使用toad做一张逻辑回归贷前评分卡
前言
对于金融信贷和保险行业,贷前/保前对客户的进行一个信用评级和打分是必要的,也就是需要构建一张评分卡,传统评分卡多是专家打分,基于机器学习的评分卡则更多是通过可解释更强的逻辑回归来构建,最近学习过程中,发现了一个第三方库,其中部分代码和功能还是较为有用的,这个项目作为一个学习过程中的记录。
由于数据特征被匿名化过,所以不进行分箱的调整,也不过多关注业务上的可解释性,仅记录从数据导入到建卡的一个流程。
所有代码和数据请点击数据、代码下载链接
fork后可下载
导入需要的库、读取数据
需要安装toad,加个镜像更快
pip install toad -i https://pypi.douban.com/simple
查看数据
obs_mth是时间
bad_ind是标签
uid是用户编码
其余10个特征(td_score jxl_score mj_score rh_score zzc_score zcx_score person_info finance_info credit_info act_info)被匿名化处理了
import toad
import pandas as pd
import numpy as np
data = pd.read_csv('/home/mw/input/A_data3225/Acard.csv')
print('Shape:',data.shape)
data.head(10)

共有2018年6、7、9、10、11五个月的数据
print('obs_mth:',data.obs_mth.unique())
obs_mth: [‘2018-10-31’ ‘2018-07-31’ ‘2018-09-30’ ‘2018-06-30’ ‘2018-11-30’]
选择三个月的数据作为训练数据,另外两个月作为时间外样本
train = data.loc[data.obs_mth.isin(['2018-06-30','2018-07-31','2018-09-30'])==True,:]
OOT = data.loc[data.obs_mth.isin(['2018-06-30','2018-07-31','2018-09-30'])==False,:]
print('train size:',train.shape,'\nOOT size:',OOT.shape)
train size: (65304, 13)
OOT size: (30502, 13)
EDA
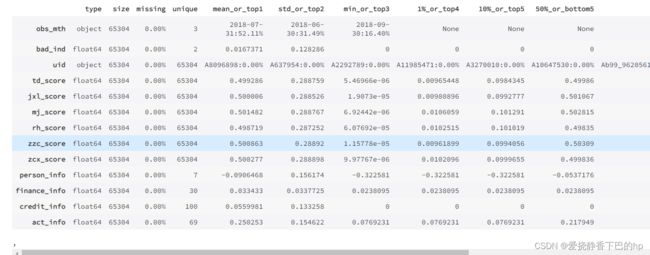
toad.detect(data)用于检测数据情况。
输出每列特征的统计性特征和其他信息,主要的信息包括:缺失值、unique values、数值变量的平均值、离散值变量的众数等
从下表我们可以看出,坏样本占比为0.0167
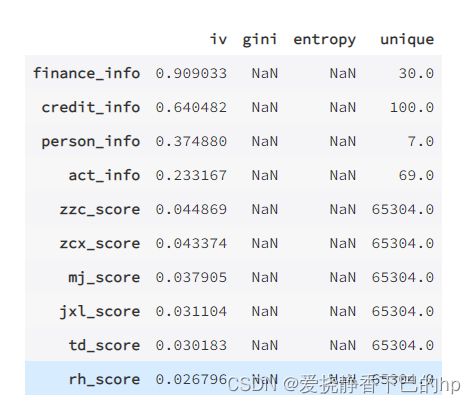
输出每个变量的iv值,gini,entropy,和unique values,结果以iv值排序。”target”为目标列,”iv_only”决定是否只输出iv值。
注意:
- 对于数据量大或高维度数据,建议使用iv_only=True
- 要去掉主键,日期等高unique values且不用于建模的特征
to_drop = ['uid','obs_mth'] # 去掉ID列和month列
toad.quality(train.drop(to_drop,axis=1),'bad_ind',iv_only=True)
特征选择
toad.selection.select(dataframe, target=’target’, empty=0.9, iv=0.02, corr=0.7, return_drop=False, exclude=None):
根据缺失值占比,iv值,和高相关性进行变量筛选,赋值为:
(1)empty=0.9: 若变量的缺失值大于0.9被删除
(2)iv=0.02: 若变量的iv值小于0.02被删除
(3)corr=0.5: 若两个相关性高于0.5时,iv值低的变量被删除
(4)return_drop=False: 若为True,function将返回被删去的变量列
(5)exclude=None: 明确不被删去的列名,输入为list格式
这里没有筛掉特征
train_selected, dropped = toad.selection.select(train,target = 'bad_ind', empty = 0.5, iv = 0.02, corr = 0.5, return_drop=True, exclude=['uid','obs_mth'])
print(dropped)
{‘empty’: array([], dtype=float64), ‘iv’: array([], dtype=object), ‘corr’: array([], dtype=object)}
可以看出,原数据没有特征被筛选掉,我们继续下面的步骤。
分箱
toad的分箱功能支持数值型数据和离散型分箱,默认分箱方法使用 卡方分箱。
卡方分箱
卡方分箱是基于卡方检验的一种分箱方式
它的基本思想:
对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
简单来说,卡方分箱首先会将所有值单独分为一箱,然后进行两两卡方检验,然后进行合并,再进行下一轮卡方检验,如此往复,直到满足预设值。
toad的分箱代码
toad.transform.Combiner 是用来分箱的class,分箱步骤如下:
*** initalise: ***c = toad.transform.Combiner()
训练分箱: c.fit(dataframe, y = ‘target’, method = ‘chi’, min_samples = None, n_bins = None, empty_separate = False)
y: 目标列
method: 分箱方法,支持’chi’ (卡方分箱), ‘dt’ (决策树分箱), ‘kmean’ , ‘quantile’ (等频分箱), ‘step’ (等步长分箱)
min_samples: 每箱至少包含样本量,可以是数字或者占比
n_bins: 箱数,若无法分出这么多箱数,则会分出最多的箱数
empty_separate: 是否将空箱单独分开
查看分箱节点:c.export()
手动调整分箱: c.load(dict)
apply分箱结果: c.transform(dataframe, labels=False):
labels: 是否将分箱结果转化成箱标签。False时输出0,1,2…(离散变量根据占比高低排序),True输出(-inf, 0], (0,10], (10, inf)。
注意:1. 注意删去不需要分箱的列,特别是ID列和时间列
# initialise
c = toad.transform.Combiner()
# 使用特征筛选后的数据进行训练:使用稳定的卡方分箱,规定每箱至少有5%数据, 空值将自动被归到最佳箱。
c.fit(train_selected.drop(to_drop, axis=1), y = 'bad_ind', method = 'chi', min_samples = 0.05) #empty_separate = False
print('person_info:',c.export()['person_info'])
person_info: [-0.2610139784946237, -0.1286774193548387, -0.05371756272401434, 0.013863440860215051, 0.06266021505376344, 0.07885304659498207]
观察分箱并调整
toad.plot的module提供了一部分的可视化功能,帮助调整分箱节点,因为数据特征匿名化,此出不再对特征分箱做调整
时间内观察: toad.plot.bin_plot(dataframe, x = None, target = ‘target)
bar代表了样本量占比,红线代表了正样本占比(e.g. 坏账率)
-
x: 需要观察的特征
-
target: 目标列
from toad.plot import bin_plot
%matplotlib inline
col = 'td_score'
bin_plot(c.transform(train_selected[[col,'bad_ind']], labels=True), x=col, target='bad_ind')
跨时间观察: toad.plot.badrate_plot(dataframe, target = ‘target’, x = None, by = None)
输出不同时间段中每箱的正样本占比
-
target: 目标列
-
x: 时间列, string格式
-
by: 需要观察的特征
注意:时间列需要预先分好并设成string,不支持timestampe
开发者提供的文档中说敞口随时间变化而增大为优,代表了变量在更新的时间区分度更强。线之前没有交叉为优,代表分箱稳定。
只理解了后半句,以两个分箱为例,交叉代表某个时间点,两个分箱的坏贷率一致,甚至是相反了,所以分箱稳定性差。
下面看起来分箱的稳定性不太好,是需要调整的
from toad.plot import badrate_plot
col = 'td_score'
# 观察 'var_d2' 分别在时间内和OOT中的稳定性
badrate_plot(c.transform(train[[col,'bad_ind','obs_mth']], labels=True), target='bad_ind', x='obs_mth', by=col)
badrate_plot(c.transform(OOT[[col,'bad_ind','obs_mth']], labels=True), target='bad_ind', x='obs_mth', by=col)
badrate_plot(c.transform(data[[col,'bad_ind','obs_mth']], labels=True), target='bad_ind', x='obs_mth', by=col)
调整分箱:c.update(dict)
#设置分组
rule = {'td_score':[0.3,0.8]}
#调整分箱
c.update(rule)
#查看手动分箱稳定性
bin_plot(c.transform(train_selected[['td_score','bad_ind']], labels=True), x='td_score', target='bad_ind')
badrate_plot(c.transform(data[['td_score','bad_ind','obs_mth']], labels=True), target='bad_ind', x='obs_mth', by='td_score')
WOE转化
WOE转化在分箱调整好之后进行,步骤如下:
用调整好的Combiner转化数据: c.transform(dataframe, labels=False)
只会转化被分箱的变量
初始化woe transer: transer = toad.transform.WOETransformer()
fit_transform: transer.fit_transform(dataframe, target, exclude = None)
训练并输出woe转化的数据,用于转化train/时间内数据
target:目标列数据(非列名)
exclude: 不需要被WOE转化的列 注意:会转化所有列,包括未被分箱transform的列,通过 ‘exclude’ 删去不要WOE转化的列,特别是target列
*根据训练好的transer,转化test/OOT数据:*transer.transform(dataframe)
根据训练好的transer输出woe转化的数据,用于转化test/OOT数据。
# 初始化
transer = toad.transform.WOETransformer()
# combiner.transform() & transer.fit_transform() 转化训练数据,并去掉target列
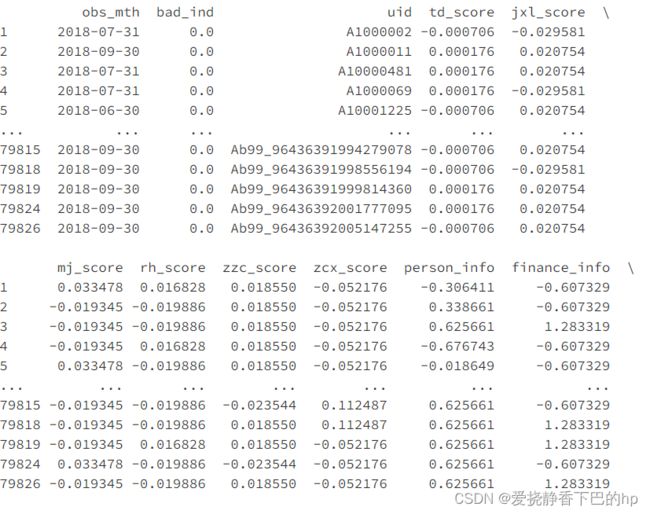
train_woe = transer.fit_transform(c.transform(train_selected), train_selected['bad_ind'], exclude=to_drop+['bad_ind'])
OOT_woe = transer.transform(c.transform(OOT))
print(train_woe)
逐步回归特征筛选
toad.selection.stepwise(dataframe, target=’target’, estimator=’ols’, direction=’both’, criterion=’aic’, max_iter=None, return_drop=False, exclude=None):
逐步回归特征筛选,支持向前,向后和双向(推荐)。
-
estimator: 用于拟合的模型,支持’ols’, ‘lr’, ‘lasso’, ‘ridge’
-
direction: 逐步回归的方向,支持’forward’, ‘backward’, ‘both’ (推荐)
-
criterion: 评判标准,支持’aic’, ‘bic’, ‘ks’, ‘auc’
-
max_iter: 最大循环次数
-
return_drop: 是否返回被剔除的列名
-
exclude: 不需要被训练的列名,比如ID列和时间列
tip: 经验证,direction = ‘both’效果最好。estimator = ‘ols’以及criterion = ‘aic’运行速度快且结果对逻辑回归建模有较好的代表性
# 将woe转化后的数据做逐步回归
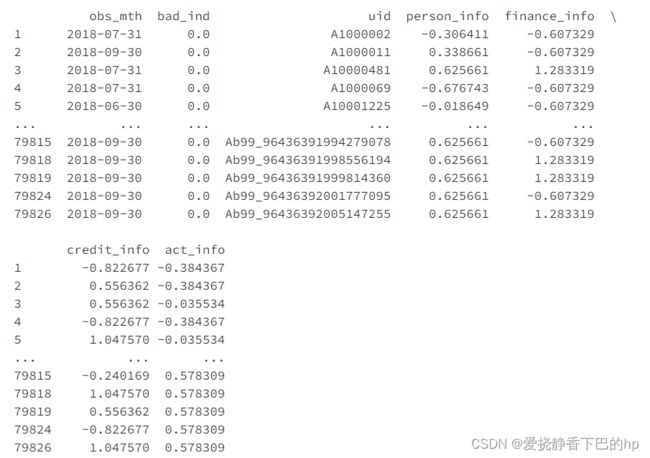
final_data = toad.selection.stepwise(train_woe,target = 'bad_ind', estimator='ols', direction = 'both', criterion = 'aic', exclude = to_drop)
# 将选出的变量应用于test/OOT数据
final_OOT = OOT_woe[final_data.columns]
print(final_data) # 逐步回归从10个变量中选出了4个
# 确定建模要用的变量
col = list(final_data.drop(to_drop+['bad_ind'],axis=1).columns)
print(col)
[‘person_info’, ‘finance_info’, ‘credit_info’, ‘act_info’]
PSI
psi
群体稳定性指标(Population Stability Index,PSI)是衡量模型的预测值与实际值偏差大小的指标,计算公式为:
PSI = SUM( (实际占比 - 预期占比)* ln(实际占比 / 预期占比) )
0-0.1为稳定
0.1-0.25表示稳定性一般
0.25以上就代表不稳定
toad代码直接调用
toad.metrics.PSI(df_train, df_test):
输出每列特征的PSI,可以用于检验WOE转化后的特征稳定性
toad.metrics.PSI(final_data[col], final_OOT[col])
person_info 0.127526
finance_info 0.136522
credit_info 0.095688
act_info 0.221254
dtype: float64
常用模型评分
toad也有集成,当然也可以使用sklearn
toad. metrics. KS, F1, AUC
# 用逻辑回归建模
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score,roc_curve,auc
lr = LogisticRegression()
lr.fit(final_data[col], final_data['bad_ind'])
# 预测训练和隔月的OOT
pred_train = lr.predict_proba(final_data[col])[:,1]
pred_oot = lr.predict_proba(final_OOT[col])[:,1]
pred_OOT_10 =lr.predict_proba(final_OOT.loc[final_OOT.obs_mth == '2018-10-31',col])[:,1]
pred_OOT_11 =lr.predict_proba(final_OOT.loc[final_OOT.obs_mth == '2018-11-30',col])[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(final_data['bad_ind'],pred_train)
fpr_lr_oot,tpr_lr_oot,_ = roc_curve(final_OOT['bad_ind'],pred_oot)
fpr_lr_o10,tpr_lr_o10,_ = roc_curve(final_OOT.loc[final_OOT.obs_mth == '2018-10-31',['bad_ind']],pred_OOT_10)
fpr_lr_o11,tpr_lr_o11,_ = roc_curve(final_OOT.loc[final_OOT.obs_mth == '2018-11-30',['bad_ind']],pred_OOT_11)
from toad.metrics import KS, AUC
train_auc = AUC(pred_train, final_data['bad_ind'])
oot_auc = AUC(pred_oot, final_OOT['bad_ind'])
oot_10_auc = AUC(pred_OOT_10, final_OOT.loc[final_OOT.obs_mth == '2018-10-31',['bad_ind']])
oot_11_auc = AUC(pred_OOT_11, final_OOT.loc[final_OOT.obs_mth == '2018-11-30',['bad_ind']])
print('train KS',KS(pred_train, final_data['bad_ind']))
print('train AUC',train_auc)
print('oot_auc AUC',oot_auc)
print('oot_10_auc AUC',oot_10_auc)
print('oot_11_auc AUC',oot_11_auc)
print('OOT结果')
print('10月 KS',KS(pred_OOT_10, final_OOT.loc[final_OOT.obs_mth == '2018-10-31','bad_ind']))
print('11月 KS',KS(pred_OOT_11, final_OOT.loc[final_OOT.obs_mth == '2018-11-30','bad_ind']))
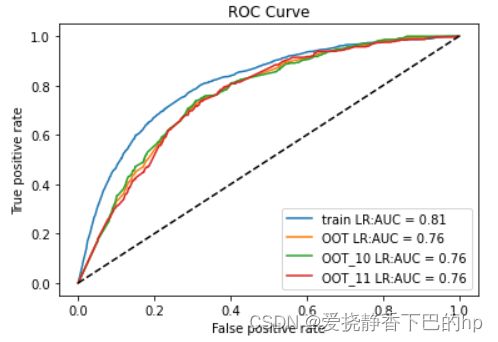
train KS 0.4826763171846684
train AUC 0.8087959037951603
oot_auc AUC 0.7601026044556345
oot_10_auc AUC 0.7625868161325697
oot_11_auc AUC 0.756943881551361
OOT结果
10月 KS 0.43015905746501576
11月 KS 0.41412676317598485
也可以通过图来展示
from matplotlib import pyplot as plt
%matplotlib inline
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR:AUC = %0.2f'% train_auc)
plt.plot(fpr_lr_oot,tpr_lr_oot,label = 'OOT LR:AUC = %0.2f'% oot_auc)
plt.plot(fpr_lr_o10,tpr_lr_o10,label = 'OOT_10 LR:AUC = %0.2f'% oot_10_auc)
plt.plot(fpr_lr_o11,tpr_lr_o11,label = 'OOT_11 LR:AUC = %0.2f'% oot_11_auc)
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
分数分箱评估
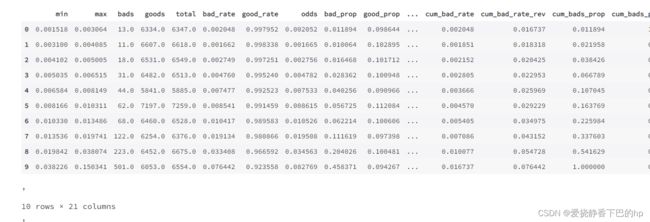
toad.metrics.KS_bucket(predicted_proba, y_true, bucket=10, method = ‘quantile’):
KS bucket输出模型预测分箱后评判信息,包括每组的分数区间,样本量,坏账率,KS等
-
bucket:分箱的数量
-
method:分箱方法,建议用’quantile’(等人数),或’step’ (等分数步长)
bad_rate为每组坏账率:(1)组之间的坏账率差距越大越好(2)可以用于观察是否有跳点(3)可以用与找最佳切点(4)可以对比
# 将预测等频分箱,观测每组的区别
toad.metrics.KS_bucket(pred_train, final_data['bad_ind'], bucket=10, method = 'quantile')
得分转换
具体转换原理可以看我之前发的项目点击跳转
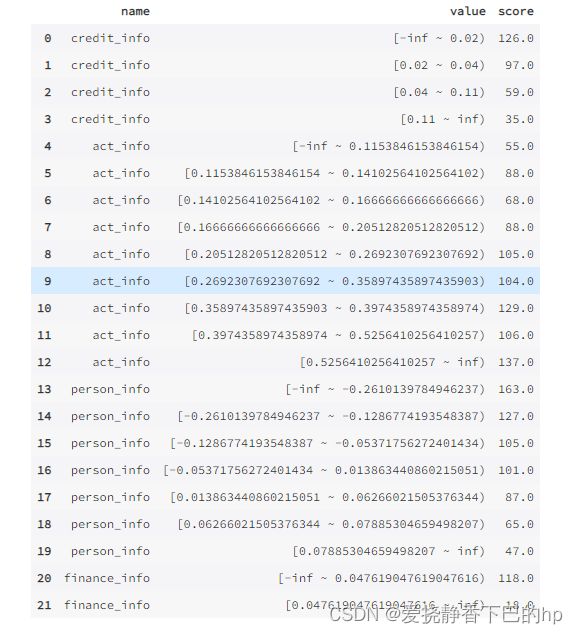
toad.ScoreCard( combiner = {}, transer = None, pdo = 60, rate = 2, base_odds = 20, base_score = 750, card = None, C=0.1,kwargs):
逻辑回归模型转标准评分卡,支持传入逻辑回归参数,进行调参。
-
combiner: 传入训练好的 toad.Combiner 对象
-
transer: 传入先前训练的 toad.WOETransformer 对象
-
pdo、rate、base_odds、base_score:
e.g. pdo=60, rate=2, base_odds=20,base_score=750
实际意义为当比率为1/20,输出基准评分750,当比率为基准比率2倍时,基准分下降60分 -
card: 支持传入专家评分卡
-
**kwargs: 支持传入逻辑回归参数(参数详见 sklearn.linear_model.LogisticRegression)
card = toad.ScoreCard(
combiner = c,
transer = transer,
class_weight = 'balanced',
#C=0.1,
base_score = 600,
base_odds = 35 ,
pdo = 50,
#rate = 2
)
card.fit(final_data[col], final_data['bad_ind'])
#输出标准评分卡
card1=card.export(to_frame=True)
card1

# 自定义转card整数的函数,并包装成scordcard函数需要的字典格式
def dict_type(card1):
card1.score=card1.score.round()
card1.value.fillna('nan',inplace=True)
namelist=list(set(card1.name))
myvalue=[]
for var in namelist:
ind_loc=card1.name==var
value_dict = dict(zip(card1.value.loc[ind_loc],card1.score.loc[ind_loc]))
myvalue=myvalue+[value_dict]
big_dict = dict(zip(namelist,myvalue))
return big_dict
# card2是四舍五入的新卡
card2 = dict_type(card1)
card2

到这一步我们就得到了一张完整的评分卡了
# 重新拟合card
card3 = toad.ScoreCard(
combiner = c,
transer = transer,
class_weight = 'balanced',
#C=0.1,
base_score = 600,
card = card2,
base_odds = 35 ,
pdo = 50,
rate = 2
)
final_card = card3.export(to_frame=True)
final_card
得到最终得分
final_score=pd.DataFrame(final_card.predict(data),index=data.index,columns=["score"])
final_score.to_excel("final_score.xlsx")
final_score.describe() #最终评分描述性统计预览