让样本不一样重要-A Dual Weighting Label Assignment Scheme for Object Detection
CVPR 2022
论文链接:https://arxiv.org/abs/2203.09730
个人理解:样本的重要性是不同的,分类和回归之间一致性较高的锚点十分重要,而一些难以被网络优化的负样本应该有更低的重要性。基于此提出了多重加权(pos和neg)区分不同样本重要性以促进训练。提出 box 细化,根据边缘判断真实框和预测框之间的误差。
论文思路:最优预测不仅应该具有较高的分类分数,还应该具有准确的定位。在训练中,通过区分样本重要性,分辨出分类定义一致性高的样本,过滤困难负样本。
提出问题:现实中分类得分最高的位置通常不是回归物体边界的最佳位置,样本重要性不一致。
方法:双重加权,一个样本的 pos 权重由其分类和定位分数之间的一致性程度决定,而 neg 权重分为锚定框是一个负样本的概率和它作为一个负样本的重要性两部分。可以区分重要或者不重要的样本。提出 box 细化,根据预测框中心以及目标边缘四个边界点从而生成一个更好的包围框。
实验:消融实验(超参数)、对比实验
结果:微弱开销、较好性能、鲁棒性
文章目录
- 简介
- 相关工作
- 方法
-
- 1. 动机和框架
- 2. pos 权值函数
- 3. neg 权值函数
- 4. 边界 box 细化
- 5. 损失函数
- 实验
-
- 1. 消融实验
- 2. 对比实验
- 3. 讨论
- 总结
简介
目前最先进的检测器大多通过使用一组预定义的 Anchor 来预测类标签和回归偏移量来实现密集检测。Anchor 作为检测器训练的基本单元,需要分配适当的分类 (cls) 和回归 (reg) 标签来监督训练过程。这被称为标签分配 (LA),其过程可以看作是为每个 Anchor 分配损失权重的任务,这种损失分配与正负样本权重以及预测得分息息相关,即 w n e g w_{neg} wneg 和 w p o s w_{pos} wpos 。
标签分配可以分为两类:Hard LA 和 Soft LA,分别为 w p o s , w n e g ∈ { 0 , 1 } w_{pos}, w_{neg} ∈ \{0,1\} wpos,wneg∈{0,1} 和 w n e g + w p o s = 1 w_{neg} + w_{pos} = 1 wneg+wpos=1 。
通过标签分配的方式可以划分最佳边界,从而判断正负样本,这样的方法可以分为静态的和动态的。静态预定义锚点,计算IoU距离判断样本。但由于不同大小和形状的对象的划分边界可能不同,一些动态方法使用置信度等方式解决这一问题。
但二者都忽略了样本不同等重要,从目标检测的评价指标来看,最优预测不仅要有较高的分类分数,而且要有准确的定位,这意味着cls和reg之间一致性较高的锚点在训练中应具有更大的重要性。
基于此,提出了软标签,GFL 和 VFL 定义软标签目标检测的两种方法,他们通过乘以调制因子将其转换为损失权值。同时,也有方法综合考虑 reg 评分和 cls 评分计算样本权重。现有的方法主要侧重于 pos 权值函数的设计,而负权值只是简单地由 pos 权值推导而来,由于负权值不能提供新的监督信息,可能会限制检测器的学习能力。
作者认为这样的加权机制不能在一个更精细的层次上区分每个训练样本。例如在图一中,GFL 和 VFL 分别为 (B, D) 和 (C, D) 分配了几乎相同的 (pos, neg) 权重对。GFL 也将锚定 A 和 C 分配为零和负,因为每个锚定 A 和 C 都有相同的 cls 分数和 IoU。

由于在现有的 Soft LA 方法中,neg 权值与 pos 权值高度相关,具有不同属性的锚点有时可以被赋值几乎相同 (pos, neg)权重,这可能会削弱训练后的检测器的有效性。
因此,作者提出了一种新的 LA 方案,即双权 (dual weighted, DW),从不同的角度指定 pos 权和 neg 权,使它们相互补充。具体来说,pos 权值是由可信度(由 cls 头获得)和 reg 值(由 reg 头获得)结合动态确定的。而每个锚的 neg 权值被分解为两个项:它是一个负样本的概率和它作为一个负样本的重要性。
pos 权值反映了 cls 头与 reg 头的一致性程度,将一致性较高的锚点推送到锚点列表中,而 neg 权值反映了不一致性程度,将不一致的锚点推送到列表的尾部。
通过这种方法,具有更高 cls 分数和更精确位置的边界框在 NMS 之后将有更好的生存机会,而位置不精确的边界框将落后并被过滤掉。
在图一中,DW 通过分配不同的 (pos, neg) 权重对来区分四个不同的锚点,为检测器提供更细粒度的监督训练信号。同时,为了能够获得精确的评分,作者提出了一个细化的学习预测模块,在粗回归图的基础上生成四个边界位置,然后对四个边界位置的预测结果进行聚合,得到更新后的当前节点的边界框。通过引入适度的计算开销得到了更精确的 reg 评分。
作者在MS COCO[23]上进行了实验,验证了该方法的有效性。
相关工作
- Hard LA
- Soft LA
方法
1. 动机和框架
在 NMS 下,一个好的检测器应该能够预测具有较高分类分数以及精确位置并且两者具有高一致性的边界框。但如果对所有样本同等对待,在分类头和预测头之间就会存在误差,即分类得分最高的位置通常不是回归物体边界的最佳位置。
这种偏差会降低检测器的性能,特别是在较高的IoU度量下。Soft LA 是一种通过加权损失增强 cls 和 reg 头之间的一致性的方法,该方法定义下的锚点损失如下:

其中 s s s 为预测的 cls 分数, b b b 和 b ′ b' b′ 分别为预测的边界框和真实对象的位置, ℓ r e g ℓ_{reg} ℓreg 为回归损失,如 Smooth L 1
损失,IoU 损失和 GIoU 损失。cls 和 reg 头之间的不一致问题可以通过分配较大的 w p o s w_{pos} wpos 和 w r e g w_{reg} wreg 给具有较高一致性的锚点来缓解。因此,能够推理得到拥有高分类分数和精确的位置的锚。
这些现有工作将 w r e g w_{reg} wreg 整合在 w p o s w_{pos} wpos 中,而非单独定义,如下表:

基于此,为了有更细粒度的样本重要性,作者提出将两个权重分别定义与计算。pos 权函数将预测的 cls 评分 s s s 和预测框与真实对象之间的 IoU 作为输入,通过估计 cls 与 reg 头之间的一致性程度来设置 pos 权重。neg 权函数采用与 pos 权函数相同的输入,但将其定义为两项的乘法:锚定框是负样本的概率,其作为负样本的重要性。通过这种方法,具有相似 pos 权值的模糊锚点可以接收到更多具有不同 neg 权值的细粒度监督信号。同时,作者对包围盒进行了细化处理,图2为 DW 流程框架,首先通过选择真实框中心附近的锚点(中心优先原则)为每个目标构建一个候选正样本集。候选集外的锚点被视为负样本,不参与加权函数的设计过程。候选集内的锚将被分配三个权重,包括 w p o s w_{pos} wpos, w n e g w_{neg} wneg 和 w r e g w_{reg} wreg,以更有效地监督培训过程。

2. pos 权值函数
pos 权值应该反映出对于目标样本分类以及定位准确的重要性,在实验中,一个类别的预测结果是根据一系列符合要求的锚的排名得到的,现在的方法常用 cls 评分或结合 cls 评分和预测 IoU 作为排名指标,每个锚的准确性会从排名列表开始检查,当某个预测锚被判断为正确预测时,存在两点要求:
1)预测边界框和真实边界框之间的 IoU 大于阈值 θ θ θ;
2)该预测框排在列表其他符合要求的预测框前面。
只有符合上述要求的第一个预测边界框会被定义为 pos 检测,其他的边界框都会认为是该真实目标的假阳预测。因此,高 IoU 和高排名是准确预测的充分必要条件,这种二者一致的锚点在训练中应该具有更高的重要性,其 pos 权重应该与 IoU 和排名分数 s s s 呈正相关。
基于此,作者定义了一个一致性度量参数 t t t 以度量两个条件之间的对齐度,
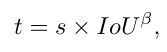
其中 β β β 为平衡因子,用于平衡这两种情况。为了使不同锚点之间的pos权重有较大的差异,作者增加了一个指数调制因子:
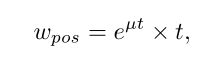
其中,µ是一个超参数,用来控制不同权重的相对差距。最后,每个锚点的pos权重由候选集中所有pos权重的总和进行规范化。
3. neg 权值函数
虽然pos权重可以获得分类分数以及 IoU 一致性较高的锚,但对于不一致的锚,其重要性不能通过pos权重来区分。例如图一中,锚D的定位较好,锚B的定位 IoU 比 θ θ θ 小但 cls 值较高,他们可能具有相同的一致性程度 t t t,因此会有相同的 w p o s w_{pos} wpos ,这并不能反映他们的差异。为了给检测器提供更有鉴别性的监督信息,作者提出 w n e g w_{neg} wneg 来表示不同锚点重要性,其定义为以下两项的乘法。
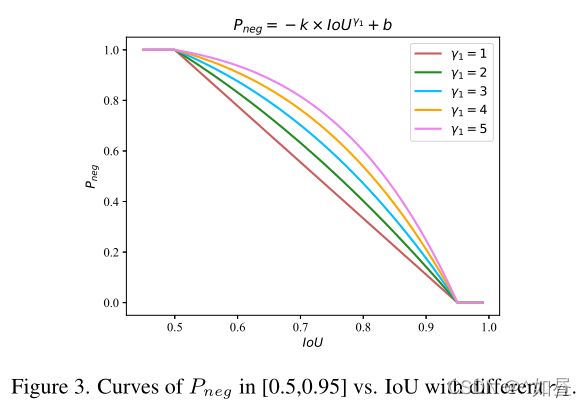
1)负样本的概率:不满足 I o U > θ IoU > θ IoU>θ 的样本会被视为负样本(IoU小于θ是预测错误的充分条件),即使有较高的 cls 得分。定义 IoU 为 P n e g P_{neg} Pneg 如下(采用 0.5 ~ 0.95 的 IoU 区间):
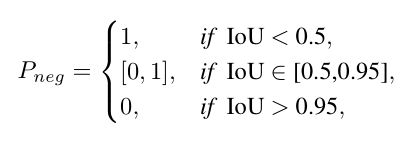
其在 0.5 ~ 0.95 区间为单调递减函数,即为

如图,3,这个函数通过点(0.5,1)和(0.95,0)。当 γ 1 γ_1 γ1 确定时,参数 k k k 和 b b b 可通过待定系数法求得。
2)负样本的重要性:列表中的负样本不会影响召回率,但会降低精度。因此,对于一些更难被网络优化的负样本,其排名分数应该尽可能的小。同时,排名高的负样本应该比排名低的负样本更重要。作者定义负样本重要性为 I n e g I_{neg} Ineg ,其为
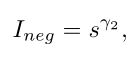
其中 γ 2 γ_2 γ2 为重要性因子,可以表示负样本的重要性。
最后, w n e g = P n e g × I n e g w_{neg} = P_{neg} × I_{neg} wneg=Pneg×Ineg ,为

其与 IoU 负相关,与 s s s 正相关。由此可得,当 w p o s w_{pos} wpos 相同时,IoU 越小, w n e g w_{neg} wneg 越大。因此, w n e g w_{neg} wneg 可以进一步区分具有几乎相同 pos 权值的模糊锚点。示例见图1。
4. 边界 box 细化
由于pos和负权函数都以 IoU 作为输入,更精确的 IoU 可以获得更高质量的样本,有利于更强特征的学习。
基于此,作者提出了一个可学习的预测模块来细化边界 Box。如图4,橙色框为粗糙定位框,在经过预测偏移量图细化为绿色精细框。对于当前锚定框的预测图 O ( j , i ) O(j,i) O(j,i) 的中心 ( i , j ) (i,j) (i,j), { ∆ l , ∆ t , ∆ r , ∆ b } \{∆l,∆t,∆r,∆b\} {∆l,∆t,∆r,∆b} 分别代表其与左、上、右、下的距离。
首先生成位置(j,i)的粗包围框(橙色框)。然后根据四个边点(绿色点)预测四个边界点(橙色点)。最后,一个更好的包围盒(绿框)由四个边界点的预测结果聚合而成。(这个绿色框是否为真实框?)

由于靠近物体边界的点更有可能预测准确的位置,在预测模块中基于粗边界框为每条边生成一个边界点,四个边界点的坐标为:

其中 { ∆ l x , ∆ l y , ∆ t x , ∆ t y , ∆ r x , ∆ r y , ∆ b x , ∆ b y } \{∆^x_l,∆^y_l,∆^x_t,∆^y_t,∆^x_r,∆^y_r,∆^x_b,∆^y_b\} {∆lx,∆ly,∆tx,∆ty,∆rx,∆ry,∆bx,∆by} 是细化模块的输出。
改进后的偏移量图 O ′ O' O′ 为精细结果:
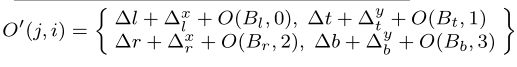
(这里的 O ( B l , 0 ) O(B_l,0) O(Bl,0) 如何得到)
5. 损失函数
DW 可应用于现有的大多数密度探测器。这里用到 FCOS 实现DW。如图2所示,整个网络结构由骨干网、FPN和检测头组成。在损失上,将中心分支和分类分支的输出相乘得到最终的 cls 分数,完整的损失定义如下:
![]()
其中 β β β 是一个平衡因子,与公式3中相同
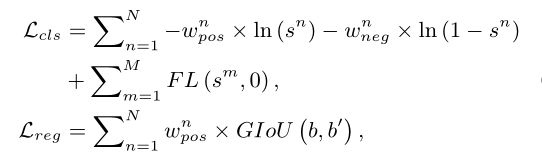
其中 N N N 和 M M M 分别为候选集中和外的锚点总数,FL 为 Fo cal Loss , GIoU为回归损失, s s s 为预测cls得分, b b b 和 b ′ b' b′ 分别是预测框和真实框的位置。
实验
- 数据集:COCO
- 实验细节:在ImageNet上预先训练的ResNet-50, FPN作为主干网络,大多数模型的训练用12个epoch(1×)。初始学习率为 0.01 ,并在8和11轮之后衰减10倍。800像素的图像尺度进行训练和测试,批处理总大小为16(每个GPU 2张图像)。在推论中,用0.05的阈值过滤出背景框,用0.6的阈值删除冗余框,以得到最终的预测结果。 γ 1 γ_1 γ1、 γ 2 γ_2 γ2、 β β β 和 µ µ µ 的分别为2,2,5和5。
1. 消融实验
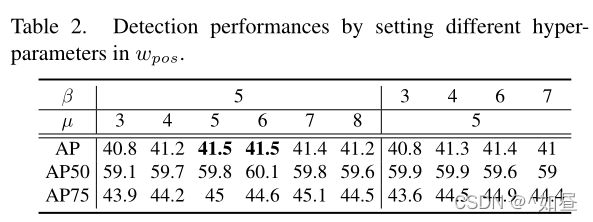
pos 权值超参数:两个超参数 β β β 和 μ μ μ。 β β β 在一致性度量 t t t 中平衡了 cls 评分和 IoU,随着 β β β 的增加,IoU 的贡献程度也增加。 µ µ µ 控制 pos 权重的相对尺度。对于最一致的样本,较大的 µ µ µ 使其具有相对较大的pos权重。由表二可得,最好的情况为, β = 5 , μ = 5 β = 5,μ = 5 β=5,μ=5。
neg 权值超参数: γ 1 γ_1 γ1 和 γ 2 γ_2 γ2 ,如表3所示,DW的性能对这两个超参数不敏感,其中,最佳为 γ 1 = 2 , γ 2 = 2 γ_1 = 2, γ_2 = 2 γ1=2,γ2=2。

候选集构造:测试了三种基于锚点到对应真实框中心距离的候选集构建方法。第一种方法是选择距离小于阈值的锚点,第二步是从每个级别的FPN中选择离我们最近的前k个锚点。第三种方法是给每个锚点一个中心,得到 e − r 2 e^{-r^2} e−r2 ,表4中可以看出AP性能在41.1和41.5之间波动较小,说明我们的DW对候选袋分离方法具有较强的鲁棒性。

neg 权值设计:如表5所示,仅使用pos权重会降低性能到39.5。这说明对于一些低重要性的困难锚定框,仅仅分配小的 pos 权值不足以减低其分数排名。但当他们被排在列表后面时,模型的 AP 更高。

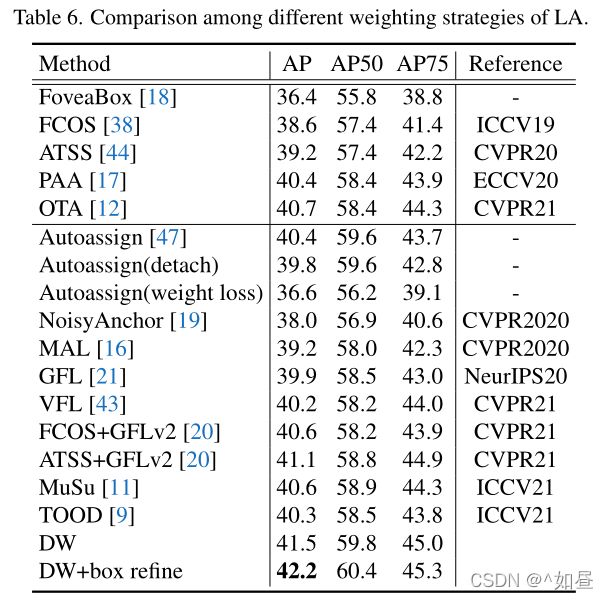
Box细化:41.5 AP - 42.2 AP。表7还显示,对 box 细化可以不断地提高具有不同主干网的DW的性能。
2. 对比实验
如表7

3. 讨论
DW可视化:图5所示,在DW中 pos 和 neg 权重主要集中在 GT 的中心区域,而 GFL 和 VFL 在一个更宽的区域分配权重。这种差异意味着 DW 可以更专注于重要的样本,减少容易的样本的贡献,比如那些靠近物体边界的样本,因此也更加稳健。同时,中心区域的锚点在DW中有不同的 (pos, neg) 权重对,而在 GFL 和 GFL 中,neg 权值与 pos 权值高度相关
VFL,为网络提供了更高的学习能力。

DW的限制:可能会影响小物体的训练效果。如表7所示,改进
小对象上的DW没有大对象上的高。为了缓解这一问题,可以根据对象大小动态设置不同的超参数,以平衡小目标和大目标之间的训练样本。
总结
作者提出了双加权 (DW),以训练精确的稠密目标探测器,通过从不同方面估计一致性和不一致性度量,动态地为每个锚点分配各自的正权和负权。同时,提出 box 细化,用于直接细化回归图上的框。ResNet-50的DW在进行和不进行 box 改进的情况下,分别达到了41.5 AP和42.2 AP,DW对不同的检测头也表现出了良好的通用性。
目标检测对社会的负面影响主要来自于对军事应用的滥用和隐私问题,在将该技术应用于现实生活之前,需要仔细考虑。