mongodb查询大全mongo语句
mongodb查询大全mongo语句
一、前言
虽然这些语句在开发当中不会使用,因为springdataMongoDB封装的非常完美了。但是这里的语句思想和关系型数据库有些区别,所以需要拿出来详细的讲解一下。因为原生的语句没有搞明白,后面使用springdataMongoDB拼接条件查询的时候心里没数,不知道该怎么去写。现在大多数教程讲的非常详细,分初级和高级,但是即使是高级,有很多经常使用到的语句依然没有讲到,这里还是很有必要去总结一下。
mongodb是非关系型数据库,也就是nosql。在使用起来是非常方便的,例如:在某个实体类中需要添加一个列,这样直接在实体类中添加就OK,不会影响mongodb的,如果你添加一个列了,然后保存数据的时候,这个类存在数据,那么就以java中保存这个集合的样子存入mongodb中。所以在关系型数据库中说的表在mongodb中不说表,说集合。
MongoDB是非关系型数据库当中最像关系型数据库的,所以我们通过它与关系型数据库的对比,来了解下它的概念。
| SQL概念 | MongoDB概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
所以更改数据的时候需要注意,有可能我们更改的那个数据字段压根就不存在。所以在更改领域会出现一个方法叫做更改不存在就添加,然后返回编号 _id。
注意:在非关系型数据库中是没有连表查询这种概念的,但是可以在集合中嵌套集合查询。因为我们在关系型数据库中的连表查询,最终的数据都是保存在集中。我们怎么保存在集合中,那么我们就以保存的这种方式直接存入mongodb就OK,但是mongodb还支持集合中嵌套集合的查询,可以给嵌套的那个集合添加条件筛选。
当前演示的mongodb版本为 4.4 (这个就要注意一下,之前的版本或许有些操作不支持,之后也有不支持的情况,如果废气了呢???)。
观看关系型查询语句和mongodb的语句对比,可以查看官方文档:https://docs.mongodb.com/master/reference/sql-comparison/
mongodb使用的是 Bson格式,Bson是JSON的一个升级版。语法和 JSON都差不多。所以在书写的时候,不管条件怎么写一定都是一个JSON格式的。这里第一个第括号是封装条件,那么条件之间使用 or连接,or里面可能有多个数据,那么又用了一个数组来存储,数组中又是一个一个的对象。从而就形成了 { $or: [ { status: "A" } , { age: 50 } ] }这样的格式。
mongodb中的表达式介绍
| 格式 | 符号描述 | 文字描述 |
|---|---|---|
:(冒号) |
= |
等于 |
$lt |
< |
小于 |
$lte |
<= |
小于等于 |
$gt |
> |
大于 |
$gte |
>= |
大于等于 |
$ne |
!= |
不等于 |
$in |
in() |
包含 |
$nin |
不包含 |
二、sql语句和mongodb语句对比
2.1、创建表并插入数据
- sql创建表
create table people (
id mediumint not null
auto_increment,
user_id varchar(30),
age number,
status char(1),
primary key (id)
)
mongodb创建表
mongodb不用创建表,如果你插入的数据指定的文档没有,那么会自动创建一个相应的文档,并保存。但是也可以显示的创建一个文档然后在向里面插入数据的。
db.people.insertOne( {
user_id: "abc123",
age: 55,
status: "A"
} )
sql的方式
insert into people(user_id,age,status) values ("bcd001",45,"a")
mongodb方式
2.2、sql和mongodb查询对比
注意
除非通过投影明确排除,否则该find()方法始终将_id字段包含在返回的文档中 。即使某些字段不包含在相应的查询中,下面的某些SQL查询也可能包含一个 反映该问题的字段。_id find()
投影:就只返回指定的字段。如果没有用投影查询,所有查询的语句都相当于sql语句中的 select * from 表名这样的语句。
目前的mongodb和MySQL表
| MYSQL | mongodb |
 |
 |
查询所有
- mysql
select * from people;
- mongodb
语法:db.文档名.find();
db.people.find();
返回指定字段
select id,user_id,status from people
db.people.find(
{},
{ user_id: 1, status: 1 }
)
注意:第一个 {},不能去掉,表示筛选条件,例如sql中的where。后面这个大括号中的字段表示是否显示,如果为 1显示,0不显示。但是 _id默认是显示的。
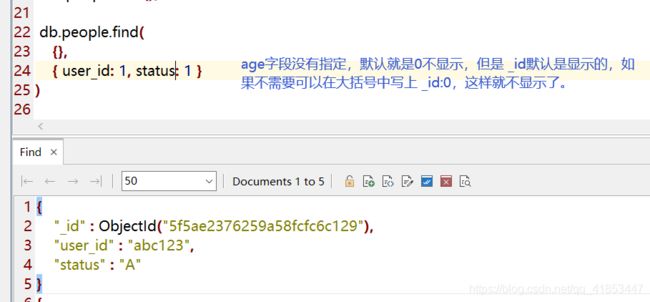
不显示编号 _id
SELECT user_id, status
FROM people
db.people.find(
{ },
{ user_id: 1, status: 1, _id: 0 }
)
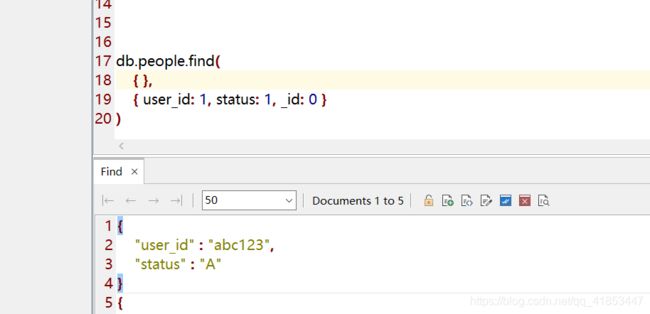
status: "A"的所有
SELECT *
FROM people
WHERE status = "A"
db.people.find(
{ status: "A" }
)
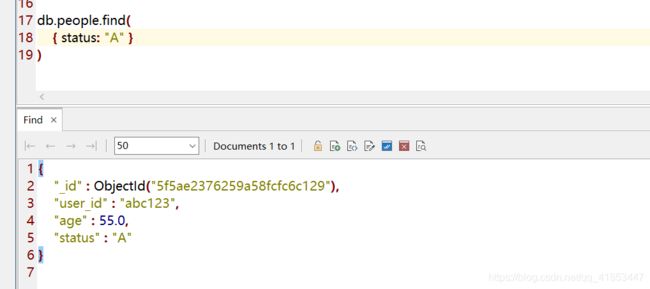
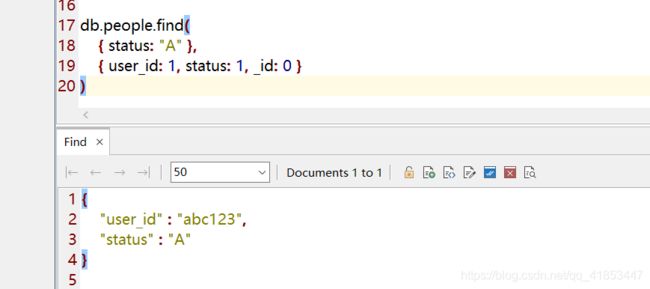
status: "A"并返回指定字段
SELECT user_id, status
FROM people
WHERE status = "A"
db.people.find(
{ status: "A" },
{ user_id: 1, status: 1, _id: 0 }
)
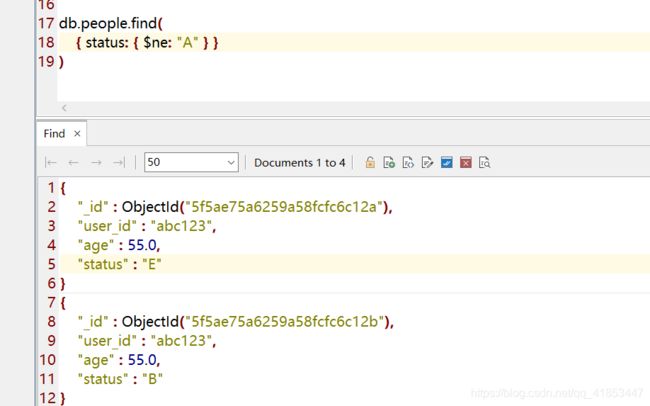
status != "A"返回所有字段
SELECT *
FROM people
WHERE status != "A"
db.people.find(
{ status: { $ne: "A" } }
)
status = “A” and age =55 返回所有字段
SELECT *
FROM people
WHERE status = "A"
AND age = 55
db.people.find(
{ status: "A",
age: 55 }
)

status = “A” or age = 50 返回所有字段
SELECT *
FROM people
WHERE status = "A"
OR age = 50
db.people.find(
{ $or: [ { status: "A" } , { age: 50 } ] }
)
注意:mongodb使用的是 Bson格式,Bson是JSON的一个升级版。语法和 JSON都差不多。所以在书写的时候,不管条件怎么写一定都是一个JSON格式的。
这里第一个第括号是封装条件,那么条件之间使用 or连接,or里面可能有多个数据,那么又用了一个数组来存储,数组中又是一个一个的对象。从而就形成了 { $or: [ { status: "A" } , { age: 50 } ] }这样的格式。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I6Ct5bZI-1599817629990)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20200911112212615.png)]
age > 25 返回所有字段
SELECT *
FROM people
WHERE age > 25
db.people.find(
{ age: { $gt: 25 } }
)
age < 25 返回所有字段
SELECT *
FROM people
WHERE age < 25
db.people.find(
{ age: { $lt: 25 } }
)
age > 25 AND age <= 50
SELECT *
FROM people
WHERE age > 25
AND age <= 50
db.people.find(
{ age: { $gt: 25, $lte: 50 } }
)
其他
SELECT *
FROM people
WHERE user_id like "%bc%"
db.people.find( { user_id: /bc/ } )
db.people.find( { user_id: { $regex: /bc/ } } )
SELECT *
FROM people
WHERE user_id like "bc%"
db.people.find( { user_id: /^bc/ } )
或者
db.people.find( { user_id: { $regex: /^bc/ } } )
- 根据
user_id升序排序,并且status = "A"
SELECT *
FROM people
WHERE status = "A"
ORDER BY user_id ASC
db.people.find( { status: "A" } ).sort( { user_id: 1 } )
注意:排序的时候,
sort()方法是在find()方法之外了。最后面这个1表示升序排序,-1表示降序排序。
SELECT *
FROM people
WHERE status = "A"
ORDER BY user_id DESC
db.people.find( { status: "A" } ).sort( { user_id: -1 } )
- 查询总数
SELECT COUNT(*)
FROM people
db.people.count()
或者
db.people.find().count()
- 指定字段查询总数
SELECT COUNT(user_id)
FROM people
db.people.count( { user_id: { $exists: true } } )
或者
db.people.find( { user_id: { $exists: true } } ).count()
SELECT COUNT(*)
FROM people
WHERE age > 30
db.people.count( { age: { $gt: 30 } } )
或者
db.people.find( { age: { $gt: 30 } } ).count()
- 去重复,非常有用
例如:访问量人数,访问一次记录一次。那么我想统计访问过我的人,而不是访问量,这时就派的上用场了。
SELECT DISTINCT(status)
FROM people
db.people.aggregate( [ { $group : { _id : "$status" } } ] )
或者
db.people.distinct( "status" )
- 获取指定条数
SELECT *
FROM people
LIMIT 1
db.people.findOne()
或者
db.people.find().limit(1)
findOne() 每次只能获取一条数据,如果我想获取2条3条呢?这时就需要使用下面这个语句了。
- 从索引为5获取10条数据
SELECT *
FROM people
LIMIT 5,10
db.people.find().limit(5).skip(10)
- 查看sql执行情况
EXPLAIN SELECT *
FROM people
WHERE status = "A"
db.people.find( { status: "A" } ).explain()
详细查看该博客:https://www.cnblogs.com/tufujie/p/9413852.html
查询参数讲解:
id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
三、mongodb语句风格说明
3.1、首先观察几个查询语句和更改语句
- 查询
status: "A"所有数据
select * from people where status: "A"
db.people.find(
{ status: "A" }
)
- 查询
status: "A",返回user_id,status字段。
select user_id,status from people where status: "A"
db.people.find(
{ status: "A" },
{ user_id: 1, status: 1, _id: 0 }
)
- 查询所有返回
user_id,status字段
select user_id,status from people
db.people.find(
{ },
{ user_id: 1, status: 1, _id: 0 }
)

- 更改全部
status: "D"
update people set status = 'D'
db.people.updateMany(
{},
{ $set: { status: "D" }}
)
- 将
status: "C"的年龄更改为 20岁
update people SET age = 20 where status = 'C'
db.people.updateMany(
{ status: "C" },
{ $set: { age: 20 } }
)
3.2、总结
不管你是查询还是更改删除,在CRUD操作的方法中。第一个个大括号都封装为条件,第二个大括号在做相应的操作。例如:
- 查询
第一个大括号封装以什么样作为条件查询;
第二个大括号封装查询结果返回那些字段。
- 更改
第一个大括号封装一什么样的条件更改;
第二个大括号封装将那些字段更改为什么样的数据。
注意:封装的条件写法都一样,不管是CRUD操作,更改的都是一样的。这里所指的条件就类似于sql语句中的where条件。
四、文字搜索
关于文字搜索方面的东西,我们一般使用 Elasticsearch来实现,所以mongodb提供的我们暂时不研究,如果需要研究的参考官方文档:https://docs.mongodb.com/master/text-search/
五、查询
向mongodb中插入测试数据
db.inventory.insertMany([
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
]);
5.1、简单查询
- 查询全部
db.inventory.find( {} )
- 对应的sql语句
select * from inventory
- 条件查询
查询 status = "D"的所有数据
db.inventory.find( { status: "D" } )
SELECT * FROM inventory WHERE status = "D"
$in查询
查询 status等于 A 或者 B 的全部数据。
db.inventory.find( { status: { $in: [ "A", "D" ] } } )
SELECT * FROM inventory WHERE status in ("A", "D")
$lt小于
查询 status = "A" 并且 qty < 30 的全部数据
db.inventory.find( { status: "A", qty: { $lt: 30 } } )
SELECT * FROM inventory WHERE status = "A" AND qty < 30
$or或者
查询 status = "A" 或者 qty < 30 的所有数据
db.inventory.find( { $or: [ { status: "A" }, { qty: { $lt: 30 } } ] } )
发现没有:如果多条件查询,没有 $or标识的,默认是 and来拼接。
SELECT * FROM inventory WHERE status = "A" OR qty < 30
- 多条件查询
查询 status: "A" 并且 qty < 30 或者 item以p结尾的全部数据。
db.inventory.find( {
status: "A",
$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
} )
SELECT * FROM inventory WHERE status = "A" AND ( qty < 30 OR item LIKE "p%")
注意:$or的后面有一个中括号的。
5.2、匹配嵌套文档
测试数据
db.inventory.insertMany( [
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
]);
注意:这里的size域不是一个值了,而是一个对象。将这个BSON格式化后就很明确的发现这个问题。
{
item: "journal",
qty: 25,
size: {
h: 14,
w: 21,
uom: "cm"
},
status: "A"
}
- 查询
size这个对象中h域等于14并且w=21并且uom=cm的数据。
db.inventory.find( { size: { h: 14, w: 21, uom: "cm" } } )
必选全部匹配才可以并且顺序也不能乱,例如:h属性在w属性前面的。我们封装条件时将w封装在前面h封装在w后面,即使有相同数据存在,也查询不到的,所有顺序也很重要。
就像我们java中判断一个对象是否相等,需要将这个对象中的每个属性值都必须相等才算这两个对象相等,这里也是相同的道理。
Book A = new Book("mongodb",89.56);
Book B = new Book("java",89.56);
如果我们判断这两个对象想不相等,不能直接 A == B ,这样永远不相等,而是要去判断对象里面的所有属性是否相等。应该要获取到A对象中的mongodb,与B对象中的java相互判断是否相等,在用A对象中的89.56和B对象中的89.56做判断。应该要这样去判断是否相等,这个思路搞清楚了,那么上面的mongodb按照条件查询方式就是这样判断的,如果有一个属性不匹配,那么都查询不到。
- 查询结果
{
"_id" : ObjectId("5f5b37756259a58fcfc6c142"),
"item" : "journal",
"qty" : 25.0,
"size" : {
"h" : 14.0,
"w" : 21.0,
"uom" : "cm"
},
"status" : "A"
}
- 顺序乱了,查询不到数据。
db.inventory.find( { size: { w: 21, h: 14, uom: "cm" } } )
- 查询
size这个对象中h = 14 and w=21的数据
db.inventory.find( { size: { h: 14, w: 21 } } )
查询没有结果数据,因为size对象中的数据全部都有 h、w、uom这三个字段的。
5.3、在嵌套字段上查询
如果需要在嵌套的字段上查询,使用点 .来连接。
- 指定
size对象里面的uom属性值查询
db.inventory.find( { "size.uom": "in" } )
- 查询结果
{
"_id" : ObjectId("5f5b37756259a58fcfc6c143"),
"item" : "notebook",
"qty" : 50.0,
"size" : {
"h" : 8.5,
"w" : 11.0,
"uom" : "in"
},
"status" : "A"
}
{
"_id" : ObjectId("5f5b37756259a58fcfc6c144"),
"item" : "paper",
"qty" : 100.0,
"size" : {
"h" : 8.5,
"w" : 11.0,
"uom" : "in"
},
"status" : "D"
}
- 查询
size对象里面h属性小于15的数据
db.inventory.find( { "size.h": { $lt: 15 } } )
{
"_id" : ObjectId("5f5b37756259a58fcfc6c142"),
"item" : "journal",
"qty" : 25.0,
"size" : {
"h" : 14.0,
"w" : 21.0,
"uom" : "cm"
},
"status" : "A"
}
{
"_id" : ObjectId("5f5b37756259a58fcfc6c143"),
"item" : "notebook",
"qty" : 50.0,
"size" : {
"h" : 8.5,
"w" : 11.0,
"uom" : "in"
},
"status" : "A"
}
{
"_id" : ObjectId("5f5b37756259a58fcfc6c144"),
"item" : "paper",
"qty" : 100.0,
"size" : {
"h" : 8.5,
"w" : 11.0,
"uom" : "in"
},
"status" : "D"
}
{
"_id" : ObjectId("5f5b37756259a58fcfc6c146"),
"item" : "postcard",
"qty" : 45.0,
"size" : {
"h" : 10.0,
"w" : 15.25,
"uom" : "cm"
},
"status" : "A"
}
- 查询
status: "D"并且size对象中h<15并且size对象中uom = in的数据。
db.inventory.find( { "size.h": { $lt: 15 }, "size.uom": "in", status: "D" } )
{
"_id" : ObjectId("5f5b37756259a58fcfc6c144"),
"item" : "paper",
"qty" : 100.0,
"size" : {
"h" : 8.5,
"w" : 11.0,
"uom" : "in"
},
"status" : "D"
}
5.4、查询数组
匹配整个数组
测试数据
db.inventory.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], dim_cm: [ 14, 21 ] },
{ item: "notebook", qty: 50, tags: ["red", "blank"], dim_cm: [ 14, 21 ] },
{ item: "paper", qty: 100, tags: ["red", "blank", "plain"], dim_cm: [ 14, 21 ] },
{ item: "planner", qty: 75, tags: ["blank", "red"], dim_cm: [ 22.85, 30 ] },
{ item: "postcard", qty: 45, tags: ["blue"], dim_cm: [ 10, 15.25 ] }
]);
注意:这里的tags和dim_cm是一个数组。格式化一条数据出来更加清晰。
{
item: "journal",
qty: 25,
tags: ["blank", "red"],
dim_cm: [14, 21]
}
- 查询
tags数组为["red", "blank"]的数据
必须指定相等的条件,包括数组的顺序元素个数都不能变化。如果想指定某个域中包含数组的某个字段就可以匹配到,忽略其他元素,可以使用$all运算符。$all参考 https://docs.mongodb.com/master/reference/operator/query/all/#op._S_all
db.inventory.find( { tags: ["red", "blank"] } )
- 查询结果
{
"_id" : ObjectId("5f5b3dad6259a58fcfc6c14d"),
"item" : "notebook",
"qty" : 50.0,
"tags" : [
"red",
"blank"
],
"dim_cm" : [
14.0,
21.0
]
}
- 查询
tags域中的数组包含red和blank元素的数据
db.inventory.find( { tags: { $all: ["red", "blank"] } } )
{
"_id" : ObjectId("5f5b3dad6259a58fcfc6c14c"),
"item" : "journal",
"qty" : 25.0,
"tags" : [
"blank",
"red"
],
"dim_cm" : [
14.0,
21.0
]
}
{
"_id" : ObjectId("5f5b3dad6259a58fcfc6c14d"),
"item" : "notebook",
"qty" : 50.0,
"tags" : [
"red",
"blank"
],
"dim_cm" : [
14.0,
21.0
]
}
{
"_id" : ObjectId("5f5b3dad6259a58fcfc6c14e"),
"item" : "paper",
"qty" : 100.0,
"tags" : [
"red",
"blank",
"plain"
],
"dim_cm" : [
14.0,
21.0
]
}
{
"_id" : ObjectId("5f5b3dad6259a58fcfc6c14f"),
"item" : "planner",
"qty" : 75.0,
"tags" : [
"blank",
"red"
],
"dim_cm" : [
22.85,
30.0
]
}
在数组中查询元素
查询数组中全部满足条件的数据。如果需要查询某个元素满足条件,需要使用过滤器。https://docs.mongodb.com/master/core/document/#document-query-filter
- 查询
dim_cm数组中全部大于25的数据。
db.inventory.find( { dim_cm: { $gt: 25 } } )
{
"_id" : ObjectId("5f5b3dad6259a58fcfc6c14f"),
"item" : "planner",
"qty" : 75.0,
"tags" : [
"blank",
"red"
],
"dim_cm" : [
22.85,
30.0
]
}
5.5、查询返回的字段
其实在第二部分mongodb和sql语句对比中已经提到过这个问题,这里在详细说一下。
因为在第一个大括号封装的全部都是条件,第二个大括号封装的是返回的字段。如果有第二个大括号存在,那么 _id默认是显示的。
注意:在第二个大括号中封装返回字段时,如果只指定某些字段值为1,说明除了这几个字段值之外都不返回。如果只指定某些字段值为0,说明除了这几个字段值都返回。
注意:有些时候如果你觉得没有任何条件,你就将第一个大括号删除了,那么这个语句就只剩下一个大括号,就默认作为条件处理了。所以即使没有条件,第一个大括号也要保留,否则没有办法判断你指定的是条件还是指定返回字段。
演示数据
db.inventory.insertMany( [
{ item: "journal", status: "A", size: { h: 14, w: 21, uom: "cm" }, instock: [ { warehouse: "A", qty: 5 } ] },
{ item: "notebook", status: "A", size: { h: 8.5, w: 11, uom: "in" }, instock: [ { warehouse: "C", qty: 5 } ] },
{ item: "paper", status: "D", size: { h: 8.5, w: 11, uom: "in" }, instock: [ { warehouse: "A", qty: 60 } ] },
{ item: "planner", status: "D", size: { h: 22.85, w: 30, uom: "cm" }, instock: [ { warehouse: "A", qty: 40 } ] },
{ item: "postcard", status: "A", size: { h: 10, w: 15.25, uom: "cm" }, instock: [ { warehouse: "B", qty: 15 }, { warehouse: "C", qty: 35 } ] }
]);
- 查询
status: "A"并返回item和status字段,_id也默认返回了
db.inventory.find( { status: "A" }, { item: 1, status: 1 } )
第二个大括号中字段的后面这个
1标识显示,0不显示。
- 不返回
_id
db.inventory.find( { status: "A" }, { item: 1, status: 1, _id: 0 } )
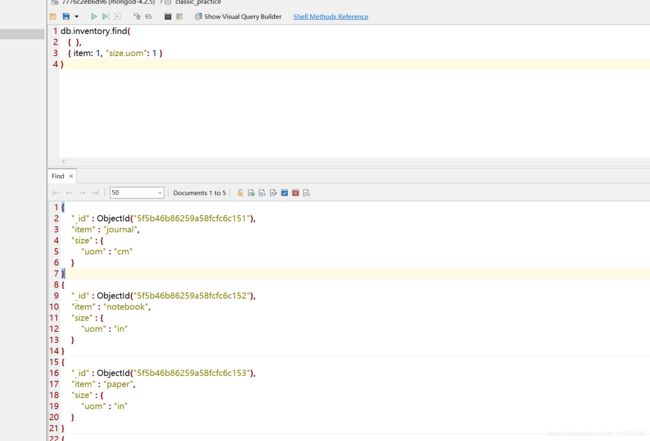
- 只返回
item字段和size对象中的uom域。
db.inventory.find(
{ },
{ item: 1, "size.uom": 1 }
)
五、聚合
聚合操作处理数据记录并返回计算结果。聚合操作将来自多个文档的值分组在一起,并且可以对分组的数据执行各种操作以返回单个结果。MongoDB提供了三种执行聚合的方法:聚合管道,map-reduce函数和单一目的聚合方法。
5.1、聚合管道 aggregate()
聚合操作这里不是使用find()方法了,而是 aggregate()方法。
$match(筛选)
将数据根据指定条件查询出来,然后在进行结果在处理。
- 范例
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("512bc962e835e68f199c8687"), "author" : "dave", "score" : 85, "views" : 521 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b257"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b258"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b259"), "author" : "annT", "score" : 60, "views" : 50 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25a"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25b"), "author" : "ty", "score" : 95, "views" : 1000 }
执行以下聚合操作
db.articles.aggregate(
[ { $match : { author : "dave" } } ]
);
查询出 author : "dave"的所有数据
返回结果为
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("512bc962e835e68f199c8687"), "author" : "dave", "score" : 85, "views" : 521 }
在执行以下操作
db.articles.aggregate( [
{ $match: { $or: [ { score: { $gt: 70, $lt: 90 } }, { views: { $gte: 1000 } } ] } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
查询 score > 70 并且 score < 90 或者 views >= 1000 的数据。然后在计算一共有多少条数据,查询结果为
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("512bc962e835e68f199c8687"), "author" : "dave", "score" : 85, "views" : 521 }
以上都是 score > 70 and score < 90
{ "_id" : ObjectId("55f5a192d4bede9ac365b257"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b258"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25b"), "author" : "ty", "score" : 95, "views" : 1000 }
查询结果
{ "_id" : null, "count" : 5 }
$group(分组)
按指定的_id表达式对输入文档进行分组,并针对每个不同的分组输出文档。_id每个输出文档的字段都包含唯一的按值分组。输出文档还可以包含包含某些累加器表达式值的计算字段。
- 语法
{
$group:
{
_id: <expression>, // 分组表达式
<field1>: { <accumulator1> : <expression1> },
...
}
}
_id:需要分组的字段。如果指定_id null或任何其他常数值,那么此$group阶段将整体计算所有输入文档的累积值。
field:*可选的。*使用累加器运算符进行计算 。
累加运算:https://docs.mongodb.com/master/reference/operator/aggregation/group/#accumulator-operator
- 范例
db.sales.insertMany([
{ "_id" : 1, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("2"), "date" : ISODate("2014-03-01T08:00:00Z") },
{ "_id" : 2, "item" : "jkl", "price" : NumberDecimal("20"), "quantity" : NumberInt("1"), "date" : ISODate("2014-03-01T09:00:00Z") },
{ "_id" : 3, "item" : "xyz", "price" : NumberDecimal("5"), "quantity" : NumberInt( "10"), "date" : ISODate("2014-03-15T09:00:00Z") },
{ "_id" : 4, "item" : "xyz", "price" : NumberDecimal("5"), "quantity" : NumberInt("20") , "date" : ISODate("2014-04-04T11:21:39.736Z") },
{ "_id" : 5, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("10") , "date" : ISODate("2014-04-04T21:23:13.331Z") },
{ "_id" : 6, "item" : "def", "price" : NumberDecimal("7.5"), "quantity": NumberInt("5" ) , "date" : ISODate("2015-06-04T05:08:13Z") },
{ "_id" : 7, "item" : "def", "price" : NumberDecimal("7.5"), "quantity": NumberInt("10") , "date" : ISODate("2015-09-10T08:43:00Z") },
{ "_id" : 8, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("5" ) , "date" : ISODate("2016-02-06T20:20:13Z") },
])
db.sales.aggregate( [
{
$group: {
_id: null,
count: { $sum: 1 }
}
}
] )
虽然使用到分组,但是
_id:null,并没有指定具体的字段。count: { $sum: 1 }是查询所以条数,count相当于别名,随便写的。
SELECT COUNT(*) AS count FROM sales
- 结果
{ "_id" : null, "count" : 8 }
- 根据
item字段分组
db.sales.aggregate( [ { $group : { _id : "$item" } } ] )
{ "_id" : "abc" }
{ "_id" : "jkl" }
{ "_id" : "def" }
{ "_id" : "xyz" }
就只能返回item不重复的数据了。
- 范例
db.sales.insertMany([
{ "_id" : 1, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("2"), "date" : ISODate("2014-03-01T08:00:00Z") },
{ "_id" : 2, "item" : "jkl", "price" : NumberDecimal("20"), "quantity" : NumberInt("1"), "date" : ISODate("2014-03-01T09:00:00Z") },
{ "_id" : 3, "item" : "xyz", "price" : NumberDecimal("5"), "quantity" : NumberInt( "10"), "date" : ISODate("2014-03-15T09:00:00Z") },
{ "_id" : 4, "item" : "xyz", "price" : NumberDecimal("5"), "quantity" : NumberInt("20") , "date" : ISODate("2014-04-04T11:21:39.736Z") },
{ "_id" : 5, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("10") , "date" : ISODate("2014-04-04T21:23:13.331Z") },
{ "_id" : 6, "item" : "def", "price" : NumberDecimal("7.5"), "quantity": NumberInt("5" ) , "date" : ISODate("2015-06-04T05:08:13Z") },
{ "_id" : 7, "item" : "def", "price" : NumberDecimal("7.5"), "quantity": NumberInt("10") , "date" : ISODate("2015-09-10T08:43:00Z") },
{ "_id" : 8, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("5" ) , "date" : ISODate("2016-02-06T20:20:13Z") },
])
db.sales.aggregate([
// 第一个阶段(筛选)
{
$match : { "date": { $gte: new ISODate("2014-01-01"), $lt: new ISODate("2015-01-01") } }
},
// 第二阶段(分组)
{
$group : {
_id : { $dateToString: { format: "%Y-%m-%d", date: "$date" } },
totalSaleAmount: { $sum: { $multiply: [ "$price", "$quantity" ] } },
averageQuantity: { $avg: "$quantity" },
count: { $sum: 1 }
}
},
// 第三阶段(排序)
{
$sort : { totalSaleAmount: -1 }
}
])
$dateToString表达式参考:https://docs.mongodb.com/manual/reference/operator/aggregation/dateToString/index.html
$multiply参考: https://docs.mongodb.com/manual/reference/operator/aggregation/multiply/index.html
- 第一个阶段
过滤出 date > = 2014-01-01 and data < 2015-01-01的数据。
- 第二阶段
按照日期分组,并将 price字段乘以 quantity字段,并求 quantity字段的平均值,最后在计算总和。这了计算的总和是计算当前这一组有多少条数据。
例如:第一次过滤满足 date > = 2014-01-01 and data < 2015-01-01这个条件的数据就只有一下这几条。
{ "_id" : 1, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("2"), "date" : ISODate("2014-03-01T08:00:00Z") },
{ "_id" : 2, "item" : "jkl", "price" : NumberDecimal("20"), "quantity" : NumberInt("1"), "date" : ISODate("2014-03-01T09:00:00Z") },
{ "_id" : 3, "item" : "xyz", "price" : NumberDecimal("5"), "quantity" : NumberInt( "10"), "date" : ISODate("2014-03-15T09:00:00Z") },
{ "_id" : 4, "item" : "xyz", "price" : NumberDecimal("5"), "quantity" : NumberInt("20") , "date" : ISODate("2014-04-04T11:21:39.736Z") },
{ "_id" : 5, "item" : "abc", "price" : NumberDecimal("10"), "quantity" : NumberInt("10") , "date" : ISODate("2014-04-04T21:23:13.331Z") }
按照时间分组,因为上面写的时间格式为 %Y-%m-%d年与日,所以其他数据不参考。
2014-03-01
2014-03-15
2014-04-04
时间就只有这几个,那么在计算 2014-03-01一共有几条数据,刚好只有2 条。_id为 1和2这两条数据。时间为 2014-03-15只有_id为3的这一条数据。时间为 2014-04-04的有 4和5这两条数据。分组查询下来的结果就是一下这样。
{
"_id" : "2014-04-04",
"totalSaleAmount" : { "$numberDecimal" : "200" },
"averageQuantity" : 15.0,
"count" : 2.0
}
{
"_id" : "2014-03-15",
"totalSaleAmount" : { "$numberDecimal" : "50" },
"averageQuantity" : 10.0,
"count" : 1.0
}
{
"_id" : "2014-03-01",
"totalSaleAmount" : { "$numberDecimal" : "40" },
"averageQuantity" : 1.5,
"count" : 2.0
}
使用sql语句就是这样。
SELECT date,
Sum(( price * quantity )) AS totalSaleAmount,
Avg(quantity) AS averageQuantity,
Count(*) AS Count
FROM sales
GROUP BY Date(date)
ORDER BY totalSaleAmount DESC
- 分组条件为
null的时候
之前我还以为这种方式不可取,用处不大。现在才发现,这种方式用于统计还是特备方便的。
db.sales.aggregate([
{
$group : {
_id : null,
totalSaleAmount: { $sum: { $multiply: [ "$price", "$quantity" ] } },
averageQuantity: { $avg: "$quantity" },
count: { $sum: 1 }
}
}
])
统计:
price乘以quantity的总和。在求quantity的平均值。
- 结果
{
"_id" : null,
"totalSaleAmount" : { "$numberDecimal" : "452.5" },
"averageQuantity" : 7.875,
"count" : 8.0
}
sql实现的写法
SELECT Sum(price * quantity) AS totalSaleAmount,
Avg(quantity) AS averageQuantity,
Count(*) AS Count
FROM sales
更多的聚合管道表达式参考:https://docs.mongodb.com/master/reference/operator/aggregation-pipeline/