目标检测综述
目标检测综述
- 摘要
- 背景
- 目标检测算法发展脉络
-
- 传统目标检测算法
-
- Viola Jones Detector
- HOG Detector
- DPM Detector
- Anchor-Based的Two-stage目标检测算法
-
- RCNN
- SPPnet
- Fast RCNN
- Faster RCNN
-
- Anchor box设计
- FPN
-
- FPN演进
- Cascade RCNN
- Anchor-based中的one-stage目标检测算法
-
- Yolo系列算法
- SSD算法
-
- SSD Anchor设计
- Loss function
- RetinaNet
- 目标检测之Anchor
- Anchor-Free中的目标检测算法
-
- CornetNet
- CenterNet
- FSAF
- FCOS
- SAPD
- 目标检测常用数据集及评价指标
-
- 常用数据集
-
- 四大公共数据集
- 其他数据集
- 常用评价指标
- 目标检测任务的六大难点与挑战
- 目标检测的五大技术及其演变
-
- Multi-Scale检测技术的演变
- 边框回归技术的演变
- 上下文信息提取技术的演变
- 非极大值抑制技术的演变
- 难分负样本挖掘技术的演变
- 目标检测模型的加速技术
-
- 轻量化网络的设计
- 模型压缩与量化
- 数值加速技术
- 提高目标检测模型精度的五大技术
-
- 特征提取网络
- 高效的特征融合
- 目标定位的改进
- 语义分割促进目标检测
- 目标检测的五大应用场景
- 目标检测未来发展的七大趋势
- 参考
摘要
本篇博客主要参考综述:目标检测二十年(2001-2021),在此基础上增加一些内容以及删减部分的内容。总体的目录架构不变。本博客旨在为自己构建一个完整的目标检测知识体系架构,同时了解目标检测相关的技术栈及其未来的发展趋势。本博客有什么不恰当的地方,恳请各位提出宝贵的意见。
背景
计算机视觉问题主要分为四个:图像分类、目标检测、语义分割以及实例分割。作为计算机视觉的基本问题之一,目标检测构成了许多其他视觉任务的基础,例如实例分割,图像标注和目标跟踪等;从检测应用的角度看:行人检测、面部检测、文本检测、交通标注与红绿灯检测,遥感目标检测统称为目标检测的五大应用。
目标检测算法发展脉络

传统目标检测算法
传统的目标检测算法主要基于手工提取特征。传统的检测算法流程如下:
- 选取感兴趣的区域(ROI),选取可能包含物体的区域
- 对可能包含物体的区域进行特征提取
- 对提取的特征进行检测分类
传统的检测算法具有以下缺点:
- 识别效果不够好,准确率不高
- 计算量较大,运算速度慢
- 可能产生多个正确识别的结果
Viola Jones Detector
VJ检测器采用滑动窗口的方式以检查目标是否存在窗口之中,该检测器看起来似乎很简单稳定,但由于计算量庞大导致时间复杂度极高,为了解决该项问题, V J VJ VJ检测器通过合并三项技术极大提高了检测速度,这三项技术分别是:1)特征的快速计算方法-积分图,2)有效的分类器学习方法-AdaBoost,以及3)高效的分类策略-级联结构的设计。
HOG Detector
HOG Histograms of oriented gradients for human detection检测器于2005年提出,是当时尺度特征不变性(Scale Invariant Feature Transform)和形状上下文(Shape Contexts)的重要改进,为了平衡特征不变性(包括平移,尺度,光照等)和非线性(区分不同的对象类别), H O G HOG HOG通过在均匀间隔单元的密集网格上计算重叠的局部对比度归一化来提高检测准确性,因此 H O G HOG HOG检测器是基于本地像素块进行特征直方图提取的一种算法,它在目标局部变形和受光照影响下都有很好的稳定性。 H O G HOG HOG为后期很多检测方法奠定了重要基础,相关技术被广泛应用于计算机视觉各大应用。
DPM Detector
作为VOC 2007-2009目标检测挑战赛的冠军,DPM[3] (Deformable Parts Model)是目标检测传统算法中当之无愧的SOTA(State Of The Art)算法。 D P M DPM DPM于2008年提出,相比于 H O G HOG HOG, D P M DPM DPM作了很多改进,因此该算法可以看作 H O G HOG HOG的延申算法。 D P M DPM DPM算法由一个主过滤器(Root-filter)和多个辅过滤器(Part-filters)组成,通过硬负挖掘(Hard negative mining),边框回归(Bounding box regression)和上下文启动(Context priming)技术改进检测精度。作为传统目标检测算法的SOTA, D P M DPM DPM方法运算速度快,能够适应物体形变,但它无法适应大幅度的旋转,因此稳定性差。
Anchor-Based的Two-stage目标检测算法
基于CNNs的目标检测算法主要有两条技术发展路线:anchor-based和anchor-free方法,而anchor-based方法则包括一阶段和二阶段检测算法(二阶段目标检测算法一般比一阶段精度要高,但一阶段检测算法速度会更快)。Two-stage算法主要分为以下两个阶段:
- 从图像中生成region proposals
- 从region proposals生成最终的物体边框
基于Anchor的目标检测算法主要有以下四大缺点:
- Anchor的大小,数量,长宽比对于检测性能的影响很大(通过改变这些超参数Retinanet在COCO benchmark上面提升了4%的AP),因此Anchor based的检测性能对于anchor的大小、数量和长宽比都非常敏感。
- 这些固定的Anchor极大地损害了检测器的普适性,导致对于不同任务,其Anchor都必须重新设置大小和长宽比。
- 为了去匹配真实框,需要生成大量的Anchor,但是大部分的Anchor在训练时标记为负样本,所以就造成了样本极度不均衡问题(没有充分利用fore-ground)。
- 在训练中,网络需要计算所有Anchor与真实框的IOU,这样就会消耗大量内存和时间。
RCNN
具体内容请参阅论文:RCNN以及对应的代码:代码。
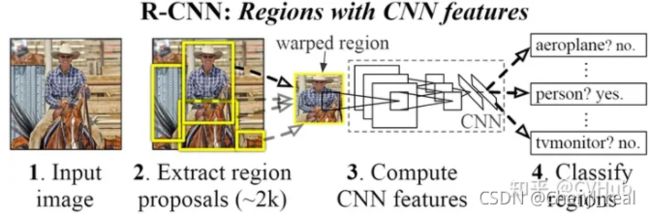
【不足】 虽然RCNN算法取得了很大进展,但缺点也很明显:重叠框(一张图片大2000多个候选框)特征的冗余计算使得整个网络的检测速度变得很慢(使用GPU的情况下检测一张图片大约需要14S)。
SPPnet
具体内容请参阅论文:SPPnet以及对应的代码:代码。

【不足】 和RCNN一样,SPP也需要训练CNN提取特征,然后训练SVM分类这些特征,这需要巨大的存储空间,并且多阶段训练的流程也很繁杂。除此之外,SPPNet只对全连接层进行微调,而忽略了网络其它层的参数。
Fast RCNN
具体内容请参阅论文:论文以及对应的代码:代码。

【不足】 Fast RCNN仍然选用选择性搜索算法来寻找感兴趣的区域,这一过程通常较慢,与RCNN不同的是,Fast RCNN处理一张图片大约需要2秒,但是在大型真实数据集上,这种速度仍然不够理想。
Faster RCNN
具体内容请参阅论文:论文以及对应的代码:代码。

Anchor box设计
Faster RCNN解析可以参考:一文读懂Faster RCNN。Faster R-CNN中的Anchor有3种不同的尺度128×128,256×256,512×512, 3种形状也就是不同的长宽比W:H=1:1,1:2,2:1,这样Feature Map中的点就可以组合出来9个不同形状不同尺度的Anchor Box。Faster R-CNN进行Anchor Box生成的Feature Map是原图下采样16倍得到的,这样不同的长宽比实际上是将面积为16×1616×16的区域,拉伸为不同的形状,如下图:
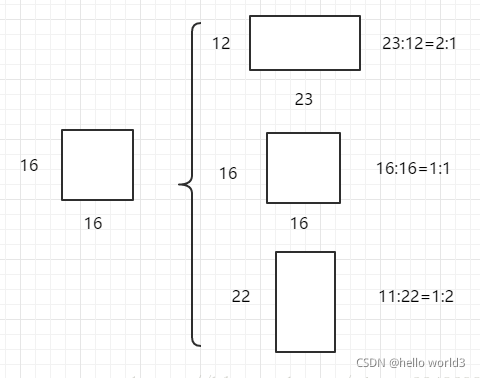
不同的ratio生成的边框的面积是相同的,具有相同的大小。三种不同的面积(尺度),实际上是将上述面积为16×16的区域进行放大或者缩小。128×128是16×16放大8倍;256×256是放大16倍;512×512则是放大32倍。如下图:


FPN
具体内容请参阅论文:论文以及对应的代码:代码。
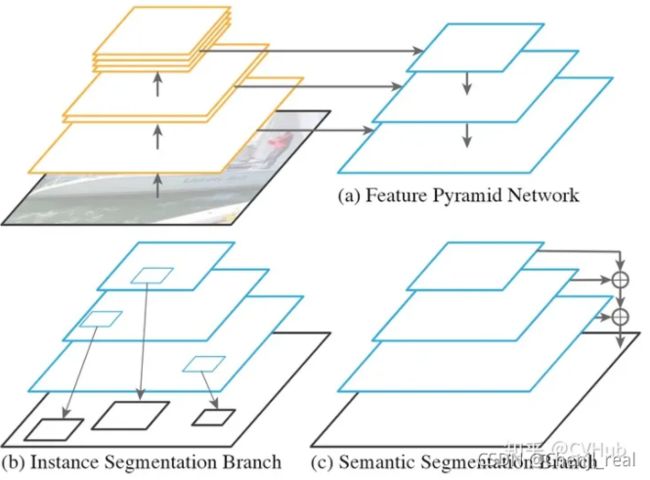
不同阶段的特征图对应的感受野不同,它们表达的信息抽象程度也不一样。浅层额度特征图感受野小,比较适合检测小目标;深层的特征图感受野打,适合检测大目标。
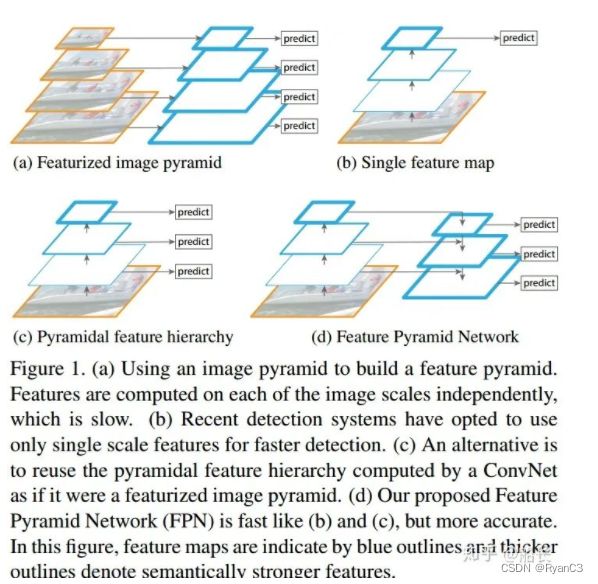
参考:一文看尽物体检测中的各种FPN
在了解各种FPN,先解构物体检测的各个阶段,物体检测大致分为三个阶段,分别为Backbone、Neck以及Detector。

- Backbone
计算机视觉任务一般都是基于常用预训练的Backbone,生成抽象的语义特征,再进行特定任务微调。物体检测也是如此。Backbone生成的特征,一般按stage划分,分别记作C1、C2、C3、C4、C5、C6、C7等,其中的数字与stage的编号相同,代表的是分辨率减半的次数,如C2代表stage2输出的特征图,分辨率为输入图片的1/4,C5代表,stage5输出的特征图,分辨率为输入图片的1/32。 - Neck
这个是FPN特有的阶段,FPN一般将上一步生成的不同分辨率特征作为输入,输出经过融合后的特征。输出的特征一般以P作为编号标记。如FPN的输入是,C2、C3、C4、C5、C6,经过融合后,输出为P2、P3、P4、P5、P6。 - Detector
FPN输出融合后的特征后,就可以输入到检测头做具体的物体检测。
FPN演进
物体检测性能提升,一般主要通过数据增强、改进Backbone、改进FPN、改进检测头、改进loss、改进后处理等6个常用手段。FPN演进如下图所示:

- 无融合
无融合,又利用多尺度特征的典型代表就是SSD,它直接利用不同stage的特征图分别负责不同scale大小物体的检测。

- 自下而上单向融合

(1) Faster/Master/Cascade RCNN中的FPN
Faster/Master/Cascade RCNN中的FPN,利用了C2-C6五个stage的特征,其中C6是从C5直接施加1x1/2的MaxPooling操作得到。FPN融合后得到P2-P6,其中P6直接等于C6,P5是先经过1x1Conv,再经过3x3Conv得到,P2-P4均是先经过1x1Conv,再融合上一层2xUpsample的特征,再经过3x3Conv得到。具体过程可以看上图。
(2) RetinaNet中的FPN
RetinaNet中的FPN,利用了C3-C7五个stage的特征,其中C6是从C5直接施加3x3/2的Conv操作得到,C7是从C6直接施加3x3/2的Conv操作得到。FPN融合后得到P3-P7,其中P6、P7直接等于C6、C7,P5是先经过1x1Conv,再经过3x3Conv得到,P3-P4均是先经过1x1Conv,再融合上一层2xUpsample的特征,再经过3x3Conv得到。具体过程可以看上图。可以看出,RetinaNet基本与Faster/Master/Cascade RCNN中的FPN一脉相承。只是利用的stage的特征略有差别,Faster/Master/Cascade RCNN利用了高分辨率低语义的C2,RetinaNet利用了更低分辨率更高语义的C7。其他都是细微的差别。
(3) Yolov3中的FPN
Yolov3中的FPN与上述两个有比较大的区别。首先,Yolov3中的FPN只利用到了C3-C5三个stage的特征;其次,从C5征到P5特征,会先经过5层Conv,然后再经过一层3x3Conv;最后,C3-C4到P3-P4特征,上一层特征会先经过1x1Conv+2xUpsample,然后先与本层特征concatenate,再经过5层Conv,之后经过一层3x3Conv。看图最清楚。可以看图仔细对比Yolov3与Faster/Master/Cascade RCNN以及RetinaNet细节上的区别。 - 简单双向融合

- 复杂的双向融合
PANet的提出证明了双向融合的有效性,而PANet的双向融合较为简单,因此不少文章在FPN的方向上更进一步,尝试了更复杂的双向融合,如ASFF、NAS-FPN和BiFPN。
Cascade RCNN
具体内容请参阅论文:论文以及对应的代码:代码。

Anchor-based中的one-stage目标检测算法
Yolo系列算法
详情请参考我的博客:目标检测yolo系列和YOLO 目标检测算法
SSD算法
论文:https://arxiv.org/pdf/1512.02325



SSD Anchor设计
SSD有个想法对于每层feature maps(长宽分别为{38,19,10,5,3,1})有不同的anchor box。对于正方形的anchor box,其最小边框为min_size,最大边框为 m i n _ s i z e ∗ m a x _ s i z e \sqrt{min\_size*max\_size} min_size∗max_size。对于长方形长宽分别为 a s p e c t _ r a t i o ∗ m i n _ s i z e \sqrt{aspect\_ratio*min\_size} aspect_ratio∗min_size和 1 a s p e c t _ r a t i o ∗ m i n _ s i z e \frac{1}{\sqrt{aspect\_ratio*min\_size}} aspect_ratio∗min_size1,另一种长方形则是长宽对换。由于ssd中aspect_ratio取值为2,3,则共有六种不同尺度的anchor box:

SSD中共有6个feature map送到分类器,每一层的feature map的anchor数量配置为:[4, 6, 6, 6, 4, 4],4表示只有正方形加上aspect_ratio=2的长方形。则我们可以计算分类器一共需要分类的anchor box的数量: 38 × 38 × 4 + 19 × 19 × 6 + 10 × 10 × 6 + 5 × 5 × 6 + 3 × 3 × 4 + 1 × 1 × 4 = 8732 38\times 38\times 4+19\times 19\times 6+10\times 10\times 6+5\times 5\times 6+3\times 3\times 4+1\times 1\times 4=8732 38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732
现在我们需要计算每个anchor的size究竟是多少。论文里面给出以下公式: s k = s m i n + s m a x − s m i n m − 1 ( k − 1 ) , k ∈ [ 1 , m ] s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1),\quad k\in[1, m] sk=smin+m−1smax−smin(k−1),k∈[1,m]其中论文设计 s m i n = 0.2 , s m a x = 0.9 s_{min}=0.2, s_{max}=0.9 smin=0.2,smax=0.9, k ∈ [ 1 , 5 ] k\in[1,5] k∈[1,5],计算过程如下所示:
s 1 = 0.2 + 0.9 − 0.2 5 − 1 ( 1 − 1 ) = 0.2 s_1=0.2+\frac{0.9-0.2}{5-1}(1-1)=0.2 s1=0.2+5−10.9−0.2(1−1)=0.2
s 2 = 0.2 + 0.9 − 0.2 5 − 1 ( 2 − 1 ) = 0.375 s_2=0.2+\frac{0.9-0.2}{5-1}(2-1)=0.375 s2=0.2+5−10.9−0.2(2−1)=0.375
s 3 = 0.2 + 0.9 − 0.2 5 − 1 ( 3 − 1 ) = 0.55 s_3=0.2+\frac{0.9-0.2}{5-1}(3-1)=0.55 s3=0.2+5−10.9−0.2(3−1)=0.55
特别要注意的是论文有一句:
We Set default box with scale 0.1
所以第一层应该是 m i n _ s i z e = 300 × 0.1 = 30 min\_size=300\times 0.1=30 min_size=300×0.1=30,后面每一层就是 m i n _ s i z e = 300 × s 1 = 60 min\_size=300\times s_1=60 min_size=300×s1=60, m i n s i z e = 300 × s 2 = 111 min_{size}=300\times s_2=111 minsize=300×s2=111以此类推,有:

Loss function
SSD中的损失函数用到的是smoothL1Loss,其目的为了使得训练速度加快并且避免梯度爆炸。详情可以参考:https://zhuanlan.zhihu.com/p/48426076
RetinaNet

目标检测之Anchor
上述介绍了基于Anchor box的方法,这一章主要总结目标检测中的Anchor机制。Anchor box的作用是在目标检测中提供先验,传统的目标检测方法通过窗口滑动技术扫描图像,得出大量的扫描框后进行分类。深度学习的方法是提供anchor box,先判断feature map中是否是前景或者背景,若存在目标即前景,则用提供先验的anchor box与ground true做回归从而得到目标。因此检测器不预测框,而是为每个anchor box预测一组值,主要是学习anchor box与ground true的偏移和confidence。
Anchor box可以由边框纵横比和边框的面积(尺度)来定义,相当于一系列预设边框的生成规则。总结来说在一幅图像,要检测的目标可能出现在图像的任意位置,并且目标可能是任意的大小和任意的形状。
- 使用CNN提取Feature Map的点来定位目标的位置
- 使用Anchor box的scale来表示目标的大小
- 使用Anchor box的Aspect Ratio来表示目标的形状
常见Anchor定义:
- Faster R-CNN定义三组纵横比ratio= [ 0.5 , 1 , 2 ] [0.5, 1, 2] [0.5,1,2]和三种尺度scale= [ 8 , 16 , 32 ] [8, 16, 32] [8,16,32],可以组合9种不同的形状和大小的边框
- YoloV2和V3通过k-means聚类方法,从训练集中学习得到不同的Anchor
- SSD固定设置5中不同的纵横比ratio= [ 1 , 2 , 3 , 1 2 , 1 3 ] [1, 2, 3, \frac{1}{2}, \frac{1}{3}] [1,2,3,21,31],由于使用了多尺度的特征,对于每种尺度只有一个固定的scale
以下内容摘自:锚框(anchor box)理解和代码实现
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。---- 《动手学深度学习v2》
Anchor-Free中的目标检测算法
基于Anchor的物体检测问题通常被建模成对一些候选区域进行分类和回归的问题,在一阶段检测器中,这些候选区域就是通过滑窗方式产生Anchor box,而在二阶段检测器中,候选区域是RPN生成的Proposal,但是RPN本身仍然是对滑窗方式产生的Anchor进行分类和回归。基于Anchor的检测算法由于Anchor太多导致计算复杂,及其所带来的大量超参数都会影响模型性能。近年的Anchor free技术则摒弃Anchor,通过确定关键点的方式来完成检测,大大减少了网络超参数的数量。
CornetNet
论文:http://openaccess.thecvf.com/content_ECCV_2018/papers/Hei_Law_CornerNet_Detecting_Objects_ECCV_2018_paper.pdf
代码:https://github.com/princeton-vl/CornerNet
CenterNet
论文链接:https://openaccess.thecvf.com/content_ICCV_2019/papers/Duan_CenterNet_Keypoint_Triplets_for_Object_Detection_ICCV_2019_paper.pdf
代码链接:https://github.com/Duankaiwen/CenterNet
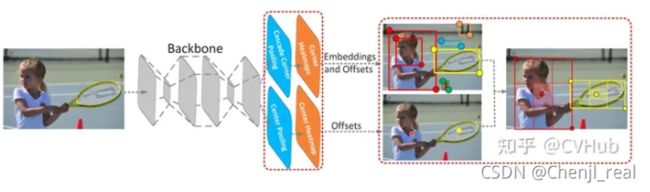
FSAF
论文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Zhu_Feature_Selective_Anchor-Free_Module_for_Single-Shot_Object_Detection_CVPR_2019_paper.pdf
代码链接:https://github.com/hdjang/Feature-Selective-Anchor-Free-Module-for-Single-Shot-Object-Detection

FCOS
论文链接:https://openaccess.thecvf.com/content_ICCV_2019/papers/Tian_FCOS_Fully_Convolutional_One-Stage_Object_Detection_ICCV_2019_paper.pdf
代码链接:https://github.com/tianzhi0549/FCOS

SAPD
论文链接:https://arxiv.org/pdf/1911.12448
代码链接:https://github.com/xuannianz/SAPD

目标检测常用数据集及评价指标
常用数据集
四大公共数据集
- PASCAL VOC数据集详细介绍可参考:https://arleyzhang.github.io/articles/1dc20586/
- ILSVRC数据集详细介绍可参考:https://cloud.tencent.com/developer/article/1747599
- MS-COCO数据集详细介绍可参考:https://blog.csdn.net/qq_41185868/article/details/82939959
- Open Images(QID)数据集详细介绍可参考:https://bbs.easyaiforum.cn/thread-20-1-1.html
其他数据集





常用评价指标
目标检测常用的评价指标有:交并比,准确率,精度,召回率,FPR,F1-Score,PR曲线-AP值,ROC曲线-AUC值,mAP值和FPS。在这里就不展开描述了,具体可以参考我github上的介绍:Yolov4或者常用评价指标
目标检测任务的六大难点与挑战
- 待检测目标尺寸很小,导致占比小,检测难度大
关于小目标检测的问题,可以参考:深度学习检测小目标常用方法 - 待检测目标尺度变化大,网络难以提取出高效特征
- 待检测目标所在背景复杂,噪音干扰严重,检测难度大
- 待检测目标与背景颜色对比度低,网络难以提取出具有判别性的特征
- 各待检测目标之间数量极度不均衡,导致样本不均衡
- 检测算法的速度与精度难以取得良好平衡
目标检测的五大技术及其演变
Multi-Scale检测技术的演变

发展过程:
- Feature pyramids and sliding windows(2014年前)
- Detection with object proposals(2010-2015年)
- Deep regression(2013-2016年)
- Multi-reference detection(2015年后)
- Multi-resolution detection(2016年后)
传统卷积网络通常采用从上到下的单行结构。对于大物体而言,其语义信息将出现在较深的特征图中;对于小物体而言,其语义信息出现在较浅的特征图中,随着网络的加深,其细节信息可能会完全消失。在目标检测任务当中,小物体检测是一个难点。由于小物体尺寸较小,可利用特征有限,使得检测较为困难,主要原因有以下几点:
- 过大的下采样率:假设当前小物体尺寸为 15 × 15 15\times15 15×15,一般物体检测的卷积下采样率为16,这样在特征图上,过大的下采样率使得小物体用一个像素点都无法表达。
- 过大的感受野:在卷积网络中,特征图上特征点的感受野比下采样率大很多,导致在特征图上的一个点中,小物体占据的特征更少,会包含大量周围区域的特征,从而影响其检测结果。
- 语义与空间的矛盾:当前检测算法,如Faster RCNN,其骨架网络大都是自上而下的方式,深层与浅层特征图在语义性与空间性上没有做到更好的均衡。
- 高层语义信息与底层语义信息缺少融合。
根据以上讨论,有以下较为通用的提升多尺度检测的方法:降低下采样率以及采用空洞卷积,空洞卷积目的是提高感受野,在语义分割中被广泛应用;设计更好的Anchor,这样能够有效提升Proposal质量,Yolo中通过聚类的方式生成anchor box。多尺度训练构建Feature map,并对特征图进行融合。
边框回归技术的演变

上下文信息提取技术的演变
目标检测领域中每一个目标都被周围背景所包围,而我们对于一个目标的认知会根据其周围的环境作出判断,于是我们将目标周围的环境信息称作上下文信息。上下文可以作为网络判断目标类别和定位的重要辅助信息,可大大提高网络检测的精度。为网络提取上下文信息有以下三种常用的方法:
- 提取局部上下文信息用于目标检测
- 提取全局上下文信息用于目标检测
- 上下文信息交互提取高效上下文信息用于目标检测
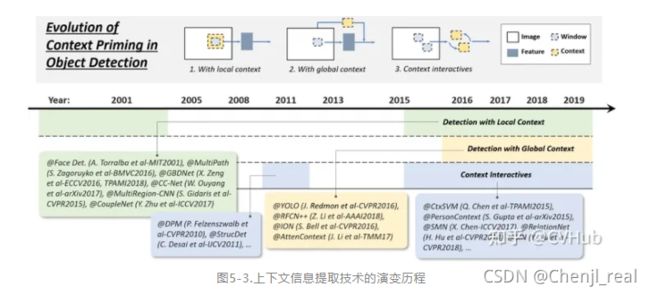
非极大值抑制技术的演变

难分负样本挖掘技术的演变

目标检测模型的加速技术
轻量化网络的设计
轻量化网络的设计可以使模型轻量化的同时保持较高的精度,对模型轻量化可以采取以下的方法:卷积分解、分组卷积、深度可分离卷积、Bottle-neck设计以及神经网络搜索。
模型压缩与量化
模型压缩与量化是两种常用于加速CNN模型的技术,这其中所涉及到的技术有模型剪枝,量化与知识蒸馏。其中模型剪枝是指修剪网络结构或权重从而减小规模的一种技术;模型量化则是指将模型一些浮点计算转成低Bit的定点计算的技术,它可以有效降低模型计算强度、参数大小和内存消耗;而知识蒸馏则是指将大网络所学习到的"知识"有效传递到小网络中的一种技术。
数值加速技术
- 积分图像加速
- 频域加速
- 矢量量化
- 降阶逼近
提高目标检测模型精度的五大技术
特征提取网络
特征提取网络(Backbone)对于目标检测模型性能的提升至关重要,一些经典的特征提取网络对目标检测任务精度起到了重要的推动作用,如AlexNet、VGG、GoogLeNet、ResNet、DenseNet、SENet等等。随着卷积神经网络的发展,业界不断涌现出了一些新的特征提取网络,性能更是步步攀升。一些先进的特征提取网络被应用于目标检测模型的特征提取Backbone,使得目标检测模型的精度与速度不断提升,比如STDN,DSOD,TinyDSOD和DenseNet等等。作为当时实力分割的SOTA算法,Mask RCNN采用了ResNeXt作为网络的Backbone。
高效的特征融合
高效的特征表示是提升目标检测性能的关键,近年来,许多研究学者在特征提取网络中加入一些Trick去提高网络的特征提取能力。而用于提高网络表征能力的两项最重要的方法便是:1)高效的特征融合 和2)学习出具备大感受野的高分辨率特征表示。目标检测中边界框的回归策略
目标定位的改进
高效的特征表示是提升目标检测性能的关键,近年来,许多研究学者在特征提取网络中加入一些Trick去提高网络的特征提取能力。而用于提高网络表征能力的两项最重要的方法便是:1)高效的特征融合 和2)学习出具备大感受野的高分辨率特征表示。
语义分割促进目标检测
目标检测的五大应用场景
具体参考:综述:目标检测二十年(2001-2021)
目标检测未来发展的七大趋势
- 轻量型目标检测
- 与AutoML结合的目标检测
- 领域自适应的目标检测
- 弱监督目标检测
- 小目标检测
- 视频检测
- 信息融合目标检测
参考
- 综述:目标检测二十年(2001-2021)
- 小目标检测常用方法总结
- 目标检测中边界框的回归策略