r语言相关性分析_R语言的相关性分析

花花写于2020-04-06,TCGA和R包都告一段落,这几天开始学些统计学知识。收集了一些资料,statquest在B站有了中英字幕版(直接搜索statquest即可),也有成套的中文学习笔记可供参考,学习难度下降了不少。笔记链接:https://www.yuque.com/biotrainee/biostat统计学的知识点比较琐碎,很难整理,正在克服困难中。。。
1.示例数据
x1:R语言内置数据集iris的前4列。 x2:R语言内置数据集state.x77
x = iris[,-5]x2 = state.x77state.x77列名的含义:Population:截至1975年7月1日的人口估计Income:人均收入(1974)Illiteracy:文盲率(1970年,占人口百分比)Life Exp:预期寿命(1969-71年)Murder:每10万人的谋杀和非过失杀人率(1976)HS Grad 高中毕业生百分比(1970)Frost:首都或大城市中最低温度低于冰点(1931-1960)的平均天数Area:土地面积(平方英里)
2.协方差
使用cov()函数计算。
关于协方差:cov(x,y)>0,表示x、y的变化为正趋势,<0为负趋势,=0为无趋势。协方差对数据的变化范围敏感,无法反应变化趋势的强弱和离散程度,但它是一些高级分析的基石。
cov(x$Sepal.Length,x$Petal.Length)#> [1] 1.274315cov(x)#> Sepal.Length Sepal.Width Petal.Length Petal.Width#> Sepal.Length 0.6856935 -0.0424340 1.2743154 0.5162707#> Sepal.Width -0.0424340 0.1899794 -0.3296564 -0.1216394#> Petal.Length 1.2743154 -0.3296564 3.1162779 1.2956094#> Petal.Width 0.5162707 -0.1216394 1.2956094 0.5810063pheatmap::pheatmap(cov(x))
image.png
3.相关
3.1计算相关性系数
cor函数可计算三种相关性系数:pearson,kendall和spearman,默认是pearson。pearson是参数检验,需要两个向量均服从正态分布。另外两个为非参数检验。
- 输入值为两个向量
cor(x$Sepal.Length,x$Petal.Length)#> [1] 0.8717538cor(x$Sepal.Length,x$Petal.Length,method = "kendall")#> [1] 0.7185159cor(x$Sepal.Length,x$Petal.Length,method = "spearman")#> [1] 0.8818981-输入值为一个数值型数据框/矩阵
cor(x)#> Sepal.Length Sepal.Width Petal.Length Petal.Width#> Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411#> Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259#> Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654#> Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000pheatmap::pheatmap(cor(x))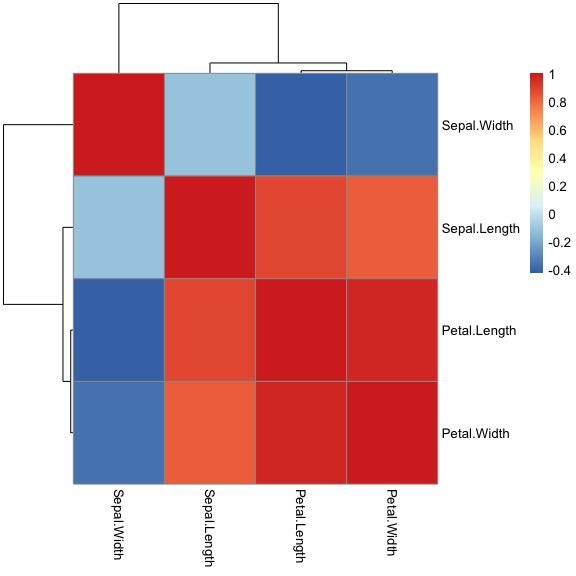
image.png
可见,计算的结果是x的4个变量(4列)两两之间的相关性。
3.2 相关系数的显著性检验
cor.test(x$Sepal.Length,x$Petal.Length)#> #> Pearson's product-moment correlation#> #> data: x$Sepal.Length and x$Petal.Length#> t = 21.646, df = 148, p-value alternative hypothesis: true correlation is not equal to 0#> 95 percent confidence interval:#> 0.8270363 0.9055080#> sample estimates:#> cor #> 0.8717538cor.test(x$Sepal.Length,x$Petal.Length,method = "kendall")#> #> Kendall's rank correlation tau#> #> data: x$Sepal.Length and x$Petal.Length#> z = 12.647, p-value alternative hypothesis: true tau is not equal to 0#> sample estimates:#> tau #> 0.7185159cor.test(x$Sepal.Length,x$Petal.Length,method = "spearman")#> Warning in cor.test.default(x$Sepal.Length, x$Petal.Length, method =#> "spearman"): Cannot compute exact p-value with ties#> #> Spearman's rank correlation rho#> #> data: x$Sepal.Length and x$Petal.Length#> S = 66429, p-value alternative hypothesis: true rho is not equal to 0#> sample estimates:#> rho #> 0.8818981cor.test函数还有一个alternative参数,表示单边/双边检验。有三个取值:“two.sided”(双边检验), “less”, “greater”。 相关性系数大于0时,应使用greater; 小于0时,应使用less; 如果不指定,则默认“two.sided”。
4.偏相关
即在控制一个或多个其他变量时,两个变量之间的相互关系。(这里的变量都应是连续型变量)
控制某个变量,指的是排除该变量的影响。被控制的变量称为条件变量。
使用ggm::pcor()函数来计算。用法为:pcor(u, S)。
- u为一个表示列号的向量,前两个元素为研究对象,其他元素是条件变量。例如c(1,2,4,5),表示在控制4、5列的条件下,研究1和2列的相关性。
- S 是协方差矩阵
举个栗子
人口数量(第一列)和收入水平(第二列)都可能影响文盲率(第三列),如果直接分别计算相关性的话:
cor(x2[,1],x2[,3])#> [1] 0.1076224cor(x2[,2],x2[,3])#> [1] -0.4370752相关系数约为0.1和-4.3。控制其中一个变量计算另一个变量的影响,结果则不同。
#install.packages("ggm")library(ggm)#在控制收入的条件下,人口数量对文盲率的影响pcor(c(1,3,2),cov(x2))#> [1] 0.2257943#在控制人口的条件下,收入对文盲率的影响pcor(c(2,3,1),cov(x2))#> [1] -0.4725271偏相关系数为0.2和-0.47,相比原来,绝对值大了一些。
同样的道理,控制收入、文盲率的影响,研究人口与谋杀率的偏相关性:
pcor(c(1,5,2,3),cov(x2))#> [1] 0.3621683偏相关性的显著性检验
pcor.test(pcor(c(2,3,1),cov(x2)),q=3,n=50)#> $tval#> [1] -3.596675#> #> $df#> [1] 45#> #> $pvalue#> [1] 0.0007972922用法为:pcor.test(r, q, n)
r是偏相关性计算结果,q是变量数,n是样本数,在帮助文档中有描述。