【研一小白论文精读】《Big Self-Supervised Models are Strong Semi-Supervised Learners》
【研一小白论文精读】
研一已经开学了,距离上一次自己写博客也有一段时间了,上一次写的博客我自己看简直又臭又长,这次是第二次,也不知道能不能做出一些改变。首先声明,我自己仍然是一个学术小白,理论基础极差,代码能力也几乎没有,更没有任何部署项目代码的能力,英语水平更是拉跨,本科毕业前六级飘过考研英语二70,面对这种纯英文的专业学术论文更是无从下手。那有人就要问了,你这么捞为啥上来就要读英语论文呢?我的导师在课上要求我们将普通论文摘要两三百词扩写到800词以上,这篇论文就是他为学生们提供的备选论文之一,既然是扩写肯定不能乱扩,而是要在通读全文之后有逻辑地扩写、所以一是为了完成作业,二是为了学习毕竟万事开头难,不硬着头皮迈出第一步怎么能进步呢?好了废话不多说进入正题。
论文题目
我这学术生涯的第一篇论文,论文题目是《Big Self-Supervised Models are Strong Semi-Supervised Learners》,字面理解是《大型自监督学习模型是强健的半监督学习者》。光看这题目我就不懂了,之前我知道监督学习和非监督学习,自监督和半监督的概念我还没接触过。所以先把概念打通。
自监督学习:属于非监督学习的一种方法而已,目的是在没有人工标注的条件下也能高效的训练网络。区别就是通过没有标签的数据自己挖掘出来标签也就是标签来源于数据自身。没有loss function的话,模型无法进行学习,所以必须定义一个objective function,通过Pretext task也叫surrogate task获取伪标签。自监督的核心问题是如何产生伪标签(Pseudo label),而这种伪标签的产生是不涉及人工的。
Pretext task:直接联想到自监督,也叫代理任务,自己对data simple的理解来定义task,网络能够解决这个task,Pretext可以理解为是一种为达到特定训练任务而设计的间接任务,说白了就是指在深度学习里就是避免了人工标记样本,实现无监督的语义提取。Pretext task进一步可以理解为对目标任务有帮助的辅助任务,这种任务在这些年大多都是采用自监督的学习方法(避免人工标注标签)。Pretext task的本质上可以是一种迁移学习,让网络先在其他任务上训练,使模型学到一定的语义知识,再用模型执行目标任务。这里提到的其他任务就是pretext task,也可以称之为采用自监督学习方法的预训练任务。
半监督学习(SSL):利用大量没有标签的数据和少量有标签的数据进行监督学习。少量有标签数据+大量无标签数据的学习问题是机器学习中存在已有的问题。其中一种知名的方法是半监督学习,它包含无监督或自监督训练,后接有监督微调。
自监督学习的核心点在于标签自动产生的方法:基于上下文在bert中有用到;基于时序如视频对话等;最后也是最强的基于对比学习,通过两个样本的相似程度也即两个样本的距离,从而计算损失。效果一般来说主要是通过Pretrain-Fine-tune的模式(预训练和微调)来判断自监督模型的好坏,至于为什么通过这种方法,我也不知道,后面再说。
伪标签学习(Pseudo-Labelling):伪标签的定义来自于半监督学习,半监督学习的核心思想是通过借助无标签的数据来提升有监督过程中的模型性能,伪标签技术就是利用在已标注数据所训练的模型在未标注的数据上进行预测,根据预测结果对样本进行筛选,再次输入模型中进行训练的一个过程。
semantic information:语义信息。
先验分布是你瞎猜参数服从啥分布;后验分布是你学习经验后有根据地瞎猜参数服从啥分布;似然估计是你猜参数是多少,才最能解释某些实验结果。
DIM(Deep InfoMax):核心思想就是主要思想是一张图的全局特征Y和它的局部特征应该高度相关,和另一张图的局部特征应该不相关。通过图像中的局部特征来构造对比学习任务。具体来说,构造二分类任务,要求模型判别全局特征和局部特征是否来自于同一幅图像。
anchor:全局特征为锚点,一般代指对比学习中的原图。
正负样本:正样本为来自同一张图像的局部特征,负样本为来自不同图像的局部特征。白话理解:在众多数据原图中,被数据增强的图片被当作是正样本,其余图片被当作是负样本。
强化学习:强化学习也是使用未标记的数据,但是可以通过一些方法知道你是离正确答案越来越近还是越来越远(奖惩函数)。可以把奖惩函数看作正确答案的一个延迟、稀疏的形式。可以得到一个延迟的反馈,并且只有提示你是离答案越来越近还是越来越远。
搞清楚概念后,再来理解一下题目。大型的自监督网络可以更好地进行半监督学习。
自监督学习相当于是半监督学习的一种方法,而对比学习又属于自监督学习方法中的 一种,当前自监督学习可以被大致分为两类:
Generative Methods(生成式方法)这类方法以自编码器为代表,主要关注pixel label的loss。举例来说,在自编码器中对数据样本编码成特征再解码重构,这里认为重构的效果比较好则说明模型学到了比较好的特征表达,而重构的效果通过pixel label的loss来衡量。
Contrastive Methods(对比式方法)这类方法则是通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。Contrastive Methods主要的难点在于如何构造正负样本。
对比学习(Contrastive Learning):
互信息:只有知道了我们需要加大什么互信息,才能更好地设计正负样本,从而利用对比学习来设计任务提高。对比学习只是加强互信息的一种方式而已。
互信息可以理解为两个随机变量的相关程度,也可以理解为两个随机变量共享的信息(知道随机变量X对随机变量Y的不确定性的减少程度,或者知道Y后X的不确定性的减少程度,用I(X,Y)表示),也是是对特征工程中特征的一个降维。
预测相对位置(PRP):学习局部成分之间的相对位置。 全局上下文是预测这些关系的隐含要求(例如了解大象的长相对于预测其头尾之间的相对位置至关重要)。
最大化互信息(MI):学习局部和全局内容之间关系的显式信息。 局部成分之间的相对位置将被忽略。
首先对比学习属于一种无监督的图像或者文本的表示学习,对比学习的核心在于如何构建正负样本集合
首先对比学习在图像领域的代表就是MoCo和SimCLR。所以对比学习可以理解为CV领域中的Bert。
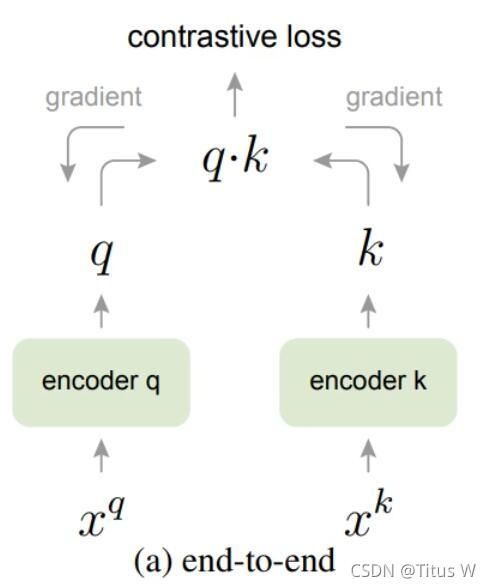
深度神经网络有着强大的表征学习能力,一张输入图片经过层层变换得到一个特征向量,如果监督学习,基于特征向量的输出可以和特征进行比对产生loss。如果是非监督学习,没有label,该如何让构建损失函数?该如何判断一个好的表征?Contrastive Learning给出的答案很简单,同类图像的特征向量应该在特征空间也是相似的,不同类的特征向量则应该越远越好,这就是对比学习的概念。但是没有label还是不知道那些实例属于同一个类别,这样我们可以把每个实实例当作同一类,用数据增广的方法创造出该类别的其他实例。
对比学习的过程可以被理解为一个查字典的过程,输入图像为query,用于对比的是字典中的K(log-scale表示负样本的数量),用softmax可以i得到两张图片相似的概率,损失函数基于对数似然损失函数构建,此时原图和变形之后的图片特征相似度越高,不同的图片特征相似度越低,整体的loss就越低,就越接近理想模型。
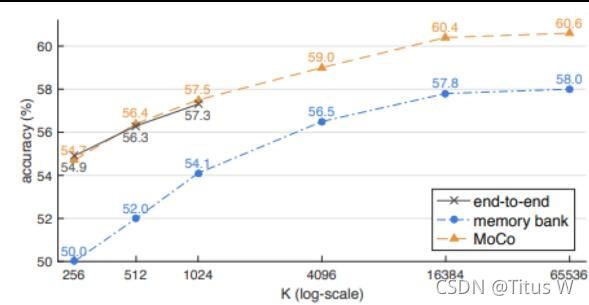
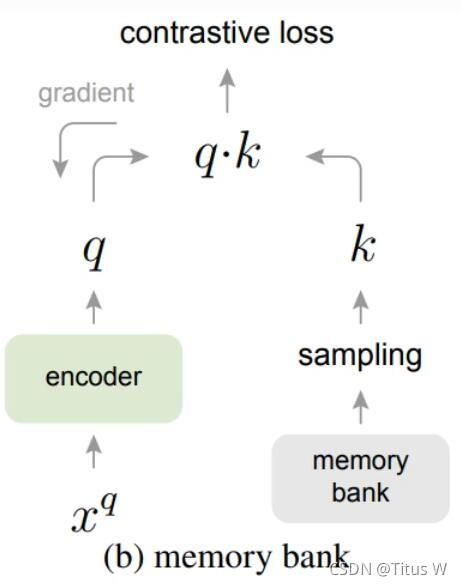
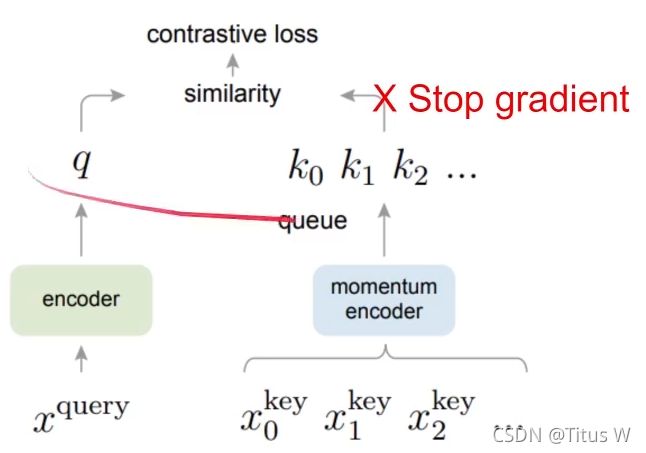
可是每次计算loss都会产生梯度回传,所以用于比对的字典大小限制于用于训练的GPU内存,对于图片这样的高维数据,由于字典不够大,可能达不到训练效果。用于解决字典大小限制的问题又由memory bank解决,这个被称为记忆银行的空间,储存了所有K,他们的初始值是随机归一化的,然后再每次经过查询后query的值就会更新到相应的key上面,由于不需要梯度回传,所以memory bank的大小是不受限于显存的,这样用来对比的负样本就足够多了,但是又出现了一个新的问题那就是记忆银行中存储的编码实际来源于该epoch中每一个step,而这个过程中编码器是不断被更新参数的,这样就破坏了该字典中K的一致性。而MoCo的作者就是想让字典足够大,同时又保证了字典的一致性。MoCo的解决方案是不去更新K,而是更新每个minibatch中ley编码器的参数,这样出来的K就是来自于同一个参数了。虽然每个mini-batch产生的key是来自同一组参数,可是如果迭代过快的话,batch和batch之间可能又变得不一致了。实验结果表明要选一个大的惯量系数,让K的编码器参数更新的比较缓慢,才能保证队列中k的一致性。(还有一个轮换批量正则化)
最后总结一下:
在MoCo提出的时候,现在手头有两种contrastive learning的手段:
SimCLR
再了解升级版SimCLR v2之前,我们很有必要先了解一下SimCLR。通过论文我们知道,这是典型的用contrastive learning来进行Self-Supervised learing的一种方法。

和BYOL一样都非常亲切地,一个图像x进来,采用不同的图像增强策略,产生两种样本,然后送到encoder里面再送到projecter里面,得到vectorZ,然后传入loss中。把同一张图像产生的Z尽量靠近,不同图像产生的Z远离。对于同一个样本的两个向量,我们希望在向量空间里的夹角更小,对于不同空间向量里希望家教更大。所以本文的主要算法还是n个样本通过两路encoder和projection就可以得到2n个样本,然后对这2n个样本两两之间构建loss,把得到的loss值求平均再更新一下encoder和projection就可以了。值得注意的是,SimCLR这个模型对batch-size是非常敏感的,如果batch-size太小,那么每次训练的时候就没有足够的样本进行学习,所以增加batch-size对模型性能的提升是很有帮助的。
Abstract
本文的摘要内容极为清晰:
1.问题:在半监督学习当中,如何充分利用没有标签的数据这个问题一直存在。本篇论文证明了通过对大量没有标签的数据进行无监督训练再进行有监督的微调,虽然没有标签的数据训练似乎与训练任务没有关系,但是效果却出乎意料地好,尤其争对大型网络效果更好。
2.方法:用非监督学习的方法先训练一个及其庞大复杂的模型,再用有监督的方法进行一个fine-turn,就可以得到一个很强的分类器。再把这个大的网络迁移到小的网络上,这样就能在没有标签数据的情况下节约成本。具体分为三个步骤:首先使用ResNet(深度残差网络)作为backbone(特征提取能力极强的主干网络)搭建大型的SimCLRv2,进行无监督的预训练。然后在少量有标注的数据上进行有监督的finetune。最后再通过未标注的数据采用蒸馏的方式对模型进行压缩并迁移到特定任务上。这里需要解释几个名词:(数据集的蒸馏:将大型训练数据集中的知识提炼成小数据)(模型的蒸馏:模型蒸馏的目的是将复杂模型的知识提炼成到简单的模型。)
3.结果:我们发现,标签越少,这种方法(对未标记数据的任务不可知使用,也就是说通过这种方式学习到的表达方式不会存在对特定分类任务的倾向性)从更大的网络中获益越多。在微调之后,通过第二次使用未标记的示例(但以特定于任务的方式),可以进一步改进大网络,并将其提取到更小的网络,而分类精度几乎没有损失。
4.结论:说白了就是换了一个更复杂的模型就有了更好的表现。该程序仅使用1%的标签就达到73.9%的ImageNettop-1准确性(≤使用Resnet-50,每类13张标签图像),标签效率比以前的最先进技术提高了10倍。对于10%的标签,使用我们的方法训练的ResNet-50达到77.5%的top-1准确率,优于所有标签的标准监督训练。
Introduction
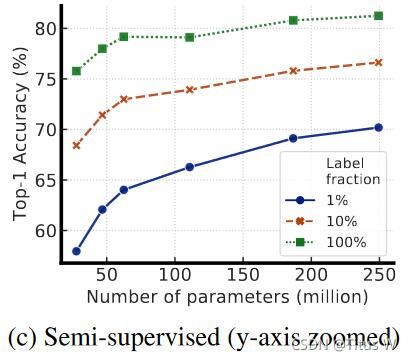
首先映入眼帘的是三张图片:

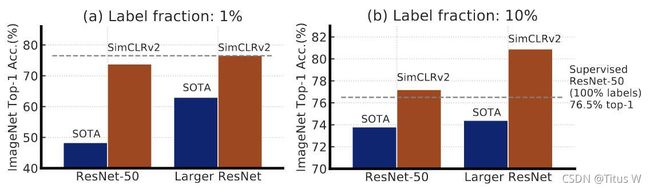
随着应用大规模的模型,一方面是提升精度,另一方面也却显得有点笨重。后面还是通过熟悉的蒸馏操作来将Large ResNet迁移到较小的ResNet-50中,使用1%和10%的标签也能达到73.95和77.5%的top1准确率,后者已然“超越”了76.5%的supervised learning。文章中可能有些地方没看明白,但是不妨碍其传递的核心思想,那就是半监督的潜力是非常巨大的。
组合上述发现得到了ImageNet上的半监督学习的SOTA性能,见上图2.SimCLRv2取得了79.8%的top-1精度,以4.3%绝对优势超过了此前SOTA方法。当仅仅采用1%和10%有标签数据进行微调并蒸馏到相同模型后,模型的指标分别为76.6%和80.9%,分别以21.6%和8.7%的绝对优势超越了已有SOTA方法。通过蒸馏,上述性能改进可以迁移到更小的ResNet50网络并取得了73.9%和77.5%的top1精度。相比较而言,ImageNet上有监督训练得到的ResNet50的精度为76.6%top精度。
Methodology
首先有三个步骤,首先先笼统的概括一下:受启发于无标检数据的成功学习,所提半监督学习方案以任务未知和任务已知两种方式利用无标签数据。首先,采用任务未知方式利用无标签数据进行无监督预训练以学习广义视觉特征表达;然后;所学习的广义特征表达通过有监督微调进行方式;最后;采用任务已知方式利用无标签数据进行模型蒸馏。为达到该目的,作者提出在无标签数据集上训练一个学生模型,而标签则来自微调后的老师模型。核心步骤有三步:pretrain,fine-tune,distill(自监督预训练,有监督微调,知识蒸馏).见下图。
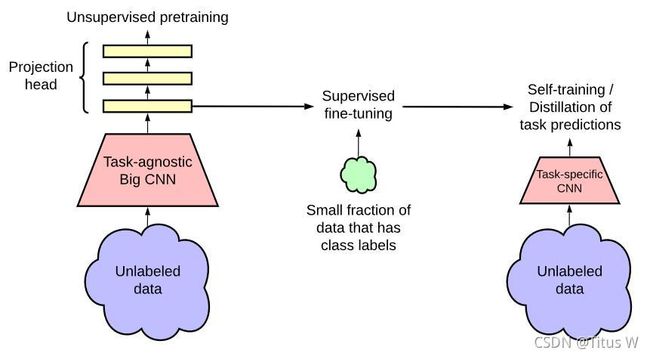
pretrain
左边整个部分是我们非常熟悉的SimCLR作为backbone,首先没有标记的样本放入大的且与任务无关的CNN当中,这个CNN就是用来做pretrain的,接着作者又加了几层hiden layers在Projection MLP里面,然后使用contrastive loss,接着做非监督学习得到预训练模型。
关于自监督预训练的损失函数和第一代其实没有什么变化。
为更好的从无标签数据上学习广义视觉特征表达,作者对SimCLR进行了改进。SimCLR通过最大化不同增广数据之前的一致性进行学习。
给定输入图像 x i x_{i} xi,它将被增广两次,构建关于同一数据两次增广[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传 x 2 k − 1 x_{2 k-1} x2k−1 x 2 k x_{2 k} x2k,这两个图像通过编码网络 f ( ⋅ ) f(\cdot) f(⋅)进行编码得到更易特征表达 h 2 k − 1 h_{2 k-1} h2k−1, h 2 k − 1 h_{2 k-1} h2k−1。这些特征表达然后经过非线性变换网络 g ( ⋅ ) g(\cdot) g(⋅)进行变换得到 z 2 k − 1 z_{2 k-1} z2k−1, z 2 k − 1 z_{2 k-1} z2k−1并用于对比学习。对比损失定义如下:
l i , j N T − X e n t = − log exp ( sim ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp ( sim ( z i , z k ) / τ ) l_{i, j}^{N T-X_{e n t}}=-\log \frac{\exp \left(\operatorname{sim}\left(z_{i}, z_{j}\right) / \tau\right)}{\sum_{k=1}^{2 N} 1_{[k \neq i]} \exp \left(\operatorname{sim}\left(z_{i}, z_{k}\right) / \tau\right)} li,jNT−Xent=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中 sim ( ⋅ , ⋅ ) \operatorname{sim}(\cdot, \cdot) sim(⋅,⋅)表示余弦相似性, τ \tau τ表示温标参数。这个loss并没有做更换,还和原来的SimCLR一样。
fine-tune
得到预训练模型之后呢,此时就要加入标签,针对图像识别任务做一个标准的监督学习,做fine-tuning。此时就得到了一个很强的分类器也就是teacher network。然后找一个小一点的student network但是专门做图像识别的迁移过去,具体来说就是这个teacher network在这unlabeled data上生成Pseudo-Label(伪标签),然后扔给studdent network。经过微调后,大模型可以进一步得以改善并蒸馏更多信息到小模型中(注:蒸馏阶段会对无标签数据进行二次利用,此时该数据将以任务已知方式进行应用)。知识蒸馏使用什么样的loss呢?
关于损失函数的公式这里真的是啥也不懂。
微调是将任务未知与训练模型迁移到任务已知中常用技巧。在SimCLR的微调阶段,非线性网络 f ( ⋅ ) f(\cdot) f(⋅)会被直接完整丢弃而仅仅保留编码器部分 g ( ) g() g()进行微调。而在SimCLRv2中则是集成非线性网络的一部分(第一层)进行微调。
作者精心构建了一个三层projection head g ( h i ) = W ( 3 ) ( σ ( W ( 2 ) σ ( W ( 1 ) h i ) ) ) g\left(h_{i}\right)=W^{(3)}\left(\sigma\left(W^{(2)} \sigma\left(W^{(1)} h_{i}\right)\right)\right) g(hi)=W(3)(σ(W(2)σ(W(1)hi))),其中 σ \sigma σ表示ReLU激活函数,为简单起见这里忽略了偏置项。在微调阶段,SimCLR采用 f task ( x i ) = W task f ( x i ) f^{\text {task }}\left(x_{i}\right)=W^{\text {task }} f\left(x_{i}\right) ftask (xi)=Wtask f(xi)进行微调;而SimCLRv2则是采用 f task = W t a s k σ ( W ( 1 ) f ( x i ) ) f^{\text {task }}=W^{t a s k} \sigma\left(W^{(1)} f\left(x_{i}\right)\right) ftask =Wtaskσ(W(1)f(xi))进行微调。这一点点的改进是不是看上去非常简单?能想到并去做才是难的!
distill
为进一步改善网络在特定任务上的性能,作者提出直接采用无标签数据进行特定任务学习。那么标签从何而来呢?伪标签咯。将签署微调模型作为老师模型并给出无标签数据对应的伪标签用于蒸馏学生模型。蒸馏阶段采用KL散度就可以了,有没有觉得很简单,方法都是现成的。
L distill = − ∑ x i ∈ D [ ∑ y P T ( y ∣ x i ; τ ) log P S ( y ∣ x i ; τ ) ] \mathcal{L}^{\text {distill }}=-\sum_{\boldsymbol{x}_{i} \in \mathcal{D}}\left[\sum_{y} P^{T}\left(y \mid \boldsymbol{x}_{i} ; \tau\right) \log P^{S}\left(y \mid \boldsymbol{x}_{i} ; \tau\right)\right] Ldistill =−xi∈D∑[y∑PT(y∣xi;τ)logPS(y∣xi;τ)]
where P ( y ∣ x i ) = exp ( f task ( x i ) [ y ] / τ ) / ∑ y ′ exp ( f t a s k ( x i ) [ y ′ ] / τ ) \text { where } P\left(y \mid \boldsymbol{x}_{i}\right)=\exp \left(f^{\operatorname{task}}\left(\boldsymbol{x}_{i}\right)[y] / \tau\right) / \sum_{y^{\prime}} \exp \left(f^{\mathrm{task}}\left(\boldsymbol{x}_{i}\right)\left[y^{\prime}\right] / \tau\right) where P(y∣xi)=exp(ftask(xi)[y]/τ)/y′∑exp(ftask(xi)[y′]/τ)
这里不仅可以使用teacher network产生的label,也可以产生更大的loss。
L = − ( 1 − α ) ∑ ( x i , y i ) ∈ D L [ log P S ( y i ∣ x i ) ] − α ∑ x i ∈ D [ ∑ y P T ( y ∣ x i ; τ ) log P S ( y ∣ x i ; τ ) ] \mathcal{L}=-(1-\alpha) \sum_{\left(\boldsymbol{x}_{i}, y_{i}\right) \in \mathcal{D}^{L}}\left[\log P^{S}\left(y_{i} \mid \boldsymbol{x}_{i}\right)\right]-\alpha \sum_{\boldsymbol{x}_{i} \in \mathcal{D}}\left[\sum_{y} P^{T}\left(y \mid \boldsymbol{x}_{i} ; \tau\right) \log P^{S}\left(y \mid \boldsymbol{x}_{i} ; \tau\right)\right] L=−(1−α)(xi,yi)∈DL∑[logPS(yi∣xi)]−αxi∈D∑[y∑PT(y∣xi;τ)logPS(y∣xi;τ)]
模型的任务已知预测属性可以进一步改善并蒸馏到一个更小的网络中。为此,作者对无标签数据进行了二次利用以促使学生网络尽可能的模拟老师网络的标签预测性能。所提方法的蒸馏阶段采用伪标签方式且不会造成额外的更多复杂度。
Results
沿着无监督学习的设置方式,作者在ImageNet数据集上进行了实验分析。注:作者采用的优化器是LARS。
在预训练阶段,batch=4096,硬件平台128CloudTPU,同时采用了全局BatchNorm,训练了800epoch。学习率在前5%epoch线性提升到6.4然后按照余弦方式衰减,权值衰减因子为0.0001。非线性网路 g ( ⋅ ) g(\cdot) g(⋅)为三层感知器。记忆buffer设置为64K,同时采用了EMA技术。增广技术类似于SimCLR,即随机裁剪、颜色都懂以及高斯模糊。
在微调阶段,作者对非线性网络的第一层进行了微调。采用了全局BatchNorm,但移除了权值衰减、学习率warmup,而是采用了更小的学习率0.16和0.064用于标准ResNet和更大ResNet。batch=1024,在1%数据上微调60epoch,在10%数据上微调30epoch。
在蒸馏阶段,作者提出仅仅采用无标签数据进行蒸馏。作者采用了两种类型的蒸馏:自蒸馏与Big-to-small蒸馏。采用了与预训练相同的学习率机制、权值衰减以及batch。合计训练400epoch,此时仅仅采用随机裁剪、随机镜像数据增广。
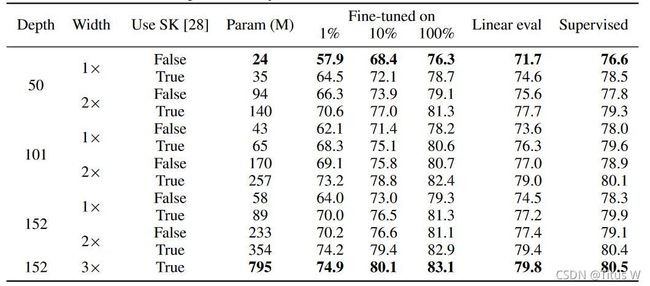
下表给出了自监督、有监督在不同模型大小下的性能评估。可以看到:提升模型宽度、深度以及添加SK(selective kernel),还有使用多少数量的label用来做fine-turn,可以取得更好的性能。

为了进一步证明该观点(模型越大,使用label的效率就越大),又通过三张图片。
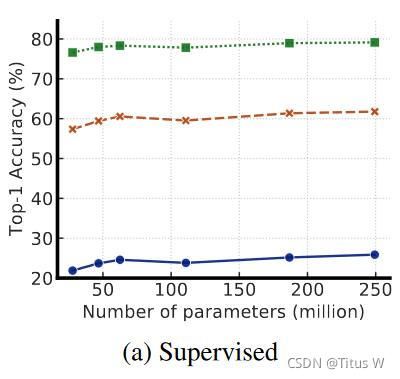
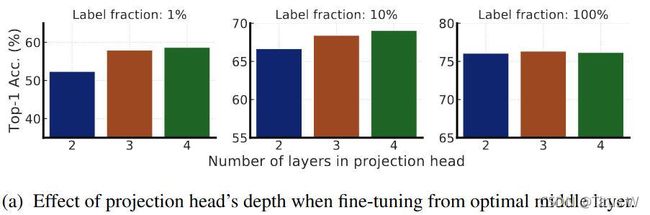
值得一提的是,作者进一步证实了SimCLR中卷积后的非线性变换(即projection head)的重要性。更深的projection head不仅可以提升特征表达质量,同时可以提升半监督学习的性能。原来的SimCLR是只有一层hiden layer的,通过对比hiden layer的层数有2层,3层,4层。上图明显能看出来随着隐含层的增加,而且在使用的标签比较少的时候性能是有提升的。
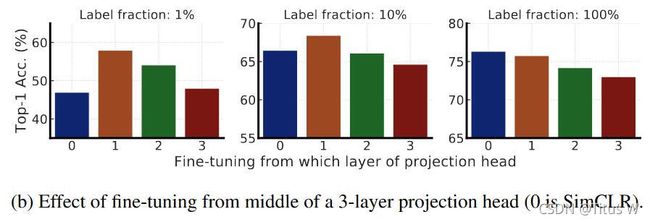
同时作者继续研究应该从那一层fineturn比较好呢?
上图看出,一开始从第一次fineturn甚至比直接从represebtation上fineturn效果还要好。但是如果使用的样本很多,最后还是发现从 represetation上直接fineturn效果比较好。有意思的发现。
那么除了前面的无监督学习和有监督微调之外,还有Distillation(蒸馏)的环节。作者发现尤其是使用没有标签的数据可以改善半监督学习的效果。

根据上表,这里使用了不同的配置:当只使用label并且label比较少的情况下,效果是不太好的;但是如果使用了distillation loss效果有了提升,但是因为几级局限在了这些有label的数据上,这些数据也比较少,所以提升也不是特别明显;但是如果连没有标签的数据也蒸馏一下子,那就极大的扩充了数据量,我们看到准确率有了很大的提升;但是如果只让teacher network去教student network,而不使用任何的label,从结果上来看性能的下降也不是特别明显,说明distillation还是起到了最主要的作用。


最后呢作者汇报了一下同行的工作,汇报了一些方法,
总结
这篇文章主要介绍的就是SimCLRv2,相比于原来有了更大的模型,但如果仅仅是这样的话肯定是不够的,所以又加上了知识蒸馏的部分。也就是在非监督学习下训练一个很大的模型,然后对这个模型按照有监督的方法进行fineturn,fineturn出来之后就得到一个很强的分类器。用这个强的分类器作为teacher,迁到一个尺寸相对小的网络。这样我们就可以用低成本,把大量没有标记的数据,还有训练好大的网络的知识灌到小的网络。