#Reading Paper# 【序列推荐】SDM: Sequential Deep Matching Model for Online Large-scale Recommender System
#论文题目:【长序列推荐】SDM: Sequential Deep Matching Model for Online Large-scale Recommender System(SDM:在线大规模推荐系统的顺序深度匹配模型)
#论文地址:https://arxiv.org/abs/1909.00385v1
#论文源码开源地址: https://github.com/alicogintel/SDM
#论文所属会议:CIKM 2019
#论文所属单位:阿里

导读
本文提出了一种新型的序列推荐模型SDM,该模型基于自注意力机制,融合长期兴趣和短期兴趣来捕捉用户动态偏好。
二、模型结构
2.1 问题定义
设 U U U表示用户集合, I I I表示物品集合。对于一个用户 u u u,我们对用户物品交互时间升序排序来得到最新的会话(session),同时我们也定义了如下几个规则来确定会话:
- 在后端系统中同一个session ID的交互归于一个会话中
- 时间差不长于10分钟(根据场景而定)的交互归于一个会话中
- 一个会话的最大长度是50分钟,长于50分钟就开启一个新的会话
每个用户 u u u的最新会话被认为是短期行为,用 S S Su =[ i i i1u, i i i2u, …, i i imu,]表示,其中 m m m是序列长度。用户 u u u的长期行为是发生在 S S Su之前的七天内的行为,用 L L Lu表示。基于上述前提,我们将推荐任定义为,给定用户 u u u的短期行为 S S Su和长期行为 L L Lu,然后我们为用户推荐物品。
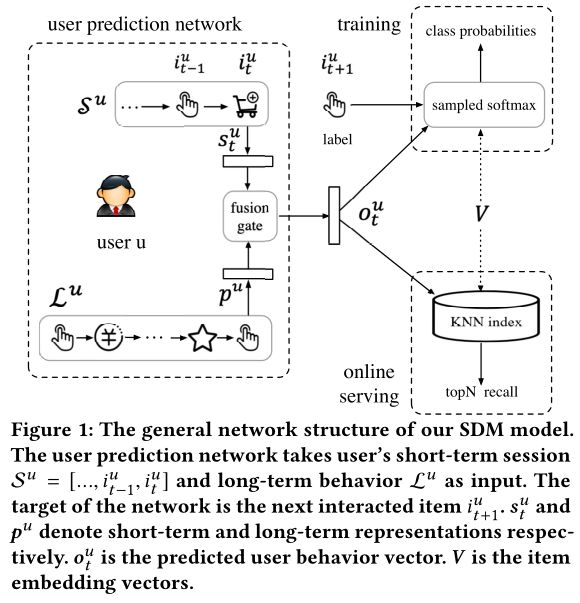
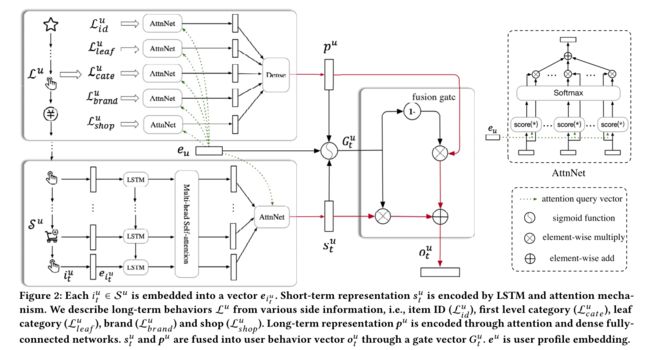
总体网络结构体如下图所示,我们的模型使用 S S Su和 L L Lu作为输入, S S Su和 L L Lu分别被编码成在时间 t t t上的短期会话特征 s s stu和长期行为特征表示 p p pu,然后使用门控神经网络将这两个特征表示结合。我们将这个模块命名为 user prediction network ,该模块根据 S S Su和 L L Lu预测用户行为向量 o o otu。图中 V V V ∈ \in ∈ R \mathbb {R} Rdx|I|,表示物品向量, d d d是向量维度, I I I是所有物品个数。我们的目标是预测Top N个物品在时间 t + 1 t+1 t+1时,其真实标签是 i i ii+1u,基于 o o otu和 V V V每个列向量 v v vi的内积
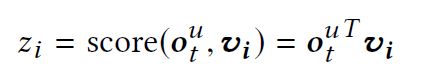
2.2 模型训练(损失函数)
模型在训练过程中,时间 t t t的正样本就是下一个交互物品 i i ii+1u。负样本是使用log-uniform从 I I I中采样得到,当然是剔除了 i i ii+1u 的。然后使用softmax来计算类别概率。上述做法被称为sampled-softmax,使用交叉熵损失函数。
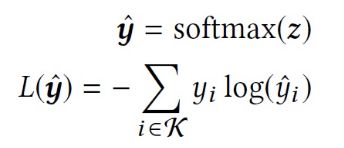
其中 K K K是从 I I I中采样出来的子集,包括了正负样本。 z z z = [ z z z1, z z z2, …, z z z|K|]是 o o otu与 v v vi( i i i ∈ \in ∈ K K K)的内积。 y ^ \hat{y} y^=[ y ^ \hat{y} y^1, …, y ^ \hat{y} y^|K|]是采样出的样本预测概率的分布律。 y y yi是物品 i i i的真实概率分布。
将模型部署在在线推荐系统上。使用高效的KNN相似度检索系统来处理物品向量 V V V。同时我们将 user prediction network 部署在高性能机器上。系统架构和Youtube DNN类似(Deep neural networks for youtube recommendations)。当用户使用在线服务时,用户会和很多物品进行交互,用户对物品的反馈会被后端保存。这些用户行为日志会被保存到数据库中。然后从这些日志中提取模型所需要的结构化数据。在时间 t t t,用户历史行为( S S Su 和 L L Lu)输入到模型中,得到用户行为向量 o o otu,然后KNN检索系统会召回最相似的N个物品,基于物品向量和用户行为向量的内积。下面,详细解析网络是如何对 S S Su 和 L L Lu进行表征的,以及如何将两个特征表示进行融合的。模型细节如下图所示。
2.3 模型细化
2.3.1 物品向量化
在淘宝推荐场景中,用户不仅关心商品自身,同时还关心品牌,商铺和价格等因素。例如,一些人倾向于买特定品牌的商品,另一些人倾向于从他们信任的商铺买商品。进一步来说,由于大规模在线商品导致的稀疏性,仅仅对商品ID进行编码是无法满足需求的,所以我们使用了很多附加信息描述物品,如第一级类别,品牌和商品等,这些附加信息集合用 F F F表示。

2.3.2 循环神经网络层
输入用户 u u u短期序列特征 ,为了捕捉和描述短期序列特征的全局时间依赖,我们采用了LSTM模型,LSTM描述如下:
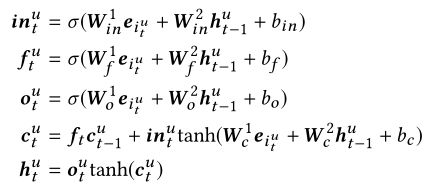

2.4 注意力机制
在线购物场景下,顾客有时会看一些不相关的产品,我们称为误点击(casual click)。不相关的点击行为在某种程度上会影响 h h htu的特征表现。我们使用了自注意力网络(self-attention network)减小不相关点击的影响。注意力网络可以将不同向量加权聚合成一个向量。
Multi-head Self-Attention
自注意力机制是注意力机制的一种特殊情况,它将输入的序列作为query,key和value向量。
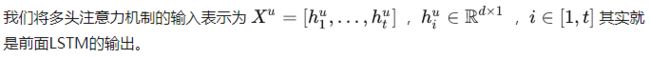
假设我们采用了 h h h头,那么第 i i i头的计算可以如下表示:
![]()
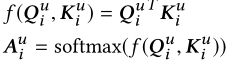
![]()
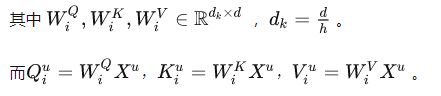
![]()
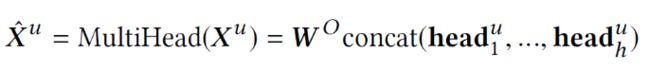
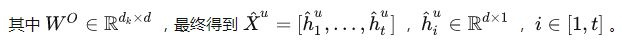
2.4.1 User Attention
对于不同的用户,他们通常有着不同的偏好,甚至对同一个物品偏好也不同。因此,在self-attention模块后面我们添加了一个user attention模块,用于挖掘更加细粒度的个性化信息。其中 e e eu作为query向量, X ^ \hat{X} X^=[ h ^ \hat{h} h^1u, …, h ^ \hat{h} h^tu]作为key和value向量。时刻t的短期行为特征表示 s s stu ∈ \in ∈ R \mathbb{R} Rdx1
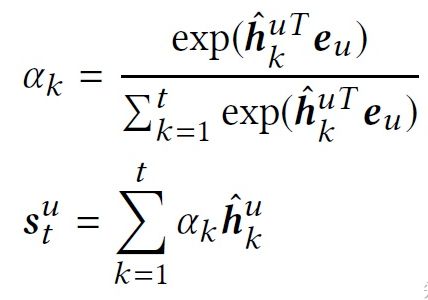
2.5 长期行为特征融合
从长期的视角来看,用户可以会逛相似的商品,买同一个类别的商品。因此我们对长期行为 L L Lu来进行编码表示。 L L Lidu(item ID), L L Lleafu(leaf category), L L Lcateu(first level category), L L Lshopu(shop), L L Lbrandu(brand),如图二所示。对于每个子集,如 L L Lshopu包含了用户过去一周内访问的所以商铺。

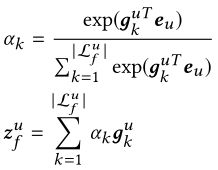
![]()
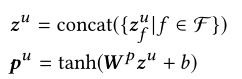
![]()

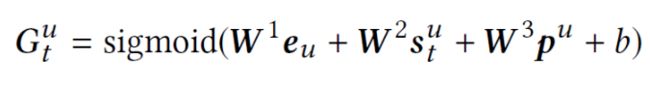
![]()
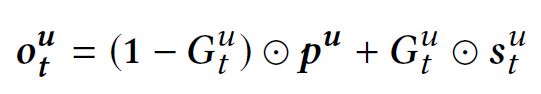
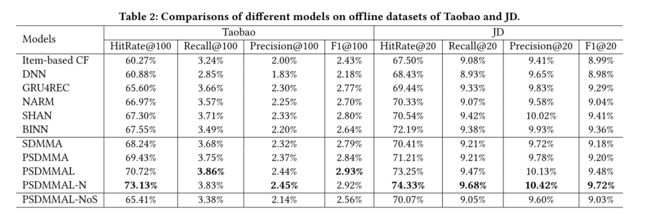
三、实验设置
3.1 数据集
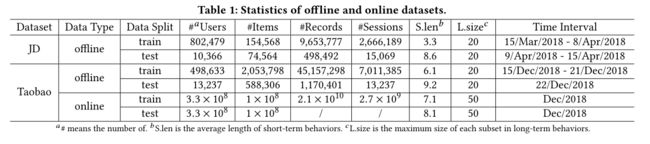
3.2 实验结果