=39 characters(dict) OR 39 features )
# model(X_new) ==> ( batch_size, time_steps_OR_characters, probabities on (max_id)=39 characters(dict) OR 39 features )
Y_pred[0]+1![]() ==>the index of last char:14 ==> 'u'
==>the index of last char:14 ==> 'u'
tokenizer.sequences_to_texts(Y_pred+1)[0][-1]# 1st sentence([0]) or 1st target, last char on 1st target![]()
X_new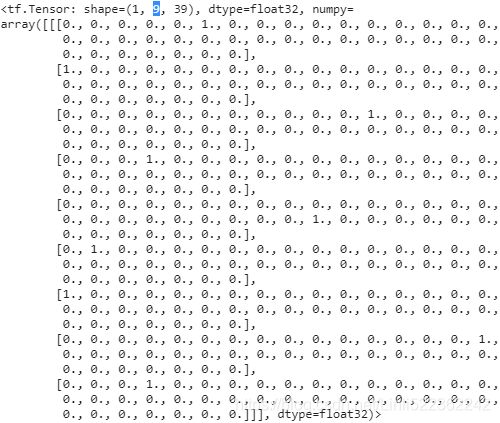
Success! The model guessed right. Now let’s use this model to generate new text(based on ### tokenizer.word_index ###).
model.save('/content/drive/MyDrive/Colab Notebooks/models/Char-RNN_cp16.h5')
Generating Fake Shakespearean Text
To generate new text using the Char-RNN model, we could feed it some text, make the model predict the most likely next letter, add it at the end of the text, then give the extended text to the model to guess the next letter, and so on. But in practice this often leads to the same words being repeated over and over again.
Instead, we can pick the next character randomly, with a probability equal to the estimated probability, using TensorFlow’s tf.random.categorical() function. This will generate more diverse and interesting text. The categorical() function samples random class indices, given the class log probabilities (logits).
tf.random.set_seed(42)
tf.random.categorical([
[ np.log(0.5), np.log(0.4), np.log(0.1) ]
], num_samples=40
).numpy()![]()
To have more control over the diversity of the generated text, we can divide the logits by a number called the temperature, which we can tweak as we wish: a temperature close to 0 will favor the highprobability characters, while a very high temperature will give all characters an equal probability(https://blog.csdn.net/Linli522362242/article/details/115258834). The following next_char() function uses this approach to pick the next character to add to the input text:
def next_char( text, temperature=1):
X_new = preprocess([text]) # ':' all estimated probabilities to predect the last char
y_proba = model(X_new)[0,-1:, :] # 0: 1st sentence, -1: last char(or last time step)
rescaled_logits = tf.math.log( y_proba )/temperature
char_id = tf.random.categorical( rescaled_logits, num_samples=1 )+1
return tokenizer.sequences_to_texts( char_id.numpy() )[0]tf.random.set_seed(42)
next_char( "How are yo", temperature=1 )![]()
Next, we can write a small function that will repeatedly call next_char() to get the next character and append it to the given text:
def complete_text( text, n_chars=50, temperature=1 ):
for _ in range( n_chars ):
text += next_char( text, temperature )
return textWe are now ready to generate some text! Let’s try with different temperatures:
tf.random.set_seed(42)
print( complete_text("t", temperature=0.2) )![]()
print( complete_text("t", temperature=1) )![]()
print( complete_text("t", temperature=2) )
Apparently our Shakespeare model works best at a temperature close to 1. To generate more convincing text, you could try using more GRU layers and more neurons per layer, train for longer, and add some regularization (for example, you could set recurrent_dropout=0.3 in the GRU layers). Moreover, the model is currently incapable of learning patterns longer than n_steps, which is just 100 characters. You could try making this window larger, but it will also make training harder, and even LSTM and GRU cells cannot handle very long sequences. Alternatively, you could use a stateful RNN.
from tensorflow import keras
shakespeare_url = "https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt"
filepath = keras.utils.get_file( "/content/drive/MyDrive/Colab Notebooks/data/shakespeare.txt",
shakespeare_url )
# filepath # '/content/drive/MyDrive/Colab Notebooks/data/shakespeare.txt'
with open( filepath ) as f:
shakespeare_text = f.read()
tokenizer = keras.preprocessing.text.Tokenizer( char_level=True )
tokenizer.fit_on_texts(shakespeare_text)
import numpy as np
max_id = len(tokenizer.word_index) # number of distinct characters
# max_id # 39
dataset_size = tokenizer.document_count # total number of characters
# dataset_size # 1115394
# np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1
# array([[19, 5, 8, ..., 20, 26, 10]])
[encoded] = np.array( tokenizer.texts_to_sequences([shakespeare_text]) )-1
# encoded
# array([19, 5, 8, ..., 20, 26, 10])
import tensorflow as tf
train_size = dataset_size * 90 //100 # 90% for training
dataset = tf.data.Dataset.from_tensor_slices( encoded[:train_size] )
n_steps = 100
window_length = n_steps+1 # target=input shifted 1 character aheadStateful RNN
Until now, we have used only 无状态stateless RNNs: at each training iteration the model starts with a hidden state full of zeros, then it updates this state at each time step, and after the last time step, it throws it away, as it is not needed anymore. What if we told the RNN to preserve this final state after processing one training batch and use it as the initial state for the next training batch? This way the model can learn long-term patterns despite only backpropagating through short sequences. This is called a 有状态stateful RNN. Let’s see how to build one.
First, note that a stateful RNN only makes sense if each input sequence in a batch starts exactly where the corresponding sequence in the previous batch left off. So the first thing we need to do to build a stateful RNN is to use sequential and nonoverlapping input sequences (rather than the shuffled and overlapping sequences we used to train stateless RNNs). When creating the Dataset, we must therefore use shift=n_steps (=window_size-1, instead of shift=1) when calling the window() method. Moreover, we must obviously not call the shuffle() method(### if window_size=31, shfit=30, train_x=[1,...,31-1=30], train_y=[2,...,31], next, train_x=[31,...,61], train_y=[32...62], next... ###). Unfortunately, batching is much harder when preparing a dataset for a stateful RNN than it is for a stateless RNN. Indeed, if we were to call batch(32), then 32 consecutive windows would be put in the same batch, and the following batch would not continue each of these window where it left off. The first batch would contain windows 1 to 32 and the second batch would contain windows 33 to 64, so if you consider, say, the first window of each batch (i.e., windows 1 and 33), you can see that they are not consecutive. The simplest solution to this problem is to just use “batches” containing a single window:
tf.random.set_seed(42)
dataset = tf.data.Dataset.from_tensor_slices( encoded[:train_size] ) # train_size = dataset_size *90//100
# n_steps = 100
# window_length = n_steps+1 # target=input shifted 1 character ahead
# encoded list ==> window()==> (windows, window_size)==> window.batch(window_length) ==>(new instances, window_size)
dataset = dataset.window( window_length, shift=n_steps, drop_remainder=True )
dataset = dataset.flat_map( lambda window: window.batch(window_length) )
dataset = dataset.repeat().batch(1)
dataset = dataset.map( lambda windows: (windows[:,:-1], windows[:,1:]) )
dataset = dataset.map( # expand dimension
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch)
)
dataset = dataset.prefetch(1)Figure 16-2 summarizes the first steps.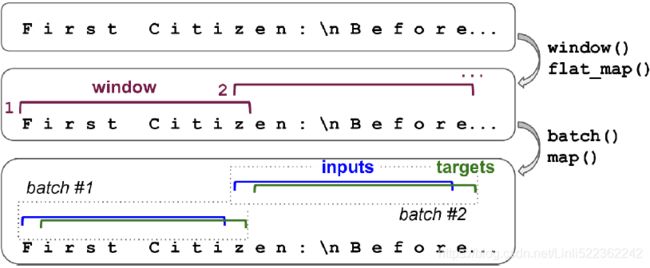 Figure 16-2. Preparing a dataset of consecutive sequence fragments for a stateful RNN
Figure 16-2. Preparing a dataset of consecutive sequence fragments for a stateful RNN
Batching is harder, but it is not impossible. For example, we could chop Shakespeare’s text into 32 texts of equal length, create one dataset of consecutive input sequences for each of them, and finally use tf.train.Dataset.zip(datasets).map( lambda *windows: tf.stack(windows) ) to create proper consecutive batches, where the ![]() input sequence in a batch starts off exactly where the
input sequence in a batch starts off exactly where the ![]() input sequence ended in the previous batch.
input sequence ended in the previous batch.
batch_size = 32
# train_size = dataset_size *90//100
encoded_parts = np.array_split( encoded[:train_size],
indices_or_sections=batch_size )
# len(encoded_parts) # 32 texts of equal length
# 31371...repeat...31371,31370
datasets = []
for encoded_part in encoded_parts:
dataset = tf.data.Dataset.from_tensor_slices(encoded_part)
# encoded list ==> window()==> (windows, window_size)==>
# window.batch(window_length) ==>(new instances, window_size)
# n_steps = 100
# window_length = n_steps+1 # target=input shifted 100 character ahead
dataset = dataset.window( window_length, shift=n_steps, drop_remainder=True )
#==> ( len(text)-window_size )/shift +1 = (31371-101)//100+1 =313 windows
dataset = dataset.flat_map( lambda window: window.batch(window_length) )
#==> (313 instances_or_windows, window_size=101)
datasets.append(dataset)
# datasets: 32 batches and each is (313 instances, window_size=101)
# [,
# ,
# ...
# ]
dataset = tf.data.Dataset.zip( tuple(datasets) ).map( lambda *windows: tf.stack(windows) )
# dataset
# # (batch_size=32, window_size=101)x313
dataset = dataset.repeat().map( lambda windows: (windows[:,:-1], windows[:, 1:]) )
dataset = dataset.map( # expand dimension
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch)
)
dataset = dataset.prefetch(1) # 1 batch : (batch_size=32, window_size=101, max_id features)x313
for x_batch, y_batch in dataset.take(1): # .take(1)
print(x_batch.shape, y_batch.shape) # (32, 100, 39) (32, 100) ![]() x313 to get the whole dataset
x313 to get the whole dataset
Now let’s create the stateful RNN.
- First, we need to set stateful=True when creating every recurrent layer.
- Second, the stateful RNN needs to know the batch size (since it will preserve a state for each input sequence in the batch), so we must set the batch_input_shape argument in the first layer.
- Note that we can leave the second dimension unspecified, since the inputs could have any length:
Note: once again, I commented outrecurrent_dropout=0.2(it cost a lot of time) so you can get GPU acceleration (if you have one).
At the end of each epoch, we need to reset the states before we go back to the beginning of the text. For this, we can use a small callback:model = keras.models.Sequential([ keras.layers.GRU( 128, return_sequences=True, stateful=True, # dropout=0.2, recurrent_dropout=0.2, dropout=0.2, #None<==100 time steps batch_input_shape=[batch_size, None, max_id]), keras.layers.GRU(128, return_sequences=True, stateful=True, # dropout=0.2, recurrent_dropout=0.2, dropout=0.2), keras.layers.TimeDistributed( keras.layers.Dense(max_id, activation="softmax") ) ])class ResetStateCallback( keras.callbacks.Callback): def on_epoch_begin(self, epoch, logs): self.model.reset_states()And now we can compile and fit the model (for more epochs, because each epoch is much shorter than earlier, and there is only one instance per batch):
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam") steps_per_epoch = train_size//batch_size//n_steps # n_steps=313 history = model.fit(dataset, steps_per_epoch=steps_per_epoch, epochs=50, callbacks=[ResetStateCallback()])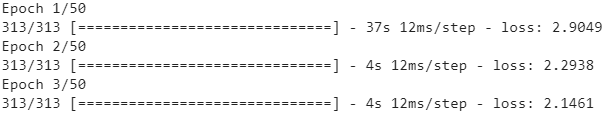
... ...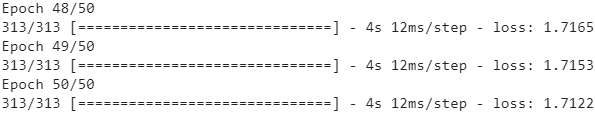
##################################
After this model is trained, it will only be possible to use it to make predictions for batches of the same size as were used during training. To avoid this restriction, create an identical stateless model, and copy the stateful model’s weights to this model.
##################################
To use the model with different batch sizes, we need to create a stateless copy. We can get rid of dropout since it is only used during training:
stateless_model = keras.models.Sequential([
keras.layers.GRU( 128, return_sequences=True, input_shape=[None, max_id]),
keras.layers.GRU( 128, return_sequences=True ),
keras.layers.TimeDistributed( keras.layers.Dense(max_id, activation="softmax") )
])To set the weights, we first need to build the model (so the weights get created):
# batch_size, time_steps, max_id
stateless_model.build( tf.TensorShape([None, None, max_id]) )
stateless_model.set_weights( model.get_weights() )
model = stateless_modeldef preprocess(texts):
X = np.array( tokenizer.texts_to_sequences(texts) )-1
return tf.one_hot(X, max_id)
def next_char( text, temperature=1):
X_new = preprocess([text]) # ':' all estimated probabilities to predect the last char
y_proba = model(X_new)[0,-1:, :] # 0: 1st sentence, -1: last char(or last time step)
rescaled_logits = tf.math.log( y_proba )/temperature
char_id = tf.random.categorical( rescaled_logits, num_samples=1 )+1
return tokenizer.sequences_to_texts( char_id.numpy() )[0]
def complete_text(text, n_chars=50, temperature=1):
for _ in range(n_chars):
text += next_char(text, temperature)
return text
tf.random.set_seed(42)
print( complete_text("t") )![]()
Now that we have built a character-level model, it’s time to look at word-level models and tackle a common natural language processing task: sentiment analysis. In the process we will learn how to handle sequences of variable lengths using masking.
Sentiment Analysis
If MNIST is the “hello world” of computer vision, then the IMDb reviews dataset is the “hello world” of natural language processing: it consists of 50,000 movie reviews in English (25,000 for training, 25,000 for testing) extracted from the famous Internet Movie Database, along with a simple binary target for each review indicating whether it is negative (0) or positive (1). Just like MNIST, the IMDb reviews dataset is popular
for good reasons: it is simple enough to be tackled on a laptop in a reasonable amount of time, but challenging enough to be fun and rewarding. Keras provides a simple function to load it:
tf.random.set_seed(42)
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data()
X_train[0][:10]![]()
Where are the movie reviews? Well, as you can see, the dataset is already preprocessed for you: X_train consists of a list of reviews, each of which is represented as a NumPy array of integers, where each integer represents a word. All punctuation was removed, and then words were converted to lowercase, split by spaces, and finally indexed by frequency (so low integers correspond to frequent words). The integers 0, 1, and 2 are special: they represent the padding token, the start-of-sequence (SSS) token, and unknown words, respectively. If you want to visualize a review, you can decode it like this:
word_index = keras.datasets.imdb.get_word_index()
# word_index
# {'fawn': 34701,
# 'tsukino': 52006,
# 'nunnery': 52007,
# ...
# }
id_to_word = { id_+3 : word for word, id_ in word_index.items() }
# id_to_word
# {34704: 'fawn',
# 52009: 'tsukino',
# 52010: 'nunnery',
# ...
# }
# use first 3 ids(0,1,2) for
# the padding token, the start-of-sequence (SSS) token, and unknown words
for id_, token in enumerate( ("", "", "") ):
id_to_word[id_] = token
# [0]: first review, [:10] first 10 words
" ".join( id_to_word[id_] for id_ in X_train[0][:10] ) ![]()
In a real project, you will have to preprocess the text yourself. You can do that using the same Tokenizer class we used earlier, but this time setting char_level=False (which is the default). When encoding words, it filters out a lot of characters, including most punctuation, line breaks, and tabs (but you can change this by setting the filters argument). Most importantly, it uses spaces to identify word boundaries. This is OK for English and many other scripts (written languages) that use spaces between words, but not all scripts use spaces this way. Chinese does not use spaces between words, Vietnamese uses spaces even within words, and languages such as German often attach multiple words together, without spaces. Even in English, spaces are not always the best way to tokenize text: think of “San Francisco” or “#ILoveDeepLearning.”
Fortunately, there are better options! The 2018 paper(Taku Kudo, “Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates,” arXiv preprint arXiv:1804.10959 (2018).) by Taku Kudo introduced an
unsupervised learning technique to tokenize and detokenize text at the subword level in a language-independent way, treating spaces like other characters. With this approach, even if your model encounters a word it has never seen before, it can still reasonably guess what it means. For example, it may never have seen the word “smartest” during training, but perhaps it learned the word “smart” and it also learned that the suffix “est” means “the most,” so it can infer the meaning of “smartest.” Google’s SentencePiece project provides an open source implementation, described in a paper(Taku Kudo and John Richardson, “SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing,” arXiv preprint arXiv:1808.06226 (2018).) by Taku Kudo and John Richardson.
Another option was proposed in an earlier paper(Rico Sennrich et al., “Neural Machine Translation of Rare Words with Subword Units,” Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics 1 (2016): 1715–1725.) by Rico Sennrich et al. that explored other ways of creating subword encodings (e.g., using byte pair encoding). Last but not least, the TensorFlow team released the TF.Text library in June 2019, which implements various tokenization strategies, including WordPiece (a variant of byte pair encoding)(Yonghui Wu et al., “Google’s Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation,” arXiv preprint arXiv:1609.08144 (2016).).
If you want to deploy your model to a mobile device or a web browser, and you don’t want to have to write a different preprocessing function every time, then you will want to handle preprocessing using only TensorFlow operations, so it can be included in the model itself. Let’s see how. First, let’s load the original IMDb reviews, as text (byte strings), using TensorFlow Datasets (introduced in Cp13 https://blog.csdn.net/Linli522362242/article/details/108039793):
import tensorflow_datasets as tfds
datasets, info = tfds.load( "imdb_reviews",
as_supervised=True,
with_info=True )
info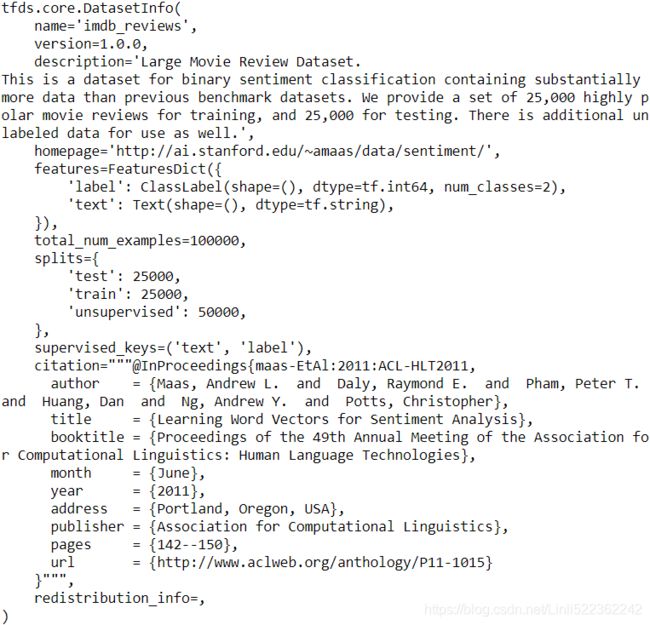
train_size = info.splits["train"].num_examples
test_size = info.splits["test"].num_examples
train_size, test_size![]()
datasets
for X_batch, y_batch in datasets["train"].batch(2).take(1):
for review, label in zip( X_batch.numpy(), y_batch.numpy() ):
print( "Review:", review.decode("utf-8")[:200], "..." )
print( "Label:", label,
"= Positive" if label else "= Negative" )
print()
Next, let’s write the preprocessing function:
- It starts by truncating the reviews, keeping only the first 300 characters of each: this will speed up training, and it won’t impact performance too much because you can generally tell whether a review is positive or not in the first sentence or two.
- Then it uses regular expressions to replace
tags with spaces
### tf.strings.regex_replace( X_batch, b"
,and to replace any characters other than letters and quotes with spaces
### tf.strings.regex_replace( X_batch, b"[^a-zA-Z']", b" " ) ###
. For example, the text "Well, I can't
" will become "Well I can't". - Finally, the preprocess() function splits the reviews by the spaces, which returns a ragged tensor, and
- it converts this ragged tensor to a dense tensor, padding all reviews with the padding token "
" so that they all have the same length.
# regex
# https://www.runoob.com/regexp/regexp-syntax.html
# https://blog.csdn.net/Linli522362242/article/details/108108665
def preprocess( X_batch, y_batch ):
X_batch = tf.strings.substr( X_batch, 0, 300 )
X_batch = tf.strings.regex_replace( X_batch,
b"",#pattern e.g.:
b" " )
X_batch = tf.strings.regex_replace( X_batch,
b"[^a-zA-Z']",
b" " )
X_batch = tf.strings.split( X_batch ) # split words on spaces
# rt = tf.ragged.constant([[9, 8, 7], [], [6, 5], [4]])
# print(rt.to_tensor(default_value=0))
# tf.Tensor(
# [[9 8 7]
# [0 0 0]
# [6 5 0]
# [4 0 0]], shape=(4, 3), dtype=int32)
return X_batch.to_tensor( default_value = b"" ), y_batch
preprocess(X_batch, y_batch)  <==
<==
Next, we need to construct the vocabulary. This requires going through the whole training set once, applying our preprocess() function, and using a Counter to count the number of occurrences of each word:
from collections import Counter
# https://pymotw.com/2/collections/counter.html
vocabulary = Counter()
for X_batch, y_batch in datasets["train"].batch(32).map(preprocess):
for review in X_batch:
vocabulary.update( list(review.numpy()) )Let’s look at the three most common words:
vocabulary.most_common()[:3]![]()
len(vocabulary)![]()
Great! We probably don’t need our model to know all the words in the dictionary to get good performance, though, so let’s truncate the vocabulary, keeping only the 10,000 most common words:
vocab_size = 10000
truncated_vocabulary = [
word for word, count in vocabulary.most_common()[:vocab_size]
]
# truncated_vocabulary
# [b'',
# b'the',
# b'a',
# ...
# ] word_to_id = { word: index
for index, word in enumerate(truncated_vocabulary)
}
# word_to_id
# {b'': 0,
# b'the': 1,
# b'a': 2,
# ...
# }
# b"This movie was faaaaaantastic".split()
# [b'This', b'movie', b'was', b'faaaaaantastic']
for word in b"This movie was faaaaaantastic".split():
print( word_to_id.get(word) or vocab_size )  <== b'faaaaaantastic' is not in word_to_id, so returns vocab_size
<== b'faaaaaantastic' is not in word_to_id, so returns vocab_size
Now we need to add a preprocessing step to replace each word with its ID (i.e., its index in the vocabulary). Just like we did in Cp13, we will create a lookup table for this, using 1,000 out-of-vocabulary (oov) buckets:https://blog.csdn.net/Linli522362242/article/details/107933572
words = tf.constant( truncated_vocabulary )
# len(truncated_vocabulary)==vocab_size == 10000
ids = tf.range( len(truncated_vocabulary), dtype=tf.int64 )
# create an initializer for the lookup table
vocab_init = tf.lookup.KeyValueTensorInitializer( words, ids )
# specifying the number of out-of-vocabulary
# (oov, reserved for tokens that do not exist in the set) buckets.
# If we look up a category (or token) that does not exist in the vocabulary
# (set), the lookup table will compute a hash of this category
# and use it to assign the unknown category to one of the oov buckets.
# Their indices start after the known categories,
num_oov_buckets = 1000
table = tf.lookup.StaticVocabularyTable( vocab_init, num_oov_buckets )We can then use this table to look up the IDs of a few words:
table.lookup(
tf.constant([ b"This movie was faaaaaantastic".split() ])
)![]()
Note that the words “this,” “movie,” and “was” were found in the table, so their IDs are lower than 10,000, while the word “faaaaaantastic” was not found, so it was mapped to one of the oov buckets, with an ID greater than or equal to 10,000.
#############################
TF Transform (introduced in Cp13 https://blog.csdn.net/Linli522362242/article/details/107933572) provides some useful functions to handle such vocabularies. For example, check out the tft.compute_and_apply_vocabulary() function: it will go through the dataset to find all distinct words and build the vocabulary, and it will generate the TF operations required to encode each word using this vocabulary.
But what if you could define your preprocessing operations just once? This is what TF Transform was designed for. It is part of TensorFlow Extended (TFX), an end-to-end platform for productionizing TensorFlow models. First, to use a TFX component such as TF Transform, you must install it; it does not come bundled with TensorFlow. You then define your preprocessing function just once (in Python), by using TF Transform functions for scaling, bucketizing, and more. You can also use any Tensor‐Flow operation you need. Here is what this preprocessing function might look like if we just had two features:
TensorFlow Transform
TensorFlow Transform is a library for preprocessing data with TensorFlow. tf.Transform is useful for data that requires a full-pass, such as:
- Normalize an input value by mean and standard deviation.
- Convert strings to integers by generating a vocabulary over all input values.
- Convert floats to integers by assigning them to buckets based on the observed data distribution.
TensorFlow has built-in support for manipulations on a single example or a batch of examples. tf.Transform extends these capabilities to support full-passes over the example data.
The output of tf.Transform is exported as a TensorFlow graph to use for training and serving. Using the same graph for both training and serving can prevent skew since the same transformations are applied in both stages.
For an introduction to tf.Transform, see the tf.Transform section of the TFX Dev Summit talk on TFX (link https://www.youtube.com/watch?v=vdG7uKQ2eKk&feature=youtu.be&t=199).
tft.scale_to_z_score
Returns a standardized column with mean 0 and variance 1.
tft.scale_to_z_score(
x, elementwise=False, name=None, output_dtype=None
)tft.compute_and_apply_vocabulary
Generates a vocabulary for x and maps it to an integer with this vocab.
Returns: A Tensor or SparseTensor where each string value is mapped to an integer.
tft.compute_and_apply_vocabulary(
x, default_value=-1, top_k=None, frequency_threshold=None, num_oov_buckets=0,
vocab_filename=None, weights=None, labels=None, use_adjusted_mutual_info=False,
min_diff_from_avg=0.0, coverage_top_k=None, coverage_frequency_threshold=None,
key_fn=None, fingerprint_shuffle=False, name=None
)https://cloud.google.com/solutions/machine-learning/data-preprocessing-for-ml-with-tf-transform-pt2
#############################
Now we are ready to create the final training set. We batch the reviews, then convert them to short sequences of words using the preprocess() function, then encode these words using a simple encode_words() function that uses the table we just built, and finally prefetch the next batch:
def encode_words( X_batch, y_batch ):
return table.lookup(X_batch), y_batch
train_set = datasets["train"].repeat().batch(32).map( preprocess )
train_set = train_set.map( encode_words ).prefetch(1)
for X_batch, y_batch in train_set.take(1): #take 1 batch and batch_size=32
print(X_batch)
print(y_batch) use One-Hot Vector's max length=60 in current batch
use One-Hot Vector's max length=60 in current batch
At last we can create the model and train it: https://blog.csdn.net/Linli522362242/article/details/107933572
https://blog.csdn.net/Linli522362242/article/details/107933572
mask_zero : Boolean, whether or not the input value 0 is a special "padding" value that should be masked out. This is useful when using recurrent layers which may take variable length input. If this is True, then all subsequent layers in the model need to support masking or an exception will be raised. If mask_zero is set to True, as a consequence, index 0 cannot be used in the vocabulary (input_dim should equal size of vocabulary + 1)
# the inputs' shape : [batch size, time steps_or tokens]
embed_size = 128
# vocab_size = 10000
# num_oov_buckets = 1000
# since mask_zero=True, so acutal num_oov_buckets-1=9999
model = keras.models.Sequential([
keras.layers.Embedding( input_dim = vocab_size+num_oov_buckets,
output_dim = embed_size,
mask_zero=True,
input_shape=[None] ),
#output shape from Embedding: [batch size, time steps, embedding size].
keras.layers.GRU(128, return_sequences=True),
keras.layers.GRU(128),#=False : return the output of the last time step
keras.layers.Dense(1, activation="sigmoid") # the estimated probability
]) # that the review expresses a positive sentiment regarding the movie
model.compile( loss="binary_crossentropy",
optimizer="adam", metrics=["accuracy"] )
history = model.fit(train_set, steps_per_epoch = train_size//32, epochs=5)The first layer is an Embedding layer, which will convert word IDs into embeddings (introduced in Chapter 13). The embedding matrix needs to have one row per word ID (vocab_size + num_oov_buckets) and one column per embedding dimension (this example uses 128 dimensions, but this is a hyperparameter you could tune). Whereas the inputs of the model will be 2D tensors of shape [batch size, time steps], the output of the Embedding layer will be a 3D tensor of shape [batch size, time steps, embedding size].
The rest of the model is fairly straightforward: it is composed of two GRU layers, with the second one returning only the output of the last time step. The output layer is just a single neuron using the sigmoid activation function to output the estimated probability that the review expresses a positive sentiment regarding the movie. We then compile the modelquite simply, and we fit it on the dataset we prepared earlier, for a few epochs.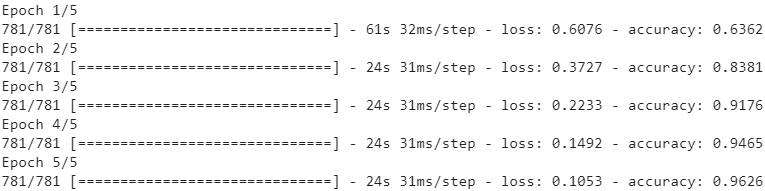
Masking
https://blog.csdn.net/Linli522362242/article/details/115518150