怎样才能在自动驾驶任务中高效地利用时间轴上的信息进行视频检测?

目录
这篇论文究竟想解决什么样的问题?
我们要尊重时间轴上的因果关系
我们对实时性有要求
简单粗暴地只添加LSTM模块行不行?
我们简单地回顾一下LSTM的原理
LSTM的局限性
作者建议的模型是如何进行取舍的
基于光流的特征图扭曲
前置知识补充:通过运动补偿描述当前帧与参考帧之间的相关关系
利用深度学习模型光流网络进行运动补偿估算
按照提取特征方式的不同,光流网络有两种网络架构
精炼网络对特征图加工上采样,并进行预测
利用运动补偿的矢量图,对上一个时刻t-1的特征图进行扭曲
检测子网络
把之前步骤的特征图进行融合
利用R-FCN对融合的最终特征图进行目标检测
模型的性能
结论
最近读了《Modeling long- and short-term temporal context for video object detection》,这是一篇2019年刊登在IEEE上的CV论文。与解决普适性的CV任务不同,作者CHEN ZHANG和JOOHEE KIM希望分别针对长时上下文信息和短时上下文进行处理,高效利用好时间轴上的信息解决自动驾驶任务中的视频检测问题。
这篇论文究竟想解决什么样的问题?
我们要尊重时间轴上的因果关系
在自动驾驶任务中,车辆沿着道路驾驶的同时也是尊重沿着时间轴序列的原则。与离线的计算机视觉应用不同,在线实时的计算机视觉系统仅能够以过去的图像作为判断和决策的参考,它无法“作弊”地提前知道当前时间以后的图像。
正因为如此,我们设计用于自动驾驶任务中的计算机视觉系统必须是因果系统,这使得大量非因果系统的模型无用武之地。
我们对实时性有要求
此外,车辆驾驶的速度极快,这要求计算机视觉要有足够的“反应”灵敏度,给予系统在单位时间内能采集更多的图像特征,对预测结果进行参考,以及有更多的时间思考并进行决策。
使用摄像头对外界环境进行连续采样,如果我们仅仅利用与静态图像检测一样的方法,而不使用时间轴上的信息,那么当目标的外观变形或被遮挡时,检测性能将大大下降。相对地,我们把时间轴上的信息用起来固然能提升检测性能,不过要用多少,怎么用就成为了难题,因为这往往与时效性有着很大的关系。
截至论文发表时的时间点,根据作者调研:目前市面上最佳性能的视频目标检测模型,它们都需要每步处理多达6帧以上的相邻图像的。
那么,有没有这样子的一个模型:
它既是一个因果系统的模型,仅需要参考过往的历史图像信息;
它仅需要多处理一帧图像就能高效地利用视频的时间轴信息;
并且能达到有竞争力、甚至最佳的检测性能呢?
这正是这篇论文的作者要完成的挑战任务。
简单粗暴地只添加LSTM模块行不行?
LSTM,long short term menory,顾名思义,长短时记忆。 我们能不能简单粗暴地只添加这个模块来获取视频中的时间关联信息呢?
我们简单地回顾一下LSTM的原理
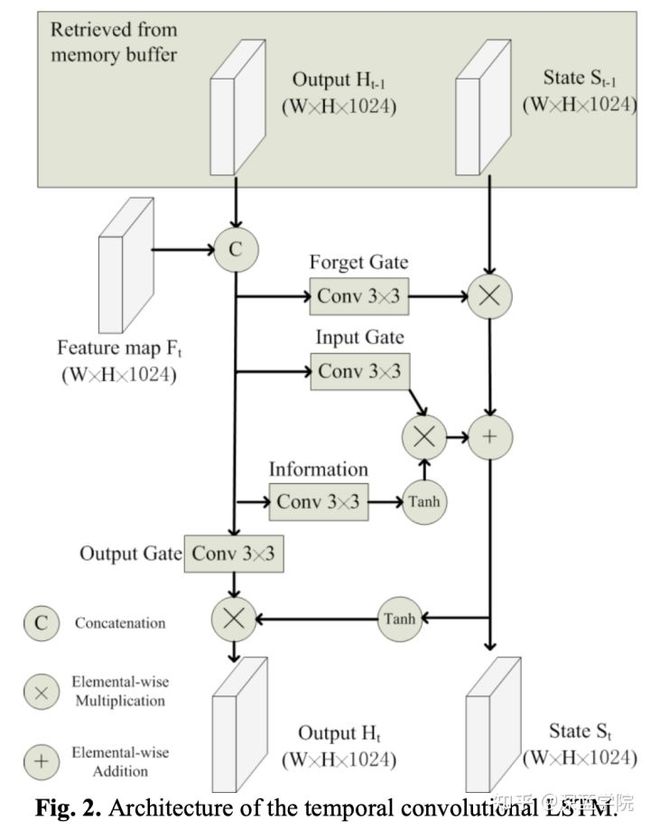
这是论文中谈及到的LSTM模型,

是上一个时刻t-1由LSTM输出的特征图,

是上一个时刻t-1由LSTM输出的记忆状态。
![]()
是当前时刻t输入的特征图。
在接下来的流程中,LSTM模块会做以下的事情:
1.决定保留上一个时刻t-1中多少的记忆
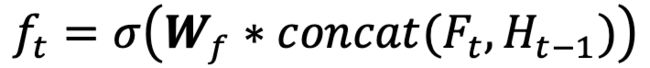
2.把当前时刻t的特征图和上一个时t-1的特征图进行加工,并决定有多少加工后的特征图添加到记忆
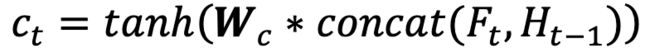
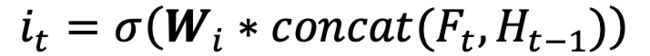
3.利用第一步和第二步的结果,更新当前时刻t的记忆
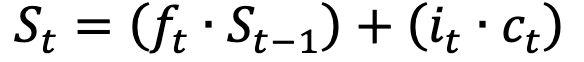
4.利用更新好的当前时刻t,与当前时刻t的特征图和上一个时t-1的特征图进行进行加工,得到当前时刻t的特征图输出
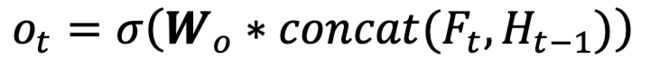
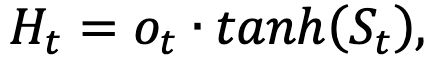
5.把当前时刻t的LSTM输出的特征图和记忆输入去下一个时刻t+1的LSTM中去。循环第一到第四步的操作。
我们可以看到,LSTM模块正是这样把特征图和记忆一步一步地随着时间轴路径传播下去的。
LSTM的局限性
从上文提及的LSTM原理中,我们步难发现了它的一些局限性:
如果我们过分关注过往的历史,那么当前这个时刻t的信息显著性就无法很好地传递
如果我们要更多地关注地关注历史,那么,这意味着我们要尽可能地增加
![]()
,减少记忆的遗忘。并且,为了促使历史记忆能更好地作用在当前时刻t的特征图输出上,
![]()
就会被需要被抑制,这使得当前时刻t的特征图进入记忆中的比重减少。
这样一来,随着时间上的传播,整体的历史记忆能得到重视,但如此同时,当前时刻t的信息显著性就没有办法高比重地传递到往后的时刻,因为记忆系统的信息流是单通道的。
如果我们过分关注当前时刻t附近的时间信息,那么历史的信息就会在接下来的传播中中断显著性
当我们想把当前时刻t的特征图信息尽可能多地更新到记忆,传递给往后的时刻时,这将使得
![]()
被压制,增大t-1以前记忆的遗忘。并且,
![]()
会需要尽可能增大,使得整个记忆系统中t-1以前的记忆比重迅速下降,t时刻的信息比重才能上升到某个占比。
此时,如果t+2想参考更多的历史记忆时就变得非常尴尬,因为历史记忆已经在t+1接收到时就已经被t时刻的比重进行了污染。
我们能不能建立多通道的LSTM?这显然脱离了我们对实时性的运算量要求。
作者建议的模型是如何进行取舍的
既然LSTM有一定的局限性,它无法同时处理好长时信息与短时信息,鱼与熊掌不可兼得的情况下,作者会如何处理,如何取长避短呢?
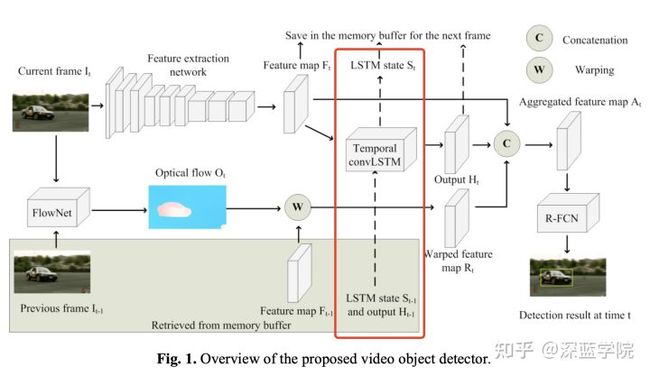
既然无法鱼与熊掌不可兼得,那么作者选择了让LSTM只做一个事情:在使用ResNet101作为骨干网络提取特征后,利用LSTM建模长时信息的历史记忆的传播。对于那些极端使用紧邻帧信息的情况,将交由其他模块进行处理。
在接下来,我们会马上看看作者使用传播短时记忆的模块——基于光流的特征图扭曲。利用相邻两帧图像的光流信息进行特征图预测,以此来建模短时信息的传播。
基于光流的特征图扭曲
论文中原文的描述是Modeling short-term temporal context using optical flow-based warping,此处意译为基于光流的特征图扭曲。
前置知识补充:通过运动补偿描述当前帧与参考帧之间的相关关系
在解读基于光流的特征图扭曲之前,我们先来补充一个前置知识。
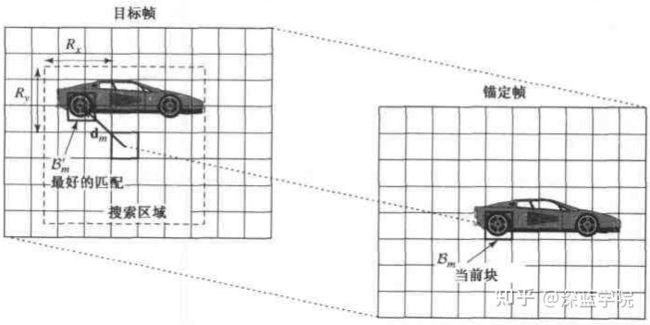
借用《视频处理与通信》(ISBN 7-5053-7635-7)的示意图,我们可以看到,在目标帧(参考帧)中的车后轮与锚定帧(当前帧)中车后轮存在一个位置关系,这个位置关系,我们可以通过一个矢量来描述,例如它从(3.5,3.5)移动到了(5,5),矢量为(1.5,1.5)。
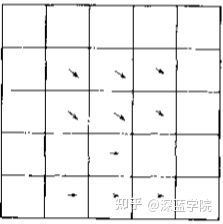
如果我们对每一个块进行计算,就可以得到一张运动补偿的矢量图。
再如,我们看看下面的两张图,

如果我们对他们的相关关系进行高密度的运算评估,那么,仅仅利用参考帧和矢量图,我们是可以很好地还原出当前帧的效果的:
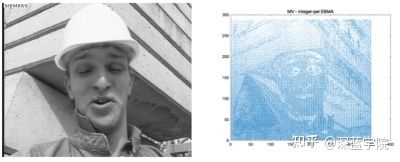
如上图,这是基于像素级别的矢量描述,利用参考帧来还原当前帧。
值得注意的是,这种估算方式是有三个很强烈的前提假设的:
1.当前帧与参考帧之间的亮度恒定。
2.当前帧与参考帧的取帧时间连续,或者,当前帧与参考帧之间物体的运动比较“微小”。
3.保持空间一致性;即,同一子图像的像素点具有相同的运动。
利用深度学习模型光流网络进行运动补偿估算
作者使用了光流网络对当前帧和参考帧进行运动补偿估算,这是一个端到端的深度学习模型,引用自另外一篇论文《FlowNet: Learning Optical Flow with Convolutional Networks》。为了更好地联系上下文,我们也对此进行必要性的附带解读。
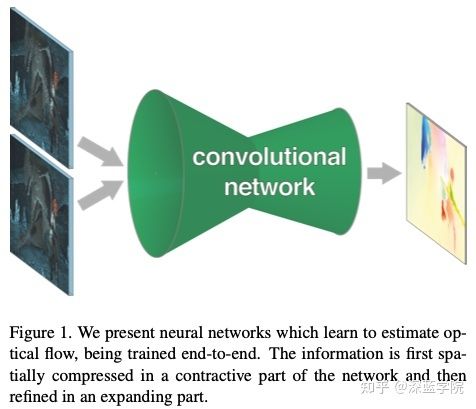
光流网络的思想是,把当前帧和参考帧送进一个CNN网络,然后网络对图像进行逐像素的预测,最终得到运动补偿的矢量信息。
按照提取特征方式的不同,光流网络有两种网络架构
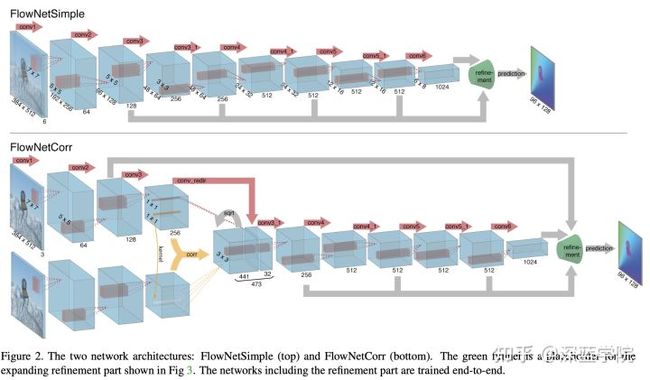
FlowNetSimple
FlowNetSimple在开始的阶段,就把384*512*3的当前帧和参考帧在通道维度上拼接在一起384*512*6,然后送进特征提取网络,最后得到一个6*8*1024的特征图,准备送入提炼网络。
FlowNetCorr
FlowNetCorr在开始阶段,先分别对384*512*3的当前帧和参考帧进行初步的特征提取,然后在48*64*256的阶段进行融合,之后对融合后的特征图进行进一步的处理。最后同样得到一个6*8*1024的特征图,准备送入提炼网络。
精炼网络对特征图加工上采样,并进行预测
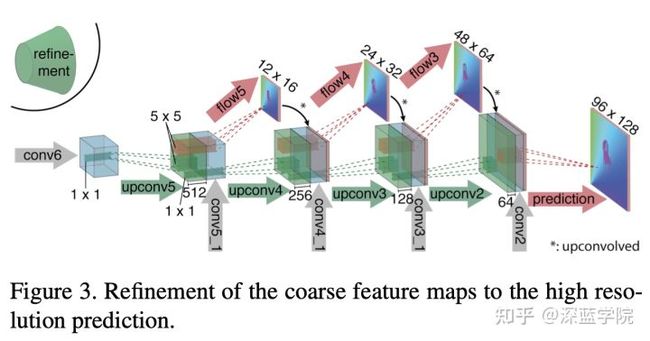
在进行上采样的阶段,除了通过反卷积进行上采样外,还会把之前提取特征阶段时对应分辨率的浅层特征图进行通道上的拼接。重复这个步骤4次最终得到96*128的特征图。此时,特征图和最终输入的384*512还相差4倍。经过实验表明,这个阶段的特征图通过双线性差值还原,最终也能得到不错的预测性能。
此时,我们通过预测,得到了当前帧和参考帧运动补偿的矢量图。
利用运动补偿的矢量图,对上一个时刻t-1的特征图进行扭曲
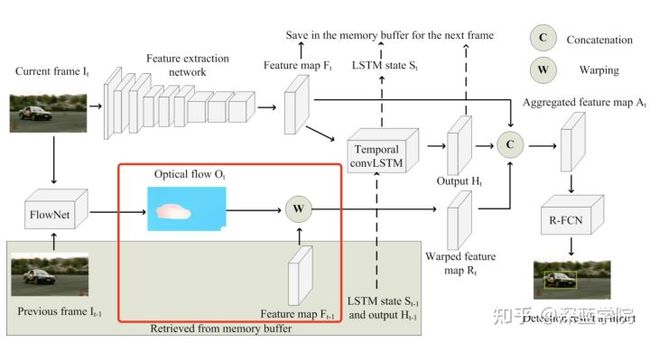
通过FlowNet,我们得到了运动补偿的矢量图,这里也被称为光流图
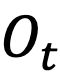
。我们假设当前帧和参考帧图像内容的运动变化应该能反映在特征图上对应的位置变化上。于是,我们用光流图
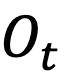
和上一个时刻t-1的特征图
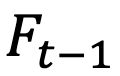
来求解扭曲后的新特征图
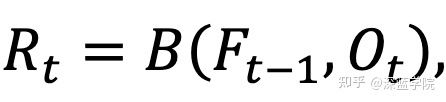
由于光流图里面的矢量数据可能是浮点数,于是,在实际处理时,会采取双线形插值:
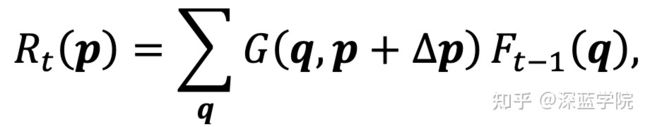
其中,

是特征图
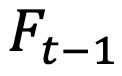
上的所有位置坐标,
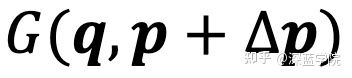
是双线形插值的核,它的表达式为:
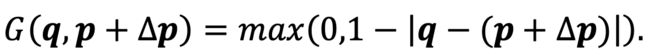
,对特征图的加工和修正,就正是论文中要表达的,基于光流的特征图扭曲,借此得到了短时的上下文信息。
结合LSTM和FlowNet基于光流的特征图扭曲,现在我们成功地分别获得了长时的上下文信息和短时的上下文信息了。而由始至终,我们仅需要在每一步多处理了一帧图像。
检测子网络
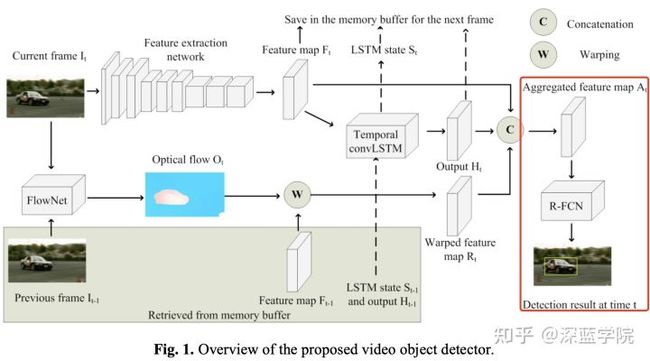
把之前步骤的特征图进行融合
在送检测子网络之前,首先需要把骨干网络输出的特征图(当前时刻t的特征图),LSTM输出的特征图(长时的上下文信息),以及基于光流的特征图扭曲(短时的上下文信息)进行融合,这里作者使用的是通道拼接的方式完成这个步骤。
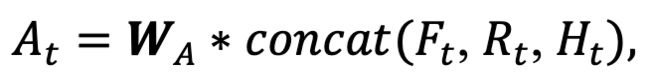
在拼接后,再通过一个1*1的卷积核把特征图降维成1024的通道数,以便减少后续进入R-FCN时的运算量。
利用R-FCN对融合的最终特征图进行目标检测
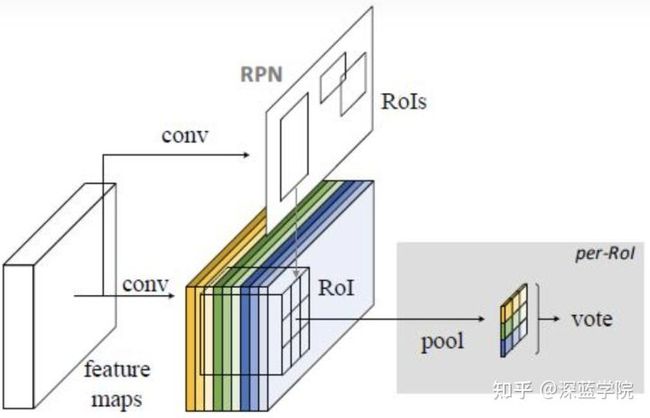
送入的特征图会经历,
RPN:对特征图生成粗糙的锚框。
Detector:利用这个粗糙的锚框进行物体检测并生成热点图。
最终,通过热点图得到目标检测的锚框回归坐标以及锚框内的物体分类预测。
模型的性能
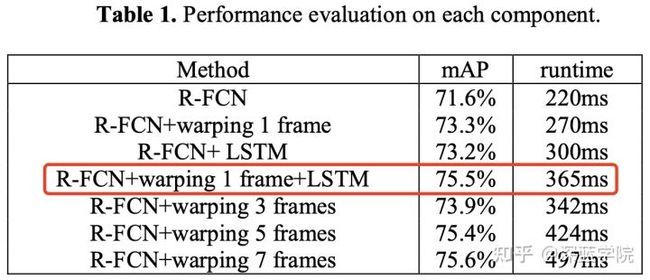
作者建议的模型中,每一步仅多处理了一帧图像。在实时性上,与单纯采取对静态图像进行目标检测的R-FCN模型相比需要增加约50%的处理时间;而与R-FCN+LSTM相比需要增加约25%的处理时间。
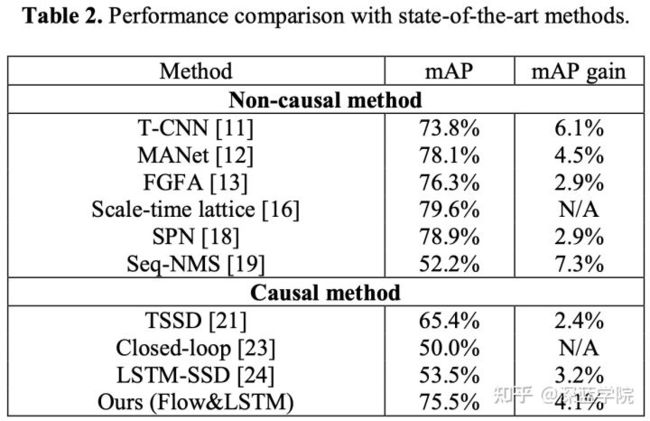
截至论文发表的时间点,在ImageNet VID数据集上,作者建议的模型在当时的因果模型中取得了最佳的检测性能。而与非因果模型对比,也依然能得到非常有竞争力的检测性能。
结论
《Modeling long- and short-term temporal context for video object detection》的作者CHEN ZHANG和JOOHEE KIM建议了一个用于自动驾驶的视频目标检测模型,它通过LSTM获取视频长时的上下文信息,通过基于光流的特征图扭曲获取视频短时的上下文信息。这些上下文信息结合当前时刻t的特征图,在每步仅需要处理多一帧过去时刻t-1的图像的策略上,取得了实效性和检测性能的平衡,并在论文发表时成为当时因果模型中检测性能最佳的视频检测模型。