Tensorflow_01_Overview 全局概述
Brief 概述
机器学习与人工智能其实可以被归类为一个有历史的学科领域,在上世纪的六零年代就已经有第一批的科学家先祖们在这个领域投入精力,但是碍于当时的硬件科技发展限制,没有办法实现大规模的运算,甚至也没有单位能够提供规模庞大的同类型数据给到科学家们,因此这个领域一直沉寂着直到现今爆炸性的成长开了一片绚丽的故事。
不过这样的发展历程也意味着非常丰富的知识和方法累计在这门学科中,应对迅速到来的时代,我们需要的不是死磕,而是需要迅速掌控该门类的知识并有效率的参与其中,而 Tensorflow 模块有效的把许多知识背后的代码整合到了各种类与函数中,我们作为一个使用者,如果借助了这个模块的力量,需要的就只是适时的呼叫函数。
Tensorflow 模块是由 Google 公司在 2015 年 11 月份公开的深度学习模块,为了就是整合深度学习中那些常被用到,同时又具有一定深度遇难度的函数原理,因此作为一个使用者只需要了解其中的原理的使用场景和运算背后的大致逻辑即可,大致上分类有下面几个环节提供我们理解的方向:
- TensorBoard
- Low Level APIs
- High Level APIs
- Estimators
- Accelerators
Links: Tensorflow Official Website, Tensorflow GitHub, Tensorflow Models
Tensorflow 使用 C++ 和 CUDA 语言编写而成,其支持语言种类有 Python, C++, Go, Java, JavaScript 等,根据编写该模块的语言特性,它可以在众多系统上移植功能,从电脑到手机,再到大规模的 GPU 调用都可以办到。
该模块中实现计算的方法是经由搭建以操作符为枢纽的节点,从设置的参数出发,让节点与参数之间彼此连成线后,根据操作符的指示开始让参数之间做运算的过程,而全部的过程我们都可以在一个指向图中一览无疑,而节点又可以被视为是一种示例(instance),流窜在节点与线之间的数字则被称为张量(tensor),Tensorflow 因而得其名。
Setup 安装
Tensorflow 是一个整合了软硬件的模块包,提供一个良好的途径让我们能够更为便捷的建构属于自己的神经网络,并且有效的部署在自己的电脑中,它帮我们处理好了缓存部署与算力分配的问题,但也因为如此,安装方法的排列组合增加了一个维度,通常我们安装需要检视下面几点条件:
- 作业系统: windows, macOS, Ubuntu, or Raspbian
- GPU 或者 CPU 版本
- 其他语言支援包
全部流程包含了比较多繁琐的步骤,点击 此处 前往官方提供安装 Tensorflow 的介绍文档。
Content 内容
根据 Tensorflow 官方技术文档说明,我们需要了解的内容主题顺序如下:
- Operators 运算符
- Tensor Values 张量值的含义
- Graph and Board 图表和画板
- Variables 变量
- Training 训练
使用这个模块在创建数学模型的时候有两个最原始的元素参与其中: 1. 节点(node); 2. 边(edge)。 每个节点里面会被赋予一个任务需要执行,参数作为一个参与者到了这个节并做完任务后,就会沿着箭头所代表的边被送到下一个节点完成另一个任务,直到最后需要做完的任务被输出为止,如下图描述:
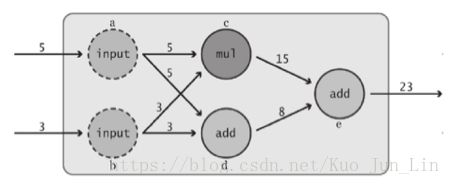
但是需要注意的是,创建了节点这件事情本身,实际上并没有执行的动作,创建仅仅是创建,如果需要执行代码,还需要我们使用一个函数 .Session() 把整个模型描述成一个绘话后,才能执行我们想要执行的运算,上图的简易模型如下代码。
每当节点在创建的时候,其实 Tensorflow 背后还帮我们在指向图中同样创建了一个流程图节点共我们审视数学框架的完整性和逻辑合理性,这个流程图即为 TensorBoard。我们一般不会在代码中看到流程图的定义的过程,原因是有一个预设的流程图已经为我们自动添加了描述的节点和边之间的关系,后面会更为详尽的介绍该图的功能和使用方法,其中包含了自定义多个流程图。
在实际上运行代码,指定节点输出一个运算结果的时候,节点之间的因果关系(依赖关系)是我们需要非常注意的重点。如上图,如果我们需要运行 e 节点,那么前面所有的运算都将称为运行 e 节点的时候必须提前做完的事情, Tensorflow 也会自动的运行它所需要的那些有因果关系的依赖节点,并只会运行那些节点。同理,如果运行的是 c 节点,那么跟 c 无关的节点就不会被运行到,如下面代码演示。
前面提到真正开始执行计算行为的时候,我们需要使用 .Session() 函数先创造一个绘话示例,然后用该示例执行节点内容,过程有了图之后变得非常直观,但每个绘话之间的独立性只有下面的范例可以看出不同,从这个角度来看,流程图就是一个主体,分发给了很多个经过 .Session() 创建的示例一个运算框架,至于发出去之后,每个示例里面发生了什么事情,都是彼此独立的个体互不影响,如下面代码演示。
p.s. feed_dict 方法会在下面内容深入提及。
import tensorflow as tf
a = tf.constant(5, name='input_a')
b = tf.constant(3, name='input_b')
c = tf.multiply(a, b, name='input_c')
d = tf.add(a, b, name='add_d')
e = tf.add(c, d, name='add_e')
sess_1 = tf.Session()
sess_2 = tf.Session()
print(sess_1.run(e))
print(sess_2.run(c, feed_dict={a: 15}))
### ----- Results as follow ----- ###
23
45
1. Operators 操作符
操作符是节点的主角,挑明了数据们一旦来到了这个站点(节点)之后,要做的事情是什么,是一种行为的描述。一般而言,指向图中的参数值会随者训练的次数增多而不断刷新,而只有含有状态的运算操作(如 Variable)才有保存下值的机会。下面是操作符的大致种类:
- 标量运算: add, subtract, multiply, div, exp, log, greater, less, equal
- 向量运算: Concat, Slice, Split, Constant, Rank, Shape, Shuffle
- 矩阵运算: MatMul, MatrixInverse, MatrixDeterminant
- 含状态的运算: Variable, Assign, AssignAdd
- 神经网络组件: SoftMax, Sigmoid, ReLU, Convolution2D, MaxPooling
- 储存与恢复: Save, Restore
- 队列与同步运算: Enqueue, Dequeue, MutexAcquire, MutexRelease
- 控制流: Merge, Switch, Enter, Leave, NextIteration
p.s. 点击 官方链接 可以一览所有操作符,且操作符不限于运算行为,还可以是其他很多的动作, 例如创建一个占着位置的“东西”等着一个时刻去 feed_dict。
2. Tensor Values 张量值
它是一个 Tensorflow 用来描述数值的一种主要手段,我们创建节点,并组织流程图的目的就是为了能够让这些张量值在里面流窜,Tensorflow 因而得名,上面的例子中我们使用的是 constant 常量,创建了两个输入节点,然后才对其运算。然而,多个节点表示需要更多的精力去管理他们,而张量思维就是一个为我们省去这类多个输入节点麻烦的方法。
张量可以看作是一个矩阵的别名,常量换句话说就是一个只有一个元素的一维矩阵,因此我们可以使用多维度,且多个元素的矩阵作为一个总体的输入,然后让操作符根据里面元素的值进行运算,得到同样的结果,下面是对上面代码的修改:
import tensorflow as tf
ab = tf.constant([5, 3], name='input_ab')
c = tf.reduce_prod(ab, name='prod_c')
d = tf.reduce_sum(ab, name='sum_d')
e = tf.add(c, d, name='add_e')
sess = tf.Session()
sess.run(e)
### ----- Results as follow ----- ###
23张量的维度对应到我们熟悉的数学专有名词如下:
- 1D: array 向量
- 2D: matrix 矩阵
- 3D: 3 Dimensional Tensor 三维张量 (三维以上则用维度表示)
Data Types 数据类型
说到张量值里面的数据类型,种类非常丰富,完整详情可以参考 官方网页 ,主要对数字默认皆为 32 位元的类型,并且 Tensorflow 的数据类型完美且紧密的和 Numpy 模块整合到了一起,紧密到了键入 tf.int32 == np.int32 回传的值是 True!
虽然说 Tensorflow 与 numpy 非常兼容,在 Tensorflow 的 Operators 中可以放入 numpy 的整数,浮点数,字符串,布尔值,列表与元组等,却需要注意如整数在 np 中只有 int32 类型,而到了 tf 中却有 16, 32, 64 等种类,如果不提前声明好的话,就不得不让模块去猜我们的心思,造成不必要的错误。
而有个函数 .string() 则是那个例外,我们可以非常顺利地把 np.string() 带入 tf 之中,但是却不能在 np 模块中找到任何一个能跟 tf.string() 完美匹配的方法,需要特别注意。
Definition of Tensor‘s Shape 张量的形状定义
定义一个张量的大小可以使用元组 (3, 4) 或是列表 [3, 4] 的形式操作,存在几个元素就表示几个维度,元素的值是多少,则表示该维度有几个值,如果填入的值是 None 则表示该维度的值个数不限定几个,这个设置一般放在 operator 里面的参数部位。
- code: shape=(3, 4, None) # One of the argument in an operator
feed_dict 方法
它不止是一个方法,同时还是一个观念,让我们可以更加明确的了解到节点创立的时候,并不包含了让节点执行动作的过程,也因为 Tensorflow 这样的特性,我们可以让流程先创立好,最后等到要运算真正开始执行的时候,再放入数字即可,就好比先打造出一个游乐园,等着人进来玩游戏,详情如下简单代码:
import tensorflow as tf
m = tf.add(5, 3)
n = tf.multiply(a, 3)
sess = tf.Session()
sess.run(n, feed_dict={a: 15})
### ----- Results as follow ----- ###
45
3. Graph and Board 图表和画板
如上面 「内容」 章节提及的内容,每当一个节点被创建的时候,有一个默认的 TensorBoard 板上会同样添加一个对应的节点,但是如果需要手动设置节点到我们喜欢的不同板上, Graph 对象就成了一个关键的源头方法,它可以让我们自由的创建图例,下面是对应的操作代码:
import tensorflow as tf
# This add node is put in the default TensorBoard graph
in_default_graph = tf.add(5, 3)
# We create another graph to load another node
g = tf.Graph()
with g.as_default():
a = tf.add(3, 4)
# If we want to have nodes created in default graph, here is the method to help us
default_graph = tf.get_default_graph()大多数情况下,用一个默认的数据流图表就可以了,如果是要定义多个相互之间彼此独立的模型,则下面三种代码的写法适合参考:
import tensorflow as tf
# 1. create a new graph and ignore the default graph
g1 = tf.Graph()
g2 = tf.Graph()
with g1.as_default():
a = tf.add(3, 4, name='add_a')
# define some nodes here to g1 graph
with g2.as_default():
b = tf.subtract(5, 2, name='sub_b')
# define some nodes here to g2 graph
# 2. get the default graph and appoint the graph to an object
g11 = tf.get_default_graph()
g12 = tf.Graph()
with g11.as_default():
c = tf.add(3, 4, name='add_c')
# define some nodes here to g11 graph
with g12.as_default():
d = tf.subtract(5, 2, name='sub_d')
# define some nodes here to g21 graph
# 3. the default graph can also be applied along with the other graph
g21 = tf.Graph()
e = tf.add(3, 4, name='add_e')
# define some nodes here in the default graph
with g21.as_default():
f = tf.subtract(5, 2, name='sub_f')
# define some nodes here to g21 graph
sess = tf.Session()
writer = tf.summary.FileWriter('./my_graph')
writer.add_graph(g21)
# or we can write the code in one line below
# writer = tf.summary.FileWriter('./my_graph', graph=g11)
# by the way, sess.graph == tf.get_default_graph() is True!!
sess.close()
writer.close()等到我们已经确定添加好所有节点到图表上之后,如果我们要把设置的结果可视化,开启 TensorBoard 的方法如上面代码最后一行,两个参数位置分别如下解释:
- 路径字符串: 根据我们命名的路径, tf 会自动创建一个文件夹,里面放着一个图表的描述档案,文件夹的路径则放置在我们代码启动的同一个路径下。
- 指明一个要被画上去的物件,可以是绘话里面的一个方法,让我们指定要被显示的绘话是什么,也可以后面使用 .add_graph() 方法添加要画上的物件。
如果一个项目比较大,图中的节点比较多,我们可能会需要使用一个大框框来涵盖所有的节点,并在图里只简单显示输入端和输出端,使得该大框框成为一个类似黑箱的存在,这时候我们需要使用到下面函数:
- tf.name_scope('give_a_name_here')
搭配 with 使用的话,就会变成:
with tf.name_scope('a_string_of_block_name'):
# the belonged nodes is constructed below.每个节点参数部分都有一个 name 标签,是用来为该节点取名字,让我们能够更为明了的在 TensorBoard 上面看出哪一个节点对应到的作用是什么,同时如果这些节点是一个占位节点,如 Variable, Constant, placeholder 等,我们还可以直接呼叫该节点的名字得到该占位节点里面值的复用。
等代码运行完毕后,找到文件夹路径,然后从命令提示资源开启该路径并键入:
- tensorboard --logdir='./the_name'
我们会得到一个本地网址,复制该网址到浏览器里面打开即可。
最后,等到所有事情做完了,如果有一个 .close() 的动作,可以避免一些不必要的错误,或是我们使用 with 的方法,也可以顺利关闭代码的行为。
4. Variables 变量
继上面张量小节提到的内容,我们除了 .Constant() 可以用之外,还有两个也非常适合拿来描述变量,甚至卡位用的函数:
- .placeholder()
- .Variable()
有别于直接键入数字,使用这些函数的好处是我们可以非常精确的声明该数值的属性和各种细节,进而免去所有因为数据类型不同造成的错误和麻烦。完整的声明也有助于我们在构建数学模型的时候提升思路的清晰度。
.placeholder() method
前面示范代码中我们都使用了单一不变的数值作为输入,但是这样造成建构好一个模型后没办法重复使用,因为数值是一样的。这个问题被 placeholder 给解开了,它白话文的意思是: 这边有一个变量,但我还没决定好它是什么,不过我可以先对其轮廓给一个定义,例如数据类型,张量大小,该变量在图表中的名称等等。
这样模糊的状态会持续到即将运行计算环节之前,我们会使用 feed_dict 参数以字典的模式导入数值到该位置,使其最终顺利运行,如下面代码:
import numpy as np
import tensorflow as tf
''' dtype is a necessity that we should announce in parameter.
shape is optional argument with a default None value on the other hand.'''
a = tf.placeholder(dtype=tf.int32, shape=[2], name='my_input')
b = tf.reduce_prod(a, name='prod_b')
c = tf.reduce_sum(a, name='sum_c')
d = tf.add(b, c, name='add_d')
sess = tf.Session()
the_dict = {a: np.array([5, 3], dtype=np.int32)}
sess.run(d, feed_dict=the_dict)
### ----- Results as follow ----- ###
23
.Variable() method
它可以用来承载任意的数值,数字,向量,矩阵,多维张量等等都囊括其中,而为了让它更方便的被使用, tf 有许多创建变量的方法,常见使用的方法如下面列举:
- tf.zeros(shape=(None, None, ...), dtype=np.int32)
- tf.ones(shape=(None, None, ...), dtype=np.int32)
- tf.random_normal(shape=(None, None, ...), mean=0.0, stddev=2.0)
- tf.truncated_normal(shape=(None, None, ...), mean=0.0, stddev=1.0)
- tf.random_uniform(shape=(None, None, ...), minval=0, maxval=10)
- Official website for more details
因为 .Variable() 方法的好用和普遍性,我们在创建好节点后并在执行运算前,需要对它们做初始化,可以是个别的也可以是全部一起的,代码如下:
- individual: tf.initialize_variables([var], name='init_var')
- overall: tf.initialize_all_variables()
如果代码执行过程中希望“取代”该变量原本的值,那么有另一个方法可以使用:
- .assign()
下面是上面列举方法的示范代码:
import numpy as np
import tensorflow as tf
a = tf.Variable(tf.ones(shape=[1], dtype=np.float32))
b = tf.Variable(tf.random_normal(shape=[1], dtype=np.float32,
mean=0.0, stddev=2.0))
c = a.assign(a*2)
d = tf.add(b, c, name='add_d')
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(3):
print(sess.run(d))
sess.run(tf.assign_add(a, np.array([3], dtype=np.float32)))
### ----- Results as below ----- ###
[0.70822]
[2.70822]
[6.70822]
array([11.], dtype=float32)如果对于某些参数我们不乐见上面示例般一轮一轮的迭代数值,可以在 .Variable() 中添加如下代码:
- tf.Variable(0, trainable=False)
如此一来就可以锁定变量值。
5. Training 训练
根据上面我们描述的内容和观念,接着我们可以开始尝试编造一个模型,并且用神经网络原理训练该模型的结果逼近到我们所预期的答案上,以下是代码的逻辑步骤:
- 引入我们需要使用的模块包,并原地创建需要的数据和方程式
- 使用神经网络的线性模型 y = wx + b,并用 tf 创建变量的方法创建需要的节点
- 计算随机给出的数字和我们的方程式相差大小
- 使用 tf 里面的梯度下降其中一个方法,并设置学习效率
- 开始使用该方法寻找方程式的最小值
- 初始化完了所有的 tf 的变量后,开启 100 次循环,表示训练次数
- 打印出结果结束
详细代码如下展示:
import numpy as np
import tensorflow as tf
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
weight = tf.Variable(tf.random_uniform(shape=[1], minval=-1.0, maxval=1.0))
bias = tf.Variable(tf.zeros(shape=[1]))
y = weight * x_data + bias
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
training = optimizer.minimize(loss)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for step in range(101):
sess.run(training)
if step % 10 == 0:
print('Round {}, weight: {}, bias: {}'
.format(step, sess.run(weight[0]), sess.run(bias[0])))
### ----- Results as follow ----- ###
Round 0, weight: 0.6381282806396484, bias: 0.005576512776315212
Round 10, weight: 0.3652426600456238, bias: 0.15702839195728302
Round 20, weight: 0.23029674589633942, bias: 0.22976720333099365
Round 30, weight: 0.16400647163391113, bias: 0.2654991149902344
Round 40, weight: 0.13144227862358093, bias: 0.2830519378185272
Round 50, weight: 0.115445576608181, bias: 0.29167452454566956
Round 60, weight: 0.10758741945028305, bias: 0.2959102392196655
Round 70, weight: 0.10372722148895264, bias: 0.29799094796180725
Round 80, weight: 0.10183093696832657, bias: 0.2990131080150604
Round 90, weight: 0.10089942812919617, bias: 0.2995151877403259
Round 100, weight: 0.1004418358206749, bias: 0.2997618615627289
下一篇文章: Tensorflow_02_Useful Functions 常用函数大全