深度学习实践:计算机视觉
计算机视觉 (Computer Vision)
Deep Learning(DL) is undeniably one of the most popular tools used in the field of Computer Vision(CV). It’s popular enough to be deemed as the current de facto standard for training models to be later deployed in CV applications. But is DL the only available option for us to develop CV applications? What about Traditional techniques that have served the CV community for an eternity? Has the time to move ahead & drop working on Traditional CV techniques all together in favor of DL arrived already? In this article, we try to answer some of these questions with comprehensive use-case scenarios in support of both DL & Traditional CV implementations.
不可否认, 深度学习(DL)是计算机视觉(CV)领域中使用最广泛的工具之一。 它足够流行,可以被认为是培训模型的当前事实上的标准,以便以后在CV应用程序中部署。 但是DL是我们开发CV应用程序的唯一可用选择吗? 对于为CV社区提供永恒服务的传统技术呢? 是否已经到了继续推进传统CV技术并放弃支持DL的时候了? 在本文中,我们尝试使用全面的用例场景来回答其中的一些问题,以支持DL和传统CV实现。
历史的第一位 (A Little Bit Of History First)
The field of Computer Vision started gaining traction dating as far back as the late 1950s till the late 1960s when researchers wanted to teach computers “to be…human”. It was around this time when researchers tried to mimic the human visual system in order to achieve a new stepping stone to endow machines with human intelligence. Thanks to the extensive research being done back then, Traditional CV techniques like Edge Detection, Motion Estimation, Optical Flow were developed.
最早可以追溯到1950年代末直到1960年代末的计算机视觉领域开始受到人们的关注,当时研究人员希望教计算机“ 成为……人类 ”。 大约在这个时候,研究人员试图模仿人类的视觉系统,以便为赋予人类智能的机器提供新的垫脚石。 由于当时进行了广泛的研究,因此开发了传统的CV技术,例如边缘检测 , 运动估计 , 光流 。
It wasn’t until the 1980s when Convolutional Neural Networks(CNNs) were developed. Aptly named, the Neocognitron which was the first CNN with the usual multilayered & shared weights Neural Nets we see today. But the popularity of DL skyrocketed only after LeNet was developed jointly by Yann LeCun & his colleagues in the 1990s. It was a pioneering moment since no other previous algorithms could ever achieve such an incredibly high accuracy as CNNs.
直到1980年代, 卷积神经网络(CNN)才被开发出来。 恰当命名的Neocognitron是我们今天看到的第一个具有通常的多层和共享重量神经网络的 CNN。 但是只有在1990年代Yann LeCun及其同事共同开发LeNet之后,DL的流行才飞速上升。 这是一个开创性的时刻,因为以前没有其他算法能够像CNN一样达到如此令人难以置信的高精度。
A decade and a half later, CNNs have made such vast developments, it even outperforms a human being with accuracy rates as high as 99% in the popular MNIST dataset![1] No wonder, it’s so easy to believe, CNNs would come down as a messiah for the CV community. But I doubt it happening any time soon.
十年半后,CNN取得了如此巨大的发展,在流行的MNIST数据集中 ,其准确率甚至高达99%,胜过人类![1]难怪,这么容易相信,CNN会下降作为CV社区的救世主。 但是我怀疑它会很快发生。
CNNs & DL techniques come with certain caveats which when compared to older Traditional techniques might make the latter appear like a godsend gift for us mortals. And this article should throw some light into those differences. We’ll gradually dive deeper into what those differences are & how do they fare for certain use cases in the following sections.
CNN和DL技术带有一些警告,与旧的传统技术相比,它们可能会使后者看起来像是送给我们凡人的天赐礼物。 并且本文应该阐明这些差异。 在接下来的几节中,我们将逐步深入探讨这些差异是什么以及它们如何适应某些用例。
差异 (The Differences)
To properly contemplate the differences between the two approaches — Deep Learning & Traditional techniques, I like to give an example of comparing an SUV and/or a hatchback. They’re both four-wheeler & an experienced driver can differentiate the pain-points as well as the ease-of-use for both the vehicles. While the hatchback might be preferable to drop your child to school & bring him/her back, the SUV would be perfect for cross-country travel if comfort & fuel efficiency is your concern. The vice-versa is possible but is probably not advisable, in general.
为了正确考虑两种方法(深度学习和传统技术)之间的差异,我想举一个比较SUV和/或掀背车的示例。 他们都是四轮驱动车,而且经验丰富的驾驶员可以区分这两种车辆的痛点以及易用性。 虽然掀背车可能更适合让您的孩子上学并带他/她回来,但如果您关注舒适性和燃油效率,那么越野车将是越野旅行的理想之选。 反之亦然,但通常不建议这样做。
In this context, consider DL techniques the SUV among all ML tools for use in Computer Vision while the hatchback as the Traditional techniques. Similar to the difference in an SUV and the hatchback, DL & other Traditional techniques have merits-demerits too. So what are those differences? Let’s take a look at some of the prominent differences followed by a detailed description of the merits & demerits below.
在这种情况下,在计算机视觉中使用的所有ML工具中,将DL技术视为SUV,将掀背车作为传统技术。 类似于SUV和掀背车的区别,DL和其他传统技术也有优缺点。 那有什么区别呢? 让我们看一下一些突出的区别,然后在下面对优点和缺点进行详细描述。
The following infographic feature some of the differences between the two approaches very briefly.
以下信息图非常简要地介绍了这两种方法之间的一些差异。
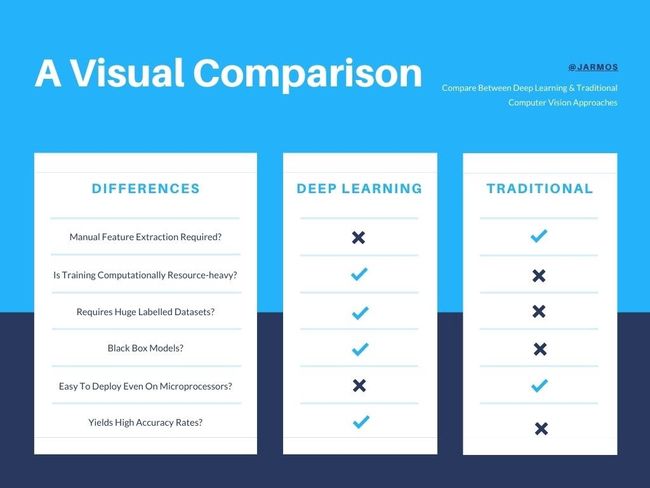
The infographic makes it so much more clear about why Deep Learning is getting all the attention. A quick glance & you’ll notice with so many tick marks obviously DL has to be the best approach among the two, right? But, is it really the case?
该信息图使人们更清楚地了解了深度学习为何获得所有关注。 快速浏览一下,您会注意到带有许多刻度线,显然DL必须是两者之中最好的方法,对吗? 但是,真的是这样吗?
Let’s dig deeper & analyze the differences mentioned in the infographic.
让我们更深入地分析图表中提到的差异。
Requirement Of Manually Extracting Features From the Image By an Expert: A major drawback of the first few Machine Learning algorithms created during the early 1960s was the requirement of painstaking manual feature extraction of the images. The little bit of automation employed back then also required careful tuning by an expert since algorithms like SVM and/or KNN were used to find the important features. This requirement meant building a dataset with set features for the model to learn from. Hence, DL techniques was a real life-saver for the practitioners, since no longer do they’ve to worry about manually selecting the features for the model to learn from.
手动从图像中提取特征的要求专家 :1960年代初创建的最初几种机器学习算法的主要缺点是需要费力地手动提取图像。 那时使用的一点点自动化也需要专家的仔细调整,因为使用了SVM和/或KNN之类的算法来查找重要特征。 这项要求意味着要建立一个具有设定特征的数据集以供模型学习。 因此,DL技术对于从业者来说是真正的救星,因为他们不再需要担心手动选择模型的特征以从中学习。
The Requirement of Heavy Computational Resources: Deep Learning is a computationally heavy task which was why the mid-1950s barely saw any advancements in the field. Fast forward a few decades, with major advancements made in GPU capabilities & other related computational resources, this present time has never been more perfect for advancing DL research. But it comes with a caveat, bigger & better computational resources has a hefty price tag as well which might not be very pocket-friendly for most people & enterprises. Thus in context to easily available resources, the Traditional approach might look like a clear winner against Deep Learning.
大量计算资源的需求 :深度学习是一项计算繁重的任务,这就是1950年代中期在该领域几乎看不到任何进步的原因。 几十年来,随着GPU功能和其他相关计算资源的重大进步,当前这一时代对于推进DL研究而言从未如此完美。 但是需要注意的是,更大,更好的计算资源的价格也很高,对于大多数人和企业来说可能不是很方便。 因此,在易于获得资源的背景下,传统方法看起来像是深度学习的明显赢家。
The Need For Huge Labeled Datasets: We live at a point of time when every second thousand & thousands of petabytes of data are being created & stored globally. It must be good news then, right? Well sadly, contrary to popular belief, storing huge amounts of data, especially image data is neither economically viable nor does it portray a sustainable business opportunity. You would be surprised to know, often most enterprises are sitting on a gold mine of a dataset, yet either they don’t have to expertise to benefit from it or the business can’t get rid of them, legally. Hence, finding a useful, labeled & in-context dataset is no easy task which is why most often Deep Learning is an overkill approach for a simple CV solution.
对巨大的标记数据集的需求 :我们生活在一个时刻,全球每秒钟创建和存储数以千计的PB数据。 那一定是个好消息,对吧? 令人遗憾的是,与普遍的看法相反,存储大量数据,尤其是图像数据在经济上既不可行,也不描绘可持续的商机。 您会惊讶地发现,通常大多数企业都坐在数据集的金矿上,但是他们要么不必从中受益,要么业务不能合法地摆脱它们。 因此,要找到有用的 ,带有标签且上下文相关的数据集并不是一件容易的事,这就是为什么大多数情况下,深度学习对于简单的CV解决方案来说是一种过大的方法。
Black Box Models Which Are Difficult to Interpret: Traditional approaches make use of easy to understand & interpret statistical methods like SVM & KNN to find features for resolving common CV problems. While on the other hand, DL involves using very complex layers of Multilayered Perceptrons(MLP). These MLPs extract informative features from the images by activating the relevant areas on the images which are often difficult to interpret. In other words, you’ll have no clue why certain areas of an image were activated while the other wasn’t.
难以解释的黑匣子模型 :传统方法利用易于理解和解释的统计方法(例如SVM和KNN)来找到解决常见CV问题的功能。 另一方面,DL涉及使用非常复杂的多层感知器(MLP)层。 这些MLP通过激活图像上通常难以解释的相关区域来从图像中提取信息特征。 换句话说,您将不知道为什么图像的某些区域被激活而其他区域没有被激活。
Small & Easy Enough to Be Shipped and/or Deployed Inside a Microprocessor: Besides being computationally heavy, the model used in a DL approach are huge in size compared to other simple Traditional approaches. These models often vary from sizes of a few hundred megabytes to a gigabyte or two which is absolutely massive. While on the other hand, traditional approaches often output a model in sizes of just a few megabytes.
体积小巧且易于在微处理器内运输和部署 :与其他简单的传统方法相比,DL方法中使用的模型除了计算量大之外,其尺寸也很大 。 这些模型的大小通常从几百兆字节到一到两个千兆字节不等,这绝对是巨大的。 另一方面,传统方法通常会输出大小仅为几兆字节的模型。
How Accurate Are the Predictions From the Two Approaches: One of the winning factors for DL to completely overshadow the achievements of the Traditional approaches is how extremely accurate the predictions are. It was a massive leap in the late 90s to the early 20s when Yann LeCunn & his colleagues came up with LeNet. It completely blitzed the previous accuracy rates made using Traditional approaches. Ever since then, DL has almost become the de facto go-to tool for any Computer Vision problems.
两种方法的预测的准确性如何 :DL完全掩盖传统方法的成就的获胜因素之一是预测的准确性。 从90年代末到20年代初,Yann LeCunn及其同事提出了LeNet,这是一次巨大的飞跃。 它完全颠覆了以前使用传统方法得出的准确率。 从那时起,DL几乎已成为解决任何计算机视觉问题的事实上的必备工具。
深度学习技术的挑战 (Challenges Of Deep Learning Techniques)
Although both DL & Traditional approaches have their trade-offs depending on certain use cases. Traditional approaches are more well established. DL techniques show promising results with incredibly high accuracy rates though. Without a doubt, DL based techniques are the poster child in the Computer Vision community. But DL techniques have their own set of drawbacks.
尽管DL和传统方法都需要根据某些用例进行权衡。 传统方法更加完善。 DL技术以令人难以置信的高准确率显示了令人鼓舞的结果。 毫无疑问,基于DL的技术是Computer Vision社区中的典型代表。 但是DL技术有其自身的缺点。
And in the following section, I describe a few of those challenges faced by the DL techniques comprehensively.
在以下部分中,我将全面描述DL技术面临的一些挑战。
- Deep Neural Networks(DNNs) are infamous for being computationally resource-heavy which is quite the contrast from Traditional techniques. Mixing both the techniques together can perhaps significantly reduce computation time & even half the bandwidth usage or even lesser! 深度神经网络(DNN)因其计算量大而臭名昭著,这与传统技术形成了鲜明的对比。 将这两种技术混合在一起可以大大减少计算时间,甚至减少一半的带宽使用量,甚至更少!
- Big Data is the loudest buzzword at the moment but in reality, useful data is hard to come by. Finding viable image data for training a DNN is a costly, difficult & time-consuming process. 大数据是目前最响亮的流行语,但实际上,有用的数据很难获得。 寻找用于训练DNN的可行图像数据是一个昂贵,困难且耗时的过程。
With the advent of Cloud Computing services like GCP & other Cloud Machine Learning platforms like Google AI platform, high-performance resources are readily available at a click of a button. But the ease of access comes with a caveat, significant price build-ups. At first glance, a $3/hr high-performant GPU instance doesn’t sound too costly. But the expenditures build up over time as the business grows & DL techniques take a lot of time to train as well.
随着诸如GCP之类的云计算服务以及诸如Google AI平台之类的其他云机器学习平台的出现,只需单击一下按钮,即可轻松获得高性能资源。 但是,易于获得伴随着警告,大量的价格上涨。 乍一看,每小时3美元的高性能GPU实例听起来并不太昂贵。 但是随着业务的增长,支出会随着时间而增加,并且DL技术也需要大量时间进行培训。
There are still certain fields of CV where DL techniques are yet to make any significant developments. Some of those fields include — 3D Vision, 360 Cameras, SLAM, among many others. Until & unless DL techniques make progress towards resolving problems in those sub-fields traditional techniques are here to stay for a long time. [2]
仍然有一些CV领域的DL技术尚未取得重大进展。 其中一些领域包括3D Vision,360相机, SLAM等。 直到&除非DL技术在解决这些子领域的问题方面取得进展,否则传统技术将在这里停留很长时间。 [2]
Quite surprisingly certain individuals of the community appear to advocate a data-driven approach towards resolving most CV problems. “Just increase the dataset size” is common knowledge in the community as of writing this article. But quite contrary to the opinion, the fundamental problem at the root is quality data to train the models on. There’s a popular saying in the community right now, “Garbage In, Garbage Out”. So until & unless a proper alternative to the data-driven approach is discovered, current DNNs will not perform better than what they’re already capable of.
令人惊讶的是,社区中的某些人似乎主张采用数据驱动的方法来解决大多数简历问题。 撰写本文时,“ 只是增加数据集的大小 ”是社区中的常识。 但是与观点完全相反,根本的根本问题是训练模型所依据的质量数据 。 目前在社区中有一种流行的说法,“ 垃圾进,垃圾出 ”。 因此,直到&除非找到数据驱动方法的适当替代方案,否则当前DNN的性能不会比其已有能力更好。
应对上述挑战的一些可能解决方案 (Some Possible Solutions To the Aforementioned Challenges)
Hybrid techniques can be leveraged extensively across various fields of implementation by using traditional techniques only on a portion of the computation process, while DNNs can be employed for identification and/or the classification process. In other words, the end-to-end ML job can be divided into CPU-bound jobs & GPU-bound jobs. For example, preprocessing on the CPU while training on the GPU.
可以利用混合技术 通过仅在计算过程的一部分上使用传统技术,广泛地跨各种实现领域,而DNN可以用于识别和/或分类过程。 换句话说,端到端ML作业可以分为CPU绑定作业和GPU绑定作业。 例如,在GPU上训练时在CPU上进行预处理。
As multi-threaded CPUs are becoming more common, I doubt it will take longer for a data pipeline which will make preprocessing before training a breeze by taking advantage of the multi-threaded environment. Besides, it is observed DNNs tend to be more accurate when the input data is preprocessed. Hence, it goes without saying, there’s a need for developing a system of data pipelines to be run on the CPU instead of the GPU.
随着多线程CPU变得越来越普遍,我怀疑数据流水线将花费更长的时间,这将使多线程环境的优势使预处理工作变得轻而易举。 此外,可以观察到在对输入数据进行预处理时,DNN往往更准确。 因此,不用说,有必要开发一种数据流水线系统,以便在CPU而非GPU上运行。
Today, Transfer Learning or using a pre-trained model is almost the de facto standard for training a new Image Classifier and/or an Object Detection model. But the caveat is, this kind of model performs even better when the new input data are somewhat similar to that of the pre-trained model. So once again preprocessing on the input data on the CPU & then training with a pre-trained model can significantly reduce Cloud Computing expenditures without any loss in performance.
如今, 转移学习或使用预训练模型几乎已成为训练新图像分类器和/或对象检测模型的事实上的标准。 但是需要注意的是,当新输入数据与预先训练的模型有些相似时,这种模型的性能会更好。 因此,再次对CPU上的输入数据进行预处理,然后使用预先训练的模型进行训练可以显着减少云计算的支出,而不会造成性能损失。
Employing a data-driven approach for certain business ventures might pay off in the future. But there’s always a logic-driven alternative albeit one which mightn’t sound very attractive. So sticking with age-old tried-and-tested logic-driven techniques cannot go wrong. Worst that could happen is you mightn’t make more money than you’re already earning.
在某些企业中采用数据驱动的方法可能会在将来获得回报。 但是,总有一种逻辑驱动的替代方案,尽管听起来可能并不很吸引人。 因此,坚持使用久经考验的逻辑驱动技术不会出错。 可能发生的最糟糕的情况是,您赚的钱可能不会比您已经赚到的多。
结语! (Wrapping Up!)
The developments made over the two decades in Deep Learning techniques for Computer Vision applications are no doubt enticing. I mean a research paper boasting of beating the human baseline on the MNIST dataset sounds amazing, almost futuristic. No wonder, some entrepreneurs out there with a sky-high vision would talk big about the next big thing with his/her product. But we shouldn’t forget the fact that the Machine Learning research community is facing a reproducibility crisis.[3] Researchers tend to just publish the best experiment out of many which worked as expected.
过去二十年来,用于计算机视觉应用程序的深度学习技术取得了令人瞩目的发展。 我的意思是说吹嘘在MNIST数据集上击败人类基线的研究论文听起来令人惊叹,几乎是未来主义。 难怪,那里的一些具有远见卓识的企业家会谈论他/她的产品的下一件大事。 但是,我们不应忘记机器学习研究社区正面临可再现性危机的事实。[3] 研究人员往往只是发布许多按预期工作的最佳实验。
What does it mean for businesses & entrepreneurs looking forward to taking advantage of this supposedly bleeding-edge proofs-of-concept?
对于希望利用这种所谓的前沿概念验证的企业和企业家意味着什么?
Simple, tread carefully.
简单,小心行事。
Towards the end of the day, you’ll come back to employing Traditional techniques for your product anyway. The tried & tested techniques will almost always suit your needs.
快要结束时,无论如何您都会回到采用传统技术的方式。 经过考验的技术几乎总是可以满足您的需求。
So what’s the lesson here?
那么这是什么教训?
When in doubt stick to Traditional techniques, Deep Learning has a long way to go & will take another eternity to REALLY production-ready for your business.
如果不确定是否要使用传统技术,则深度学习还有很长的路要走,并且需要花很长时间才能真正为您的业务做好生产准备。
[1] Savita Ahlawat, Amit Choudhary, et al, Improved Handwritten Digit Recognition Using Convolutional Neural Networks (CNN) (2018), MDPI
[1] Savita Ahlawat,Amit Choudhary等人,《 使用卷积神经网络(CNN)改进手写数字识别》 (2018年),MDPI
[2] Nial O’ Mahony, et al, Deep Learning Vs. Traditional Computer Vision, Institute of Technology Tralee (2019)
[2] Nial O'Mahony等人,《 深度学习与挑战》 。 传统计算机视觉 ,特拉利技术学院(2019)
[3] Shlomo Engelson Argamon, People Cause Replication Problems, Not Machine Learning (2019), American Scientist (accessed on 14th August 2020)
[3] Shlomo Engelson Argamon,《 人会引起复制问题,而不是机器学习》 (2019年),美国科学家( 于2020年8月14日访问 )
翻译自: https://medium.com/discover-computer-vision/deep-learning-vs-traditional-techniques-a-comparison-a590d66b63bd
深度学习实践:计算机视觉