一种高效的基于邻域空间聚合的点云语义分割不确定性估计方法(ICRA2021)
Neighborhood Spatial Aggregation based Efficient Uncertainty Estimation for Point Cloud Semantic Segmentation (2021-ICRA)
代码地址:https://github.com/chaoqi7/Uncertainty_Estimation_PCSS.
点云语义分割(point cloud semantic segmentation,PCSS)的不确定性估计是指如何量化点的预测标签的置信度,这对于决策任务至关重要,例如机器人抓取、路径规划和自动驾驶。本文作者提出了一种基于邻域空间聚合的方法,NSA-MC dropout,可以高效的实现点云语义分割的不确定性估计。与传统的基于重复推理的不确定性估计方法 MC dropout不同,作者提出的 NSA-MC dropout 通过一次性推理实现了不确定性估计。具体而言,作者设计了一种空间相关的方法,通过仅执行一次随机前向传递模型来对模型进行多次采样,并且它近似于 MC dropout 中基于重复推理的采样过程。此外,称为 NSA 的邻域空间聚合模块聚合每个点的邻域的概率输出结果,并与空间相关采样一起建立输出分布。最后,作者提出了一个不确定性感知框架 NSAMC dropout,以实现有效捕获预测结果的不确定性。实验结果表明,作者的方法获得了与 MC dropout 相当的性能。更重要的是,NSA-MC dropout 对语义推理的效率几乎没有影响,比MC dropout快得多,并且推理时间与采样时间没有建立耦合关系。
本文主要贡献总结如下:
1) 在没有重复推断的情况下为每个点建立了输出分布。高效的分布建立依赖于一种新颖的空间相关采样方法,以空间换取时间,解决了传统MC dropout中采样耗时的问题。
2) 提出的 NSA-MC dropout 可以很容易地集成到现有的 PCSS 框架中进行不确定性感知推理,并且它通过仅执行一次随机前向传递模型来实现有效的不确定性估计。
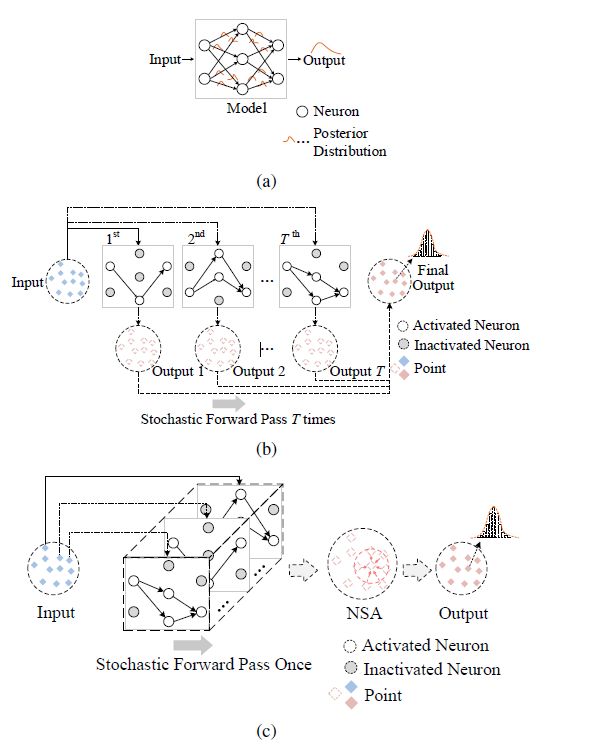
图1 (a) 神经网络中的不确定性估计。网络中的所有权重都由可能值的后验分布表示,而不是由单个固定值推导。同样,每个点的输出都由分布表示。(b) 具有时间依赖性采样的 MC dropout。MC dropout 通过重复推理使用 dropout 对权重的后验分布进行采样。这种采样方法需要将模型随机转发 T 次,导致 T 倍减速。(c) NSA-MC dropout 与空间依赖采样。与 MC-dropout 不同,作者的方法通过执行一次随机前向对模型进行多次采样。不同点的语义推断是基于不同架构的网络。NSA 聚合概率信息并且为每个点生成输出分布。
点云语义分割的不确定性估计有助于我们了解可以信任点的预测标签的程度。这个能力对于决策应用任务来讲至关重要,例如机器人抓取、路径规划和自动驾驶。然而,不确定性估计依赖于输出分布的建立,需要大量的计算时间。大量时间消耗问题对于基于大规模点云的语义分割任务的不确定性估计来说非常具有挑战,特别是对于那些需要有高效率要求的任务。因此,作者探索了一种实现 PCSS 有效不确定性估计的方法。
基于神经网络 (Neural network,NN) 的 PCSS 方法广泛用于实际工程应用。虽然目前对 PCSS 不确定性估计的研究很少,但一般的神经网络不确定性估计方法已被广泛关注。NN 中的不确定性估计一般是通过推断分布从而为每个目标生成输出分布网络权重,如图1(a)所示。以前的方法使用高斯分布来逼近真实的后验分布,这导致模型参数和计算成本大幅增加。最近提出的Monte Carlo dropout(MC dropout)方法是一种是高斯过程的近似。由于其简单性,即只需在推理时将其集成到当前方法中,目前广受欢迎。MC dropout 可用于 PCSS 的不确定性估计,如图 1(b)所示。然而,传统的MC dropout面临着严重的耗时采样过程,难以用于具有高效率要求的PCSS。这促使相关学者相继探索 MC dropout 的改进版本,并基于快速采样方法实现 PCSS 的有效不确定性估计。
与图像等二维网格数据不同,点云是一组用于描述物体表面和结构的点。基于几何连续性的特性,可以很好地利用空间信息。通过对一个点的重复推理建立的高斯过程可以被通过对该点及其邻域的一次性推理建立的近似过程代替。这种近似高斯过程依赖于一种新颖的空间相关采样方法,它消除了对重复推理的依赖。
具体来说,作者设计了 NSA 用来估计基于空间相关采样方法的点预测结果的不确定性,如图 1(c)所示。NSA 将邻域的推理结果汇总到一个点,生成该点的概率分布,用于不确定性估计。空间相关采样方法保证了邻域点语义推断的模型随机性,并且整个过程只需要前传一次模型。
另外,作者结合NSA,扩展了基于PointNet(++)的点云语义分割框架来估计不确定性。探索了框架的特性,并将基于 NSA 的 MC dropout(NSAMC dropout)嵌入其中。NSA-MC dropout 在语义推理过程中实现空间相关采样,并快速估计点云分割结果的不确定性。
方法核心:
为了实现对 PCSS 的有效不确定性估计,作者提出了一种基于快速采样的不确定性感知框架。首先,设计了一个名为 NSA 的模块,使用新颖的空间相关采样为每个点生成输出分布。其次,作者将 NSA-MC dropout 嵌入到基于 PointNet (++) 的 PCSS 框架中,以进行有效的不确定性估计。
1、邻域空间聚合
基于采样的不确定性估计。以给定数据集为条件的网络权重的真实后验分布通常是通过使用权重 q(w)上的高斯分布的变分推理来估计的。此外,MC dropout可以用来模拟高斯过程,这些近似推论可以表示为:

其中 T 是总采样时间, y* 是 x* 的相应预测标签。w^ 是通过在权重上放置伯努利分布来生成的,这是 dropout 处理过程。
表 1 中给出了几个不同的可用于捕获不确定性概念的获取函数:预测熵 (PE)、贝叶斯主动学习分歧 (BALD) 和平均标准偏差(平均 STD)。
表1 基于采样的不确定性估计采集函数
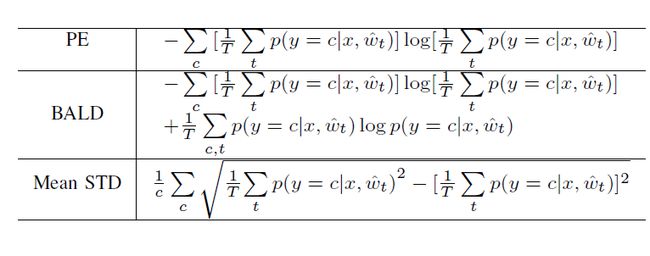
NSA 与空间相关的采样。在传统的 MC dropout 中,T 次采样相当于对模型进行 T 次随机前向传递,需要花费大量时间。作者探索了一种基于点云的结构特征来解决采样耗时问题的方法。
点云用于描述物体的表面和结构。邻域 U 中相邻点的几何特征相似,相邻点的预测结果也很接近。因此为了在方程中找到更为精确的拟合表面函数。作者在每个点上预测一个逐点权重。然后,所有点通过主成分分析(PCA)转换到切线空间,并通过加权最小二乘(WLS)拟合问题求解表面系数:

x*及其 T-1 个相邻点 x*t 的平均输出近似于 T 次采样的 MC dropout结果。

这个过程就称为邻域空间聚合,它与空间相关的采样一起起作用以获得输出分布。如图 1(c) 所示,用于不同点语义推断的网络呈现随机架构。每个点聚合邻域推理的结果使用 NSA 生成输出分布。
2、不确定性感知 PCSS
作者探索了向 PCSS 框架添加主动 dropout 层的适当方案,以实现空间相关采样和不确定性估计。
不确定性的backbone。考虑到 PointNet 和 PointNet++ 在 PCSS 中的巨大成功,作者选择其作为backbone方法。PointNet(++)是一个encoder-decoder网络,如图2所示。编码部分提取全局特征或局部特征,解码部分将特征连接到点云中的每个点进行进一步分类。

图2 NSA-MC dropout 使用 PointNet(++) 作为backbone方法。在编码阶段,生成不同尺度的特征向量。在解码阶段,将生成的特征连接到点以进行进一步分类,并在 MLP 之后插入 dropout 以实现采样。NSA 通过总结邻域内点的推理结果实现有效地估计不确定性。
backbone中的 NSA-MC dropout。在先前的工作中已经讨论了在 NN 中应用 dropout 进行不确定性估计。一个完整的 BNN 应该在每个具有可学习参数的层之后使用 dropout 进行训练和测试。有学者发现这是一个强大的正则化器,导致训练过程中收敛速度缓慢。此外,许多仅在部分层之后插入dropout 的变体可以体显示出与完全 BNN 相似的不确定性输出。
作者的目标是找到一种在 PointNet(++) 中应用 dropout 层的合适方案,它不仅可以多次有效地对模型进行采样,而且对模型训练的影响很小。为此,应考虑以下问题。
一方面,如图 2 所示,多层感知器(MLP)包含几个权重共享的全连接层(FC), 而每个FC都对应着一个点。每个点在解码阶段与特征向量相连接,而FC则用于更新相应点的状态。通过随机丢弃MLP中的单元,MLP中的FC代表不同的结构。MLP代表不同的架构,这导致了用于不同点的语义推理的网络架构的随机性。通过NSA的功能作用,从而实现在一次语义推理中实现多次采样。
另一方面,PointNet(++) 将相同的编码信息连接到特定空间域中的点。假设我们在编码阶段加入了dropout层,空间域中不同点的编码信息仍然相同,这对用于采样的架构随机性贡献不大。此外,它会导致点云语义建模能力的损失,这将在实验中得到证明。
总之,dropout 层仅用于解码中的 MLP。
3、实验环节
A.数据集
作者选择数据集 S3DIS 来评估 NSA-MC dropout 的性能。数据集中的每个点云都是一个房间,Area-5中的点云作为测试数据,其他的作为训练数据。考虑到PointNet(++)很难直接处理单个房间的点云。因此,每个点云都被分成1mX1m 的块用于训练和测试。
B.实验细节
模型训练。PointNet(++) 使用反向传播和自适应矩估计 (Adam) 求解器进行端到端训练,学习率为 0.001。训练批次大小设置为 16。所有实验均在单个 GeForce GTX 1080 Ti 和 Intel(R) Core(TM) i7-6850K 3.60GHz 6 核 CPU 上进行。
不确定性估计。测试时保持 dropouts 打开以实现不确定性估计的采样,并且使用 KD-Tree 搜索算法在邻域空间聚合中并行搜索最近邻。
C.评价标准
NSA-MC dropout 是 MC dropout 的一种变体。因此,作者引入以下指标来全面比较所提方法与 MC dropout 的性能。
1.语义分割评价指标
oAcc, mAcc, 和 mIoU
2.不确定性估计评价指标
1)Precision-Recall curve (PR-curve)
2)Ranking IoU.
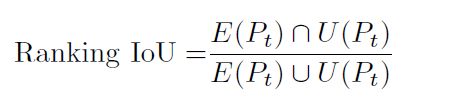

图3 误差排序序列是通过按预测误差的递增顺序对体素进行排序来创建的。不确定性排序序列是通过按平均不确定性的递增顺序对体素排序来创建的。
3.有效性评价指标
推理时间
D.实验对比
语义分割的定量分析。表2展示了 PointNet(++) 与 NSA-MC dropout 和 PointNet(++) 与 MC dropout 之间语义分割的比较。
表2 语义分割对比结果

不确定性估计的点级定量分析。这里作者使用 PR 曲线来量化不确定性和预测精度之间的相关性,如图 4 所示。通过PR曲线可以看出,一方面,随着不确定性的增加,改进的方法和对比方法生成的曲线都有明显的下降趋势。另一方面,无论使用哪种采集函数,得到的两条曲线都显示出高度的一致性。从而证明NSA-MC dropout 实现了基于空间相关采样的点的准确概率输出。
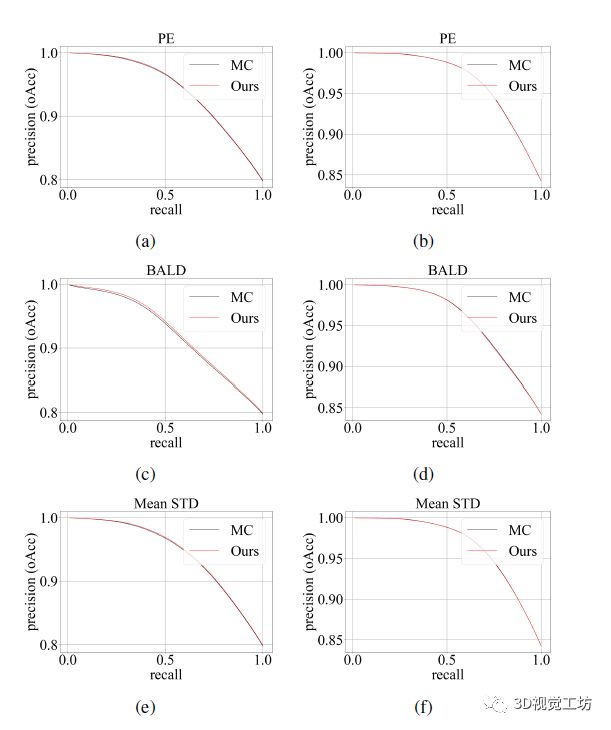
图4 基于不同采集函数和不同backbone方法的 PR 曲线。左列数字是使用PointNet作为backbon的结果,右列数字是使用PointNet++作为backbon的结果。oAcc 用作精度。PE、BALD 和平均 STD 用作采集函数。
不确定性估计的体素级定量分析。整个 S3DIS Area 5 被划分为 103 个体素,使用体素级度量 Ranking IoU 的评估结果如表 3 所示。通过改进方法获得的结果与通过 MC dropout 获得的结果相当。
表3 使用Ranking IOU 的评估结果

有效性分析。所提方法在推理时间上的分析如表4所示。可以看出采样计算的效率非常高。
表4 推理的平均计算时间

质量分析。图 5 显示了 S3DIS Area 5 中几个房间的语义分割、预测误差和不确定性图的可视化。为了进一步探索本文方法的准确性和不确定性之间的关系,作者计算了每个类别的测试数据集的平均不确定性和准确性并绘制图 6 中的关系。

图5 S3DIS Area 5上的可视化结果,选择PE作为获取函数,左边两列是使用PointNet作为backbone的可视化结果,而右边两列使用PointNet++作为backbone的可视化结果。
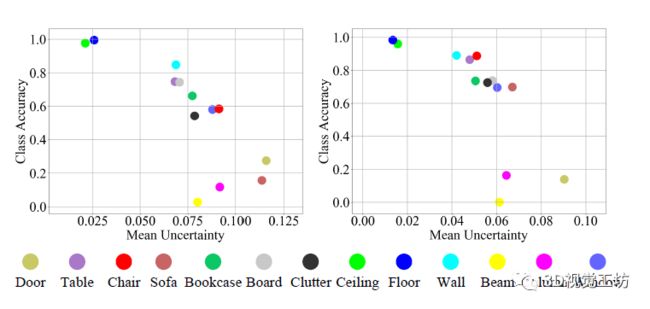
图6 测试数据集中的类准确率和平均不确定性之间的关系。左图使用PointNet作为backbone,右图使用PointNet++作为backbone。
4、总结
本文最大的优势在于推理时间显着减少,而不确定性估计性能却没有损失。因此这项工作可以促进不确定性估计在现实世界 PCSS 任务中的应用。
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
原创征稿
初衷
3D视觉工坊是基于优质原创文章的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向,欢迎砸稿过来~文章内容可以为paper reading、资源总结、项目实战总结等形式,公众号将会对每一个投稿者提供相应的稿费,我们支持知识有价!
投稿方式
邮箱:[email protected] 或者加下方的小助理微信,另请注明原创投稿。

▲长按加微信联系

▲长按关注公众号