可以估计不确定性的神经网络:SDE-Net
作者丨段易通@知乎
来源丨https://zhuanlan.zhihu.com/p/234834189
编辑丨极市平台
随着深度学习技术的不断发展,DNN模型的预测能力变得越来越强,然而在一些情况下这却并不是我们想要的,比如说给模型一个与训练集完全不相关的测试样本,我们希望模型能够承认自己的“无知”,而不是强行给出一个预测结果,这种能力对于自动驾驶或者医疗诊断等重视风险的任务是至关重要的。因此,为了达到这个目的,我们的模型需要具有量化不确定性的能力,对于那些它没有把握的样本,模型应该给出较高的不确定性,这样就能指导我们更好地利用模型的预测结果。
之前我介绍过可以预测概率分布的DeepAR模型,其实这次介绍的SDE-Net与它的目标是一致的,都是令模型在预测的基础上还能够度量预测结果的不确定性,不过SDE-Net的实现这个目标的思路与DeepAR不同,下面就来具体介绍。
段易通:概率自回归预测——DeepAR模型浅析
https://zhuanlan.zhihu.com/p/201030350
不确定性
上文中已经提到,我们的目的是要量化不确定性,那么我们当然要先知道是什么导致了模型的不确定性、并且要了解不确定性产生的来源有哪些,论文中认为模型预测的不确定性来自于两个方面:
aleatoric uncertainty:来自于任务本身所固有的自然随机性(比如说label噪声等)
epistemic uncertainty:由于缺乏训练数据所导致的,模型对于训练数据分布之外的样本是无知的
对于aleatoric uncertainty,它是由任务本身天然决定的,可以设想一个所有标签都是噪声的训练集,用这样的数据集训练出来的模型,它的预测结果显然是不可信的,即不确定度很大;而对于epistemic uncertainty,它是由于模型的认知不足造成的,在面对训练集分布之外的数据时,模型的预测结果会具有较高的不确定度。
下图是对两种不确定度对模型预测结果影响的示意图,我们这里用到的是概率模型(比如说DeepAR或者后面要说的SDE-Net,输出的是一个随机变量而不是一个定值,因此通过模型得到的其实是一个概率分布)。其中左边的simplex corner代表分类任务(三分类),右边的二维坐标代表回归任务,其中横轴代表predictive mean 、纵轴是predictive variance (不太明白这里 和 的含义,求解惑~)。

SDE量化不确定性
我们知道,神经网络尤其是ResNet可以看做是由常微分方程(ODE)控制的一个动力学系统(具体可以看ResNet的相关资料,或者我的这篇文章,https://zhuanlan.zhihu.com/p/92254686),相邻层之间的输入输出关系为:
其中 是第t层的隐藏状态,如果我们令 ,上式可以写做: ,如果我们让 ,那么就有:
ResNet其实可以看做是离散化的动力学系统,不过控制方程是一个ODE,所以神经网络得到是只是一个确定性结果。为了让模型可以估计不确定性,我们自然就想到是不是可以改用一个随机微分方程(SDE)来控制dynamic呢?这就是论文的核心思想,其实也很简单,就是在原有ODE的基础上再加上一个随机项,这里采用的是标准布朗运动,那么dynamic的形式就变为:
这里 就是标准布朗运动,可以看出函数 控制的就是dynamic的波动,我们就用它来代表模型对于epistemic uncertainty的估计,下图是 的大小对于dynamic的影响。
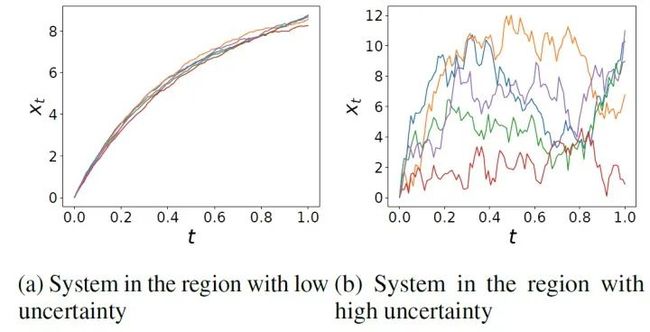
模型构造
这样一来,我们就利用SDE来描述了隐层状态的dynamic,并通过随机过程的方差来量化估计epistemic uncertainty。为了使模型具有良好的预测精度和可靠的不确定性估计,论文的SDE-Net模型用了两个单独的神经网络来表示分别dynamic的漂移和扩散,如下图所示:
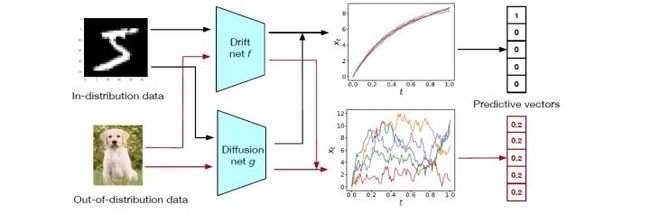
可以看出,对于分布内的测试样本,diffusion net计算出的不确定度很小,因此drift net占主导地位,我们可以获得置信度很高的预测结果;但是对于分布外的样本,计算出的不确定度很大,因此diffusion net占主导地位,得到的结果几乎就是随机分布的结果。
对于SDE-Net的两个神经网络,论文采用了如下的目标函数来进行训练
其中 是任务的损失函数,T是随机过程的末时刻(即网络的输出层), 和 分别是训练集分布内与分布外(OOD)的数据,OOD数据可以通过给原数据加噪声做变换的方式获得,也可以直接用另一个任务目标不相关的数据集。
可以看出,目标函数一共分为三部分,前两项是关于分布内样本的目标函数,其目的是保证在常规的损失最小化的基础上,还要使得这些样本的不确定度估计较小,后一项是关于OOD数据的,对于这些样本,我们不关注其loss的大小,而是只令模型对于OOD样本的不确定度增加。
需要注意的是,这里SDE-Net中每一层的参数都是共享的,而且扩散项的方差仅由起始点x0决定,这样可以使模型训练起来更容易。
训练好模型之后,我们可以通过多次采样的方法,来得到多个输出 ,这种采样计算的思路与传统的集成方法具有相似之处,但是传统方法需要训练多个模型,而SDE-Net只需训练一次即可通过布朗运动的随机性得到多个输出样本,从而大大减小了训练成本。
理论分析
论文还对模型做了一些理论分析,内容不多,就直接放原文了


模型训练
考虑到模型的层数是有限的,因此我们需要将SDE离散化,形式如下:
其中时间区间为 ,模型一共有N层,因此 。
总的来看,SDE-Net的训练算法如下:

简单概括一下这个算法,首先我们从分布内采样出一批训练数据,然后通过一个降采样层得到输入 ,接着就根据SDE-Net来控制隐层状态的dynamic,并在最后接一个全连接层得到模型的输出 ,这样我们就可以通过计算loss的梯度来更新降采样层、drift net以及全连接层的参数;另外,我们还要从分布外采样出一批数据(OOD数据),然后根据分布内外的数据分别对diffusion net的参数做梯度下降和梯度上升。
实验
论文的实验研究了不确定性估计在model robustness和label efficiency中的作用,实验采用的对比模型有:Threshold、MC-dropout、DeepEnsemble、Prior network(PN)、Bayes by Backpropagation (BBP)、preconditioned Stochastic gradient Langevin dynamics(p-SGLD);其中PN和SDE-Net需要额外的OOD数据,这里通过对原有的数据样本上加上高斯噪声来进行构造、或者直接采用另一个数据集,至于其它的一些具体设定可以看论文的实验和补充材料部分。
1.OOD检测
就像在文章开头提到的,让模型有“自知之明”是非常重要的,因此第一个任务就是评估模型识别OOD样本的能力,实验中使用的metric如下所示,这些metrics都是值越大越好:
True negative rate (TNR) at 95% true positive rate (TPR)
Area under the receiver operating characteristic curve (AUROC)
Area under the precision-recall curve (AUPR)
Detection accuracy
实验结果如下所示:
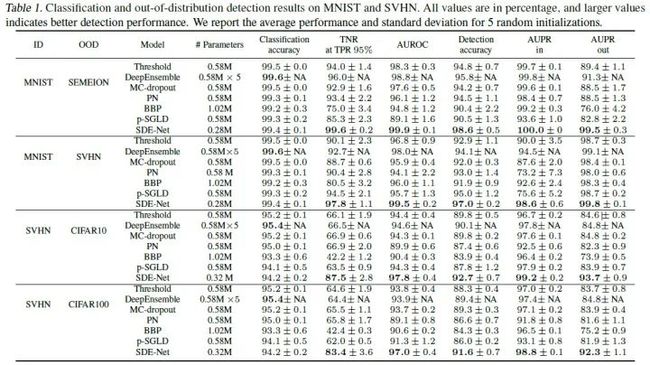
分类任务
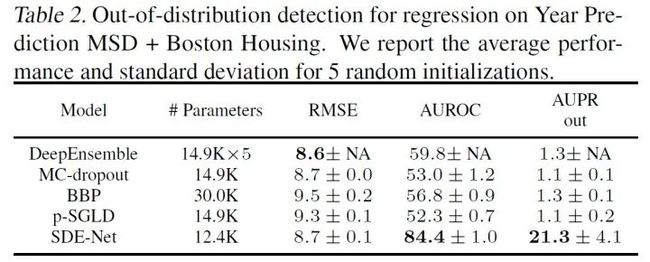
回归任务
从表中可以看出,SDE-Net的性能基本超越了其它所有模型。另外,下图是提高模型层数或者ensemble数量对OOD检测的影响,可以看出SDE-Net不需要像一些其它模型那样必须大量堆叠才能达到最优性能。
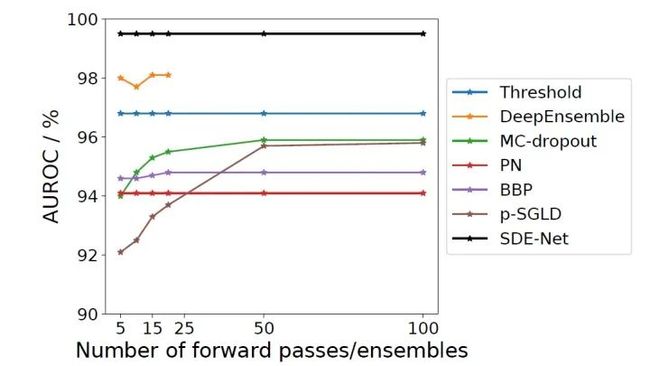
2.误分类检测
如果模型预测的不确定性很大,那么就说明模型对预测结果是没有把握的,样本可能被分类错误。因此这个任务的目的是利用预测的不确定性来找出模型分类错误的样本,其结果如下:
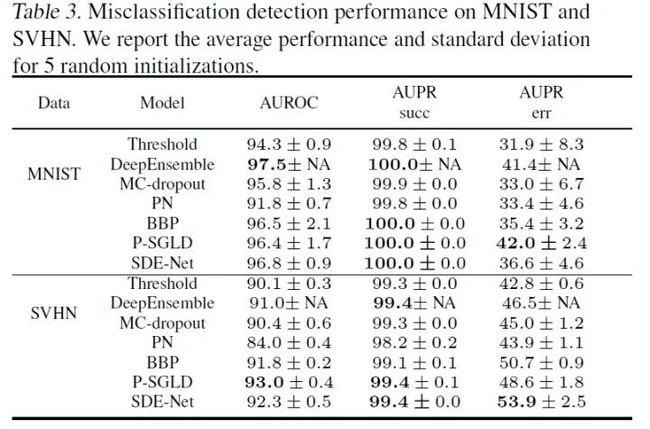
虽然P-SGLD的效果也不错,不过它的计算成本很高,因此在实际情况中SDE-Net可能会是一个更好的选择。
3.对抗样本检测
我们知道,在样本中加入一些很小的对抗扰动后,正常的DNNs会变得非常容易出错,因此这个任务的目标就是从样本集中找出对抗样本,这里采用了两种对抗攻击方式Fast Gradient-Sign Method (FGSM)和Projected Gradient Descent (PGD)来产生对抗样本,实验结果如下:
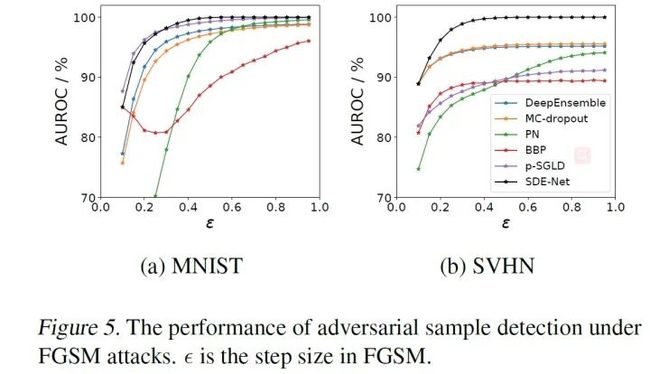
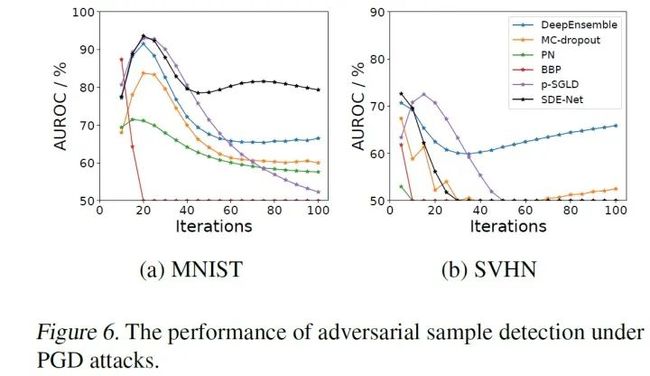
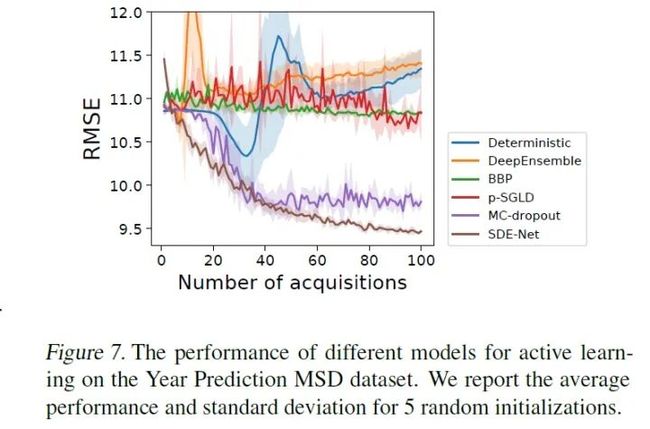
4.主动学习
假设一开始样本集里有标注的样本很少,模型需要自己挑一些信息量大的样本出来让专家进行标注,这就是主动学习的思想。直观上来看,挑选信息量大的样本可以显著减少用于模型训练的数据量,而信息量小的样本会增加训练成本、甚至会导致过拟合。最后一个任务就是关于主动学习的,论文设定acquisition function(不了解的同学可以学习一下相关知识点)的形式为:
该式的意思就是让模型选择那些具有较高的epistemic uncertainty但数据具有较低的low aleatoric noise的样本,结果如下,可以看出SDE-Net选择的样本都是信息量比较大样本,因此RMSE下降的更快。
总结
ResNet可以对应为一个离散ODE,这篇文章受到该思路的启发,构建了一个可以被看做离散SDE的SDE-Net模型,模型由两个神经网络drift net和diffusion net构成,其中drift net与传统模型类似,是为了预测模型的输出结果,而diffusion net则用来估计预测的不确定性,估计出的不确定性可以应用于OOD样本检测、误分类检测、主动学习等多个任务,而可以估计不确定性的SDE-Net也更加适合于一些关注风险的实际应用领域。
个人感觉,论文中通过SDE来评估不确定性的想法很有意思,确实有一定的可取之处;不过模型为了训练diffusion net网络,专门构建了用于梯度上升的OOD数据集,这样的数据集无论怎么构建,都很难代表整个训练集以外的分布,因此不可避免地会引入一些bias,而这就可能会影响模型对于不确定度的估计。
参考文献
[1] SDE-Net: Equipping Deep Neural Networks with Uncertainty Estimates
https://arxiv.org/abs/2008.10546
觉得有用麻烦给个在看啦~ 