用户使用手册
我们的项目是:OpenEuler上下游分析
上游分析
1、爬取数据:
请您运行/code/UpStream/crawler.py
将上游分析的数据爬取至本地进行处理,如果您在爬取数据时出现了错误,请您登录OpenEuler的官方代码库,查看哪一个镜像源您可以使用,并替换main()中的link即可。
爬取成功,您会发现/code/UpStream/UpData的文件夹,里面存放了我们接下来需要的数据。
2、分析数据
请您运行/code/UpStream/upAnalysis.py。我们在上游分析中作业数据流的处理,您可以方便的一站式完成上游的分析任务。具体的实现细节,您可以查看/code/UpStream/upAnalysis.py中的代码部分。
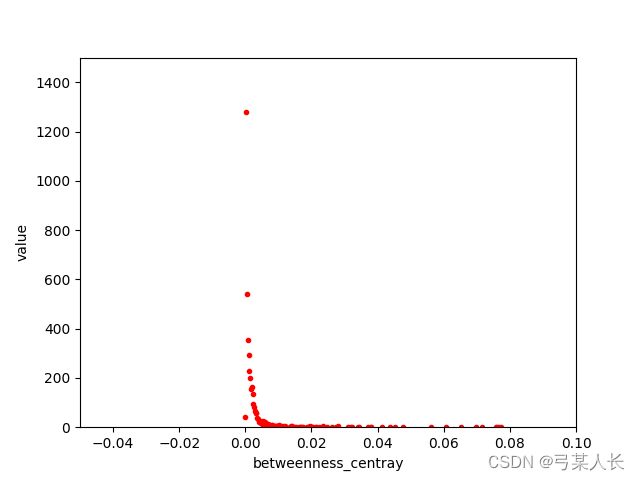
这里我们主要使用了入度出度,在此,我们会生成4个.csv和4张图像,它们分别存放在/code/UpStream/UpData/top10和/code/UpStream/UpData/pics中,您可以凭借相关的内容做出您自己的分析与理解,我们对此表示非常欢迎。
Tips:
我们的依赖关系不一定是全面的,当你找到了某一个包所依赖的其他包,你可以新建一个说明文档,并联系我们。其中,这个文档的命名为:
[包名]–[版本号].md
在文档内按照模板要求编辑该包的具体信息,模板如下:
# {在此填写包名}
{在此填写包描述}
## 版本号
{在此填写版本号}
## 作者信息
### 作者A
{在此填写作者A描述}
### 作者B
{在此填写作者B描述}
### 作者C
{在此填写作者C描述}
可以看到,该文件包含整个包的具体信息,包括:
- 包名
- 版本号
- 作者信息
下游分析
1、运行:
/code/DownStream/OpenEuler_Crawler.py中的main()
爬取仓库信息,此时爬取的内容被保存到result.html文件中
2、进入:
/code/DownStream/html_parser.py,将main()函数中的filename修改为:
result.html
运行parse(doc),即可得到OpenEuler_repo.csv文件,其中存放了所有的仓库。
3、回到(1)
运行repo(),爬取每一个仓库页面,保存到repo_result.html中
4、回到(2)
将filename修改为repo_result.html
运行parse_repo(doc),即可得到OpenEuler_repo_result.csv,其中保存了仓库名和星数与作者数
5、回到(2),运行parse_description(doc),即可得到OpenEuler_description.csv,存放了所有仓库的描述
6、进入:
/code/DownStream/topics_num_for_lda.py
首次使用请运行draw()获取推荐的主题数。coherence越大,主题数约合适。
我们已经得到了合适的主题数为7,所以代码中直接引用了7:
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=7, passes=30, random_state=1)
得到推荐主题数之后,运行build,即可得到一个网页,打开便是主题分析结果:
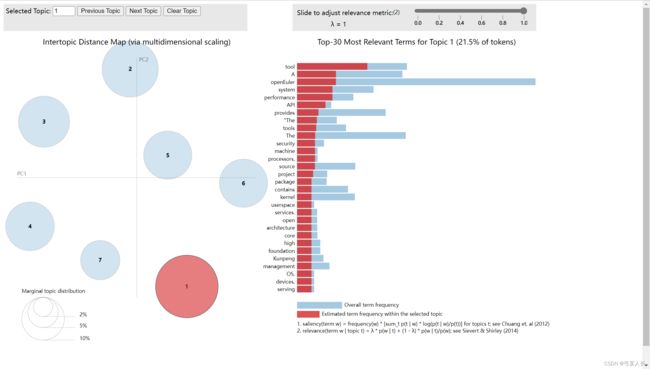
随后进入/code/DownStream/topics_sorted.py
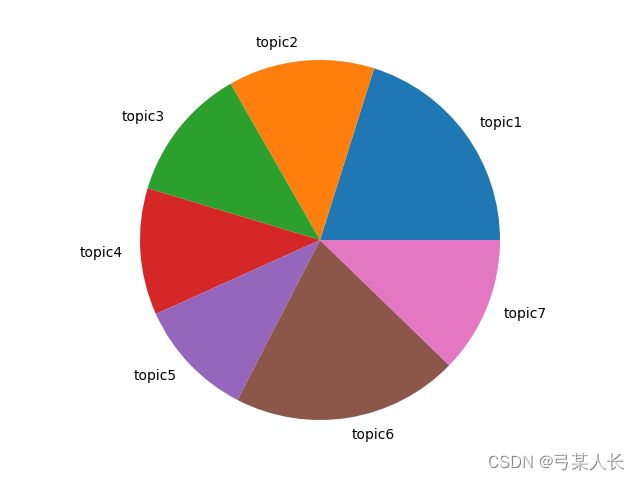
将分词好的主体进行定义,运行,得到饼状结果图: