SpringCloudAlibaba-Seata
Seata
简介
分布式事务
事务是数据库的概念,数据库事务(ACID:原子性、一致性、隔离性和持久性);
分布式事务的产生,是由于数据库的拆分和分布式架构(微服务)带来的,在常规情况下,我们在一个进程中操作一个数据库,这属于本地事务,如果在一个进程中操作多个数据库,或者在多个进程中操作一个或多个数据库,就产生了分布式事务;
(1)数据库分库分表就产生了分布式事务;
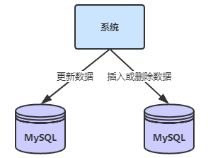
(2)项目拆分服务化也产生了分布式事务;
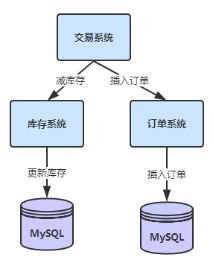
Seata
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务;
Seata为用户提供了AT、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案;
四种事务模式中,XA模式正在开发中…,其他事务模式已经实现;
目前使用的流行度情况是:AT > TCC > Saga;
我们可以参看seata各公司使用列表:
https://github.com/seata/seata/issues/1246 大部分公司都采用的AT事务模式;
Seata已经在国内很多团队开始落地,其中不乏有大公司;
Github:https://github.com/seata/seata
官网:http://seata.io/
在Seata的架构中,一共有三个角色:
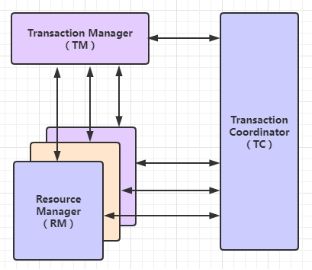
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚;
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务;
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交互以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚;
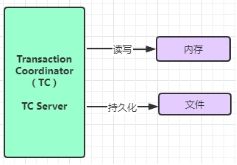
其中TC为单独部署的 Server 服务端,TM和RM为嵌入到应用中的 Client 客户端;
在Seata中,一个分布式事务的生命周期如下:
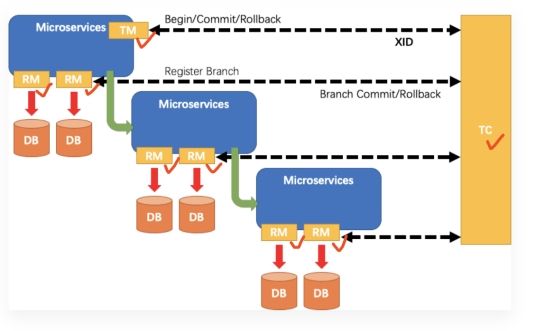
TM请求TC开启一个全局事务,TC会生成一个XID作为该全局事务的编号,XID会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起;
RM请求TC将本地事务注册为全局事务的分支事务,通过全局事务的XID进行关联;
TM请求TC告诉XID对应的全局事务是进行提交还是回滚;
TC驱动RM将XID对应的自己的本地事务进行提交还是回滚;
TC Server(Seata)运行环境部署
我们先部署单机环境的 Seata TC Server,用于学习或测试,在生产环境中要部署集群环境;
因为TC需要进行全局事务和分支事务的记录,所以需要对应的存储,目前,TC有三种存储模式( store.mode ):
file模式:适合单机模式,全局事务会话信息在内存中读写,并持久化本地文件 root.data,性能较高;
db模式:适合集群模式,全局事务会话信息通过 db 共享,相对性能差点;
redis模式:解决db存储的性能问题;
我们先采用file模式,最终我们部署单机TC Server如下图所示:
下载Seata:http://seata.io/zh-cn/blog/download.html
解压:tar -zxvf seata-server-1.3.0.tar.gz
切换cd seata
默认seata-server.sh脚本设置的jvm内存参数2G,我们再虚拟机里面做实验,可以改小一点;

在bin目录下启动:./seata-server.sh
默认配置下,Seata TC Server 启动在 8091 端口;
因为我们没有修改任何配置文件,默认情况seata使用的是file模式进行数据持久化,所以可以看到用于持久化的本地文件 root.data;
AT模式事务案例-单体应用多数据源分布式事务
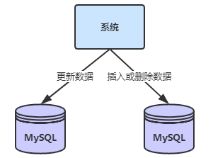
在Spring Boot单体项目中,如果使用了多数据源,就需要考虑多个数据源的数据一致性,即产生了分布式事务的问题,我们采用Seata的AT事务模式来解决该分布式事务问题;
以电商购物下单为例:
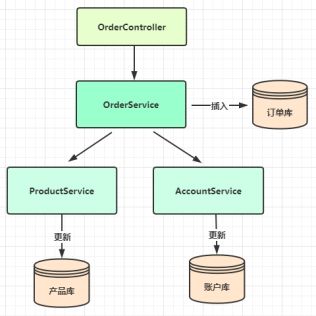
1、准备数据库表和数据;
其中每个库中的undo_log表,是 Seata AT模式必须创建的表,主要用于分支事务的回滚;
2、开发一个SpringBoot单体应用;
测试:http://localhost:8080/order?userId=1&productId=1
AT模式事务案例-微服务的分布式事务
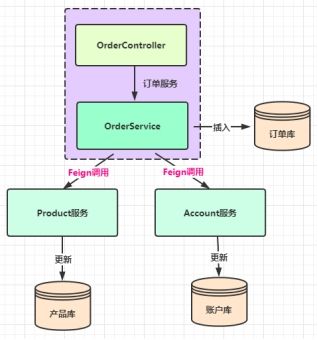
tips:异常部分如果使用try-catch进行捕获,则Seata不会检测到异常也就不会进行事务回滚
AT事务模式分布式事务工作机制
前提
基于支持本地 ACID 事务的关系型数据库;(mysql、oracle)
Java 应用,通过JDBC访问数据库;
整体机制
就是两阶段提交协议的演变:
一阶段:
“业务数据“和“回滚日志记录“在同一个本地事务中提交,释放本地锁和连接资源;
二阶段:
如果没有异常异步化提交,非常快速地完成;
如果有异常回滚通过一阶段的回滚日志进行反向补偿;
具体举例说明整个AT分支的工作过程:
业务表:product
*Field* *Type* *Key*
id bigint(20) PRI
name varchar(100)
since varchar(100)
AT分支事务的业务逻辑:
update product set name = ‘GTS’ where name = ‘TXC’;
一阶段过程:
1、解析SQL,得到SQL的类型(UPDATE),表(product),条件(where name = ‘TXC’)等相关的信息;
2、查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据;
select id, name, since from product where name = ‘TXC’;
得到前镜像:
id name since
1 TXC 2014
3、执行业务 SQL:更新这条记录的 name 为 ‘GTS’;
4、查询后镜像:根据前镜像的结果,通过 主键 定位数据;
select id, name, since from product where id = 1;
得到后镜像:
id name since
1 GTS 2014
5、插入回滚日志:把前后镜像数据以及业务SQL相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中;

6、分支事务提交前,向TC注册分支,申请product表中,主键值等于1的记录的全局锁(在当前的同一个全局事务id范围内是可以申请到全局锁的,不同的全局事务id才会排斥);
7、本地事务提交:业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交;
8、将本地事务提交的结果上报给TC;
二阶段-回滚
1、收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作;
2、通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录;
3、数据校验:拿 UNDO LOG 中的后镜像与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改,这种情况,需要人工来处理;
4、根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句:
update product set name = ‘TXC’ where id = 1;
5、提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC;
二阶段-提交
1、收到TC的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给TC;
2、异步任务阶段的分支提交请求将异步和批量地删除相应UNDO LOG记录;
回滚日志表:
*Field* *Type*
branch_id bigint PK
xid varchar(100)
context varchar(128)
rollback_info longblob
log_status tinyint
log_created datetime
log_modified datetime
SQL建表语句:
CREATE TABLE `undo_log` (
`id` bigint NOT NULL AUTO_INCREMENT,
`branch_id` bigint NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
AT事务模式运行机制解读
AT 模式的前提:
1、基于支持本地 ACID 事务的关系型数据库;
2、Java 应用,通过 JDBC 访问数据库;
整体机制是两阶段提交协议的演变:
一阶段:
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源;(本地事务,就已经在数据库持久化了)
二阶段:
如果没有异常提交异步化,非常快速地完成;(正常情况,那就提交了,同步一下TC Server的状态,删除回滚日志)
如果有异常回滚通过一阶段的回滚日志进行反向补偿;(比如订单删除,库存加回去,余额加回去);
AT事务模式数据隔离
写隔离
一阶段本地事务提交前,需要确保先拿到全局锁;
拿不到 全局锁 ,不能提交本地事务;
拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁;
以一个示例来说明:
两个或者多个全局事务 tx1 和 tx2,分别并发对 a 表的 m 字段进行更新操作,m 的初始值 1000;
假设tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900,本地事务提交前,先拿到该记录的 全局锁 ,拿到了全局锁,本地提交并释放本地锁;
tx2后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800,本地事务提交前,尝试拿该记录的 全局锁 ,tx1全局提交前,该记录的全局锁一直会被 tx1 持有,tx2 需要重试等待 全局锁 ;
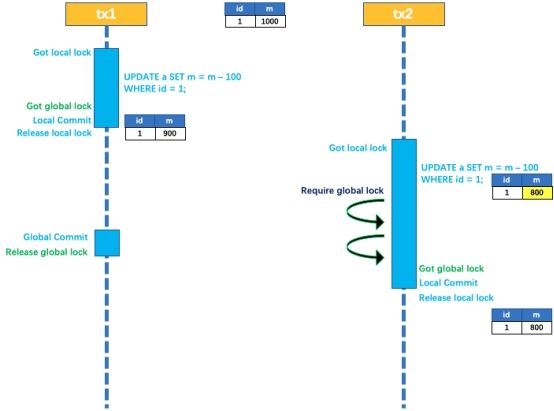
tx1 二阶段全局提交,释放 全局锁 ,tx2 拿到 全局锁 提交本地事务;
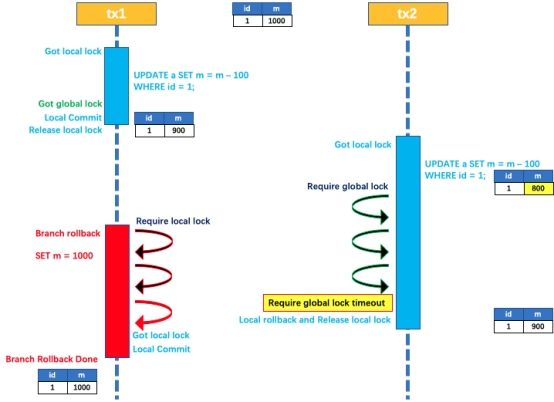
如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚;
此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功;
因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题;
读隔离
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是读未提交**(Read Uncommitted)**
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理;
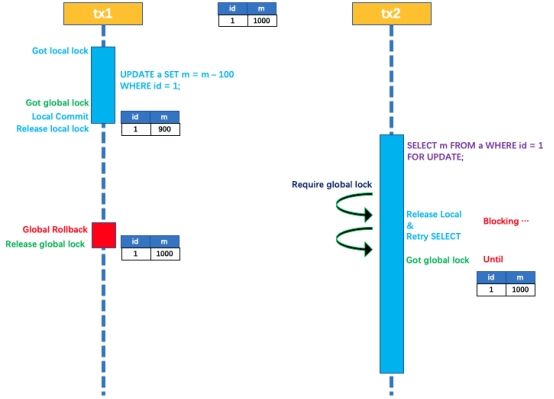
SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试,这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回;
出于总体性能上的考虑,Seata目前的方案并没有对所有SELECT语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句;
Seata TC Server集群部署
生产环境下,需要部署集群 Seata TC Server,实现高可用,在集群时,多个 Seata TC Server 通过 db 数据库或者redis实现全局事务会话信息的共享;
每个Seata TC Server注册自己到注册中心上,应用从注册中心获得Seata TC Server实例,这就是Seata TC Server的集群;
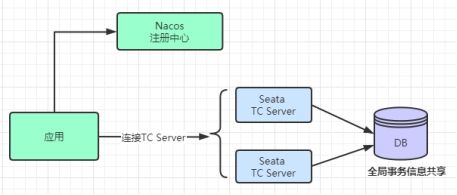
Seata TC Server 对主流的注册中心都提供了集成,Naco作为注册中心越来越流行,这里我们就采用Nacos;
Seata TC Server集群搭建具体步骤:
1、下载并解压两个seata-server-1.3.0.tar.gz;
2、初始化 Seata TC Server 的 db 数据库,在 MySQL 中,创建 seata 数据库,并在该库下执行如下SQL脚本:
使用seata-1.3.0\script\server\db脚本(网盘有共享)
3、修改 seata/conf/file.conf 配置文件,修改使用 db 数据库,实现 Seata TC Server 的全局事务会话信息的共享;
(1)mode = “db”
(2)数据库的连接信息
driverClassName = "com.mysql.cj.jdbc.Driver"
url = "jdbc:mysql://39.99.163.122:3306/seata"
user = "mysql"
password = "UoT1R8[09/VsfXoO5>6YteB"
4、设置使用 Nacos 注册中心;
修改 seata/conf/registry.conf 配置文件,设置使用 Nacos 注册中心;
(1)type = “nacos”
(2)Nacos连接信息:
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
username = ""
password = ""
}
5、启动数据库和nacos;
6、启动两个 TC Server
执行 ./seata-server.sh -p 18091 -n 1 命令,启动第一个TC Server;
-p:Seata TC Server 监听的端口;
-n:Server node,在多个 TC Server 时,需区分各自节点,用于生成不同区间的 transactionId 事务编号,以免冲突;
执行 ./seata-server.sh -p 28091 -n 2 命令,启动第二个TC Server;
7、打开Nacos注册中心控制台,可以看到有两个Seata TC Server 实例;
8、应用测试;
对于SpringBoot单体应用:
1、添加nacos客户端依赖;
<dependency>
<groupId>com.alibaba.nacosgroupId>
<artifactId>nacos-clientartifactId>
<version>1.3.1version>
dependency>
2、配置application.properties文件
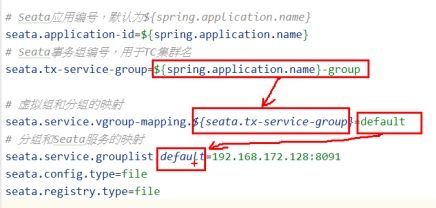
#----------------------------------------------------------# Seata**应用编号,默认为**${spring.application.name}**
seata.application-id=springcloud-order-seata
# Seata**事务组编号,用于**TC**集群名**
seata.tx-service-group=springcloud-order-seata-group
#* *虚拟组和分组的映射**
seata.service.vgroup-mapping.springcloud-order-seata-group=default
#seata-spring-boot-starter 1.1**版本少一些配置项**
seata.enabled=true
seata.registry.type=nacos
seata.registry.nacos.cluster=default
seata.registry.nacos.server-addr=192.168.172.128:8848
seata.registry.nacos.group=SEATA_GROUP
seata.registry.nacos.application=seata-server
#----------------------------------------------------------
对于Spring Cloud Alibaba微服务应用:
则不需要加nacos的jar包依赖,application.properties文件配置完全一样;
TCC事务模式执行机制
AT模式基本上能满足我们使用分布式事务大部分需求,但涉及非关系型数据库与中间件的操作、跨公司服务的调用、跨语言的应用调用就需要结合TCC模式;
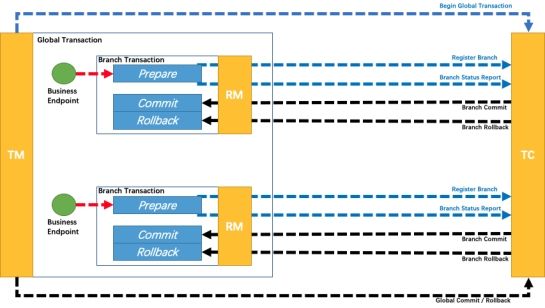
一个分布式的全局事务,整体是两阶段提交(Try - [Comfirm/Cancel])的模型,在Seata中,AT模式与TCC模式事实上都是基于两阶段提交,它们的区别在于:
AT模式基于支持本地ACID事务的关系型数据库:
1、一阶段prepare行为:在本地事务中,一并提交“业务数据更新“和”相应回滚日志记录”;
2、二阶段 commit 行为:马上成功结束,自动异步批量清理回滚日志;
3、二阶段 rollback 行为:通过回滚日志,自动生成补偿操作,完成数据回滚;
而TCC 模式,需要我们人为编写代码实现提交和回滚:
1、一阶段 prepare 行为:调用自定义的 prepare 逻辑;(真正要做的事情,比如插入订单,更新库存,更新余额)
2、二阶段 commit 行为:调用自定义的 commit 逻辑;(自己写代码实现)
3、二阶段 rollback 行为:调用自定义的 rollback 逻辑;(自己写代码实现)
所以TCC模式,就是把自定义的分支事务的提交和回滚并纳入到全局事务管理中;
通俗来说,Seata的TCC模式就是手工版本的AT模式,它允许你自定义两阶段的处理逻辑而不需要依赖AT模式的undo_log回滚表;
TCC事务模式应用实践
基于SpringBoot单体应用的TCC事务
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6ivRMAch-1628737977796)(E:\software\JAVA\springcloud-alibaba\document\动力节点spring cloud alibaba\wps7-1627612492997.jpg)]
@LocalTCC
public interface AccountService {
*/****
\* *** *扣除余额**
\* *** *定义两阶段提交**
\* ** name = reduceStock**为一阶段**try**方法**
\* ** commitMethod = commitTcc* *为二阶段确认方法**
\* ** rollbackMethod = cancel* *为二阶段取消方法**
\* ** BusinessActionContextParameter**注解 可传递参数到二阶段方法**
\* ****
\* ** @param* *userId* *用户**ID**
\* ** @param* *money* *扣减金额**
\* ** @throws* *Exception* *失败时抛出异常**
\* **/**
@TwoPhaseBusinessAction(name = "reduceBalance", commitMethod = "commitTcc", rollbackMethod = "cancelTcc")
void reduceBalance(@BusinessActionContextParameter(paramName = "userId") Integer userId,
@BusinessActionContextParameter(paramName = "money") BigDecimal money);
*/****
\* *** *确认方法、可以另命名,但要保证与**commitMethod**一致**
\* ** context**可以传递**try**方法的参数**
\* ****
\* ** @param* *context* *上下文**
\* ** @return boolean**
\* **/**
boolean commitTcc(BusinessActionContext context);
*/****
\* *** *二阶段取消方法**
\* ****
\* ** @param* *context* *上下文**
\* ** @return boolean**
\* **/**
boolean cancelTcc(BusinessActionContext context);
}
@LocalTCC注解标识此TCC为本地模式,即该事务是本地调用,非RPC调用,@LocalTCC一定需要注解在接口上,此接口可以是寻常的业务接口,只要实现了TCC的两阶段提交对应方法即可;
@TwoPhaseBusinessAction,该注解标识为TCC模式,注解try方法,其中name为当前tcc方法的bean名称,写方法名便可(全局唯一),commitMethod指提交方法,rollbackMethod指事务回滚方法,指定好三个方法之后,Seata会根据事务的成功或失败,通过动态代理去帮我们自动调用提交或者回滚;
@BusinessActionContextParameter 注解可以将参数传递到二阶段(commitMethod/rollbackMethod)的方法;
BusinessActionContext 是指TCC事务上下文,携带了业务方法的参数;
基于Spring Cloud Alibaba的TCC分布式事务
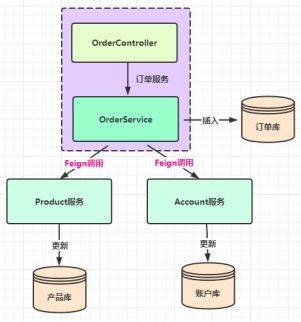
具体代码实现和springboot单体应用的代码实现几乎没有区别,具体参考Git上提交的代码;
由于Seata出现时间并不长,也在不断的改进中,在实际面试中应该不会问大家比较底层的实现,同学们如果感兴趣的话,基于我们已有的源码阅读经验,可以看一下Seata的源码,它如何进行事务隔离保证数据一致性,官方提供的文档并不详细;
n,该注解标识为TCC模式,注解try方法,其中name为当前tcc方法的bean名称,写方法名便可(全局唯一),commitMethod指提交方法,rollbackMethod指事务回滚方法,指定好三个方法之后,Seata会根据事务的成功或失败,通过动态代理去帮我们自动调用提交或者回滚;
@BusinessActionContextParameter 注解可以将参数传递到二阶段(commitMethod/rollbackMethod)的方法;
BusinessActionContext 是指TCC事务上下文,携带了业务方法的参数;
基于Spring Cloud Alibaba的TCC分布式事务
[外链图片转存中…(img-Kv8vbK90-1628737977798)]
具体代码实现和springboot单体应用的代码实现几乎没有区别,具体参考Git上提交的代码;
由于Seata出现时间并不长,也在不断的改进中,在实际面试中应该不会问大家比较底层的实现,同学们如果感兴趣的话,基于我们已有的源码阅读经验,可以看一下Seata的源码,它如何进行事务隔离保证数据一致性,官方提供的文档并不详细;