机器学习——逻辑回归案例——泰坦尼克号乘客生还
提示:本案例使用逻辑回归模型,进行二分类
目录
一、逻辑回归是什么?
二、使用步骤
1.需要引入库
2.首先导入读取数据模块pandas读入数据
3、查看不同属性的生还情况
4、数据预处理
5、模型构建与训练
三、模型评估
6.预测测试数据
7.绘制混淆矩阵
8.绘制ROC曲线,并计算AUC。
总结
前言
泰坦尼克号的沉没是历史上最臭名昭著的沉船之一。
1912年4月15日,在她的处女航中,被广泛认为"不沉"的"泰坦尼克号"在与冰山相撞后沉没。不幸的是,船上的每个人都没有足够的救生艇,导致2224名乘客和船员中有1502人死亡。
虽然生存中有一些运气因素,但似乎有些群体比其他群体更有可能生存下来。
我们要求您建立一个预测模型,以回答以下问题:"什么样的人更有可能生存?"使用乘客数据(即姓名,年龄,性别,社会经济阶层等)。
它是一个二分类问题,要求根据乘客的相关信息去预测乘客的生还,我们使用逻辑回归模型去预测,本案例训练集可以在这里下载:
https://download.csdn.net/download/qq_21402983/85068980 https://download.csdn.net/download/qq_21402983/85068980
https://download.csdn.net/download/qq_21402983/85068980
提示:以下是本篇文章正文内容,下面案例可供参考
一、逻辑回归是什么?
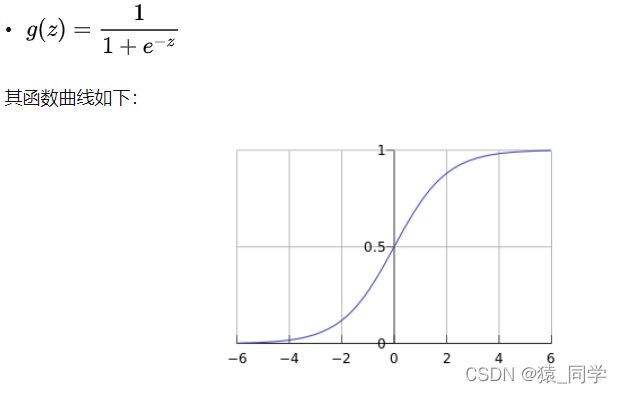
简单来说, 逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等。 注意,这里用的是“可能性”,而非数学上的“概率”,logisitc回归的结果并非数学定义中的概率值,不可以直接当做概率值来用。该结果往往用于和其他特征值加权求和,而非直接相乘。
二、使用步骤
1.需要引入库
代码如下(示例):
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression2.首先导入读取数据模块pandas读入数据
代码如下(示例):
import pandas as pd
data=pd.read_csv("train.csv") #读取数据
data.info() #查看数据框的所有信息
在Age、Cabin、Embarked中发现有缺失值
data.describe()
3、查看不同属性的生还情况
1、按性别查看
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
Survived_m=data.Survived[data.Sex == 'male'].value_counts()
Survived_f=data.Survived[data.Sex=='female'].value_counts()
df=pd.DataFrame({'男性':Survived_m,'女性':Survived_f})
df.plot(kind='bar',stacked=True,rot=0)
plt.title('按性别看是否生还')
plt.xlabel('生还')
plt.ylabel('人数')
2、按不同的登船港口乘客的生还情况
Survived_0=data.Embarked[data.Survived == 0].value_counts()
Survived_1=data.Embarked[data.Survived == 1].value_counts()
plt.rcParams['font.sans-serif'] = ['SimHei']
df=pd.DataFrame({'生还':Survived_1,'未生还':Survived_0})
df.plot(kind='bar',stacked=True,rot=0)
plt.title('各登船港口乘客是否生还')
plt.xlabel('登船港口')
plt.ylabel('人数')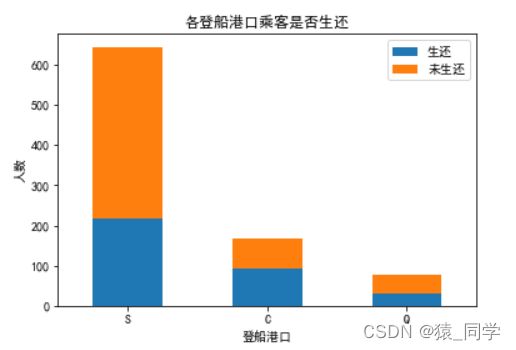
4、数据预处理
#删除一些无关信息
data.drop(['Name','PassengerId','Ticket','Cabin'],axis=1,inplace=True)
data['Age']=data['Age'].fillna(data['Age'].mean())
data['Fare']=data['Fare'].fillna(data['Fare'].mean())
data['Embarked']=data['Embarked'].fillna(data['Embarked'].value_counts().index[0])
#将性别与登船港口进行独热编码
dumm=pd.get_dummies(data[['Sex','Embarked']],drop_first=True)
data=pd.concat([data,dumm],axis=1)
data.drop(['Sex','Embarked'],axis=1,inplace=True)
#数据缩放
data['Age']=(data['Age']-data['Age'].min()) / (data['Age'].max()-data['Age'].min())
data['Fare']=(data['Fare']-data['Fare'].min()) / (data['Fare'].max()-data['Fare'].min())
print(data.describe())划分训练集和测试集,用于评估模型
#划分训练集和测试集,既预留一部分数据(30%),用于评估模型。
from sklearn.model_selection import train_test_split
X=data.drop('Survived',axis=1)
y=data.Survived
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)5、模型构建与训练
创建模型:
from sklearn.linear_model import LogisticRegression
LR=LogisticRegression()训练模型:
LR.fit(X_train,y_train)
print('训练集准确率:\n',LR.score(X_train,y_train))
print('验证集准确率:\n',LR.score(X_test,y_test))测得准确率为:

三、模型评估
接下来我们对模型进行评估
6.预测测试数据
y_pred=LR.predict(X_test)7.绘制混淆矩阵
from sklearn import metrics
print(metrics.confusion_matrix(y_test,y_pred),)![]()
print(metrics.precision_score(y_test,y_pred))
print(metrics.recall_score(y_test,y_pred))
print(metrics.f1_score(y_test,y_pred))
print(metrics.accuracy_score(y_test,y_pred))
使用分类报告的形式显示所有类别的查准率、查全率和F1分数等。
print(metrics.classification_report(y_test,y_pred))
8.绘制ROC曲线,并计算AUC。
#每个样例属于正类的概率值
y_pred_prob =LR.predict_proba(X_test)
#计算ROC曲线,既真正例率、假正率等
fpr,tpr,thresholds = metrics.roc_curve(y_test,y_pred_prob[:,1])
#计算AUC值
auc1=metrics.auc(fpr,tpr)
print(auc1)
![]()
绘制ROC曲线
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(fpr,tpr,lw=2,label='ROC curve(area={:.2f})'.format(auc1))
plt.plot([0,1],[0,1],'r--')
plt.xlabel('False Positive Rate')
plt.ylabel('Frue Positive Rate')
plt.title('Receiver opsitive cRatr')
plt.legend(loc='lower right')
总结
可以看到,该模型在测试集上的准确率高于训练集上的准确率,没有过拟合,可以考虑增加模型参数或复杂度。逻辑回归模型关于泰坦尼克号乘客生还能达到较好的预测效果