【Kaggle实践记录】电商图片分类
一、题目介绍
题目地址
BoolArt-Image-Classification | KaggleImage-Classificationhttps://www.kaggle.com/competitions/boolart-image-classification本题目的目的是对电商图片进行分类,该项目训练集包括35551个样本,测试集有8889个样本。评估指标为准确率。
二、数据分析
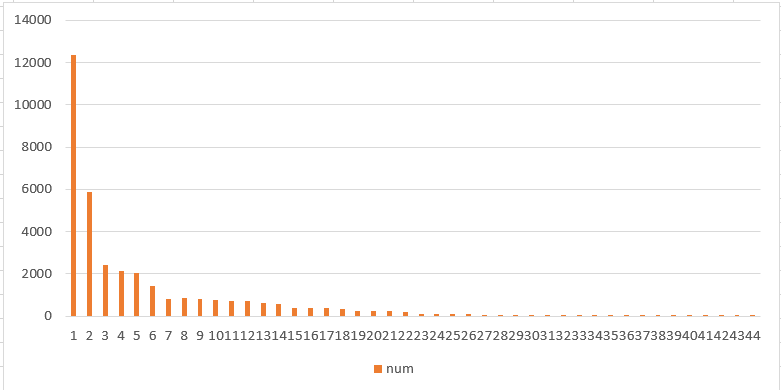
训练集的数据呈现明显的长尾特点,这在一定程度上会限制模型的性能。训练集图像尺寸均为80*60*3(其实不然,在实际训练过程中曾出现80*58*3的图片尺寸)。
三、解题思路
- 这是一个基本的图像分类问题,可以使用VGG,ResNet等卷积网络解决。这里选用今年来性能比较优异的ResNet模型。
- 图像数据集大小为400MB左右,可选择一次性读取入内存后使用(当然,这对计算机的内存形成了一定的压力),也可以根据需要随时从硬盘读取。这里选择第二种方式。
- 由于长尾现象的存在,我们可以对数据进行数据增强处理,包括随机剪裁,旋转,镜像,添加椒盐噪声等。
- 题目没有给出验证集,可以使用K折交叉验证在训练数据上区分训练集和验证集。
- 使用SGD,Adam等流行优化方法。
四、代码实现(Pytorch)
1、直接训练ResNet
数据集构建
import torch
import numpy as np
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class TrainDataset(Dataset):
def __init__(self, data_frame, transform=None, meta=False):
self.df = data_frame
self.file_names = data_frame['id'].values
self.labels = data_frame['target'].values
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
self.file_path = f'F:/boolart-image-classification/train_image/{self.file_names[idx]}.jpg'
image = np.array(Image.open(self.file_path).convert("RGB"))
image = Image.fromarray(image)
if self.transform:
image = self.transform(image)
label = torch.tensor(self.labels[idx]).long()
return image, label
class TestDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df['id'].values
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
self.file_path = f'F:/boolart-image-classification/test_image/{self.df[idx]}.jpg'
image = np.array(Image.open(self.file_path).convert("RGB"))
image = Image.fromarray(image)
if self.transform:
image = self.transform(image)
else:
image = image[np.newaxis, :, :]
image = torch.from_numpy(image).float()
return image, self.df[idx]模型构建(引用CVPR2019 MW-Net中的模型代码)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from torch.autograd import Variable
import torch.nn.init as init
def to_var(x, requires_grad=True):
if torch.cuda.is_available():
x = x.cuda()
return Variable(x, requires_grad=requires_grad)
class MetaModule(nn.Module):
# adopted from: Adrien Ecoffet https://github.com/AdrienLE
def params(self):
for name, param in self.named_params(self):
yield param
def named_leaves(self):
return []
def named_submodules(self):
return []
def named_params(self, curr_module=None, memo=None, prefix=''):
if memo is None:
memo = set()
if hasattr(curr_module, 'named_leaves'):
for name, p in curr_module.named_leaves():
if p is not None and p not in memo:
memo.add(p)
yield prefix + ('.' if prefix else '') + name, p
else:
for name, p in curr_module._parameters.items():
if p is not None and p not in memo:
memo.add(p)
yield prefix + ('.' if prefix else '') + name, p
for mname, module in curr_module.named_children():
submodule_prefix = prefix + ('.' if prefix else '') + mname
for name, p in self.named_params(module, memo, submodule_prefix):
yield name, p
def update_params(self, lr_inner, first_order=False, source_params=None, detach=False):
if source_params is not None:
for tgt, src in zip(self.named_params(self), source_params):
name_t, param_t = tgt
# name_s, param_s = src
# grad = param_s.grad
# name_s, param_s = src
grad = src
if first_order:
grad = to_var(grad.detach().data)
tmp = param_t - lr_inner * grad
self.set_param(self, name_t, tmp)
else:
for name, param in self.named_params(self):
if not detach:
grad = param.grad
if first_order:
grad = to_var(grad.detach().data)
tmp = param - lr_inner * grad
self.set_param(self, name, tmp)
else:
param = param.detach_() # https://blog.csdn.net/qq_39709535/article/details/81866686
self.set_param(self, name, param)
def set_param(self, curr_mod, name, param):
if '.' in name:
n = name.split('.')
module_name = n[0]
rest = '.'.join(n[1:])
for name, mod in curr_mod.named_children():
if module_name == name:
self.set_param(mod, rest, param)
break
else:
setattr(curr_mod, name, param)
def detach_params(self):
for name, param in self.named_params(self):
self.set_param(self, name, param.detach())
def copy(self, other, same_var=False):
for name, param in other.named_params():
if not same_var:
param = to_var(param.data.clone(), requires_grad=True)
self.set_param(name, param)
class MetaLinear(MetaModule):
def __init__(self, *args, **kwargs):
super().__init__()
ignore = nn.Linear(*args, **kwargs)
self.register_buffer('weight', to_var(ignore.weight.data, requires_grad=True))
self.register_buffer('bias', to_var(ignore.bias.data, requires_grad=True))
def forward(self, x):
return F.linear(x, self.weight, self.bias)
def named_leaves(self):
return [('weight', self.weight), ('bias', self.bias)]
class MetaConv2d(MetaModule):
def __init__(self, *args, **kwargs):
super().__init__()
ignore = nn.Conv2d(*args, **kwargs)
self.in_channels = ignore.in_channels
self.out_channels = ignore.out_channels
self.stride = ignore.stride
self.padding = ignore.padding
self.dilation = ignore.dilation
self.groups = ignore.groups
self.kernel_size = ignore.kernel_size
self.register_buffer('weight', to_var(ignore.weight.data, requires_grad=True))
if ignore.bias is not None:
self.register_buffer('bias', to_var(ignore.bias.data, requires_grad=True))
else:
self.register_buffer('bias', None)
def forward(self, x):
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
def named_leaves(self):
return [('weight', self.weight), ('bias', self.bias)]
class MetaConvTranspose2d(MetaModule):
def __init__(self, *args, **kwargs):
super().__init__()
ignore = nn.ConvTranspose2d(*args, **kwargs)
self.stride = ignore.stride
self.padding = ignore.padding
self.dilation = ignore.dilation
self.groups = ignore.groups
self.register_buffer('weight', to_var(ignore.weight.data, requires_grad=True))
if ignore.bias is not None:
self.register_buffer('bias', to_var(ignore.bias.data, requires_grad=True))
else:
self.register_buffer('bias', None)
def forward(self, x, output_size=None):
output_padding = self._output_padding(x, output_size)
return F.conv_transpose2d(x, self.weight, self.bias, self.stride, self.padding,
output_padding, self.groups, self.dilation)
def named_leaves(self):
return [('weight', self.weight), ('bias', self.bias)]
class MetaBatchNorm2d(MetaModule):
def __init__(self, *args, **kwargs):
super().__init__()
ignore = nn.BatchNorm2d(*args, **kwargs)
self.num_features = ignore.num_features
self.eps = ignore.eps
self.momentum = ignore.momentum
self.affine = ignore.affine
self.track_running_stats = ignore.track_running_stats
if self.affine:
self.register_buffer('weight', to_var(ignore.weight.data, requires_grad=True))
self.register_buffer('bias', to_var(ignore.bias.data, requires_grad=True))
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(self.num_features))
self.register_buffer('running_var', torch.ones(self.num_features))
else:
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
def forward(self, x):
return F.batch_norm(x, self.running_mean, self.running_var, self.weight, self.bias,
self.training or not self.track_running_stats, self.momentum, self.eps)
def named_leaves(self):
return [('weight', self.weight), ('bias', self.bias)]
class BasicBlock(MetaModule):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = MetaConv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = MetaBatchNorm2d(planes)
self.conv2 = MetaConv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = MetaBatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
MetaConv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
MetaBatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(MetaModule):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = MetaConv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = MetaBatchNorm2d(planes)
self.conv2 = MetaConv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = MetaBatchNorm2d(planes)
self.conv3 = MetaConv2d(planes, self.expansion * planes, kernel_size=1, bias=False)
self.bn3 = MetaBatchNorm2d(self.expansion * planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
MetaConv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
MetaBatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(MetaModule):
def __init__(self, block, num_blocks, num_classes):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = MetaConv2d(3, 64, kernel_size=3, stride=1, padding=0, bias=False)
self.bn1 = MetaBatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = MetaLinear(512 * block.expansion, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.25)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
# out = self.dropout(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18(num_classes):
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)
def ResNet34(num_classes):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes)
def ResNet50(num_classes):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes)
def ResNet101(num_classes):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes)
def ResNet152(num_classes):
return ResNet(Bottleneck, [3, 8, 36, 3], num_classes)3、训练过程
import argparse
import torch
import torch.nn.functional as F
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torchvision.transforms as transforms
from torch.optim import AdamW
from visdom import Visdom
from torchvision import models
import pandas as pd
from sklearn.model_selection import StratifiedKFold
import numpy as np
# from metrics import *
from dataset import TrainDataset
from model import ResNet152, ResNet50
parser = argparse.ArgumentParser(description='PyTorch WideResNet Training')
parser.add_argument('--epochs', default=40, type=int,
help='number of total epochs to run')
parser.add_argument('--start_epoch', default=0, type=int,
help='manual epoch number (useful on restarts)')
parser.add_argument('--batch_size', '--batch-size', default=32, type=int,
help='mini-batch size (default: 64)')
parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float,
help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, help='momentum')
parser.add_argument('--nesterov', default=True, type=bool, help='nesterov momentum')
parser.add_argument('--weight-decay', '--wd', default=5e-4, type=float,
help='weight decay (default: 5e-4)')
parser.add_argument('--layers', default=28, type=int,
help='total number of layers (default: 28)')
parser.add_argument('--widen-factor', default=10, type=int,
help='widen factor (default: 10)')
parser.add_argument('--no-augment', dest='augment', action='store_false',
help='whether to use standard augmentation (default: True)')
parser.add_argument('--resume', default='', type=str,
help='path to latest checkpoint (default: none)')
parser.add_argument('--seed', type=int, default=42)
parser.add_argument('--prefetch', type=int, default=0, help='Pre-fetching threads.')
parser.add_argument('--version', type=str, default="default", help='version')
parser.add_argument('--gpu', type=int, default=0)
parser.add_argument('--n_fold', type=int, default=5)
parser.add_argument('--max_grad_norm', type=float, default=500)
parser.set_defaults(augment=True)
args = parser.parse_args()
use_cuda = True
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
torch.cuda.set_device(args.gpu)
print()
print(args)
wind1 = Visdom()
wind2 = Visdom()
# 初始化窗口参数
wind1.line([[0., 0.]], [0.], win='loss_window', opts=dict(title='loss', legend=['train', 'test']))
wind2.line([0.], [0.], win='acc_window', opts=dict(title='accuracy'))
def adjust_learning_rate(optimizer, epochs):
lr = args.lr * ((0.1 ** int(epochs >= 20)) * (0.1 ** int(epochs >= 30)))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def build_dataset():
train = pd.read_csv('F:/boolart-image-classification/train.csv')
Fold = StratifiedKFold(n_splits=args.n_fold, shuffle=True, random_state=args.seed)
for n, (train_index, val_index) in enumerate(Fold.split(train, np.array(train['target']))):
train.loc[val_index, 'fold'] = int(n)
train['fold'] = train['fold'].astype(int)
fold = 0
folds = train
trn_idx = folds[folds['fold'] != fold].index
val_idx = folds[folds['fold'] == fold].index
train_folds = folds.loc[trn_idx].reset_index(drop=True)
valid_folds = folds.loc[val_idx].reset_index(drop=True)
valid_labels = valid_folds['target'].values
normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])
if args.augment:
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: F.pad(x.unsqueeze(0), (4, 4, 4, 4), mode='reflect').squeeze()),
transforms.ToPILImage(),
# transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.Resize([32, 32]),
transforms.ToTensor(),
normalize,
])
else:
train_transform = transforms.Compose([
transforms.Resize([32, 32]),
transforms.ToTensor(),
normalize,
])
test_transform = transforms.Compose([
transforms.Resize([32, 32]),
transforms.ToTensor(),
normalize
])
train_data = TrainDataset(data_frame=train_folds, transform=train_transform)
val_data = TrainDataset(data_frame=valid_folds, transform=test_transform)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=args.batch_size, shuffle=True,
num_workers=args.prefetch, pin_memory=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=args.batch_size, shuffle=False,
num_workers=args.prefetch, pin_memory=True)
return train_loader, val_loader
def build_model():
model = ResNet50(num_classes=44).to(device)
return model
def validate(val_loader, model):
model.eval()
correct = 0
test_loss = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(val_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs1 = model(inputs)
outputs2 = model(inputs.flip(-1))
outputs3 = model(inputs.flip(-2))
outputs4 = model(inputs.flip([-2, -1]))
outputs5 = model(inputs.flip(-1).flip([-2, -1]))
outputs6 = model(inputs.flip(-2).flip([-2, -1]))
outputs = (outputs1 + outputs2 + outputs3 + outputs4 + outputs5 + outputs6) / 6
test_loss += F.cross_entropy(outputs, targets).item()
_, predicted = outputs.max(1)
correct += predicted.eq(targets).sum().item()
test_loss /= len(val_loader.dataset)
accuracy = 100. * correct / len(val_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(
test_loss, correct, len(val_loader.dataset),
accuracy))
return accuracy, test_loss
def train(model, train_loader, val_loader, optimizer, epoch):
model.train()
print("Epoch:%d" % epoch)
running_loss = 0
for batch_idx, (input, target) in enumerate(train_loader):
input = input.to(device)
target = target.to(device)
y_pred = model(input)
optimizer.zero_grad()
loss = F.cross_entropy(y_pred, target)
loss.backward()
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
optimizer.zero_grad()
running_loss = running_loss + loss.item()
if (batch_idx + 1) % 100 == 0:
print('Epoch: [%d/%d]\t'
'Iters: [%d/%d]\t'
'Loss: %.4f\t' % (
epoch, args.epochs, batch_idx + 1, len(train_loader.dataset) / args.batch_size,
(running_loss / (batch_idx + 1))))
if (batch_idx + 1) % 200 == 0:
test_acc, test_loss_ = validate(model=model, val_loader=val_loader)
return running_loss / (len(train_loader.dataset) / args.batch_size + 1)
train_loader, val_loader = build_dataset()
model = build_model()
optimizer_model = torch.optim.SGD(model.params(), args.lr,
momentum=args.momentum, weight_decay=args.weight_decay, nesterov=args.nesterov)
optimizer = AdamW(model.params(), lr=args.lr, weight_decay=args.weight_decay, amsgrad=True)
if __name__ == '__main__':
# model.load_state_dict(torch.load('model_parameter.pkl'), strict=True)
for epoch in range(args.start_epoch, args.epochs + 1):
adjust_learning_rate(optimizer, epoch)
tr_loss = train(model=model, train_loader=train_loader, val_loader=val_loader, optimizer=optimizer, epoch=epoch)
acc, te_loss = validate(val_loader=val_loader, model=model)
wind1.line([[tr_loss], [te_loss]], [epoch], win="loss_window", update="append")
wind2.line([acc], [epoch], win="acc_window", update="append")
torch.save(model.state_dict(), "model_parameter.pkl")存在的问题:
- 梯度爆炸。首次训练未使用梯度剪裁,在第1个Epoch之后,频繁出现梯度爆炸现象,训练Loss一度到达百万数量级,模型精度无法上升,始终为40%左右。后使用梯度剪裁并调整batch size,并且从优化算法传统SGD算法改为admaw,成功使得梯度爆炸消失。
- 过拟合导致精度偏低。即使解决了梯度爆炸,整个模型精度仍然偏低。对此,改用从ResNet34尝试改用ResNet50和ResNet152。ResNet50效果较好,ResNet152效果偏差,初步推测由于参数过多导致优化困难。
接下来的改进,主要解决过拟合导致的精度偏低问题。
2、使用预训练模型
PyTorch提供了常用网络的预训练模型,这其中也包括了ResNet的预训练模型。这里使用ResNet50的预训练模型。预训练模型调用方法如下
from torchvision import models
model = models.resnet50(pretrained=True).to(device)预训练模型在大型图像数据集ImageNet上进行训练,其模型输出已经十分贴合真实世界的图像分布,所以我们对其进行fine tuning即可。
实验证明,使用预训练模型的精度从85%左右提升到了91%。
3、元学习权重分配
现在,笔者将性能提升的瓶颈归结于数据的长尾分布。这很可能导致数据量大的样本过拟合,同时数据量小的样本学习不充分。可行的方法之一是在损失函数上添加正则化项,以期模型能充分学习小数量样本,但是这样的正则化项人工定义较难。于是,我们采用元学习的方法,在损失函数上添加权重 ,希望等在小数量样本上拥有更高的数值。
,希望等在小数量样本上拥有更高的数值。
损失函数变为:![]()
所谓元学习,即挑选一批易于学习,信息丰富,分布较好的数据作为元数据,在每一次正式进行反向传播更新参数前,先进行“伪更新”一次,以“伪更新”后得到的模型参数指导元模型更新,以原模型更新后的参数指导模型进行进行正式更新。其算法可以由一下两个公式表示,其中w为原模型参数,θ为主模型参数。

为此,我们更新训练过程,其中warmup阶段是为了是模型有用一定的知识,之后再进行元学习的指导:
def train(model, vnet, train_loader, train_meta_loader, val_loader, optimizer_model, optimizer_vnet, epoch):
print('\nEpoch: %d' % epoch)
train_loss = 0
meta_loss = 0
train_meta_loader_iter = iter(train_meta_loader)
for batch_idx, (inputs, targets) in enumerate(train_loader):
model.train()
inputs, targets = inputs.to(device), targets.to(device)
if epoch < args.warmup:
y_pred = model(inputs)
optimizer.zero_grad()
loss = F.cross_entropy(y_pred, targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
optimizer.zero_grad()
train_loss = train_loss + loss.item()
if (batch_idx + 1) % 100 == 0:
print('Epoch: [%d/%d]\t'
'Iters: [%d/%d]\t'
'Loss: %.4f\t' % (
epoch, args.epochs, batch_idx + 1, len(train_loader.dataset) / args.batch_size,
(train_loss / (batch_idx + 1))))
else:
meta_model = build_model().cuda()
meta_model.load_state_dict(model.state_dict())
outputs = meta_model(inputs)
# grad clip
torch.nn.utils.clip_grad_norm_(meta_model.parameters(), args.max_grad_norm)
cost = F.cross_entropy(outputs, targets, reduce=False)
cost_v = torch.reshape(cost, (len(cost), 1))
v_lambda = vnet(cost_v.data)
l_f_meta = torch.sum(cost_v * v_lambda) / len(cost_v)
meta_model.zero_grad()
grads = torch.autograd.grad(l_f_meta, (meta_model.params()), create_graph=True)
meta_lr = args.lr * ((0.1 ** int(epoch >= 40)) * (0.1 ** int(epoch >= 60))) # For ResNet32
meta_model.update_params(lr_inner=meta_lr, source_params=grads)
del grads
try:
inputs_val, targets_val = next(train_meta_loader_iter)
except StopIteration:
train_meta_loader_iter = iter(train_meta_loader)
inputs_val, targets_val = next(train_meta_loader_iter)
inputs_val, targets_val = inputs_val.to(device), targets_val.to(device)
y_g_hat = meta_model(inputs_val)
l_g_meta = F.cross_entropy(y_g_hat, targets_val)
# prec_meta = accuracy(y_g_hat.data, targets_val.data, topk=(1,))[0]
optimizer_vnet.zero_grad()
l_g_meta.backward()
optimizer_vnet.step()
outputs = model(inputs)
# grad clip
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
cost_w = F.cross_entropy(outputs, targets, reduce=False)
cost_v = torch.reshape(cost_w, (len(cost_w), 1))
# prec_train = accuracy(outputs.data, targets.data, topk=(1,))[0]
with torch.no_grad():
w_new = vnet(cost_v)
loss = torch.sum(cost_v * w_new) / len(cost_v)
optimizer_model.zero_grad()
loss.backward()
optimizer_model.step()
train_loss += loss.item()
meta_loss += l_g_meta.item()
if (batch_idx + 1) % 100 == 0:
print('Epoch: [%d/%d]\t'
'Iters: [%d/%d]\t'
'Loss: %.4f\t'
'MetaLoss:%.4f\t' % (
epoch, args.epochs, batch_idx + 1, len(train_loader.dataset) / args.batch_size,
(train_loss / (batch_idx + 1)),
(meta_loss / (batch_idx + 1))))
if (batch_idx + 1) % 200 == 0:
acc, te_loss = validate(val_loader=val_loader, model=model)
return train_loss / (len(train_loader.dataset) / args.batch_size + 1)遗憾的是,这种方法的精度与直接训练ResNet相差无几,这证明长尾其实不是限制其性能的主要原因。
五、实验结果
目前的最好精度来自于使用预训练模型,这是由于其包含了广泛的先验知识,只需进行微调就可以匹配大部分数据集的分布。