2016秋季网络程序设计学习总结
USTC-NP2016秋季网络程序设计
这门课的第一堂,老师说要“玩个大的”,因为自己基础不太好,便打了退堂鼓,但是由于一直以来接受的都是传统的“灌输式”教学方法,孟宁老师这种类似团队做项目,让同学们自己来学习分享的教学方法十分吸引我,于是选择了这门课,果然受益匪浅。
课程主要目标
这门课程的主要目标是通过学习神经网络和深度学习等机器学习算法来实现出一个完整的对血常规检验报告的OCR识别、学习与分析系统,主要对年龄与性别进行了预测。
//项目的最后效果就是,用户上传一张血常规报告单的图片,后台首先进行OCR识别出图片中的项目,将其存入MongoDB,然后会根据机器学习算法生成的模型对用户数据进行预测。
项目地址
项目地址
项目总览
本项目分两大部分,前端展示和后台OCR及预测;三大模块,web模块,图像OCR模块,学习预测模块。
项目环境配置及运行
环境配置
安装numpy,python的数据科学库
1 $ sudo apt-get install python-numpy安装opencv,
1 $ sudo apt-get install python-opencv安装pytesseract( OCR识别库pytesseract开源项目: pytesseract)
$ sudo apt-get install tesseract-ocr
$ sudo pip install pytesseract
$ sudo apt-get install python-tk
$ sudo pip install pillow安装Flask框架
$ sudo pip install Flask安装mongodb
$ sudo apt-get install mongodb # 如果提示no module name mongodb, 先执行sudo apt-get update
$ sudo service mongodb started
$ sudo pip install pymongo安装Tensorflow,当前最流行的深度学习平台
$ sudo apt-get install python-numpy
$ sudo apt-get install python-imaging
$ pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0rc0-cp27-none-linux_x86_64.whl运行
$ cd BloodTestReportOCR
$ python view.py # upload图像,在浏览器打开http://yourip:8080各模块说明
Web模块
view.py:
Web 端上传图片到服务器,存入mongodb并获取oid,目前并不完善。
图像识别模块
imageFilter.py
实现了图像的透视,剪裁,识别等,OCR进行了简单的封装,以便于模块间的交互,规定适当的接口
imageFilter = ImageFilter() # 可以传入一个opencv格式打开的图片
num = 22
print imageFilter.ocr(num)ocr函数
模块主函数返回识别数据
用于对img进行ocr识别,他会先进行剪切,之后进一步做ocr识别,返回一个json对象 如果剪切失败,则返回None @num 规定剪切项目数
perspect函数
初步的矫正图片
用于透视image,他会缓存一个透视后的opencv numpy矩阵,并返回该矩阵 透视失败,则会返回None,并打印不是报告 @param 透视参数
具体处理过程:
1,先对图像进行灰度化,高斯平滑,开闭运算,轮廓识别
#灰度化
img_gray = cv2.cvtColor(self.img, cv2.COLOR_BGR2GRAY)
#高斯平滑
img_gb = cv2.GaussianBlur(img_gray, (gb_param,gb_param), 0)
#闭运算
closed = cv2.morphologyEx(img_gb, cv2.MORPH_CLOSE, kernel)
#开运算
opened = cv2.morphologyEx(closed, cv2.MORPH_OPEN, kernel)
#canny算子边缘检测
edges = cv2.Canny(opened, canny_param_lower , canny_param_upper)2.由于我们上传的报告单中既含有中文,英文还有数字,符号,直接识别十分困难,因此我们将图片分割成不同的小块,定位于是成了关键。我们将黑线当成识别的特征
# 调用findContours提取轮廓
contours, hierarchy = cv2.findContours(edges,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
#求最小外接矩形
def getbox(i):
rect = cv2.minAreaRect(contours[i])
box = cv2.cv.BoxPoints(rect)
box = np.int0(box)
return box比较最小外接矩形相邻两条边的长短
以两条短边的中点作为线的两端
所有的线两两进行比较筛选
# 由三条线来确定表头的位置和表尾的位置
line_upper, line_lower = findhead(line[2],line[1],line[0])
# 由表头和表尾确定目标区域的位置
# 利用叉乘的不可交换性确定起始点
total_width = line_upper[1]-line_upper[0]
total_hight = line_lower[0]-line_upper[0]
cross_prod = cross(total_width, total_hight)
if cross_prod <0:
temp = line_upper[1]
line_upper[1] = line_upper[0]
line_upper[0] = temp
temp = line_lower[1]
line_lower[1] = line_lower[0]
line_lower[0] = temp如果图像拍的不完全正,就进行透视变换
#使用透视变换将表格区域转换为一个1000*760的图
PerspectiveMatrix = cv2.getPerspectiveTransform(points,standard)
self.PerspectiveImg = cv2.warpPerspective(self.img,PerspectiveMatrix, (1000, 760))这样得到的图就是1000*760的相同大小图,能够进行裁剪成每个小方块。之后调用ocr识别库进行识别。就能够得到训练的数据。
关于param
参数的形式为[p1, p2, p3 ,p4 ,p5]。 p1,p2,p3,p4,p5都是整型,其中p1必须是奇数。
p1是高斯模糊的参数,p2和p3是canny边缘检测的高低阈值,p4和p5是和筛选有关的乘数。
如果化验报告单放在桌子上时,有的边缘会稍微翘起,产生比较明显的阴影,这种阴影有可能被识别出来,导致定位失败。 解决的方法是调整p2和p3,来将阴影线筛选掉。但是如果将p2和p3调的比较高,就会导致其他图里的黑线也被筛选掉了。 参数的选择是一个问题。 我在getinfo.default中设置的是一个较低的阈值,p2=70,p3=30,这个阈值不会屏蔽阴影线。 如果改为p2=70,p3=50则可以屏蔽,但是会导致其他图片识别困难。
就现在来看,得到较好结果的前提主要有三个:
- 化验单尽量平整
- 图片中应该包含全部的三条黑线
- 图片尽量不要包含化验单的边缘,如果有的话,请尽量避开有阴影的边缘。
filter函数
过滤掉不合格的或非报告图片
返回img经过透视过后的PIL格式的Image对象,如果缓存中有PerspectivImg则直接使用,没有先进行透视 过滤失败则返回None @param filter参数
autocut函数
将图片中性别、年龄、日期和各项目名称数据分别剪切出来
用于剪切ImageFilter中的img成员,剪切之后临时图片保存在out_path, 如果剪切失败,返回-1,成功返回0 @num 剪切项目数 @param 剪切参数
剪切出来的图片在BloodTestReportOCR/temp_pics/ 文件夹下
函数输出为data0.jpg,data1.jpg……等一系列图片,分别是白细胞计数,中性粒细胞记数等的数值的图片。
classifier.py
用于判定裁剪矫正后的报告和裁剪出检测项目的编号
imgproc.py
将识别的图像进行处理二值化等操作,提高识别率 包括对中文和数字的处理
digits
将该文件替换Tesseract-OCR\tessdata\configs中的digits
深度学习和机器学习模块
这一部分主要就是对数据进行处理,这一部分刚开始我想跟着用TensorFlow,但是由于某些问题,电脑配置不成功,于是换了scikit-learn来实现对于年龄与性别的预测。
神经网络原理
神经网络由能够互相通信的节点构成,赫布理论解释了人体的神经网络是如何通过改变自身的结构和神经连接的强度来记忆某种模式的。而人工智能中的神经网络与此类似。请看下图,最左一列蓝色节点是输入节点,最右列节点是输出节点,中间节点是隐藏节点。该图结构是分层的,隐藏的部分有时候也会分为多个隐藏层。如果使用的层数非常多就会变成我们平常说的深度学习了。
一个简单的神经网络
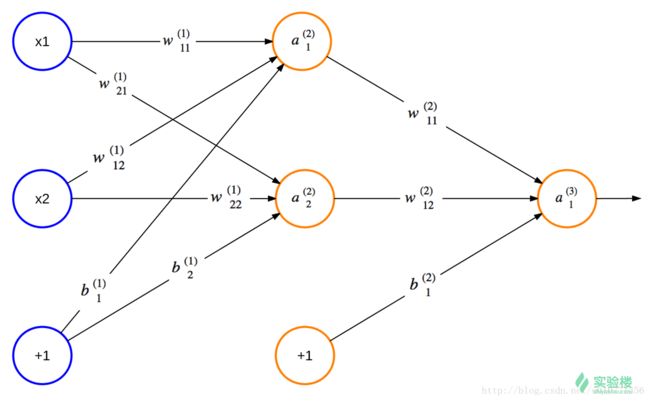
每一层(除了输入层)的节点由前一层的节点加权加相加加偏置向量并经过激活函数得到,公式如下:
![]()
f是激活函数,b是偏置向量
神经网络属于监督学习,那么多半就三件事,决定模型参数,通过数据集训练学习,训练好后就能到分类工具/识别系统用了。数据集可以分为2部分(训练集,验证集),也可以分为3部分(训练集,验证集,测试集),训练集可以看作平时做的习题集(可反复做)。通过不断的训练减少损失,我们就可以得到最优的参数,即偏置向量和权重。
递归神经网络
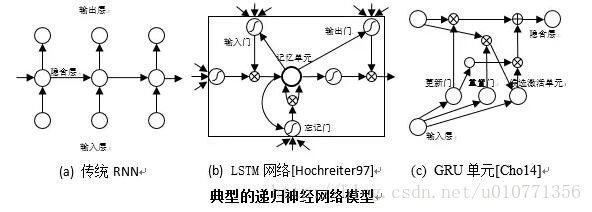
RNN通常用于描述动态时间行为序列,将状态在自身网络中循环传递,可以接受更为广泛的时序序列结构输入。不同于前馈深层神经网络,RNN更重视网络的反馈作用。由于存在当前状态和过去状态的连接,RNN可以具有一定的记忆功能。
当前代表性的递归神经网络包括传统RNN模型,长短期记忆神经网络(long short-term memory, LSTM) [Hochreiter97]以及GRU(gated recurrent unit)模型[Cho14],
卷积神经网络
在课程上通过同学的分享我了解了很多机器学习的方法,例如感知机、支持向量机、决策树、随机森林以及不同的神经网络算法。这里简单介绍一下其中我比较熟悉的卷积神经网络。
卷积神经网络是人工神经网络的一种,是一种前馈型网络,它已经成为了当前语音分析和图像识别领域的研究热点,它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。它使得图像可以直接作为网路的输入,避免了传统识别算法中的特征提取和数据重建过程。卷积神经网络相比传统的神经网络模型,主要区别是加入了卷积层和抽样层。
卷积层的一个特征图(feature map)和输入层通过一组权重集(3×3的卷积核)相连,这样每个特征图中的神经元对应的输入区域也为 3×3的区域,通过和卷积核进行卷积运算得到该神经元的输入。输入层中虚线矩形框范围内的 3×3个输入层节点和卷积核进行卷积运算,其结果和一个偏差相加之后作为特征图第一个节点的输入。具体卷积操作如下图所示。由于同一个特征图的节点共享同一个卷积核作为连接,所以这种连接方式和全连接构成的神经网络模型相比,待训练的权重大量减少。卷积核一般有多个,每个对应输入图的一个特征,通过卷积操作得到一个卷积层特征图。因此一个卷积层的特征图数目比其输入层的特征图数目多很多,这种特征转换使得特征的维数快速上升,为了避免维数太多,可以引入抽样层对卷积层特征图进行特征筛选,抽样层特征图的每个神经元节点的输入是前一层对应特征图中一个窗形区域内的节点集以某种方式筛选所得。通过卷积层和抽样层处理后的数据会被送到类似传统神经网络的全连接层,最后到输出层。
TensorFlow
最终还是用了tensorflow全连接网络
预测流程:
tf_predict.py
先进行数据归一化预处理:
def normalized(a,b):
for i in range(22):
tmp = np.mean(a[:, i])
a[:, i] = a[:, i] - tmp
b[:, i] = b[:, i] - tmp
if np.min(a[:, i]) != np.max(a[:, i]):
b[:, i] = 2 * (b[:, i] - np.min(a[:, i])) / (np.max(a[:, i]) - np.min(a[:, i])) - 1
else:
b[:, i] = 0
return b 然后构建神经网络模型并进行预测。这里的模型采用了四层网络结构,分别是1个输入层,2个隐藏层,1个输出层,激活函数采用的是relu函数。本次项目采用了机器学习库tensorflow进行预测模块的开发。
设置学习率、每层的单元数等参数:
learning_rate = 0.005
display_step = 100
n_input = 22
n_hidden_1_age = 32
n_hidden_2_age = 16
n_classes_age = 1 构建神经网络模型的部分主要代码:
def multilayer_perceptron_age(x_age, weights_age, biases_age):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x_age, weights_age['h1']), biases_age['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights_age['h2']), biases_age['b2'])
layer_2 = tf.nn.relu(layer_2)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights_age['out']) + biases_age['out']
return out_layer
weights_age = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1_age])),
'h2': tf.Variable(tf.random_normal([n_hidden_1_age, n_hidden_2_age])),
'out': tf.Variable(tf.random_normal([n_hidden_2_age, n_classes_age]))
}
biases_age = {
'b1': tf.Variable(tf.random_normal([n_hidden_1_age])),
'b2': tf.Variable(tf.random_normal([n_hidden_2_age])),
'out': tf.Variable(tf.random_normal([n_classes_age]))
} 项目运行
启动
$ cd BloodTestReportOCR
$ python view.py
访问 http://0.0.0.0:8080/这样就进入了以下页面:
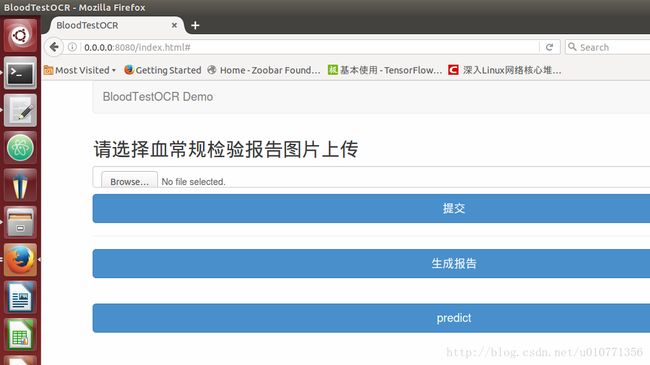
上传图片
我上传的是这张图:

经过上面提到的ImageFilter模块的处理,上传成功后是这样的:

生成报告
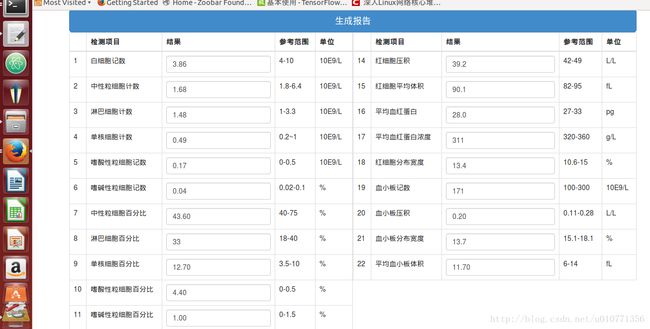
点击预测
课程心得
之前就对孟老师有所耳闻,之前可惜没能选上孟宁老师的高级软件工程课程,我很欣赏孟宁老师这种课程教学方式,不是老师读PPT的传统式教学,给予学生充分的自主权。引导我们进行团队开发做工程。
这门课对我来说的确是很难,不仅是因为之前代码量少,而且也是因为要学习一门新的语言与大量的理论知识。学习分享非常棒,调动了大家学习的热情,而且相互之间的分享讨论也减轻了自己学习的负担,很不好意思的是没能在这个工程里多多贡献,但是这门课的确是让我对各个方面包括工程,团队合作,图像处理以至于神经网络等方面有了更进一步的了解。之前一直觉得理论知识学的足够了才能能动手敲代码,这门课也纠正了我这个想法,只有理论与实践结合起来才能更快更有效率的学习到应用上学到的 东西,两者相辅相成,老师的教学方法我认为十分适合计算机这门学科,应该被广泛应用到计算机教学中,及保证了理论知识的学习,又没有放松动手能力的培养,实在是巧妙。
我最大的收获就是要立即行动,勤于动手。机器学习这才是刚刚开始。