一文详解百度、谷歌、京东、腾讯在分布式网络训练下的联邦学习解决方案

fedprox | fedavg | 联邦学习
机器学习 | 差分隐私 | 分布式网络训练
随着机器学习、隐私计算、高性能计算、深度学习训练、差分隐私的快速发展,如今的人工智能仍然面临两大挑战。一是在大多数行业中,数据以孤岛的形式存在;另一个是加强数据隐私和安全。为这些挑战提出了一个可能的解决方案:安全联邦学习。其中包括横向联邦学习、纵向联邦学习和联邦迁移学习。
联邦学习(Federated Learning)是一种分布式机器学习技术,其核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练,在不需要交换本地个体或样本数据的前提下,仅通过交换模型参数或中间结果的方式,构建基于虚拟融合数据下的全局模型,从而实现数据隐私保护和数据共享计算的平衡,即“数据可用不可见”、“数据不动模型动”的应用新范式。许多客户端(例如移动设备或整个组织)在中央服务器(例如服务提供商)的编排下协同训练一个模型,同时保持训练数据的分散。联邦学习体现了集中数据收集和最小化的原则,可以减轻许多由传统的、集中的机器学习和数据科学方法造成的系统性隐私风险和成本。
联邦学习涉及在大规模分布式网络中训练机器学习模型。虽然联合平均(fedavg)是在此设置中训练非凸模型的主要优化方法,但在跨统计异构设备(即每个设备以非相同的时尚。众所周知的 fedprox 框架来解决统计异质性,它包含了 fedavg 作为一个特例。通过一种新颖的设备相异性假设为 fedprox 提供收敛保证,能够表征网络中的异质性,最后,对一套联合数据集进行了详细的实证评估,证明了广义 fedprox 框架相对于 fedavg 在异构网络中学习的鲁棒性和稳定性有所提高。

联邦学习科研论文成果现状
一、论文发表量复合年增长率为 40%
基于 AMiner 系统,通过关键词组在标题和摘要中检索 2016 年至 2021 年论文数据。结果显示,研究时段内联邦学习相关论文共计 4576 篇, 自 2016 年被提出以来,研究论文数量逐年增多, 到 2021 年的复合年增长率为 40.78%,相关论文趋势如下图所示。

联邦学习研究论文趋势(2016-2021 年)
二、论文发布量以中美两国为引领
根据论文作者所在机构所属国家进行排序分析,发现近年来联邦学习论文发布量 TOP 10 国家依次是中国、美国、英国、俄罗斯、德国、印度、澳大利亚、加拿大、日本和法国。相关论文量较突出的国家是中国(1245 篇)和美国(1175 篇)详细信息如下图所示。
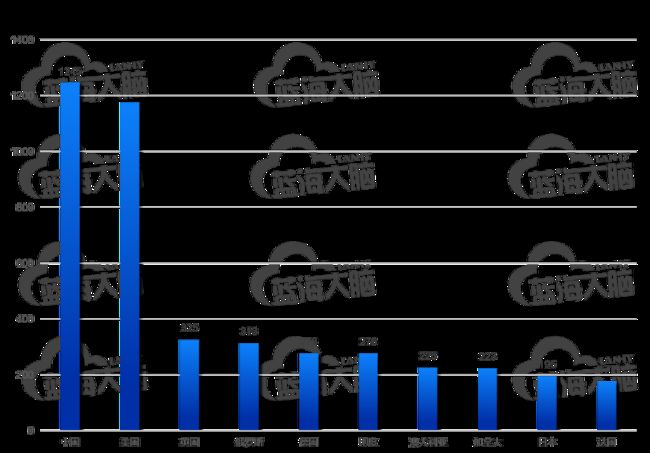
联邦学习论文发表量 TOP 10 国家(2016-2021 年)
三、研究热点涵盖应用、系统和模型设计、安全隐私三个领域
1、总体研究热点
总体来看,基于 AMiner 系统的论文热词分析,发现 2016-2021 年联邦学习领域的研究热点 TOP 10 按热度递减依次包括:Internet of Things(物联网)、blockchain(区块链)、edge computing ( 边缘计算 )、optimization (优化)、deep network(深度网络)、aggregation(聚合)、differential privacy(差分隐私)、healthcare(医疗保健)、Multiparty Computation(多方计算)、reinforcement learning(强化学习)等,如图所示。可见,在研究时段内,联邦学习的主要研究热点是关于应用及相关算法模型。

2016-2021 年联邦学习领域研究热点词云图
2、主题热点趋势
通过 TF-IDF 算法对所研究时段内每一年的联邦学习主题相关论文数量进行计算,获取论文数量 TOP 30 的热点词,然后聚合成联邦学习的应用 (application)、系统和模型设计(system and model design ) 和安全隐私( secure and privacy)三个主题领域的研究热点集。这三个细分主题的研究趋势呈现出如下特征。
在应用研究领域,联邦学习的研究热点按照总热度由高到低依次包括物联网(Internet of things)、边缘计算( edge computing )、 医疗保健 (healthcare)、车辆交互(vehicle)、无线通信( wireless communication )、 数据库 (database)、以及推荐 (recommendation),详细信息如图所示。

联邦学习在应用方面的研究热点趋势(2016-2021 年)
关于联邦学习在系统和模型设计方面的研究热点趋势情况如图所示。由图可见,截止目前,在系统和模型设计方面研究热点依照热度递减分别是优化(optimization)、聚合(aggregation)、鲁棒性( robustness ) 、 通信效率 ( communication efficiency )、异构 (heterogeneity)、公平性(fairness)、资源效率 (resource efficiency)和激励机制(incentive mechanism)。优化主题曾经在 2016 和 2017 年研究热度最高,经过 2018-2020 年的热度相对弱化后,在 2021 年再度成为最热门的研究主题。
2017 年,资源效率和公平性相关主题研究开始崭露头角
2018 年,通信效率相关研究占据热度榜第一
2019 年,热度最高的是与安全聚合相关研究, 同时,对联邦学习(数据和系统)异构的研究大幅 提升
2020 年,与异构相关研究上升为最热门,和激励机制相关的研究数量大幅提升
2021 年,与优化和聚合相关主题研究上升幅度显著。
从热度持续性看,聚合、优化、鲁棒性、激励机制和公平性的相关研究在研究时段内一直保持着不同程度的热度上扬
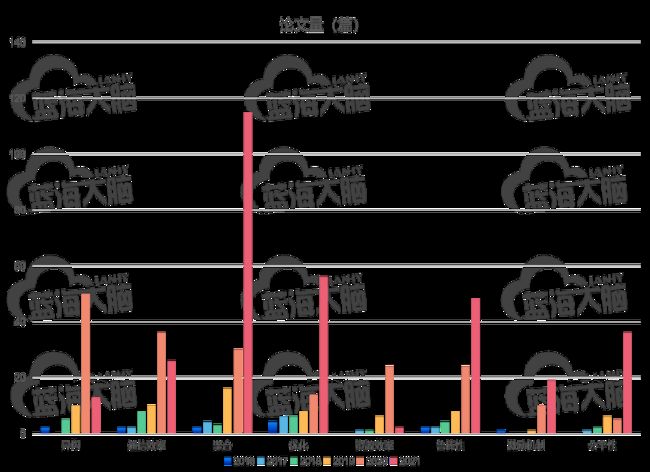
联邦学习系统和模型设计方面的研究热点趋势(2016-2021 年)
在安全隐私方面,联邦学习研究主题依据总热度递减依次包括区块链(blockchain)、差分隐私 (differential privacy)、 安全多方计算 (multiparty computation)、 恶意攻击 (malicious attack)、 隐私泄露 (privacy leakage)、 同态加密 (homomorphic encryption)、网络安全(cyber security)以及 容错(fault tolerance),具体热度趋势情况如图所示。在研究时段内,区块链、差分隐私、多方计算、恶意攻击、隐私泄露和同态加密的研究热度总体持续逐年上涨。
2016 年,研究最热的是对联邦学习中恶意攻击的研究
2017 年,研究最热的是差分隐私
2018 年,研究最热的是安全多方计算所涉及数据安全和隐私保护技术,与区块链结合的相关研究虽然于 2018 年出现但快速成为 2019 年至 2021 年最热的研究主题

联邦学习安全隐私方面的研究热点趋势(2016-2021 年)
四、高被引论文分析
根据联邦学习领域论文被引用量进行排序,选取了排名前 3%的论文作为具有重大学术影响的高被引论文进行相关的作者及其所隶属机构与国家等特征分析。数据显示,本年度联邦学习领域高被引论文的最低被引次数是 120 次,是去年高被引论文最低被引次数的 3 倍,反映出该领域论文的整体学术影响力大幅提升。
1、六成以上高被引论文来自中美两国
根据论文第一作者所在机构的所属国家进行统计分析,发现联邦学习的近年来高被引论文发表主要是来自于美国和中国。其中,美国的高被引论文占 39.2%,虽然较上期下降了 1 个百分点,但仍为全球最多;中国的高被引论文占 26.4%,虽仍居于全球第二位,但数量比上期增加了近 10 个百分 点;德国、英国、澳大利亚与新加坡也拥有一定数量的高被引论文;其余国家所发表高被引论文的占比均低于 4%,详细信息如图所示。

联邦学习高被论文国家分布(2016-2021 年)
2、美国的论文被引用量全球显著领先
联邦学习相关论文总引用量 TOP 10 国家是美国、中国、澳大利亚、德国、新加坡、英国、印度、日本、以色列和波兰,具体信息如图所示。其中,美国的论文总被引用量明显高于其他国家,其较上期增长 1.6 倍,仍占据榜首;中国的论文被引用量较上期增长近 3 倍,保持第二位置。印度、以色列和波兰是本期新进入前十的国家,上期居于前十的沙特阿拉伯、韩国和瑞士本期未能进入前十。

联邦学习论文引用量 TOP 10 国家(2016-2021 年)
从领先国家来看,美国联邦学习被引用量最高的论文是谷歌公司研究科学家 H. Brendan Mcmahan 作为一作发表的论文 Communication-efficient learning of deep networks from decentralized data,该论文于 2016 年发表于 ArXiv e-prints (2016): arXiv- 1602,并在2017年收录于AISTATS (International Conference on Artificial Intelligence and Statistics),目前其被引用 4534 次。中国联邦学习总体论文引用量居于第二,其中被引用最高的论文是香港科技大学计算机科学与工程学系教授杨强为第一作者、与微众银行 AI 部门、北京航空航天大学计算机学院的研究人员联合发表的 Federated Machine Learning: Concept and Applications,该文被引用量 1936 次。
多开源联邦学习系统框架详细介绍
一、OpenMined——PySyft
PySyft 是开源社区 OpenMined 推出的一个用于安全和私有深度学习的 Python 库。它使用联邦学习、差分隐私和加密计算来解耦私人和敏感数据,可以在主要的深度学习框架中使用,例如 TensorFlow 和 PyTorch。PySyft 代表在深度学习程序中启用可靠的隐私模型的首批尝试之一。 PySyft 的核心组件是称为 SyftTensor 的抽象。
SyftTensors 旨在表示数据的状态或转换,并且可以链接在一起。链结构始终在其头 部具有 PyTorch 张量,并且使用 child 属性向下访问由 SyftTensor 体现的变换或状态,而使用 parent 属性向上访问由 SyftTensor 体现的变换或状态。

二、微众银行——FATE
微众银行 AI 部门研发了FATE(Federated AI Technology Enabler)联邦学习开源项目,是首个开源的联邦学习工业级框架。目前 FATE 开源社区已汇聚了 700 多家企业、300 余所高校等科研机构的开发者,是国内最大的联邦学习开源社区。
FATE 项目使用多方安全计算 (MPC) 以及同态加密 (HE) 技术构建底层安全计算协议,以此支持不同种类的机器学习的安全计算,包括逻辑回归、树算法、深度学习(人工神经网络)和迁移学习等。FATE 目前支持三种类型联邦学习算法:横向联邦学习、纵向联邦学习以及迁移学习。
FATE 整体架构如图所示。FATE 主仓库包含 FederatedML 核心联邦算法库和多方联邦建模 Pipeline 调度模块 FATE-Flow,FATE 拥抱大数据生态圈,底层引擎支持使用微众银行自主研发的 EGGROLL 或者 Spark 进行高性能的计算。围绕 FATE 联邦学习生态,FATE 还提供了完整的联邦学习生态链,如联邦可视化模块 FATE-Board、联邦在线推理模块 FATE-Serving、联邦多云管理 FATECloud 等。

微众银行 FATE 系统架构
FederatedML 是 FATE 的联邦学习算法库模块,提供了 20+种联邦学习算法,支持纵向联邦学习、横向联邦学习、联邦迁移学习三种联邦建模场景,覆盖了工业建模的数据处理、特征变换、训练、预测、评估的全建模流程。另外,封装了众多的多方安全计算协议以提供给上层算法的调度和支持联邦学习开发者的联邦算法开发。
FATE-Flow 为 FATE 提供了端到端联邦建模 Pipeline 调度和管理,主要包括 DAG 定义联邦建模 pipeline、联邦任务生命周期管理、联邦任务协同调度、联邦任务追踪、联邦模型管理等功能,实现了联邦建模到生产服务一体化。 FATE-Board 联邦学习建模的可视化工具,为终端用户提供可视化和度量模型训练的全过程。
三、谷歌——TensorFlow Federated(TFF)
TensorFlow Federated project (TFF) 由谷歌公司开发和维护,是一个为联邦机器学习和其他计算方法在去中心化数据集上进行实验的开源框架。TFF 让开发者能在自己的模型和数据上模拟实验现有的联邦学习算法,以及其他新颖的算法。TFF 提供的建造块也能够应用于去中心化数据集上,来实现非学习化的计算,例如聚合分析。
TFF 的接口有两层构成:联邦层(FL)应用程序接口(API)和联邦核心(FC)API。TFF 使得开发者能够声明和表达联邦计算,从而能够将其部署于各类运行环境。 TFF 中包含的是一个单机的实验运行过程模拟器。该联邦学习的框架如图所示。
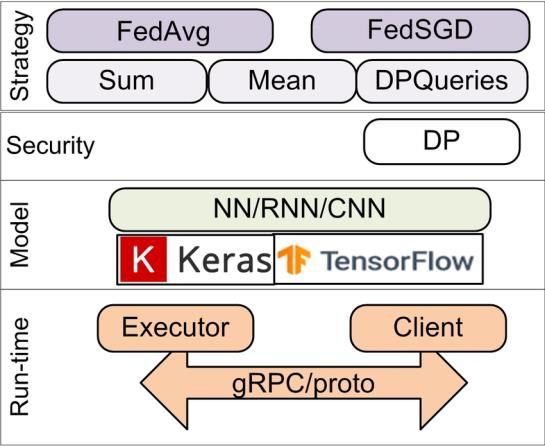
不同于分布式训练理念,TFF 框架设计理念是以数据为主,而不是代码分离上。在编写模型、训练代码的时候,将 clients 和 server 看作一个整体,同一个文件里不需要分割开 Server 端(S 端)和 Clients 端(C 端)的代码,C 端和 S 端的区分是在代码逻辑层面的。也就是说,用户在编写 TFF 代码时,不需要指明某段代码是应该运行在 C 端还是 S 端)仅需要指出每个数据是储存在C 端/S 端、是全局唯一的还是有多份拷贝的即可。类似 TF 的 non-eager 模式,当用户编写完模型代码和训练代码后,TFF 会自动地将代码分别放置到 clients 和 server 设备上。用户只要关注模型架构、C&S 端交互的数据格式、聚合多 clients 模型的方式即可。
四、字节跳动——Fedlearner
字节跳动联邦学习平台 Fedlearner 基于字节跳动在推荐和广告领域积累的机器学习建模技术和个性化推荐算法,可以支持多类联邦学习模式,已经在电商、金融、教育等行业多个落地场景实际应用。
Fedlearner 联邦学习平台整个系统包括控制台、训练器、数据处理、数据存储等模块,各模块对称部署在参与联邦的双方的集群上,透过代理互相通信,实现训练。
五、百度——PaddleFL
PaddleFL 是一个基于百度飞桨(PaddlePaddle)的开源联邦学习框架 。PaddleFL 提供很多联邦学习策略及其在计算机视觉、自然语言处理、推荐算法等领域的应用,例如,横向联邦学习(联邦平均、差分隐私、安全聚合)和纵向联邦学习(带 privc 的逻辑回归,带 ABY3 的神经网络)。研究人员可以用 PaddleFL 复制和比较不同的联邦学习算法。
此外,PaddleFL 还提供传统机器学习训练策略的应用,例如多任务学习、联邦学习环境下的迁移学习、主动学习。依靠 PaddlePaddle 的大规模分布式训练和 Kubernetes 对训练任务的弹性调度能力,PaddleFL 可以基于全栈开源软件轻松地部署。

PaddleFL 中主要提供两种解决方案:Data Parallel 以及 Federated Learning with MPC (PFM)。通过 Data Parallel,各数据方可以基于经典的横向联邦学习策略(如 FedAvg,DPSGD等)完成模型训练。此外,PFM 是基于多方安全计算(MPC)实现的联邦学习方案。作为 PaddleFL 的一个重要组成部分,PFM 可以很好地支持联邦学习,包括横向、纵向及联邦迁移学习等多个场景。
六、京东——九数联邦学习 9NFL
京东自研的九数联邦学习平台(9NFL)于2020 年初正式上线。9NFL 平台基于京东商业提升事业部 9N 机器学习平台进行开发,在 9N 平台离线训练、离线预估、线上推断(inference)、模型的发版等功能的基础上,增加了多任务跨域调度、跨域高性能网络、大规模样本匹配、大规模跨域联合训练、模型分层级加密等功能。整个平台可以支持百亿级/百 T 级超大规模的样本匹配、联合训练,并且针对跨域与跨公网的复杂环境,对可用性与容灾设计了一系列的机制与策略,保障整个系统的高吞吐、高可用、高性能。
七、FedML.AI——FedML
FedML 是一个以研究为导向的联邦学习图书馆,支持分布式计算、移动/物联网设备上训练和独立模拟,可促进新的联合学习算法的开发和公平的性能比较。支持分布式计算、移动/物联网设备上训练和独立模拟。
FedML 还通过灵活且通用的 API 设计和参考基准实现和促进了各种算法研究。针对非 I.I.D 设置的精选且全面的基准数据集旨在进行公平比较。 FedML 可以为联合学习研究社区提供开发和评估算法的有效且可重复的手段。
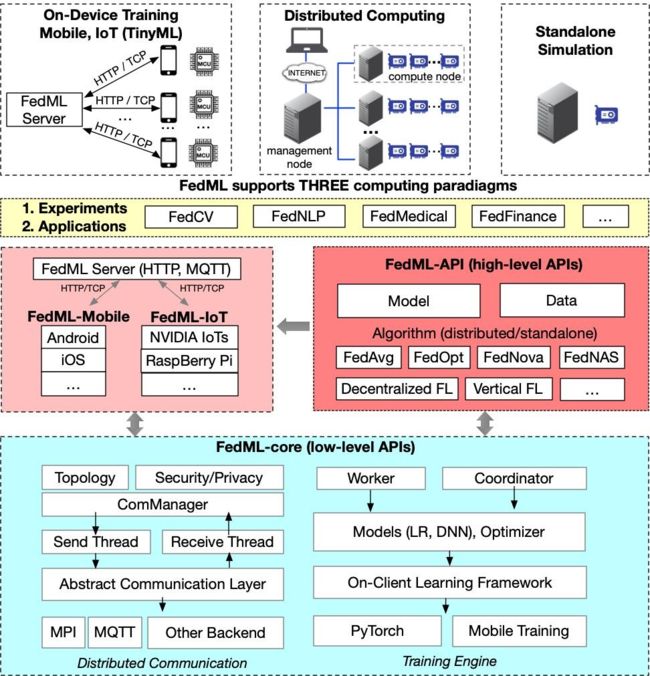
八、台湾人工智能实验室——Harmonia
台湾人工智能实验室(AI Labs)开发了一个开源项目 Harmonia,旨在开发系统/基础设施和图书馆,以简化联合学习的研究和生产用途。Harmonia 使用工程师熟悉的环境和语言,比如热门的开源工具 Kubernetes、Git Large File Storage 和 GitOps 等。Harmonia 利用 Git 进行访问控制、模型版本控制和服务器和联合培训 (FL)运行参与者之间的同步。FL 训练策略、全局模型和本地模型/渐变保存在 Git 存储库中。这些 Git respoitroies 的更新会触发 FL 系统状态转换。这将自动化 FL 培训过程。
FL 参与者被激活为由操作员和应用容器组成的 K8S 吊舱。操作容器负责维护 FL 系统状态,并通过 gRPC 与应用程序容器通信。本地训练和聚合函数封装在应用程序容器中。此设计可在 Kubernetes 群集环境中轻松部署,并快速插件现有机器学习(ML)工作流。

非开源联邦学习系统框架详细介绍
一、腾讯——Angel PowerFL
Angel Power FL(原名 AngelFL)安全联合计算是基于腾讯自研的多数据源联合计算技术,提供安全、易用、稳定、高性能的联邦机器学习、联合数据分析解决方案,助力数据融合应用。它构建在 Angel 机器学习平台上,利用 Angel-PS 支持万亿级模型训练的能力,将很多在 Worker 上的计算提升到 PS(参数服务器)端;Angel PowerFL 为联邦学习算法提供了计算、加密、存储、状态同步等基本操作接口,通过流程调度模块协调参与方任务执行状态,而通信模块完成了任务训练过程中所有数据的传输。
采用去中心的架构设计,全自动化流程,算法支持 LR、XGBoost、PCA、用户自定义神经网络模型(如 MLP、CNN、RNN、 Wide&Deep,DeepFM, DSSM 等)。Angel PowerFL 联邦学习已经在腾讯金融云、腾讯广告联合建模等业务中开始落地。目前主要应用产品是腾讯云安全隐私计算。

二、京东科技——Fedlearn
京东数字科技集团(简称:京东数科,现名: 京东科技)于 2020 年 10 月推出自主研发的联邦学习平台 Fedlearn。Fedlearn 平台具有“六位一 体”核心能力:多自研联邦学习算法、多方同态加密、轻量级分布式架构、区块链与联邦学习融合、数据安全容器、一站式操作平台。
京东科技 Fedlearn 平台具有三大特点:
1、数据和模型隐私方面
不同参与方之间没有直接交换本地数据和模型参数,而是交换更新参数所需的中间数值。为了避免从这些中间数值中恢复数据信息,采用增加扰动对这些数值进行保护,确保了数据和模型的隐私安全
2、通讯方面
引入中心化数据交换的概念,使得数据的交换独立于参与方
3、计算架构
采用异步计算框架,提高模型训练的速度
三、富数科技——FMPC
富数多方安全计算平台(FMPC)是上海富数科技旗下产品,目前未开源,主要通过体验或者服务购买方式使用 。

FMPC 架构具有以下特点:
1、联邦学习
原始数据不出门,参与各方本地建模;没有敏感数据流通,只交互中间计算结果;整个模型被保护,参与各方只有自己模型参数;私有化部署;开放 API 快速开发;支持主流机器学习算法,如 LR, DT, RF, Xgboost 等;建模速度快 3 倍;密文训练精度误差<1%。
2、多方安全计算
落地应用计算量 1.1 万+次 /天;支持多方数据安全求交;支持一次多项式;支持多方归因统计分析;支持多方多维数据钻取分析;私有化部署。
3、匿踪查询
支持 100 亿+条记录;秒级响应时间;查询授权存证;甲方查询信息不泄露;加密隧道避免中间留存;私有化部署。
隐私计算(联邦学习)液冷GPU服务器
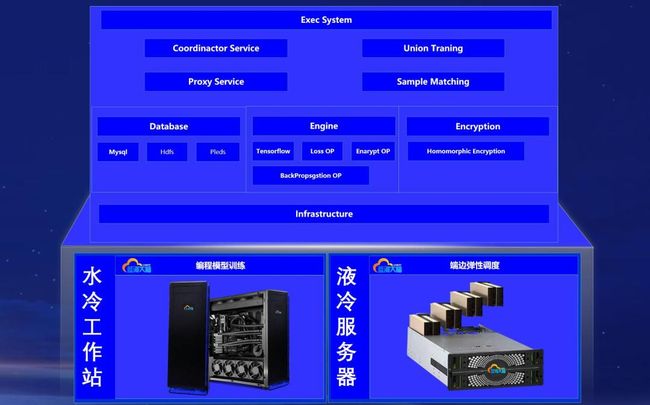
蓝海大脑隐私计算(联邦学习)大数据液冷GPU服务器基于数据隐私保护的安全建模过程提供丰富的可视化呈现,为终端用户可视化和度量模型训练的全过程,支持模型训练过程全流程的跟踪、统计和监控等,帮助模型开发人员快速搭建联邦学习任务,可根据客户需求深度定制开发。是一款具备高性能、高可靠、高灵活及高扩展特性的深度学习操作系统,由高性能计算加速中间件、深度学习训练平台及数据推理平台三个子系统构成,为用户提供数据处理、模型训练、推理服务应用等完整的 AI 解决方案。
一、用户现状
1、数据产品相互分离
同一业务可能随着业务发展和需求变化,同时部署不同的数据库和数据平台产品;此外,为了保证企业的核心竞争力,企业不断部署新的数据库和数据平台产品,不断建设、合并和迁移业务。然而,竖井建设模式使得数据产品相互分离,导致数据孤岛问题,最终降低了企业的数据共享能力。
2、系统复杂性剧增
传统的解决方案需要经过复杂耗时的ETL,将数据反复存储在同一个存储介质中,然后重新开发业务获得数据计算结果。数据分散存储在不同的数据产品中,数据结构存在差异,给跨产品数据间的关联计算带来了一定的难度。
3、开发运维困难
系统集成一段时间后,业务部门会推出新的业务数据库,ETL流程需要改造。底层数据库频繁的业务架构调整和数据变换也会导致集成系统的失败。面对集成系统的开发和运维难题,企业自身的技术开发能力显然难以应对,最终集成系统的响应速度无法满足业务的时效性需求。

二、方案优势
1、统一平台架构
连接企业内部各类数据源,满足各种多样复杂的业务需求,为企业提供平台数据计算能力
2、极致性能
自主研发的统一分布式计算引擎可以根据不同的查询对象,通过各种优化技术自动优化查询,并实现毫秒级延迟
3、多数据源支持
支持传统关系型数据库、Nosql数据库、MPP数据库和大数据平台产品
4、统一的SQL查询
自主研发统一的SQL编译器,通过一个标准的SQL就可以实现各个数据库之间的关联查询
5、数据独立性
实现跨数据库、跨平台的数据集成的同时,满足底层数据库的自治需求
6、安全合规
提供统一的权限体系、用户行为审计与溯源,提供数据安全与合规保障
三、客户收益
1、建设统一计算平台,简化IT系统架构,降低IT成本
2、提升企业数据共享能力,快速响应业务需求
3、提升企业信息技术架构的敏捷程度,助力企业数据数字转型