MEE: A Novel Multilingual Event Extraction Dataset 论文解读
MEE: A Novel Multilingual Event Extraction Dataset

paper:[2211.05955] MEE: A Novel Multilingual Event Extraction Dataset (arxiv.org)
code:None
期刊/会议:EMNLP 2022
摘要
事件抽取(EE)是信息抽取(IE)的基本任务之一,旨在从文本中识别事件提及及其论点(即参与者)。由于其重要性,已经为事件抽取开发了广泛的方法和资源。然而,当前EE研究的一个局限性涉及对非英语语言的探索不足,其中缺乏用于模型训练和评估的高质量多语言EE数据集是主要障碍。为了解决这一限制,我们提出了一种新的多语言事件抽取数据集(MEE),该数据集以8种不同类型的语言为超过50K个事件提及提供标注。MEE全面标注实体提及、事件触发词和事件论元的数据。我们对所提出的数据集进行了广泛的实验,以揭示多语言EE面临的挑战和机遇。
1、简介
事件抽取(EE)是文本信息抽取(IE)的主要任务之一。在完整的EE pipline方法中,应追求三个主要目标:(1)实体提及检测(EMD):识别真实世界实体的提及;(2) 事件检测(ED):识别事件提及/触发词及其类型。事件触发词是指最清楚地表示事件发生的单词或短语;以及(3)事件论元抽取(EAE):查找文本中提到的事件的参与者/论元。参与者是在给定事件提及中具有特定角色的实体提及。例如,在“The soldiers were hit by the forces.”一句中,有两个实体提到“soldiers”和“forces”类型的PERSON和ORGANIZATION,以及一个事件触发器“hit”类型的ATTACK。此外,这两个事件提到“soldiers”和“forces”在ATTACK事件中分别扮演Victim和Attacker的角色。一个EE系统将被应用到其他下游任务,如问答、知识库填充和文本摘要,以帮助抽取文本中事件的信息。
已经提出了多种用于事件提取的方法。早期的工作采用了基于特征的模型,而后来的方法探索了深度学习,以呈现最优的事件抽取性能。然而,尽管近年来在事件抽取方面取得了所有进展,但当前EE研究的一个主要局限是过度关注少数流行语言,因此未能充分揭示世界上许多其他语言中模型的挑战和泛化。因此,在多种语言上研究EE的一个关键障碍是缺乏高质量的数据集,这些数据集可以为EE的许多其他语言充分标注数据。例如,EE最流行的数据集,即ACE 2005,仅提供英语、中文和阿拉伯语三种语言的标注,而TAC KBP数据集仅支持英语、中文及西班牙语。TempEval-2数据集涉及6种语言;但是,它不提供事件论元标注。更糟糕的是,最近创建的数据集,例如MA VEN、RAMS和WikiEvents,只使用英语进行标注。总之,这种语言和任务限制阻碍了研究在不同语言和多语言环境下全面开发和评估EE方法。此外,这些数据集的有限大小,即ACE 2005和TempEval-2中分别小于11K和27K,阻碍了数据饥饿深度学习模型的训练。最后,我们注意到EE的重要多语言数据集,例如ACE 2005和TAC KBP,尚未公开,这进一步限制了该领域的研究。
为了解决这些局限性,在这项工作中,我们提出了一个大规模的多语言事件提取(MEE)数据集,该数据集涵盖了来自多个语系的8种不同类型的语言,包括英语、西班牙语、葡萄牙语、波兰语、土耳其语、印地语、韩语和日语。因此,葡萄牙语、波兰语、土耳其语、印地语和日语在流行的EE多语言数据集(即ACE 2005和TAC KBP)中没有被探索。重要的是,为了实现公共数据共享和数据的多样性,我们使用了8种语言的维基百科文章(即经济、政治、技术、犯罪、自然和军事)进行EE标注。
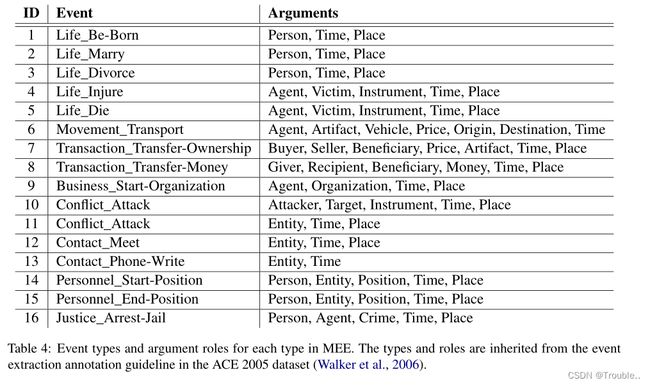
我们的数据集以一种语言对所有三个子任务EMD、ED和EAE的每个文档进行全面标注。为了与先前的EE研究保持一致,我们从ACE 2005数据集继承了此类任务的类型选集,该数据集为类型提供了精心设计的指南和示例。特别是,我们在MEE中包括7个实体类型、8个事件类型和16个事件子类型,以及23个论元角色,以便于在多种语言上进行EE标注。总体而言,我们的数据集涉及超过415K个实体提及、50K个事件触发词和38K个论元,这些数据集比以前的多语言EE数据集大得多,以更好地支持深度学习的模型训练和评估。
由于在所有语言中共享信息模式,我们的MEE数据集支持MEE模型的跨语言迁移学习评估,其中训练和测试数据来自不同语言。为此,我们对单语和跨语言学习环境进行了全面的实验,为特定语言的挑战和EE方法的跨语言泛化提供见解。通过检查EE的pipline和joint推理模型,我们的实验表明,所提出的数据集存在独特的挑战,现有EE模型的性能不太令人满意,特别是在跨语言环境下,因此需要在未来对多语言EE进行更多的研究。
2、数据标注
我们遵循流行的ACE 2005数据集中的实体/事件类型定义和标注准则,以从其精心设计的文档中获益,并与先前的EE研究保持一致。因此,实体提及是指文本中对现实世界实体的提及,可以通过名称、名词和代词来表达。实体提及抽取(EMD)比仅涉及实体名称的命名实体识别更通用。此外,事件被定义为其发生改变真实世界实体状态的事件。事件提及是指由两个组成部分组成的事件的输入文本部分:(1)事件触发词:最清楚地表示事件发生的单词。值得注意的是,我们允许事件触发词跨越多个单词,以适应多种语言的触发词标注。例如,在土耳其语短语“tayin etmek”中,这两个词都是表示类型为“Appoint”的事件触发词所必需的;以及(2)事件论元:实体提到了事件中涉及的一些角色。
基于ACE 2005数据集,我们的数据集标注了7种实体类型的实体提及: PERSON (human entities), ORGANIZATION (corporations, agencies, and other groups of people),GPE (geographical regions defined by political and/or social groups), LOCATION (geographical entities such as landmasses or bodies of water), FACILITY (buildings and other permanent manmade structures), VEHICLE (physical devices primarily designed to move an object from one location to another), and WEAPON (physical devices primarily used as instruments for physically harming)。对于事件类型,为了避免混淆并提高数据质量,我们对原始的ACE2005事件类型进行了删减,以仅包括跨多种语言不模糊的类型。例如,在土耳其语中,Sentence和Convict的事件类型非常相似(都可以由短语“Mahkum etmek”引起),因此它们不会保留在我们的数据集中。因此,我们保留了8个事件类型和16个子类型,这些类型对于数据集中的标注来说足够不同。最后,对于事件论元,我们保留了ACE 2005数据集中的所有23个论元角色。表4显示了事件类型列表及其在数据集中的论元角色。
2.1 数据准备
我们的数据集MEE涵盖8种不同的语言,即英语、西班牙语、葡萄牙语、波兰语、土耳其语、印地语、韩语和日语。这些语言是根据其多样性选择的类型及其相对于现有多语言EE数据集的新颖性。对于每种语言,我们都使用维基百科文章的最新转储作为标注的原始数据。为了关注事件数据,我们选择维基百科中事件类别下的子类别中的文章。特别是,以下子类别被认为可以提高话题的多样性:经济、政治、技术、犯罪、自然和军事。注意,我们从英语维基百科中的这些类别开始。之后,我们遵循不同语言类别之间的链接,以确定MEE中非英语语言维基百科的预期类别。
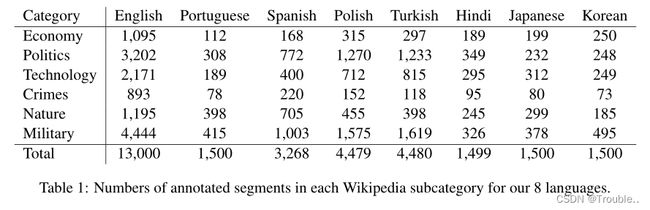
我们使用WikiExtractor工具处理收集的文章,以获得每篇文章的干净文本数据和元数据。然后,文本数据被拆分成句子,并由多语言NLP工具包Trankit标记为单词。之后,要用实体和事件提及对数据进行标注,一种方法是直接要求标注者完全阅读每篇文章进行标注。然而,由于维基百科中的文章可能很长,这种方法对标注者来说可能是压倒性的,从而阻碍了他们的注意力,降低了标注数据的质量。为了解决这个问题,我们遵循先前为EE创建数据集的努力,即RAMS,将文章分成五个连续句子的片段。然后将为EE任务单独标注每个段,这样标注者可以更好地捕获整个上下文,以提供实体和事件标注。注意,与RAMS类似,我们在每个事件触发词的文本段中标注所有事件论元,从而允许事件论元出现在与事件触发词不同的句子中(即文档级EAE)。最后,为了满足我们的预期,我们为每种语言获取了文本段样本,以供标注。表1显示了数据集中每种语言类别的选定文本段数量。
2.2 标注处理
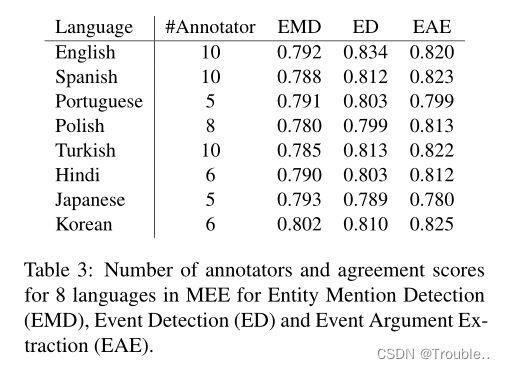
为了标注采样的文章片段,我们采用了众包平台upwork.com网站,允许我们在全球范围内雇佣具有不同专业知识的自由职业者。对于数据集中的每种语言,我们选择母语为母语的人作为标注者候选。此外,我们要求他们英语流利,有相关任务的经验(即信息提取的数据标注),且准确率高于95%(即在其个人资料中提供)。候选人首先获得英文标注指南和界面。之后,他们被邀请参加实体提及、事件触发词和论元的标注测试。然后,那些正确标注所有测试用例的候选人将被正式雇佣来从事我们的标注工作。表3显示了受雇者为数据集中的每种语言标注数据的数量。接下来,在实际的标注过程之前,英语标注指南和示例由雇佣的标注人员翻译成每种目标语言。任何特定于语言的混淆和标注规则都会被讨论并包含在翻译中,以形成共同的理解。最后,我们的语言专家将审查每种语言的标注指南,以避免用于实际标注的语言之间的冲突。
我们的标注过程分三个单独的步骤完成,以按照实体提及、事件触发词和事件论元的顺序标注三个EE任务的数据。特别是,后续任务的标注将在已为先前任务标注并最终确定的文本段上执行(例如,事件论元将在已提供实体提及和事件触发词的段上标注)。因此,对于每项任务,标注者将对每种语言的20%文本段进行共同标注,以衡量一致性得分。剩下的20%将被分段分给每一个标注者进行标注。基于Krippendorff的alpha和MASI距离度量,我们在表3中报告了每个任务和语言的标注者间一致性(IAA),显示了我们MEE数据集的高一致性分数和质量。请注意,在为每个EE任务独立标注之后,标注者还共享它们的标注并相互通信,以解决任何冲突并最终确定数据。
2.3 数据分析
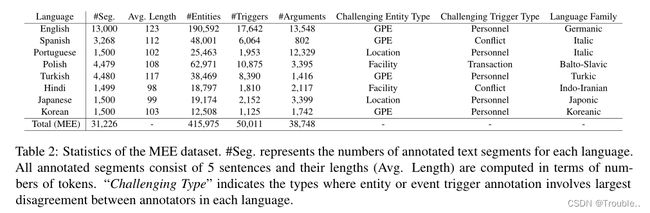
表2显示了每种语言的MEE主要统计数据。因此,与EE流行的多语言ACE 2005数据集相比,我们的MEE数据集提供了更多的语言(3 vs 8)和更多的事件提及(11K vs 50K)。对于EE的其他多语言数据集,即TAC KBP(具有三种语言和6.5K个事件提及)和TempEval-2(具有6种语言和27K个事件提到),它们不标注实体提及和事件论元。相比之下,我们的MEE数据集完全标注了三个EE任务(即EMD、ED和EAE)的文本,并且还有更多语言和事件提及。这清楚地表明了我们的数据集相对于现有的EE多语言数据集的优势。
此外,从表中我们发现数据集中的语言对于文本中的实体提及、事件触发词和论元表现出不同的密度。特别是,虽然葡萄牙语文本段中的实体平均数量为16.9个,但韩语中的实体数量仅为8.3个。对于事件密度,在波兰语中,每个文章段平均有2.4个事件提及,而韩语中的平均数量仅为0.75。同样,对于事件论元,每个事件的平均论元数量在葡萄牙语中为6.1,在英语中为0.75。
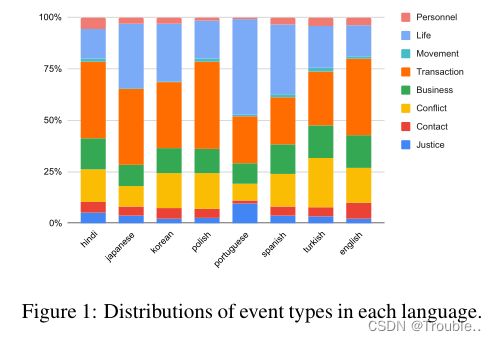
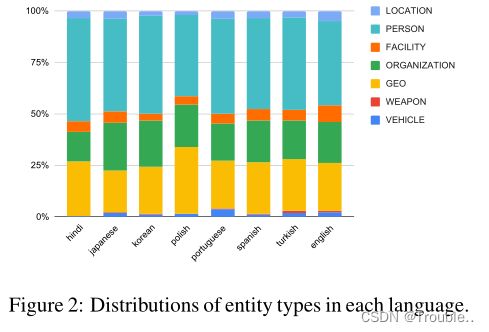
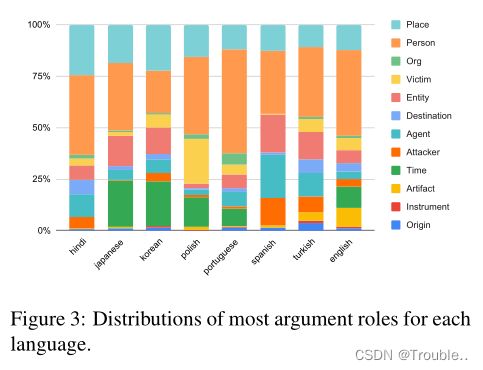
表2强调了语言之间在挑战性实体和事件类型方面的差异。具体来说,我们使用每个实体和事件类型的标注者之间的不一致率(即,不一致的数量除以提及的频率)。具有最高不一致率的类型被选为具有挑战性的实体或事件类型。最后,图2、图1和图3分别显示了数据集中每种语言的实体类型、事件类型和论元角色的分布,这进一步说明了MEE中语言之间的差异。总之,不同维度上的这种差异将给EE模型适应新语言(例如,跨语言迁移学习)带来重大挑战,从而为我们的数据集进行多语言EE研究提供了充足的机会。
3、实验
本节评估了事件抽取的最先进模型,以揭示我们新数据集MEE中的挑战。为此,MEE中每种语言的标注文章段被随机分成 train/dev/test 部分,比例为80/10/10。为了防止任何信息泄漏,我们确保文章的不同部分(如果有的话)只分配给每种语言数据分割的一部分。我们在两种不同的环境中考察EE模型:(1)单语学习,其中模型的训练和测试数据来自同一语言;(2) 跨语言迁移学习,其中模型基于一种语言(即源语言)的训练数据进行训练,但直接基于其他语言(即目标语言)的测试数据进行评估。
模型:在这项工作中,我们评估了两种具有pipline和joint推理的EE模型的典型方法。首先,对于pipline方法,分别为EE中的三个任务(即实体提及检测(EMD)、事件检测(ED)和事件论元抽取(EAE))中的每一个训练模型。这里,EMD和ED任务被建模为序列标注问题,旨在预测每个输入句子的BIO标签序列,以捕获实体和事件提及的跨度和类型。因此,受先前工作的启发,我们的EMD和ED模型利用预训练的基于transformer的语言模型来编码输入文本。然后将输入文本中每个token的表示(通过最后一个transformer层中的单词块的隐藏向量的平均值获得)发送到前馈网络中,以计算用于训练和解码的token的标签分布。对于EAE,任务被表述为文本分类问题,其中输入由输入文本和两个单词索引组成,用于事件触发词和感兴趣的实体提及的位置。目标是预测实体提及的事件所起的论证作用。为此,我们还使用预先训练的语言模型来获得输入文本中标记的表示。接下来,事件触发词和实体提及词的表示被连接起来并发送到前馈网络以预测论元角色。注意,EAE模型在训练过程中采用正确的实体提及和事件触发词,而EMD和ED模型的输出在测试时间被输入EAE模型。
其次,对于joint推理方法,EE模型以端到端的方式同时预测实体提及、事件触发词和论元,以避免错误传播并利用任务之间的相互依赖性。为此,我们评估了两个最先进的(SOTA)joint EE模型OneIE和FourIE,因为它们的语言不可知性。OneIE和FourIE都使用预先训练的语言模型来表示输入文本,并捕获跨任务依赖关系以进行联合推理。请注意,这些模型最初是为了包括实体之间的关系抽取任务而设计的。为了使它们适应EE,我们从原始论文中获得了它们的实现,并删除了关系抽取组件。最后,对于性能度量,我们使用与先前工作相同的正确性标准(即,需要对实体提及的偏移量和类型、事件触发词和论元角色进行正确预测),报告了三个任务EMD(实体)、ED(事件)和EAE(论元)上EE模型的性能(F1分数)。
超参数:为了促进多语言评估,我们利用多语言预训练语言模型(PLM)mBERT和XLM RoBERTa(base version)为EE模型编码文本。对于pipline方法,我们微调EMD、ED和EAE模型的超参数在英语的dev数据上,并将所选值应用于所有实验以保持一致性。特别是,我们的 pipline 模型超参数包括:2个隐藏层,每个层中有250个隐藏单元,用于前馈网络,8个用于小批量,1e-2用于Adam优化器的学习率。对于联合IE模型,我们使用了原始论文中建议的相同超参数,即OneIE和FourIE。
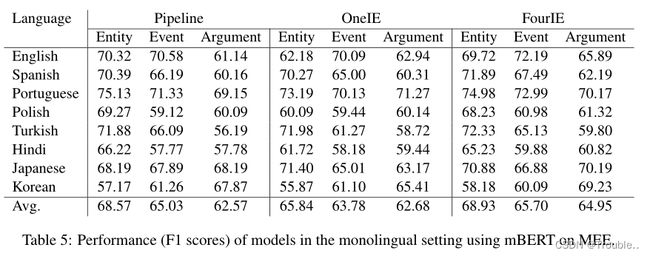
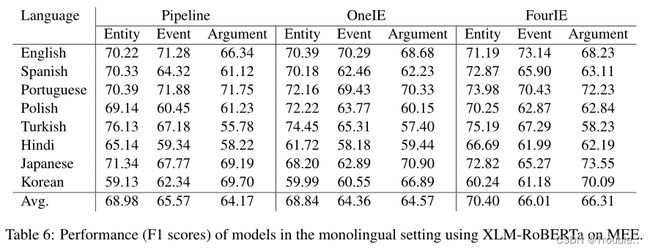
结果:MEE中不同语言的单语言实验结果如表5和表6所示(即,分别使用mBERT和XLMRoBERTa编码器)。表中有几个观察结果。首先,模型在单个语言上的性能以及在EMD、ED和EAE这三个任务上的平均性能仍然远远不够完美(即,所有平均性能都低于69%),因此表明我们的多语言EE数据集对于未来的研究具有相当大的挑战。此外,将当前最先进的joint IE模型(即FourIE)与流水线方法进行比较,我们发现FourIE平均优于pipline 模型,尤其是对于性能差距较大的EAE任务。因此,我们将此归因于联合模型减轻EMD和ED对EAE的错误传播以提高性能的能力。由于其最佳的平均性能,FourIE将在我们的下一个实验中发挥作用。最后,我们发现XLMRoBERTa通常比mBERT(即平均值)在EE模型中具有更好的性能。因此,未来的研究可以集中在XLM RoBERTa上,以开发用于多语言环境的更好的EE模型。
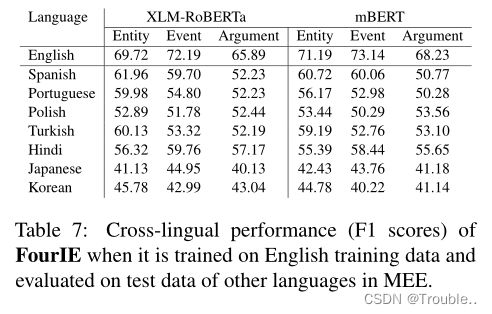
交叉语言评估:为了进一步了解MEE中的跨语言泛化挑战,表7报告了FourIE在跨语言迁移学习环境中的表现,其中模型在英语训练数据(源语言)上进行训练,并在其他语言的MEE测试数据上进行测试。可以看出,与英语测试集上的性能相比,FourIE在其他语言上进行评估时,在不同任务和多语言编码器上的性能显著下降。因此,它证明了完整EE模型的跨语言泛化的内在挑战,可以用MEE进一步研究。此外,跨语言测试导致的性能损失在不同的目标语言中有所不同(例如,在EAE任务中,西班牙语损失10.88%,而日语损失33.42%)。这些差异可归因于语言之间的不同程度的差异(例如,句子结构和形态),这些差异阻碍了EE的跨语言知识转移。
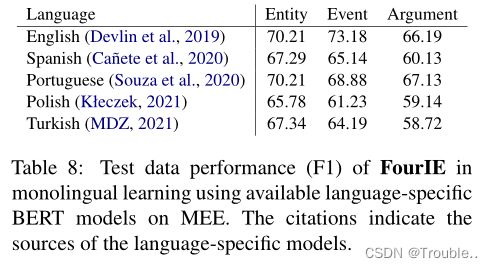
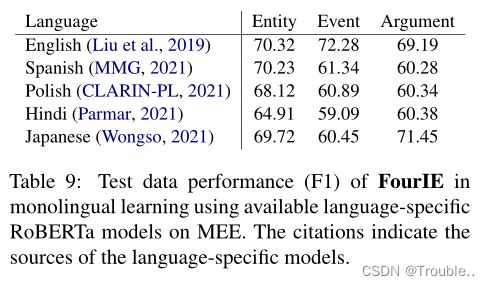
特定语言的编码器:为了研究预先训练的语言模型作为EE模型的文本编码器的有效性,我们比较了当多语言编码器mBERT或XLM RoBERTa替换为可对比的语言特定编码器(即,mBERT的基于BERT的模型和XLM RoBERTa的基于RoBERTa的模型)时FourIE的性能。使用MEE中公开的语言预训练语言模型,表8和表9分别显示了基于BERT和基于RoBERTa模型的语言在测试数据上的单语性能。比较表5、表6、表8和表9中的相应性能,很明显,特定于语言的语言模型在不同的EE任务和语言上都表现不佳,因此,建议使用多语言数据来训练语言模型编码器,以提高不同语言的EE性能。
源语言影响:最后,为了研究源语言对EE跨语言迁移学习的影响,我们比较了英语或其他对比语言作为源语言时FourIE的性能,以提供训练数据来训练模型。特别是,我们选择波兰语作为英语的对比语言,因为它具有相同的句子结构(即,两种语言都具有主语-动词-宾语顺序),并且实体/事件提及的密度和类型分布与英语相似。表10显示了在MEE中对其他6种语言的测试数据进行测试时模型的性能。这里,为了使其具有可比性,我们使用从英语和波兰语的训练数据中采样的相同数量的标注片段(即3500)来训练FourIE模型。有趣的是,我们发现,在大多数任务和目标语言对(即EMD和ED超过4种语言,EAE超过5种语言)中,波兰语比英语能为FourIE带来更好的表现。这个问题的一个可能的解释来自于波兰语可能引入的更丰富的事件模式,从而使EE的跨语言泛化能力优于英语。因此,波兰语的优异表现挑战了EE和NLP跨语言迁移学习中使用英语作为源语言的普遍做法。未来的研究可以探索这一方向,以更好地理解语言之间的差异,从而最佳地选择源语言,从而优化EE相对于目标语言的性能。
4、相关工作
由于其重要性,最近在不同领域为EE开发了各种数据集,包括CySecED(用于网络安全领域)、LitBank(用于识字)、MA VEN、RAMS和WikiEvents(用于维基百科文本)。然而,这些数据集仅针对英文文本进行标注。EE、ACE、TAC KBP和TempEval-2存在多个多语言数据集;然而,此类数据集仅为少数流行语言提供标注,事件提及次数有限,可能无法完全支持所有EE任务(例如,TAC KBP和TempEval-2中缺少EAE)。
关于模型开发,现有的EE方法可分为基于特征的或深度学习方法。尽管大多数现有的EE方法都是针对一种流行语言设计的,但在最近的工作中,人们对EE的多语言和跨语言学习越来越感兴趣,将多语言PLM(即mBERT和XLMR)作为表征学习的关键组成部分。然而,由于此类工作仅依赖于现有的多语言EE数据集,因此其评估仅限于少数几种流行语言,无法评估与许多其他语言相比的通用性。
5、总结
我们提出了一个新的多语言EE数据集,即MEE,该数据集涵盖了8种类型不同的语言,事件提及次数超过50K,以支持大型深度学习模型的训练。MEE为三个EE子任务提供了完整的标注,即实体提及检测、事件检测和事件论元抽取。为了研究MEE中的挑战,我们在单语和跨语言学习环境中使用不同的EE方法进行了广泛的分析和实验。我们的结果表明,在多语言环境中,EE面临各种挑战,MEE可以进一步解决这些挑战。未来,我们将扩展我们的数据集,为IE提供更多语言和任务。
限制
在这项工作中,我们提出了一个用于事件抽取的新型大规模多语言数据集。如实验所示,我们的数据集引入了许多挑战,可以为未来的多语言事件抽取研究提供信息。然而,目前的工作仍有一些局限性,可以在未来的研究中加以改进。首先,EE的跨语言迁移学习是一项具有挑战性的任务,需要专门设计的模型和方法。然而,在这项工作中,我们主要关注了最初为单语环境开发的现有最先进的EE模型。因此,未来的工作可以研究跨语言迁移模型,这些模型专门设计用于解决语言之间的差距,以更好地理解我们多语言EE数据集中的挑战。第二,除了多语言EE的数据稀缺之外,这个问题的另一个挑战是缺乏多语言文本编码和处理的资源。特别是,预训练语言模型和文本处理工具可能不适用于阻碍数据集创建和模型开发工作的某些语言(例如,低资源语言)。因此,我们的工作还没有探索用于EE的低资源语言的数据集和方法。此外,如我们的实验所示,大多数现有的特定于语言的文本编码器在EE模型中的性能都低于多语言编码器。然而,我们的工作还没有研究如何改进这种针对EE的语言模型。最后,尽管我们的实验从经验上挑战了英语作为跨语言学习的主要源语言,但我们没有探索为什么在这种情况下,其他语言可能是源语言的更好选择。未来的研究可以进行更全面的分析,以阐明这一方向。