现代操作系统原理与实践04:实验1:机器启动
目录
1 实验环境使用说明
1.1 环境部署
1.2 源码下载
1.3 代码编译
1.4 qemu运行
1.5 qemu调试
1.5.1 启动GDB Server
1.5.2 连接GDB Server
1.5.3 调试环境改进
2 编译后结果分析
2.1 磁盘中的Section
2.2 加载到内存中的Segment
2.2.1 Segment 0分析
2.2.2 Segment 1分析
3 实验代码分析
3.1 代码布局
3.2 重要编译配置文件
3.2.1 scripts/build.sh
3.2.2 CMakeLists.txt
3.2.3 boot/config.cmake
3.2.4 scripts/linker-aarch64.lds.in
3.2.5 kernel/CMakeList.txt
3.3 程序流程分析
3.3.1 入口点分析
3.3.2 init_c函数分析
3.3.3 start_kernel函数分析
4 实验1:完善内核打印流程
4.1 内核打印流程分析
4.1.1 kinfo函数分析
4.1.2 printk函数分析
4.1.3 simple_vsprintf函数分析
4.1.4 printk_write_num函数分析
4.1.5 prints函数分析
4.1.6 simple_outputchar函数分析
4.2 完善printk_write_num函数
4.3 实验结果
5 实验2:实现栈回溯
5.1 函数栈使用分析
5.1.1 函数栈相关寄存器
5.1.2 函数调用惯例
5.2 任务分析
5.3 函数实现
5.4 实验结果
1 实验环境使用说明
1.1 环境部署
实验环境基于Ubuntu 20.04构建,需要安装如下软件
# 安装git环境
sudo apt-get install git
# 不使用docker而直接编译的工具,编译lab时运行`./scripts/build.sh`
# 我们这里不使用docker编译
sudo apt-get install gcc-aarch64-linux-gnu
# 安装lab运行环境
sudo apt-get install make gdb-multiarch cmake ninja-build qemu-system-arm说明:环境部署可参考
ChCore实验环境配置
1.2 源码下载
实验代码gitee地址如下
ChCore-lab: 上海交通大学IPADS 《现代操作系统:原理与实现》chcore 课程实验实验文档请访问:《现代操作系统:原理与实现》主页(https://ipads.se.sjtu.edu.cn/mospi/) - Gitee.com

说明:此处默认下载的是lab1的实验代码,根据不同的实验可以切换分支

1.3 代码编译
执行如下命令,可实现对工程的编译
/scripts/build.sh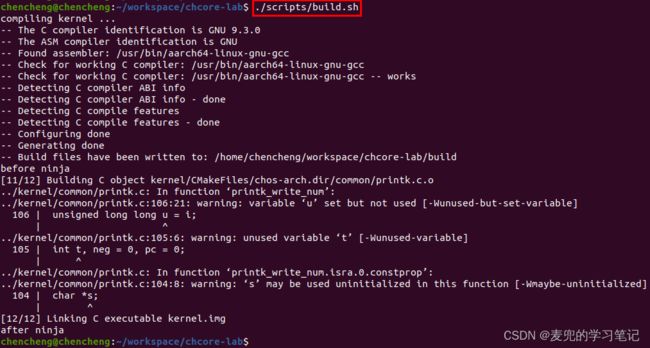
说明1:实验代码使用CMake + ninja编译
说明2:实验代码还可以在docker中编译,我们目前不使用该方式
1.4 qemu运行
执行如下命令,可以在qemu中模拟运行编译出的镜像
make qemu命令执行效果如下,
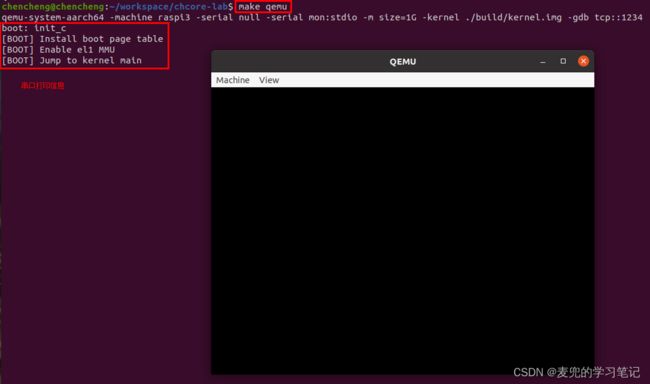
可见在运行时会启动一个图形化界面
说明:make qemu执行命令分析

① 使用的qemu程序为qemu-system-aarch64,可以在X86体系结构上模拟AArch64体系结构
② -machine raspi3:模拟的设备为树莓派3
③ -serial null:Redirect the virtual serial port to host character device null
④ serial mon:stdio:creates a multiplexed stdio backend connected to the serial port and the QEMU monitor
⑤ -m size=1G:设置虚拟机内存为1GB
⑥ -kernel $(BUILD_DIR)/kernel.img:指定kernel文件
⑦ -gdb tcp::1234:启动qemu中的GDB Server,并在tcp::1234上等待连接
1.5 qemu调试
1.5.1 启动GDB Server
首先在一个窗口中执行如下命令,启动qemu中的GDB Server
make qemu-gdb命令执行结果如下,

说明:make qemu-gdb执行命令分析
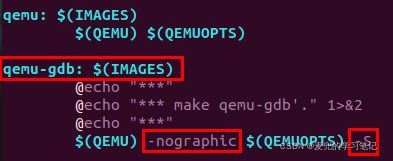
make qemu-gdb相较于make qemu,增加了2个命令行参数
① -nographic:启动的虚拟机没有图形化界面
② -S:Do not start CPU at startup(qemu会在执行第一条指令之前暂停)
1.5.2 连接GDB Server
在另一个窗口中执行如下命令,连接GDB Server并启动调试
make gdb命令执行效果如下,
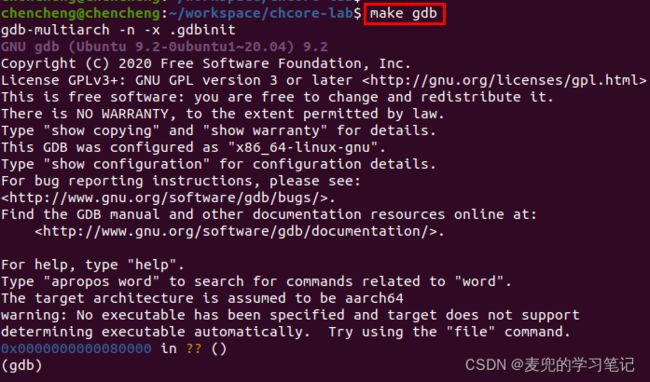
可见已进入GDB调试界面
说明1:进入调试的位置
① 通过GDB中的where命令,可见调试的第1条指令位于0x00080000,函数为_start

② gdb的where指令是backtrace指令的同义词,可以显示程序的当前位置及调用栈
说明2:make gdb执行命令分析

① 由于是在X86-64平台上使用GDB来调试AArch64代码,因此使用gdb-multiarch程序
② .gdbinit是启动gdb-multiarch的initial command file
说明3:.gdbinit文件分析

① set architecture aarch64
设置要调试的目标体系结构为aarch64
② target remote localhost:1234
通过网络连接GDB Server
③ file ./build/kernel.img
设置要调试的文件,GDB从该文件中读取符号表
1.5.3 调试环境改进
1.5.3.1 当前调试环境问题
目前调试时不能对照源码,因此无法达到调试的目的
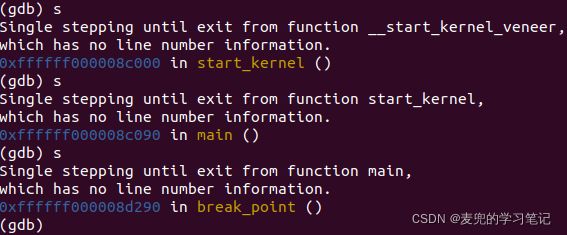
而造成该问题的原因,是因为GDB目前加载符号表是失败的

在GDB命令行中使用file命令再次加载kernel.img,可见该文件中没有调试用的符号表(debugging symbols)
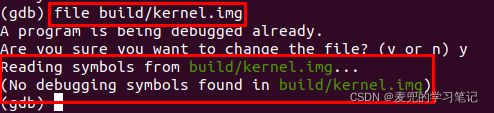
之所以会出现这个现象,是因为目前在编译代码时没有带-g选项,所以编译出的镜像不携带调试所需的符号表
1.5.3.2 改进方法
1. 编译时增加-g选项
修改文件:CMakeLists.txt

2. 启动gdb-multiarch时增加--tui选项
修改文件:Makefile

这样在调试时就可以查看对应的源码,修改之后调试效果如下,在调试到head.S时可以同步查看对应的源码

但是修改后的环境只能从kernel代码的head.S文件开始显示对应源代码,boot代码还不可以,目前尚未解决
3. 在调试环境下使用layout regs命令显示寄存器的值
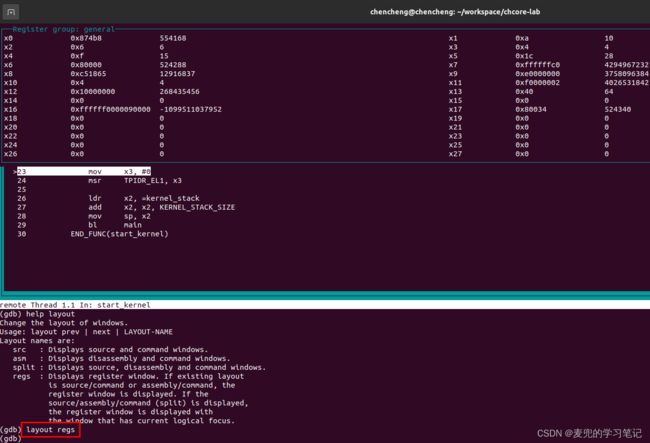
说明:增加-g编译选项后新增Section
① 增加-g编译选项前

② 增加-g编译选项后

可见在增加-g选项后,会增加调试相关的Section
2 编译后结果分析
2.1 磁盘中的Section
使用readelf -S命令查看磁盘中的Section

下面对比较重要的Section进行说明,
1. .init
保存bootloader的代码和数据(对应源码中的boot目录,该段的组成详见下文分析)
2. .text
保存内核程序代码
3. .data
保存初始化的全局变量或静态变量数据
4. .rodata
保存只读数据,包括一些不可修改的常量数据
5. .bss
记录未初始化或初始化为0的全局变量或静态变量,链接器只记录地址和大小,而不实际占用磁盘上的存储空间
2.2 加载到内存中的Segment
使用readelf -l命令查看将ELF文件kernel.img加载到内存后的Segment

说明:从Section与Segment的对应关系可见,相同类型的Section在加载到内存时,会被汇总到同一个Segment中
2.2.1 Segment 0分析
1. 属性为RWE(可读可写可执行)
2. 加载内存的物理地址为0x80000
3. 运行时的虚拟地址为0x80000
说明:.init段存储的是bootloader的代码和数据,他们被加载到物理地址0x80000处,运行时的虚拟地址也是0x80000
2.2.2 Segment 1分析
1. 属性为RWE(可读可写可执行)
2. 加载内存的物理地址为0x90000
3. 运行时的虚拟地址为0xFFFFFF0000090000
说明1:.text / .rodata / .eh_frame / .bss段存储的是内核的代码和数据,他们被加载到物理地址0x90000处,运行时的虚拟地址为0xFFFFFF0000090000
说明2:ELF文件的加载与执行
ELF文件的加载(load)与执行(execute)是启动一个程序的两个重要步骤,
① 加载
将程序的ELF文件按照链接规则从存储器中按照每个段的加载内存地址(Load Memory Address,LMA)拷贝到内存上指定的地址
② 执行
将ELF文件中的段"放到"(通过拷贝或页表映射等方式)虚拟内存地址(Virtual Memory Address,VMA),然后开始真正执行ELF文件中的代码
说明3:使用objdump -h命令可以查看ELF文件中每个段的LMA和VMA

大多数情况下,一个段的LMA和VMA是相同的,这里不同的原因,详见下文实验代码分析
3 实验代码分析
3.1 代码布局
实验代码中包含了bootloader和kernel两部分

3.2 重要编译配置文件
3.2.1 scripts/build.sh
scripts/build.sh为编译镜像时执行的顶层脚本

3.2.2 CMakeLists.txt
由于是在实验代码的顶层目录执行scripts/build.sh脚本,所以对应使用的配置文件为顶层目录的CMakeList.txt


3.2.3 boot/config.cmake
boot/config.cmake用于指定bootloader包含的源文件

3.2.4 scripts/linker-aarch64.lds.in
说明1:链接器脚本中的标号地址
下面根据kernel.img符号表验证链接器脚本中的标号地址

| 链接地址 |
符号类型 |
标号 |
| 0x80000 |
T(External Text) |
imag_start |
| 0x90000 |
A(External Absolute) |
init_end |
| 0xa00f4 |
R(External read only) |
_bss_start |
| 0xa00f4 |
R(External read only) |
_edata |
| 0xa8350 |
B(External zeroed data) |
_bss_end |
| 0xb0000 |
B(External zeroed data) |
_img_end |
可见各标号的地址是符合预期的
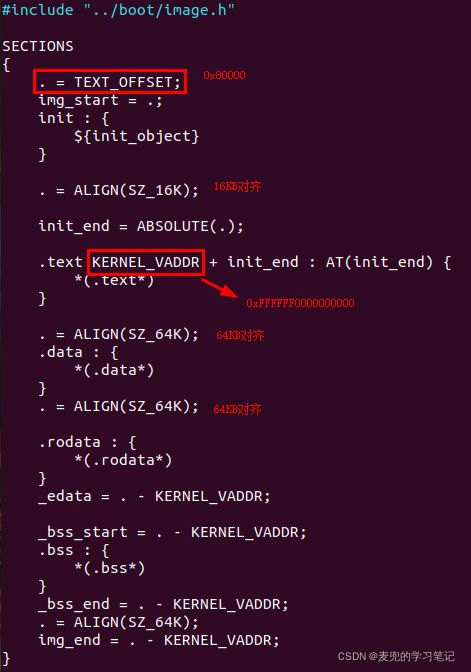
说明2:.text KERNEL_VADDR + init_end : AT(init_end)语法说明
该语法用于指定输出段的地址,完整语法为
section [address] : [AT(lma)]可见.text段的VMA为KERNEL_VADDR + init_end(0xFFFFFF0000090000),LMA为init_end(0x90000),这也就是kernel部分VMA与LMA不同的原因
说明3:如上文分析,kernel.img的入口标号为_start,该标号的地址为0x80000。之所以将该标号的地址在链接器脚本中设置为0x80000(TEXT_OFFSET),是因为树莓派在启动时会将kernel.img加载到内存0x80000处运行
关于树莓派启动流程,可参考02. 搭建实验环境 chapter 4.4
3.2.5 kernel/CMakeList.txt
kernel/CMakeList.txt用于指定kernel包含的源文件

3.3 程序流程分析
3.3.1 入口点分析
文件:boot/start.S

3.3.1.1 当前特权级
在进入调试后执行info regs命令,查看其中cpsr寄存器的值(bit[3:2] = 0b11),对照CurrentEL在cpsr中的位置,可知当前特权级为EL3


3.3.1.2 判断主核与从核
通过读取MPIDR_EL1寄存器判断当前处理器编号

MPIDR_EL1寄存器的具体实现由对应的处理器核架构定义,树莓派3使用的BCM 2837 SoC为Cortex-A53处理器核架构,需要参考《Arm Cortex-A53 MPCore Processor Technical Reference Manual》


Cortex-A53处理器核架构每个cluster最多支持4个核,使用MPIDR_EL1寄存器的bit[7:0]标识CPU ID
3.3.1.3 迁移特权级到EL1
1. 当前特权级为EL3,目标特权级为EL1,也就是说是要降低特权级
2. 根据ARMv8体系结构,只能通过从异常返回的方式(eret)降低特权级
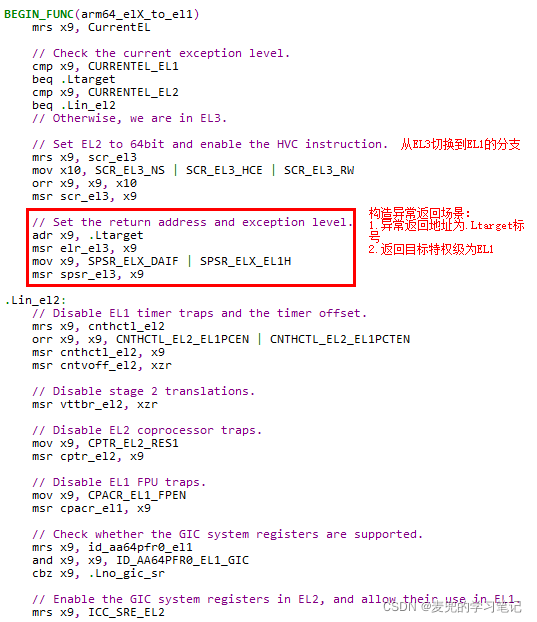
说明:关于异常返回地址与特权级的设置
arm64_elX_to_el1函数寄存器设置与ARMv8体系结构及Cortex-A53处理器核架构相关,这里只说明与异常返回地址与特权级相关的内容,其余内容随ARMv8体系结构的学习展开
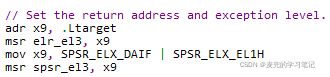
此处构造的是从EL3返回EL1的异常返回场景,其中
① 返回地址(ELR_EL3)设置为.Ltarget标签,该标签位于arm64_elX_to_el1函数返回之前


② 返回后的异常等级为EL1H(EL1 + 使用SP_EL1作为栈指针)同时关闭(mask)中断


3.3.1.4 设置栈

1. 执行到该步骤时,处理器核已经处于EL1异常等级,并且使用SP_EL1作为栈指针
通过调试验证,此时异常等级为EL1
![]()
2. 由于初始化要进入C语言阶段,因此需要进行栈的设置
说明:栈的位置
① 栈所使用的内存空间在boot/init_c.c文件中定义

可见此处为每个核在启动阶段准备了4KB作为栈使用
② 可以查看内核符号表,确定boot_cpu_stack符号的地址

③ 此处使用boot_cpu_stack + 4KB(0x88d00)设置当前栈指针,对于满减栈,这就是CPU0的栈顶
通过调试验证,设置的值符合预期

3.3.2 init_c函数分析
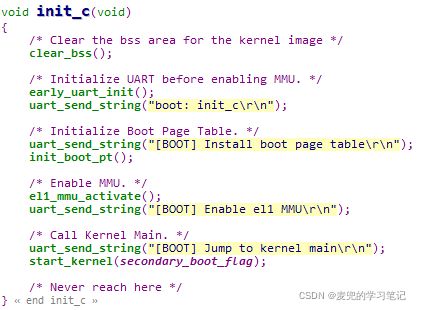
3.3.2.1 清空BSS段

在clear_bss函数中使用了链接器脚本中的符号,需要通过取地址才能获取BSS段的链接地址,相关内容可参考04. 代码重定位 & SDRAM初始化 chapter 1.3.4
3.3.2.2 初始化串口
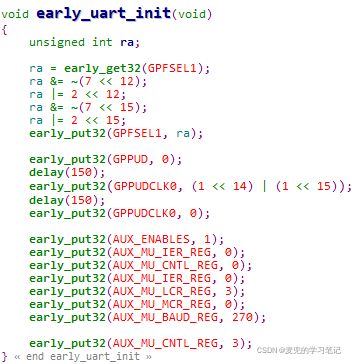
初始化串口通过设置相关寄存器实现,具体内容可参考树莓派芯片手册
3.3.2.3 初始化页表
3.3.2.3.1 初始化页表目的
1. 根据上文分析,编译内核镜像时,kernel部分的起始虚拟地址为0xFFFFFF0000090000,而加载的物理地址为0x90000
2. 目前程序在boot部分运行,尚未开启MMU,因此使用的是物理地址(从0x80000开始)
3. 在跳转到kernel部分运行之前,需要建立页表,将虚拟地址0xFFFFFF0000090000映射到物理地址0x90000处
3.3.2.3.2 ARMv8虚拟内存结构简述
以最常见的使用4KB页为例,



1. 页大小为4KB
2. 页目录项与页表项大小为8B,因此每页可以存储512个页目录项或页表项
3. 索引512个页目录项或页表项需要9位,因此48的虚拟地址被划分为9 + 9 + 9 + 9 + 12,即Level 0 ~ Level 3共4级页表
说明:参考上文中图D5-7,页目录中除了设置Page descriptor指向下级页表,还可以设置Block descriptor直接映射一个内存块(本课程实验代码使用的就是这种方式)
3.3.2.3.3 数据结构定义

1. 通过定义数组存储页表集,这里定义了从Level 0 ~ Level 2共3级页表,我们可以计算一下这些页表可以映射的内存大小
2. 可映射内存的最大值如下
512(Level 0页表索引) * 512(Level 1页表索引) * 512(Level 2页表索引)*
2MB(映射的Block大小)
= 2^48
即可以映射ARMv8中使用的48位完整虚拟地址空间可以看出,映射Block的大小2MB就是512 * 4KB,也就是Level 3页表所能映射的内存大小
3.3.2.3.4 宏定义

3.3.2.3.5 函数流程分析
1. 建立低端1GB物理内存恒等映射
① 将虚拟地址0x0 ~ 0x40000000映射到物理地址0x0 ~ 0x40000000
② 恒等映射页表后续将设置到TTRB0寄存器,也就是用户页表

2. 建立低端1GB物理内存线性映射
① 将虚拟地址0xFFFFFF0000000000 ~ 0xFFFFFF0040000000映射到物理地址0x0 ~ 0x40000000
② 线性映射页表后续将设置到TTRB1寄存器,也就是内核页表
③ 内核页表的设置与编译内核模块时的链接地址是匹配的

3. 建立后续1GB物理内存线性映射

① 将虚拟地址0xFFFFFF0040000000 ~ 0xFFFFFF0080000000映射到物理地址0x40000000 ~ 0x80000000
② 实现方式是在Level 1页表中设置Block映射项

3.3.2.4 使能MMU

3.3.2.4.1 设置MAIR_EL1寄存器
1. MAIR_EL1寄存器用于设置memory属性,最多可设置8种属性,页表格式中的AttrIndx[2:0]则是用于索引MAIR_EL1寄存器中设置的属性


2. el1_mmu_activate函数中设置的memory属性如下

3.3.2.4.2 设置TCR_EL1寄存器
TCR_EL1寄存器用于控制地址转换属性

实验代码设置了如下属性,
1. TTBR0_EL1的分页粒度为4KB
2. TTBR1_EL1页表分享属性为Inner Shareable
3. TTBR1_EL1的Outer cacheability属性为Normal memory, Outer Write-Back Read-Allocate Write-Allocate Cacheable
4. TTBR1_EL1的Inner cacheability属性为Normal memory, Inner Write-Back Read-Allocate Write-Allocate Cacheable.
5. TTBR1_EL1的region size为(64 - 48)
6. TTBR1_EL1的分页粒度为4KB
7. TTBR0_EL1页表分享属性为Inner Shareable
8. TTBR0_EL1的Outer cacheability属性为Normal memory, Outer Write-Back Read-Allocate Write-Allocate Cacheable
9. TTBR0_EL1的Inner cacheability属性为Normal memory, Outer Write-Back Read-Allocate Write-Allocate Cacheable
10. TTBR0_EL1的region size为(64 - 48)
11. Intermediate Physical Address Size为48位,即256TB
12. ASID Size为16位
3.3.2.4.3 设置TTBR寄存器
将之前设置好的页表集物理地址设置到TTBR寄存器中
3.3.2.4.4 设置SCTLR_EL1寄存器
SCTLR_EL1为系统控制寄存器

实验代码设置了如下属性,
1. 使能EL1 & EL0 stage 1地址转换
2. disable EL1 & EL0 load / store指令的alignment检查
3. disable EL0的栈alignment检查(否则栈操作需要16B对齐)
4. disable EL1的栈alignment检查(否则栈操作需要16B对齐)
5. disable EL0 & EL2特定指令的alignment检查
6. 使能EL0 & EL2 data access cacheable
7. 使能EL0 & EL2 instruction access cacheable
3.3.2.5 跳转到kernel执行
![]()
1. start_kernel函数在kernel/head.S文件中定义,属于kernel模块
2. 在init_c函数中调用start_kernel函数,就将控制从boot模块转移到了kernel模块
说明:start_kernel的虚拟地址为0xFFFFFF0000090000,由于已经设置了页表并使能MMU,所以可以跳转到该函数执行(背后还有一个原因,就是目前都是在EL1异常等级运行)

3.3.3 start_kernel函数分析

3.3.3.1 设置Thread ID

1. TPIDR_EL1寄存器用于设置EL1的software thread ID,该寄存器供操作系统使用,PE不会使用该寄存器
2. 实验代码中将TPIDR_EL1设置为当前处理器核的CPU ID
3.3.3.2 设置内核栈

1. 内核栈定义在kernel/main.c文件中
2. 内核为每个CPU准备了8KB作为栈使用
3. 此处设置的内核栈将替换之前在boot模块中设置的栈
4. 当前运行的是CPU 0,因此将SP设置为该核对应的内核栈栈顶
说明:kernel_stack虚拟地址
![]()
其中符号类型B表示External zeroed data
3.3.3.3 跳转到main函数执行
通过bl main指令,跳转到main函数执行
3.3.4 main函数分析
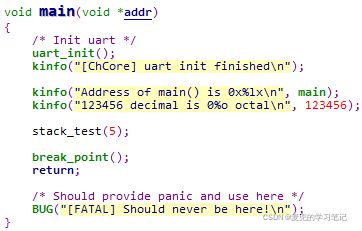
main函数就是本次实验要修改的部分
4 实验1:完善内核打印流程
4.1 内核打印流程分析
4.1.1 kinfo函数分析
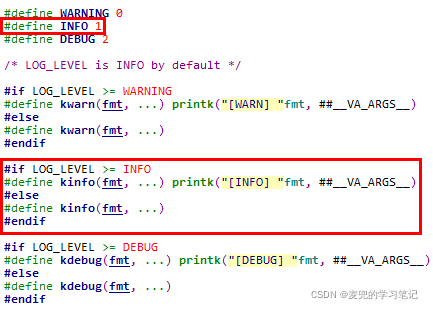
1. kinfo函数根据当前LOG_LEVEL的设置,实现为空函数或调用printk函数
2. LOG_LEVEL宏定义在CMakeLists.txt中,目前定义的LOG_LEVEL为1,因此kinfo可以打印
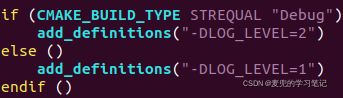
2. 调用printk函数时##记号的作用是当__VA_ARGS__为空时,消除fmt字符串最后的逗号,详情可参考Linux设备驱动01:Linux设备驱动概述_麦小兜的博客-CSDN博客 chapter 6.5
4.1.2 printk函数分析

1. printk函数的实现使用了C语言对可变参数函数的支持,详情可参考S5PV210体系结构与接口06:串口编程_麦小兜的博客-CSDN博客_s5pv210的接口有哪些 chapter 4.2
2. 经过va_start调用后,va指向函数的可变参数部分
4.1.3 simple_vsprintf函数分析

1. 当调用传递到simple_vsprintf函数时,fmt指向格式字符串,va指向可变参数。simple_vsprintf函数的工作就是根据fmt指向的格式字符串来解析va指向的可变参数
2. 在解析过程中,通过va_arg宏从可变参数中取出指定类型长度的数据
4.1.4 printk_write_num函数分析
4.1.4.1 printk_write_num函数功能
printk_write_num函数用于按进制打印数字,从另一个方面说,就是将一个"数值"按进制转换成字符并打印

4.1.4.2 printk_write_num函数参数

4.1.4.3 printk_write_num函数流程

1. 本实验要完善的就是将u按进制转换为字符串,并打印到print_buf数组中的功能
2. 在最后调用prints函数时,s指针应该指向转换后字符串的首地址
4.1.5 prints函数分析

4.1.6 simple_outputchar函数分析

4.2 完善printk_write_num函数

由于分离数值中的位数时,只能从最后一位开始,所以此处从后向前使用print_buf数组
4.3 实验结果
main函数中的kinfo函数测试用例如下

实验结果如下,可见打印结果正确
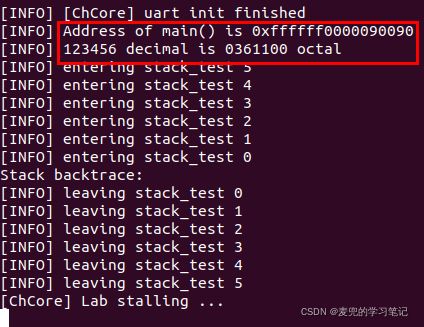
5 实验2:实现栈回溯
5.1 函数栈使用分析
5.1.1 函数栈相关寄存器
1. 栈指针(Stack Pointer,SP)
① 在AArch64中使用sp寄存器
② 指向当前正在使用的栈顶,即栈上的最低地址处(对于递减栈)
2. 帧指针(Frame Pointer,FP)
① 在AArch64中使用x29寄存器
② 指向当前正在使用的栈底,即栈上的最高地址处(对于递减栈)
说明1:FP和SP之间的内存空间,就是当前正在执行的函数的栈空间
说明2:在AArch64中,SP和FP均为64位地址,并且8B对齐
5.1.2 函数调用惯例
5.1.2.1 概述
根据调用惯例(calling convention),在进入函数时,该函数在真正执行函数内部逻辑之前,会有一些初始化栈的代码,通常包含如下操作,
1. 将上一个函数所使用的FP压栈,保存旧的FP
2. 将当前SP的值赋值到FP,用于构成新的栈底
3. 在新的栈中保存函数的返回地址、函数参数、寄存器值等
说明:函数返回地址保存在链接寄存器(Link Register,LR),在AArch64中使用x30寄存器
5.1.2.2 反汇编分析
1. 目标代码
首先说明一下我们要分析的C代码,我们要使用stack_test函数实现栈回溯功能。实验代码中将其优化等级设置为O1,目的是为了避免编译器优化导致无法回溯函数栈
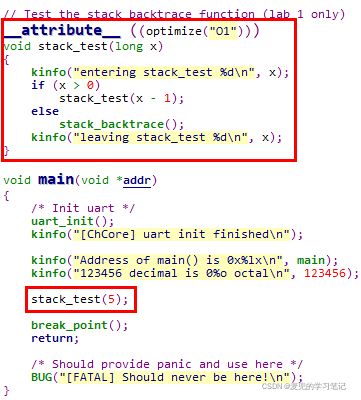
2. stack_test函数调用点反汇编
以下为调用stack_test函数的反汇编,可见使用x0寄存器传递参数

3. stack_test函数反汇编

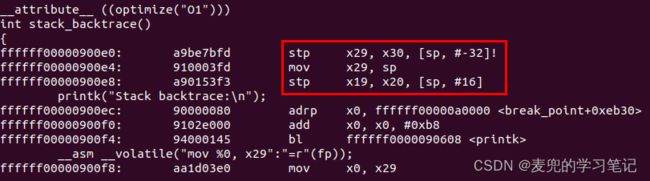
可见在stack_backtrace函数中,开辟了32B的栈,其中压入了FP、LR和函数参数,还有8B没有使用
说明:这里需要特别注意的是,与X86体系结构不同,在AArch64中是将新建的栈顶赋值给x29
在X86体系结构中,是将新建的栈底(高地址处)赋值给EBP寄存器
5.1.2.3 gdb分析
1. 调试断点


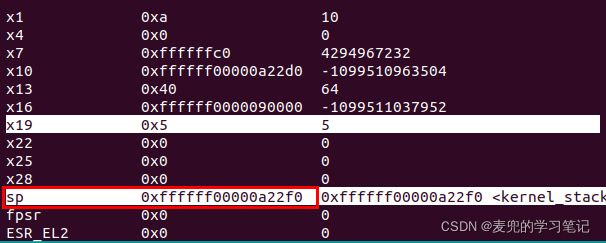
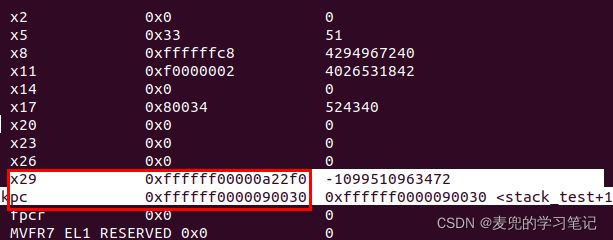
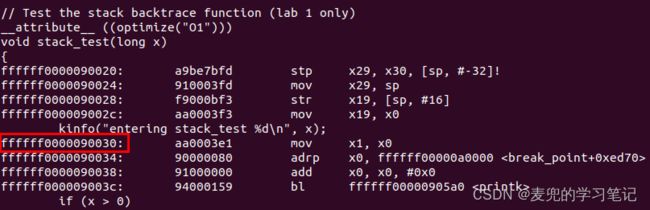

对照反汇编代码及内核符号表,相关寄存器状态如下,
① pc = 0xffffff0000090030
此时stack_test函数的压栈操作已经完成
② x30(lr) = 0xffffff00000900d8
指向跳转到stack_test函数后的下一条指令地址,也就是stack_test函数的返回地址
③ sp = 0xffffff00000a22f0
指向新栈的栈顶
④ x29(FP) = 0xffffff00000a22f0
mov x29, sp,将新建栈顶赋值给x29
⑤ x19 = 0x5
mov x19, x0,保存函数参数
2. 函数栈布局
使用如下指令查看函数栈布局
# x: gdb查看内存指令
# g:按8B显示
# $x29:内存起始地址为x29寄存器的值
x/g $x29
# 10g:显示10 * 8B
x/10g $29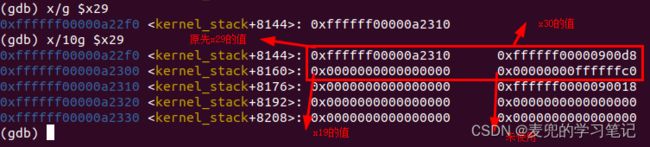
根据上述内容,stack_test函数栈布局如下。可见只要获取了FP寄存器,就可以实现栈的回溯
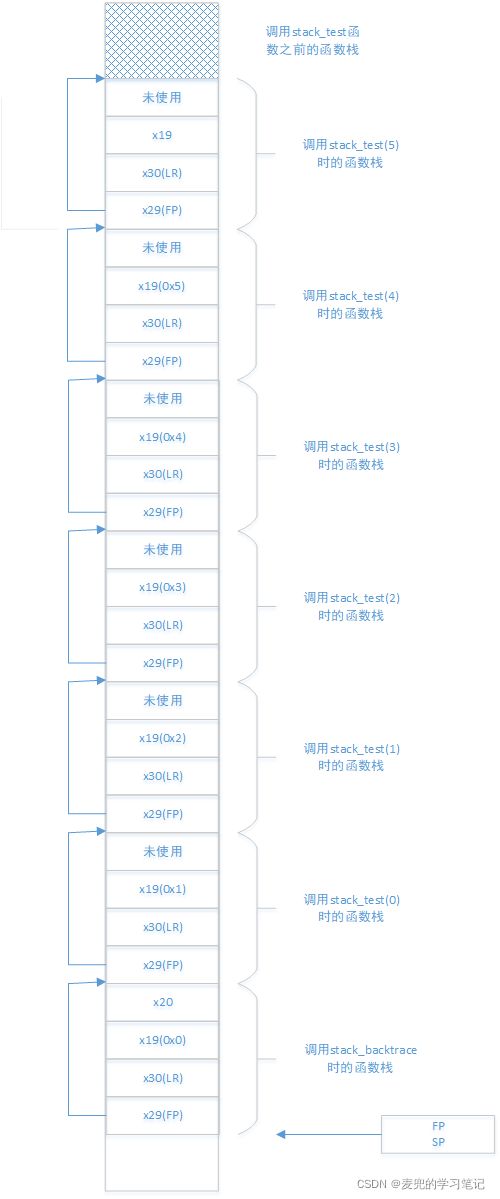
说明:最后一级stack_backtrace函数的构造方式如下
5.2 任务分析


1. 在main函数中以参数5调用stack_test函数
2. stack_test函数中会递归调用stack_test函数,直到递归出口时调用stack_backtrace函数进行栈回溯
3. 当调用到stack_backtrace函数时,已经递归调用了stack_test(5) ~ stack_test(0),因此可以回溯之前的函数调用栈
5.3 函数实现

1. 如上文stack_test函数栈布局所示,stack_test(0)的参数保存在下一级函数调用的栈中
2. stack_test(n > 0)的参数保存在stack_test(n - 1)的函数调用栈中
5.4 实验结果
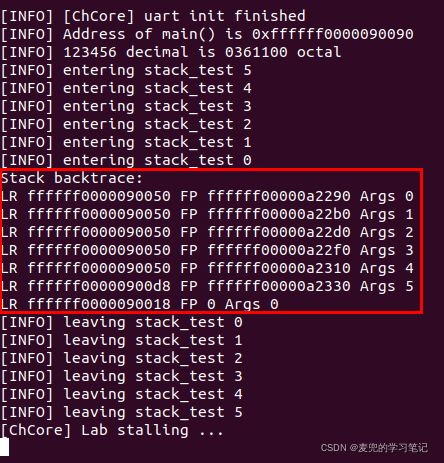
1. 0xffffff0000090050表示的函数返回值

当以参数4 ~ 0调用stack_test函数时的返回地址
2. 0xffffff00000900d8表示的函数返回值

当以参数5调用stack_test函数时的返回地址
3. 0xffffff0000090018表示的函数返回值

在start_kernel函数中跳转到main函数时的返回地址