官方文档 https://docs.oracle.com/javase/tutorial/essential/concurrency/index.html
推荐《Java高并发编程详解:多线程与架构设计》
推荐《Java高并发编程详解:深入理解并发核心库》 有很多工具的基准测试
同步和异步
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列 。要么成功都成功,失败都失败,两个任务的状态可以保持一致。
所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了 。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定, 所以它是不可靠的任务序列 。
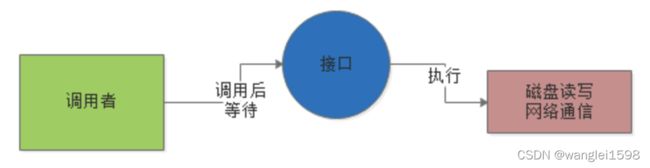
所谓的“ 同步 ”,比如说调用者去调用一个接口,这个接口比如要执行一些磁盘文件读写操作,或者是网络通信操作。
假设是“同步”的模式,调用者必须要等待这个接口的磁盘读写或者网络通信的操作执行完毕了,调用者才能返回,这就是“同步”,如下图所示:
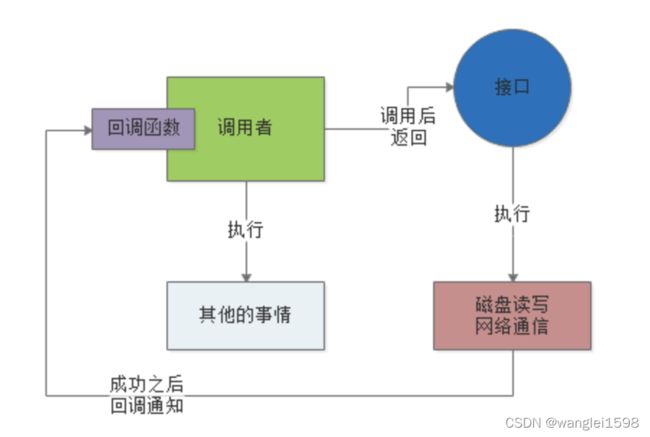
所谓的“ 异步 ”,就是说这个调用者调用接口之后,直接就返回了,他去干别的事儿了,也不管那个接口的磁盘读写或者是网络通信是否成功。
然后这个接口后续如果干完了自己的任务,比如写完了文件或者是什么的,会反过来通知调用者,之前你的那个调用成功了。 可以通过一些内部通信机制来通知,也可以通过回调函数来通知,如下图。
阻塞和非阻塞
阻塞和非阻塞这两个概念与程序(线程)等待消息通知 时的状态有关 (无所谓同步或者异步)。也就是说阻塞与非阻塞主要是程序(线程)等待消息通知时的状态角度来说的。
阻塞调用是指调用结果返回之前,当前线程会被挂起,一直处于等待消息通知,不能够执行其他业务 。
非阻塞是指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回 。虽然表面上看非阻塞的方式可以明显的提高CPU的利用率, 但是也带了另外一种后果就是系统的线程切换增加 。 增加的CPU执行时间能不能补偿系统的切换成本需要好好评估 。
阻塞:当某个事件或者任务在执行过程中,它发出一个请求操作,但是由于该请求操作需要的条件不满足,那么就会一直在那等待,直至条件满足;
非阻塞:当某个事件或者任务在执行过程中,它发出一个请求操作,如果该请求操作需要的条件不满足,会立即返回一个标志信息告知条件不满足,不会一直在那等待。
这就是阻塞和非阻塞的区别。也就是说阻塞和非阻塞的区别关键在于当发出请求一个操作时,如果条件不满足,是会一直等待还是返回一个标志信息。
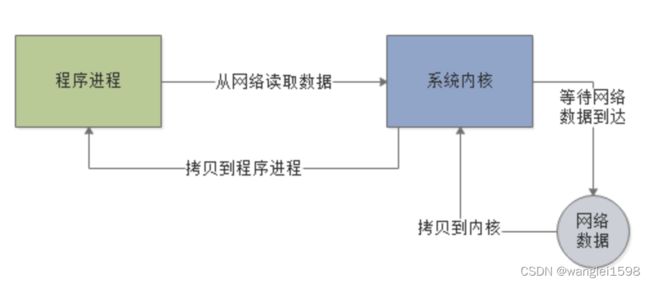
实际上 阻塞与非阻塞的概念,通常是针对底层的IO操作来说的 。
比如现在我们的程序想要通过网络读取数据,如果是阻塞IO模式,一旦发起请求到操作系统内核去从网络中读取数据,就会 阻塞 在那里,必须要等待网络中的数据到达了之后,才能从网络读取数据到内核,再从内核返回给程序,如下图。
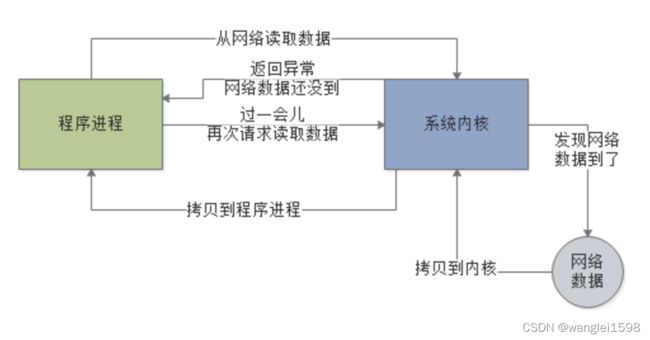
而 非阻塞 ,指的就是程序发送请求给内核要从网络读取数据,但是此时网络中的数据还没到,此时不会阻塞住,内核会返回一个异常消息给程序。
程序就可以干点儿别的,然后过一会儿再来发起一次请求给内核,让内核尝试从网络读取数据。
因为如果网络中的数据还没到位,是不会阻塞住程序的,需要程序自己不断的轮询内核去尝试读取数据,所以这种IO就是非阻塞的。如下图:
阻塞和同步的区别
对于同步调用来说,很多时候当前线程可能还是激活的,只是从逻辑上当前函数没有返回而已,此时,这个线程可能也会处理其他的消息 。还有一点,在这里先扩展下:
(a) 如果这个线程在等待当前函数返回时,仍在执行其他消息处理,那这种情况就叫做同步非阻塞;
(b) 如果这个线程在等待当前函数返回时,没有执行其他消息处理,而是处于挂起等待状态,那这种情况就叫做同步阻塞;
所以同步的实现方式会有两种:同步阻塞、同步非阻塞;同理,异步也会有两种实现:异步阻塞、异步非阻塞;
对于阻塞调用来说,则当前线程就会被挂起等待当前函数返回;
1.老王用水壶煮水,并且 站在那里 , 不管水开没开,每隔一定时间看看水开了没 。- 同步阻塞
老王想了想,这种方法不够聪明。
2.老王还是用水壶煮水,不再傻傻的站在那里看水开,跑去寝室上网,但是还是会每隔一段时间过来看看水开了没有,水没有开就走人。-同步非阻塞
老王想了想,现在的方法聪明了些,但是还是不够好。
3.老王这次使用高大上的响水壶来煮水,站在那里,但是不会再每隔一段时间去看水开,而是等水开了,水壶会自动的通知他。-异步阻塞
老王想了想,不会呀,既然水壶可以通知我,那我为什么还要傻傻的站在那里等呢,嗯,得换个方法。
4.老王还是使用响水壶煮水, 跑到客厅上网去 ,等着响水壶 自己把水煮熟了以后通知他 。- 异步非阻塞
-
同步和异步
同步就是烧开水,需要自己去轮询(每隔一段时间去看看水开了没),异步就是水开了,然后水壶会通知你水已经开了,你可以回来处理这些开水了。
同步和异步是相对于操作结果来说,会不会等待结果返回。
-
阻塞和非阻塞
阻塞就是说在煮水的过程中,你不可以去干其他的事情,非阻塞就是在同样的情况下,可以同时去干其他的事情。阻塞和非阻塞是相对于线程是否被阻塞。
消息通知
异步的概念和同步相对。当一个同步调用发出后,调用者要一直等待返回消息(结果)通知后,才能进行后续的执行;当一个异步过程调用发出后,调用者不能立刻得到返回消息(结果)。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
这里提到执行部件和调用者通过三种途径返回结果:状态、通知和回调。使用哪一种通知机制,依赖于执行部件的实现,除非执行部件提供多种选择,否则不受调用者控制。
如果执行部件用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(有些初学多线程编程的人,总喜欢用一个循环去检查某个变量的值,这其实是一种很严重的错误);
如果是使用通知的方式,效率则很高,因为执行部件几乎不需要做额外的操作。至于回调函数,其实和通知没太多区别。
在阻塞式io中,如果一个线程在等待io操作,那么cpu还会分配时间片给该线程吗?{运行态,就绪态,阻塞态}
运行态---wait/阻塞io-→阻塞态
运行态-------调度--------→就绪态
就绪态-------调度--------→运行态
阻塞态--- 信号/io返回-→就绪态
所以不占用时间片。
阻塞IO&&非阻塞IO
在阻塞模式下,若从网络流中读取不到指定大小的数据量,阻塞IO就在那里阻塞着。比如,已知后面会有10个字节的数据发过来,但是我现在只收到8个字节,那么当前线程就在那傻傻地等到下一个字节的到来,对,就在那等着,啥事也不做,直到把这10个字节读取完,这才将阻塞放开通行。
在非阻塞模式下,若从网络流中读取不到指定大小的数据量,非阻塞IO就立即通行。比如,已知后面会有10个字节的数据发过来,但是我现在只收到8个字节,那么当前线程就读取这8个字节的数据,读完后就立即返回,等另外两个字节再来的时候再去读取。
同步IO&&异步IO
在同步文件IO中,线程启动一个IO操作然后就立即进入等待状态,直到IO操作完成后才醒来继续执行。而异步文件IO方式中,线程发送一个IO请求到内核,然后继续处理其他的事情,内核完成IO请求后,将会通知线程IO操作完成了。
同步过程中进程触发IO操作并等待或者轮询的去查看IO操作是否完成。异步过程中进程触发IO操作以后,直接返回,做自己的事情,IO交给内核来处理,完成后内核通知进程IO完成
多线程
线程概念
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是行程中的实际运行单位。一条线程指的是进程中一个单一顺序的控制流,一個进程中可以并行多个线程,每条线程并行执行不同的任务。 每个线程共享堆空间,拥有自己独立的栈空间。
线程和进程的区别
-
线程划分尺度小于进程,线程隶属于某个进程;
-
进程是CPU、内存等资源占用的基本单位,线程是不能独立占有这些资源的;
-
进程之间相互独立,通信比较困难,而线程之间共享一块内存区域,通信方便;
-
进程在执行过程中,包含比较固定的入口、执行顺序和出口,而进程的这些过程会被应用程序控制
多线程 是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多个线程,进而提升整体处理效能。
多线程的优点
-
更高的运行效率。在多核CPU上,线程之间是互相独立的,不用互相等待,也就是所谓的“并行“。举个例子,一个使用多线程的文件系统可以实现高吞吐量和低延迟。这是因为我们可以用一个线程来检索存储在高速介质(例如高速缓冲存储器)中的数据,另一个线程检索低速介质(例如外部存储)中的数据,二者互不干扰,也不用等到另一个线程结束才执行;
-
多线程是模块化的编程模型。在单线程中,如果主执行线程在一个耗时较长的任务上卡住,或者因为网络响应问题陷入长时间等待,此时程序不会响应鼠标和键盘等操作。多线程通过将程序分成几个功能相对独立的模块,单独分配一个线程去执行这个长耗时任务,不影响其它线程的执行,就可以避免这个问题;
-
与进程相比,线程的创建和切换开销更小。使用多线程为多个客户端服务,比使用多进程消耗的资源少得多。由于启动一个新的线程必须给这个线程分配独立的地址空间,建立许多数据结构来维护线程代码段、数据段等信息,而运行于同一进程内的线程共享代码段、数据段,线程的启动和切换开销小得多。一个典型的应用例子就是Apache HTTP服务器所使用的线程池: 一个监听线程池专门用来监听是否有请求进入,另一个服务器线程池用来处理这些请求;
-
通信方便。因为线程共享栈空间,可以通过线程之间共享的数据、代码和文件来进行线程之间的通信(详见我的另一篇 JAVA多线程(四)数据共享 )。相比之下,进程之间的通信则需要专门的消息传递机制;
-
使用多线程能简化程序的结构,使程序便于理解和维护。一个复杂的进程可以分成多个线程来执行;
-
更高的资源利用率。多CPU或多核计算机本来就具有执行多线程的能力,如果只使用单个线程,将无法重复利用计算机资源,造成巨大浪费。
弊端 :尽管使用多线程往往可以获得更大的吞吐率和更短的响应时间,但是,多线程程序不一定比单线程程序执行速度快。很多线程存在情况下,线程之间的切换会非常频繁,切换带来的性能损耗是非常可观的。
上下文切换(context switch)
在多任务处理系统中,作业数通常大于CPU数。为了让用户觉得这些任务在同时进行,CPU给每个任务分配一定时间,把当前任务状态保存下来,当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。之后CPU可以回过头再处理之前被挂起任务。上下文切换就是这样一个过程,它允许CPU记录并恢复各种正在运行程序的状态,使它能够完成切换操作。在这个过程中,CPU会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后继续运行。
上下文切换在不同的场合有不同的含义,在下表中列出:
|
上下文切换种类
|
描述
|
|
线程切换
|
同一进程中的两个线程之间的切换
|
|
进程切换
|
两个进程之间的切换
|
|
模式切换
|
在给定线程中,用户模式和内核模式的切换
|
|
地址空间切换
|
将虚拟内存切换到物理内存
|
根据种类的不同,切换时造成的性能消耗也不同。
|
上下文切换发生条件
|
描述
|
|
中断处理
|
中断分为硬件中断和软件中断,软件中断包括因为IO阻塞、未抢到资源或者用户代码等原因,线程被挂起
|
|
多任务处理
|
每个程序都有相应的处理时间片,当前任务的时间片用完之后,系统CPU正常调度下一个任务
|
|
用户态切换
|
这种情况下,上下文切换并非一定发生,只在特定操作系统才会发生上下文切换
|
上下文切换的原因大概有以下几种: 1. 当前执行任务的时间片用完之后, 系统CPU正常调度下一个任务 2. 当前执行任务碰到IO阻塞, 调度器将挂起此任务, 继续下一任务 3. 多个任务抢占锁资源, 当前任务没有抢到,被调度器挂起, 继续下一任务 4. 用户代码挂起当前任务, 让出CPU时间 5. 硬件中断.
上下文切换的步骤
PCB通常是系统内存占用区中的一个连续存区,它 存放着操作系统用于描述进程情况及控制进程运行所需的全部信息 ,它使一个在多道程序环境下不能独立运行的程序成为一个能独立运行的基本单位或一个能与其他进程并发执行的进程。
上下文切换的具体步骤是(假设当前进程是进程A,要切换到的下一个进程是进程B):
-
保存进程A的状态(寄存器和操作系统数据);
-
更新PCB中的信息,对进程A的“运行态”做出相应更改;
-
将进程A的PCB放入相关状态的队列;
-
将进程B的PCB信息改为“运行态”,并执行进程B;
-
B执行完后,从队列中取出进程A的PCB,恢复进程A被切换时的上下文,继续执行A。
线程分为用户级线程和内核级线程。同一进程中的用户级线程切换的时候,只需要保存用户寄存器的内容,程序计数器,栈指针,不需要模式切换。但是这样会导致线程阻塞和无法利用多处理器。而同一进程中的内核级线程切换的时候,就克服了这两个缺点,但是除了保存上下文,还要进行模式切换。
线程切换和进程切换的步骤也不同。进程的上下文切换分为两步:1.切换页目录以使用新的地址空间;2.切换内核栈和硬件上下文。对于linux来说,线程和进程的最大区别就在于地址空间。对于线程切换,第1步是不需要做的,第2是进程和线程切换都要做的。所以明显是进程切换代价大。
线程上下文切换和进程上下文切换一个最主要的区别是 线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的 。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
上下文切换会导致CPU在寄存器和运行队列之间来回奔波。这种消耗可以分为两种
|
损耗种类
|
描述
|
|
直接损耗
|
CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉
|
|
间接损耗
|
多核的cache之间得共享数据
|
查看上下文切换数 vmstat 命令
三大问题:
1.可见性
可见性是什么?
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
为什么会有可见性问题?
对于如今的多核处理器,每颗CPU都有自己的缓存,而缓存仅仅对它所在的处理器可见,CPU缓存与内存的数据不容易保证一致。
为了避免处理器停顿下来等待向内存写入数据而产生的延迟,处理器使用写缓冲区来临时保存向内存写入的数据。写缓冲区合并对同一内存地址的多次写,并以批处理的方式刷新,也就是说 写缓冲区不会即时将数据刷新到主内存中 。
缓存不能及时刷新导致了可见性问题。
Java提供了以下三种方式来保证可见性。
1.使用关键字volatile,当一个变量被volatile关键字修饰时,对于共享资源的读操作会直接在主内存中进行(当然也会缓存到工作内存中,当其他线程对该共享资源进行了修改,则会导致当前线程在工作内存中的共享资源失效,所以必须从主内存中再次获取),对于共享资源的写操作当然是先要修改工作内存,但是修改结束后会立刻将其刷新到主内存中。
2.通过synchronized关键字能够保证可见性,synchronized关键字能够保证同一时刻只有一个线程获得锁,然后执行同步方法,并且还会确保在锁释放之前,会将对变量的修改刷新到主内存当中。
3.通过JUC提供的显式锁Lock也能够保证可见性,Lock的lock方法能够保证在同一时刻只有一个线程获得锁然后执行同步方法,并且会确保在锁释放(Lock的unlock方法)之前会将对变量的修改刷新到主内存当中。
Synchronized和volatile可以保证共享资源在多线程间的可见性,但是实现机制完全不同。
·synchronized借助于JVM指令monitor enter和monitor exit对通过排他的方式使得同步代码串行化,在monitor exit时所有共享资源都将会被刷新到主内存中。
·相比较于synchronized关键字,volatile使用机器指令(偏硬件)“lock;”的方式迫使其他线程工作内存中的数据失效,不得到主内存中进行再次加载。
2.原子性
原子性是什么?
把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。
在并发编程中,原子性的定义不应该和事务中的原子性(一旦代码运行异常可以回滚)一样。应该理解为:一段代码,或者一个变量的操作,在一个线程没有执行完之前,不能被其他线程执行。
为什么会有原子性问题?
线程是CPU调度的基本单位。CPU会根据不同的调度算法进行线程调度,将时间片分派给线程。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去CPU使用权。多线程场景下,由 于时间片在线程间轮换,就会发生原子性问题 。
如:对于一段代码,一个线程还没执行完这段代码但是时间片耗尽,在等待CPU分配时间片,此时其他线程可以获取执行这段代码的时间片来执行这段代码,导致多个线程同时执行同一段代码,也就是原子性问题。
线程切换带来原子性问题。
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
以得出以下几个结论。
·多个原子性的操作在一起就不再是原子性操作了。
·简单的读取与赋值操作是原子性的,将一个变量赋给另外一个变量的操作不是原子性的。
·Java内存模型(JMM)只保证了基本读取和赋值的原子性操作,其他的均不保证,如果想要使得某些代码片段具备原子性,需要使用关键字synchronized,或者JUC中的lock。如果想要使得int等类型自增操作具备原子性,可以使用JUC包下的原子封装类型java.util.concurrent.atomic.*
三、有序性
有序性:程序执行的顺序按照代码的先后顺序执行。
编译器为了优化性能,有时候会改变程序中语句的先后顺序。例如程序中:“a=6;b=7;”编译器优化后可能变成“b=7;a=6;”,在这个例子中,编译器调整了语句的顺序,但是不影响程序的最终结果。不过有时候编译器及解释器的优化可能导致意想不到的Bug。
在Java的内存模型中,允许编译器和处理器对指令进行重排序,在单线程的情况下,重排序并不会引起什么问题,但是在多线程的情况下,重排序会影响到程序的正确运行,Java提供了三种保证有序性的方式,具体如下。
·使用volatile关键字来保证有序性。
·使用synchronized关键字来保证有序性。
·使用显式锁Lock来保证有序性。
重排序
不同处理器(硬件系统)的重排序表现不一样。
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序: 
-
编译器优化的重排序 。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
-
指令级并行的重排序 。处理器将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
-
内存系统的重排序 。处理器使用缓存和读/写缓冲区,使得加载和存储操作看上去可能是在乱序执行。
重排序需要遵守一定规则,以保证程序正确执行。
重排序遵守数据依赖性
数据依赖性 :如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
存在数据依赖性的三种情况:
① 写后读:a = 1;b = a; 写一个变量之后,再读这个位置。
② 写后写:a = 1;a = 2; 写一个变量之后,再写这个变量。
③ 读后写:a = b;b = 1;读一个变量之后,再写这个变量。
存在数据依赖关系的两个操作,不可以重排序。
数据依赖性只针对单个处理器中执行的指令序列和单个线程中执行的操作。
重排序遵守as-if-serial 语义
as-if-serial 语义:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。
笔者看来,遵守数据依赖性和as-if-serial 语义实质上是一回事。为了遵守 as-if-serial 语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。
重排序可以提高程序执行的性能,但是代码的执行顺序改变,可能会 导致多线程程序出现可见性问题和有序性问题 。
JMM处理重排序问题:
1)对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。
2)对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,来禁止特定类型的处理器重排序。
3)JMM根据代码中的关键字(如:synchronized、volatile)和J.U.C包下的一些具体类来插入内存屏障。
JMM 把内存屏障指令分为下列四类: 
Store: 数据对其他处理器可见(即: 刷新到内存中)
Load: 让缓存中的数据失效,重新从主内存加载数据
机器硬件CPU
在计算机中,所有的运算操作都是由CPU的寄存器来完成的,CPU指令的执行过程需要涉及数据的读取和写入操作,CPU所能访问的所有数据只能是计算机的主存(通常是指RAM),虽然CPU的发展频率不断地得到提升,但受制于制造工艺以及成本等的限制,计算机的内存反倒在访问速度上并没有多大的突破,因此CPU的处理速度和内存的访问速度之间的差距越拉越大,通常这种差距可以达到上千倍,极端情况下甚至会在上万倍以上。
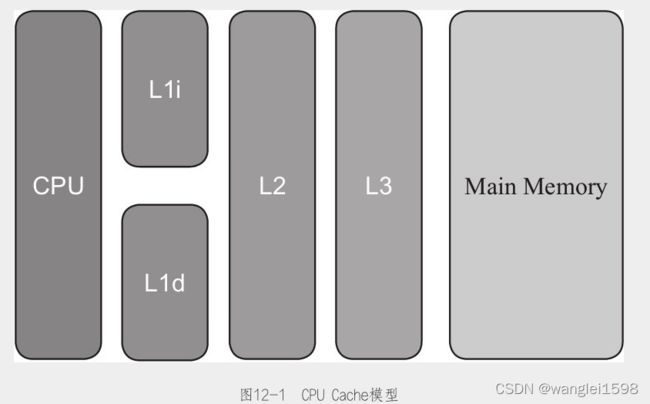
12.2.1 CPU Cache模型
由于两边速度严重的不对等,通过传统FSB直连内存的访问方式很明显会导致CPU资源受到大量的限制,降低CPU整体的吞吐量,于是就有了在CPU和主内存之间增加缓存的设计,现在缓存的数量都可以增加到3级了,最靠近CPU的缓存称为L1,然后依次是L2,L3和主内存,CPU缓存模型如图12-1所示。
由于程序指令和程序数据的行为和热点分布差异很大,因此L1 Cache又被划分成了L1i(i是instruction的首字母)和L1d(d是data的首字母)这两种有各自专门用途的缓存,CPU Cache又是由很多个Cache Line构成的,Cache Line可以认为是CPU Cache中的最小缓存单位,目前主流CPU Cache的Cache Line大小都是64字节,图12-2是一张主存以及各级缓存之间的响应时间对比图。
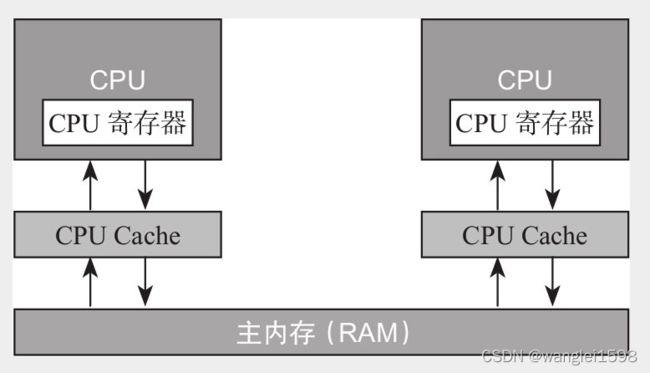
Cache的出现是为了解决CPU直接访问内存效率低下问题的,程序在运行的过程中,会将运算所需要的数据从主存复制一份到CPU Cache中,这样CPU进行计算时就可以直接对CPU Cache中的数据进行读取和写入,当运算结束之后,再将CPU Cache中的最新数据刷新到主内存当中,CPU通过直接访问Cache的方式替代直接访问主存的方式极大地提高了CPU的吞吐能力,有了CPU Cache之后,整体的CPU和主内存之间交互的架构大致如图12-3所示。
CPU告诉缓存比CPU的寄存器慢,但比主存快。
一般L1和L2缓存是各CPU私有。L3缓存是部分核心或者所有核心共享的。
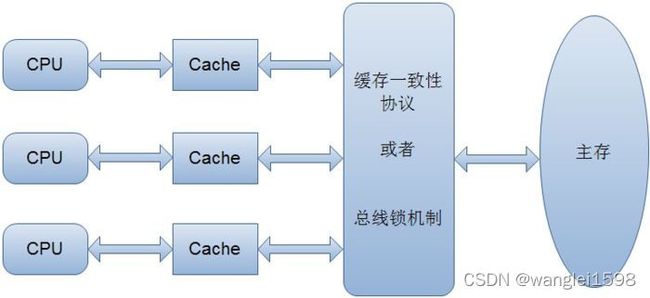
12.2.2 CPU缓存一致性问题
由于缓存的出现,极大地提高了CPU的吞吐能力,但是同时也引入了缓存不一致的问题,比如i++这个操作,在程序的运行过程中,首先需要将主内存中的数据复制一份存放到CPU Cache中,那么CPU寄存器在进行数值计算的时候就直接到Cache中读取和写入,当整个过程运算结束之后再将Cache中的数据刷新到主存当中,具体过程如下。
1)读取主内存的i到CPU Cache中。
2)对i进行加一操作。
3)将结果写回到CPU Cache中。
4)将数据刷新到主内存中。
i++在单线程的情况下不会出现任何问题,但是在多线程的情况下就会有问题,每个线程都有自己的工作内存(本地内存,对应于CPU中的Cache),变量i会在多个线程的本地内存中都存在一个副本。如果同时有两个线程执行i++操作,假设i的初始值为0,每一个线程都从主内存中获取i的值存入CPU Cache中,然后经过计算再写入主内存中,很有可能i在经过了两次自增之后结果还是1,这就是典型的缓存不一致性问题。
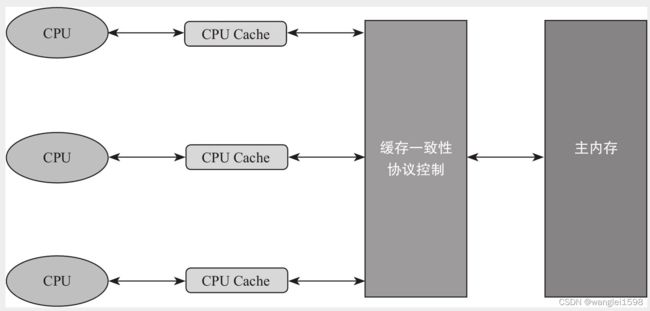
为了解决缓存不一致性问题,通常主流的解决方法有如下两种。
·通过总线加锁的方式。
·通过缓存一致性协议。
第一种方式常见于早期的CPU当中,而且是一种悲观的实现方式,CPU和其他组件的通信都是通过总线(数据总线、控制总线、地址总线)来进行的,如果采用总线加锁的方式,则会阻塞其他CPU对其他组件的访问,从而使得只有一个CPU(抢到总线锁)能够访问这个变量的内存。这种方式效率低下,所以就有了第二种通过缓存一致性协议的方式来解决不一致的问题(见图12-4)
在缓存一致性协议中最为出名的是Intel的MESI协议,MESI协议保证了每一个缓存中使用的共享变量副本都是一致的,它的大致思想是,当CPU在操作Cache中的数据时,如果发现该变量是一个共享变量,也就是说在其他的CPU Cache中也存在一个副本,那么进行如下操作:
1)读取操作,不做任何处理,只是将Cache中的数据读取到寄存器。
2)写入操作,发出信号通知其他CPU将该变量的Cache line置为无效状态,其他CPU在进行该变量读取的时候不得不到主内存中再次获取。
高速缓存一致性协议(cache consistency protocol)
CPU缓存一致性协议MESI_Jehue的博客-CSDN博客_缓存一致性协议
内存屏障(Memory Barrier )
上面讲到了,通过内存屏障可以禁止特定类型处理器的重排序,从而让程序按我们预想的流程去执行。
内存屏障,又称内存栅栏,是一个CPU指令,基本上它是一条这样的指令:
保证特定操作的执行顺序。
影响某些数据(或则是某条指令的执行结果)的内存可见性。
编译器和CPU能够重排序指令,保证最终相同的结果,尝试优化性能。插入一条Memory Barrier会告诉编译器和CPU: 不 管什么指令都不能和这条Memory Barrier指令重排序。
Memory Barrier所做的另外一件事是 强制刷出各种CPU cache,如一个Write-Barrier(写入屏障)将刷出所有在Barrier之前写入 cache 的数据,因此,任何CPU上的线程都能读取到这些数据的最新版本。
java内存模型volatile是基于Memory Barrier实现的。
如果一个变量是volatile修饰的,JMM会在写入这个字段之后插进一个Write-Barrier指令,并在读这个字段之前插入一个Read-Barrier指令。这意味着,如果写入一个volatile变量,就可以保证:
一个线程写入变量a后,任何线程访问该变量都会拿到最新值。
在写入变量a之前的写入操作,其更新的数据对于其他线程也是可见的。因为Memory Barrier会刷出cache中的所有先前的写入。
最低限的安全性:
当一个线程在没有同步的情况下读取变量,它可能会得到一个过期值。但至少它可以看到某个线程在那里设定的一个真实值,而不是一个凭空而来的值。
最低限的安全性应用于所有变量,除一例外:没有声明为volatile的64位数值变量(double和long)。Java存储模型要求获取和存储操作都是原子的,但是对于非volatile的long 和double变量,JVM允许将64位的读或写划分为两个32位的操作。如果读和写发生在两个不同的线程,这种情况读取一个非volatile的long就可能会得到一个值得高32位和一个值的低32位。因此,即使你不关心过期数据,但仅仅在多线程程序中使用共享的、可变的long和double变量也可能是不安全的,除非将它们声明为volatile类型,或者用锁保护起来。
Java内存模型要求lock、unlock、read、load、assign、use、store、write这8个操作都是具有原子性,但是对于64位的数据类型(long、double),允许虚拟机将没有被volatile修饰的64位数据的读写操作划分为两次32位的操作来进行,即允许虚拟机实现选择可以不保证64位数据类型的load、store、read和write这四个原子操作,但是可以视为原子性操作。
java 内存模型
https://mp.weixin.qq.com/s?__biz=MzIxMjE5MTE1Nw==&mid=2653193452&idx=1&sn=0f7126c6ebf20ced0f125461f8035064&chksm=8c99f636bbee7f20ffc0e5e870356e5865f7
76b3bb28baa4375b318a72899822ef92bc18e671&mpshare=1&scene=1&srcid=0320AUcJla5A1QPSoWVGuAoy#rd
终于有人把Java内存模型说清楚了!
Java的内存模型(Java Memory Mode,JMM)指定了Java虚拟机如何与计算机的主存(RAM)进行工作,如图12-5所示,理解Java内存模型对于编写行为正确的并发程序是非常重要的。在JDK1.5以前的版本中,Java内存模型存在着一定的缺陷,在JDK1.5的时候,JDK官方对Java内存模型重新进行了修订,JDK1.8及最新的JDK版本都沿用了JDK1.5修订的内存模型。
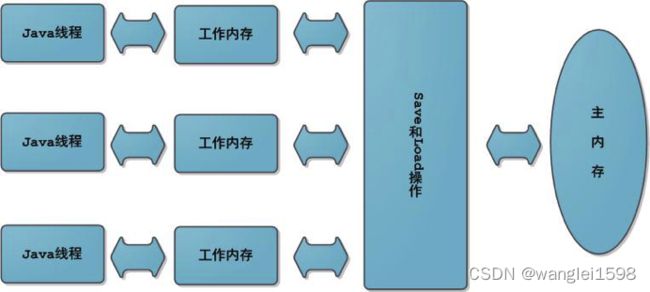
Java的内存模型决定了一个线程对共享变量的写入何时对其他线程可见,Java内存模型定义了线程和主内存之间的抽象关系,具体如下。
·共享变量存储于主内存之中,每个线程都可以访问。
·每个线程都有私有的工作内存或者称为本地内存。
·工作内存只存储该线程对共享变量的副本。
·线程不能直接操作主内存,只有先操作了工作内存之后才能写入主内存。
·工作内存和Java内存模型一样也是一个抽象的概念,它其实并不存在,它涵盖了缓存、寄存器、编译器优化以及硬件等。
假设主内存的共享变量为0,线程1和线程2分别拥有共享变量X的副本,假设线程1此时将工作内存中的x修改为1,同时刷新到主内存中,当线程2想要去使用副本x的时候,就会发现该变量已经失效了,必须到主内存中再次获取然后存入自己的工作内容中,这一点和CPU与CPU Cache之间的关系非常类似。
Java的内存模型是一个抽象的概念,其与计算机硬件的结构并不完全一样,比如计算机物理内存不会存在栈内存和堆内存的划分,无论是堆内存还是虚拟机栈内存都会对应到物理的主内存,当然也有一部分堆栈内存的数据有可能会存入CPU Cache寄存器中。图12-6所示的是Jave内存模型与CPU硬件架构的交互图。
JVM 首先会在main memory(JVM堆)给变量分配一个内存空间,并存储其值为0.
线程启动后,会分配一片working memory 区(通常是操作数栈)。当线程执行i++,JVM分为5步执行(装载、读取、操作、存储、写入)
JVM把对于working memory的操作分为了 use assign load store lock unlock.对于main memory的操作分为 read write lock unlock
Java内存模型8种操作
-
1) lock(锁定) 作用于主内存的变量,它把一个变量标志为一条线程独占的状态
-
2) unlock(解锁) 作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其它线程锁定
-
3) read(读取) 作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
-
4) load(载入) 作用于工作内存的变量,它把read操作从主内存得到的变量值放入工作内存的变量副本中
-
5) use(使用) 作用于工作内存的变量,它把变量副本的值传递给执行引擎,每当虚拟机遇到一个需要使用的变量的值的字节码指令时,将会执行这个操作。
-
6) assign(赋值) 作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作副本变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作
-
7) store(存储) 作用于工作内存的变量,将工作副本变量的值传输给主内存,以便随后的write操作使用
-
8) write(写入) 作用于主内存的变量, 它把store操作从工作内存得到的变量的值放入主内存的变量
Java内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
-
不允许read和load、store和write操作之一单独出现
-
不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中。
-
不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中。
-
一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
-
一个变量在同一时刻只允许一条线程对其进行lock操作,lock和unlock必须成对出现
-
如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值
-
如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量。
-
对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。
原子访问
https://docs.oracle.com/javase/tutorial/essential/concurrency/atomic.html
-
Reads and writes are atomic for reference variables and for most primitive variables ( all types except long and double).
-
Reads and writes are atomic for all variables declared volatile ( including long and double variables).
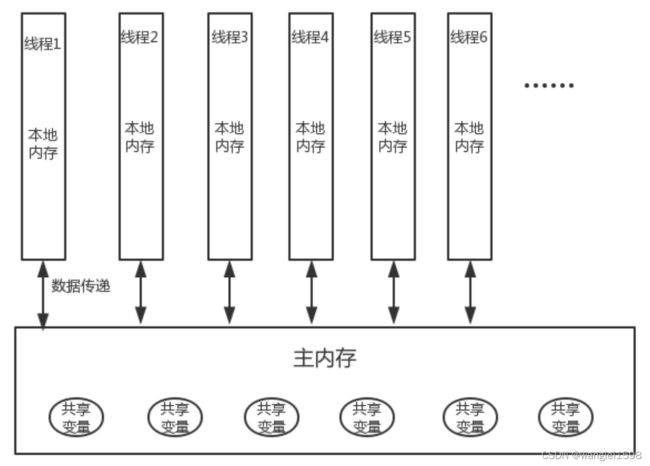
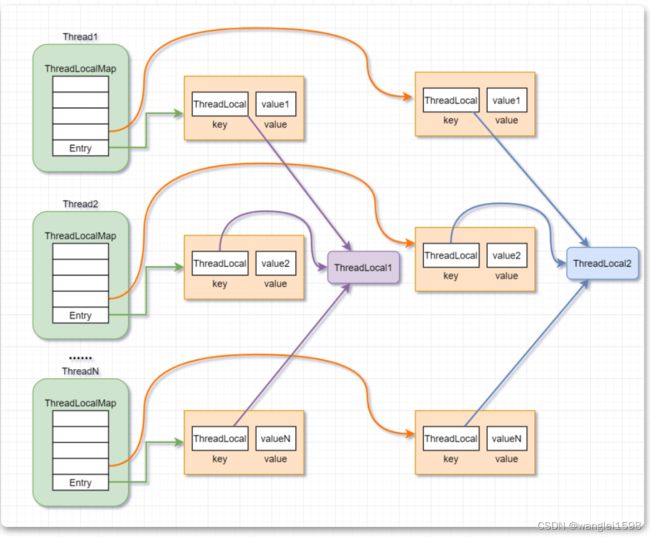
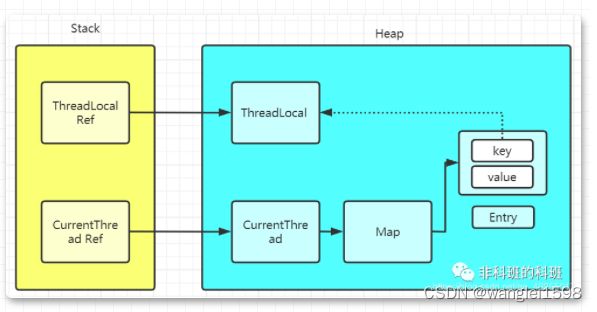
每个Thread都拥有自己的线程存储空间
Thread何时同步本地存储空间的数据到主存是不确定的
每个线程都有自己的工作内存,会先将线程从主内存中读入到工作内存中。使用volatile修饰的对象,直接读写主内存。
对于一写多读,是可以解决变量的同步问题,但是如果是多写,同样无法解决线程安全问题。
i++和++i并非原子操作
count++ 程序代码是一行,但是翻译成 CPU 指令确是三行( 不信你用 javap -c 命令试试)
子性的操作组合而来的,因此它们就不具备原子性。这样的语句的具体实现步骤如下。
1)将主内存中x的值读取到CPU Cache中。
2)对x进行加一运算。
3)将结果写回到CPU Cache中。
4)将x的值刷新到主内存中。
再比如,long类型的加法x+1的操作就不是原子性的。在Brian Goetz、Tim Peierls、Joshua Bloch、Joseph Bowbeer、David Holmes、Doug Lea合著的《Java Concurrency in Practice》一书的Nonatomic 64-bit operations章节中提到过:“a 64-bit write operation is basically performed as two separate 32-bit operations. This behavior can result in indeterminate valuesbeing read in code and that lacks atomicity.”(一个64位写操作实际上将会被拆分为2个32位的操作,这一行为的直接后果将会导致最终的结果是不确定的并且缺少原子性的保证。)在Java虚拟机规范中同样也有类似的描述:“For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separatewrites: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.”详见虚拟机官方网址,地址如下:
Chapter 17. Threads and Locks
在JDK 1.5版本之前,为了确保在多线程下对某基本数据类型或者引用数据类型运算的原子性,必须依赖于关键字synchronized,但是自JDK 1.5版本以后这一情况发生了改变,JDK官方为开发者提供了原子类型的工具集,比如AtomicInteger、AtomicBoolean等,这些原子类型都是Lock-Free及线程安全的,开发者将不再为一个数据类型的自增运算而增加synchronized的同步操作。本章将为大家详细介绍Java的各种原子类型(实际上在Java推出原子工具集之前,很多第三方库也提供了类似的解决方案,比如Google的Guava,甚至于JDK自身的原子类工具集也是来自DougLea的个人项目)。
JMM抽象结构模型
JMM定义了线程和主内存之间的抽象关系:
-
线程之间的共享变量存储在主内存中
-
每个线程都有一个私有的本地内存,本地内存中存储了该线程用以读/写共享变量的副本
共享变量:堆内存在线程之间共享,存储在堆内存中所有实例域、静态域和数组元素都是共享变量
Java内存模型
JMM解决可见性和有序性问题
-
要求程序员都去搞懂重排序以及JMM内存屏障再去编程是不现实的。
-
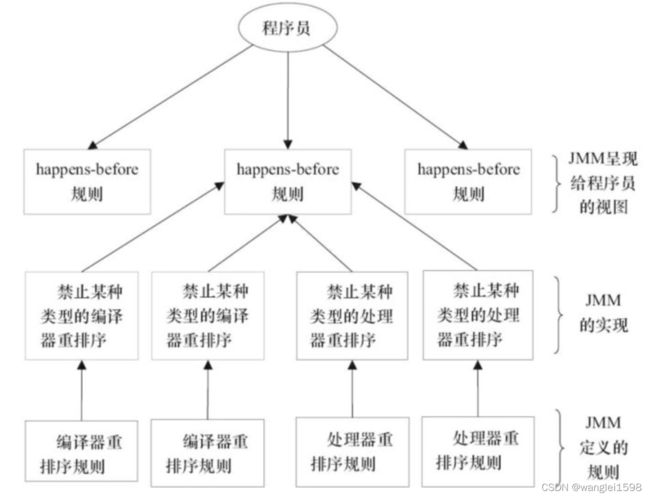
JMM提供了简单易懂的happens-before原则,并向程序员保证执行并发程序会遵守happens-before原则。
-
程序员只需理解happens-before原则,按照happens-before原则写并发代码,就能保证内存可见性和有序性。
JMM的设计
1.程序员对内存模型的使用
程序员希望内存模型易于理解、易于编程。程序员希望基于一个强内存模型来编写代码。
JMM向程序员提供的happens-before规则,简单易懂且提供了足够强的内存可见性保证。程序员可以把happens-before规则当做强内存模型看待。
2.编译器和处理器对内存模型的实现
编译器和处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。编译器和处理器希望实现一个弱内存模型。
JMM遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。
Happens-Before https://docs.oracle.com/javase/tutorial/essential/concurrency/memconsist.html
一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
两个操作可以是单线程或多线程,happens-before解决的就是多线程内存可见性问题。区分数据依赖性和as-if-seial针对单线程。
happens-before原则定义如下:
1)一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
2)两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
happens-before原则规则:
1)程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
2)锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
3)volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
4)传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
5)线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
6)线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
7)线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过 Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
8)对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
JMM与原子性问题
Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,需要通过互斥加锁synchronized和Lock来实现。
这里A happens- before B,但实际执行时B却可以排在A之前执行(看上面的重排序后的执行顺序)。在第一章提到过, 如果A happens- before B,JMM并不要求A一定要在B之前执行。JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作A的执行结果不需要对操作B可见;而且重排序操作A和操作B后的执行结果,与操作A和操作B按happens- before顺序执行的结果一致。在这种情况下,JMM会认为这种重排序并不非法(not illegal),JMM允许这种重排序。
Volatile
1.保证可见性
volatile保证了不同线程对volatile修饰变量进行操作时的可见性。
对一个volatile变量的读,(任意线程)总是能看到对这个volatile变量最后的写入。
-
一个线程修改volatile变量的值时,该变量的新值会立即刷新到主内存中,这个新值对其他线程来说是立即可见的。
-
一个线程读取volatile变量的值时,该变量在本地内存中缓存无效,需要到主内存中读取。
2.保证有序性
volatile保证了不同线程对volatile修饰变量进行操作时的可见性。
对一个volatile变量的读,(任意线程)总是能看到对这个volatile变量最后的写入。
-
一个线程修改volatile变量的值时,该变量的新值会立即刷新到主内存中,这个新值对其他线程来说是立即可见的。
-
一个线程读取volatile变量的值时,该变量在本地内存中缓存无效,需要到主内存中读取。
3.不保证原子性
volatile是不能保证原子性的。
原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行。
4.实现原理
volatile保证有序性原理
volatile-可见性通过加入内存屏障和禁止重排序优化实现:
前文介绍过,JMM通过插入内存屏障指令来禁止特定类型的重排序。
java编译器在生成字节码时,在volatile变量操作前后的指令序列中插入内存屏障来禁止特定类型的重排序。
volatile内存屏障插入策略:
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个StoreLoad屏障。
在每个volatile读操作的后面插入一个LoadLoad屏障。
在每个volatile读操作的后面插入一个LoadStore屏障。

内存屏障
Store:数据对其他处理器可见(即:刷新到内存中)
Load:让缓存中的数据失效,重新从主内存加载数据
volatile保证可见性原理
volatile内存屏障插入策略中有一条,“在每个volatile写操作的后面插入一个StoreLoad屏障”。
StoreLoad屏障会生成一个Lock前缀的指令,Lock前缀的指令在多核处理器下会引发了两件事:
1. 将当前处理器缓存行的数据写回到系统内存。
2. 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
volatile内存可见的写-读过程:
-
volatile修饰的变量进行写操作。
-
由于编译期间JMM插入一个StoreLoad内存屏障,JVM就会向处理器发送一条Lock前缀的指令。
-
Lock前缀的指令将该变量所在缓存行的数据写回到主内存中,并使其他处理器中缓存了该变量内存地址的数据失效。
-
当其他线程读取volatile修饰的变量时,本地内存中的缓存失效,就会到到主内存中读取最新的数据。
在JVM中,可以使用volatile关键字修饰变量,或者使用JUC包中的原子性变量(如AtomicLong)对普通变量进行包装,来保证多线程下共享变量的内存可见性,当然使用加锁的方式也可以保证内存可见性,但是其开销更大。既然使用volatile关键字可以解决共享变量内存可见性问题,那么为何不把所有变量都使用volatile修饰呢?这是因为使用volatile修饰变量,写入该变量的时候会把Cache直接刷新回内存,读取时会把Cache内缓存失效,然后从主内存加载数据,这就 破坏了Cache的命中率,对性能是有损的。
并发编程中的Final
写final域
在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
编译器会在final域的写之后,插入一个StoreStore屏障,这个屏障可以禁止处理器把final域的写重排序到构造函数之外。
解释:保证先写入对象的final变量,后调用该对象引用。
读final域
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
编译器会在读final域操作的前面插入一个LoadLoad屏障,这个屏障可以禁止读对象引用和读该对象final域重排序。
解释:先读对象的引用,后读该对象的final变量。
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
编译器会在读final域操作的前面插入一个LoadLoad屏障,这个屏障可以禁止读对象引用和读该对象final域重排序。
解释:先读对象的引用,后读该对象的final变量。
Synchronize 关键字
线程安全问题
并发编程中,当多个线程同时访问同一个资源的时候,就会存在线程安全问题。
由于每个线程执行的过程是不可控的,所以很可能导致最终的结果与实际期望的结果相违背或者直接导致程序出错。
基本上所有的并发模式在解决线程安全问题时,都采用“序列化访问临界资源”的方案,即在同一时刻,只能有一个线程访问临界资源,也称作同步互斥访问。
通常来说,是在访问临界资源的代码前面加上一个锁,当访问完临界资源后释放锁,让其他线程继续访问。
在Java中,提供了两种方式来实现同步互斥访问:synchronized和Lock。
Java中用synchronized标记同步块。
-
同步块在Java中是同步在某个对象上(监视器对象)。
-
所有同步在一个对象上的同步块在同一时间只能被一个线程进入并执行操作。
-
所有其他等待进入该同步块的线程将被阻塞,直到执行该同步块中的线程退出。
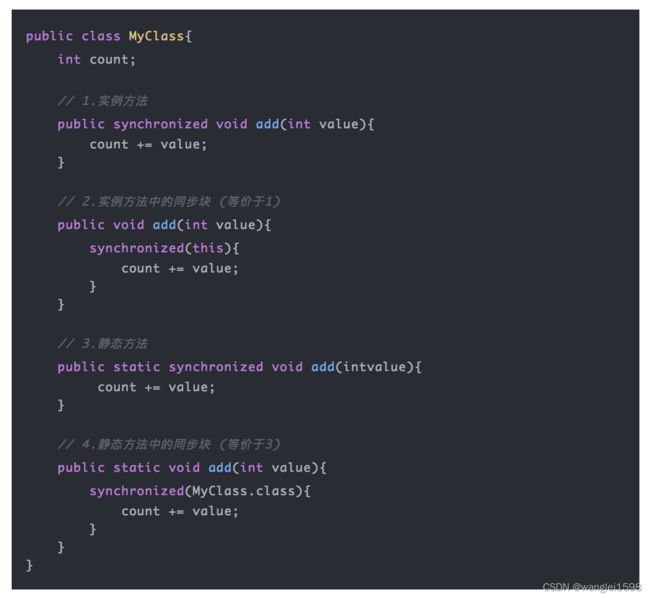
synchronized用法
-
普通同步方法,锁是当前实例对象
-
静态同步方法,锁是当前类的class对象
-
同步方法块,锁是括号里面的对象
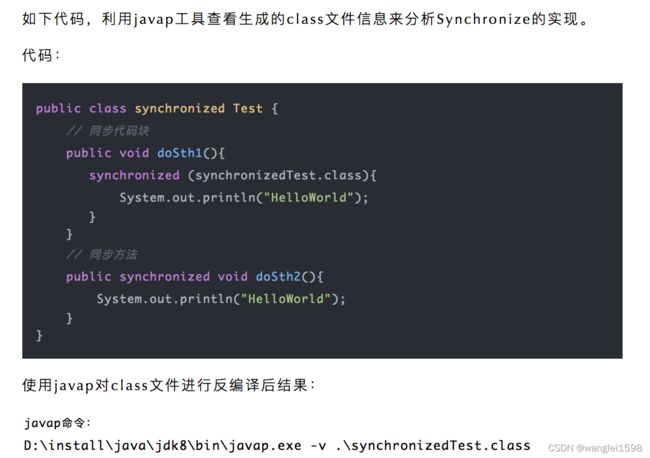
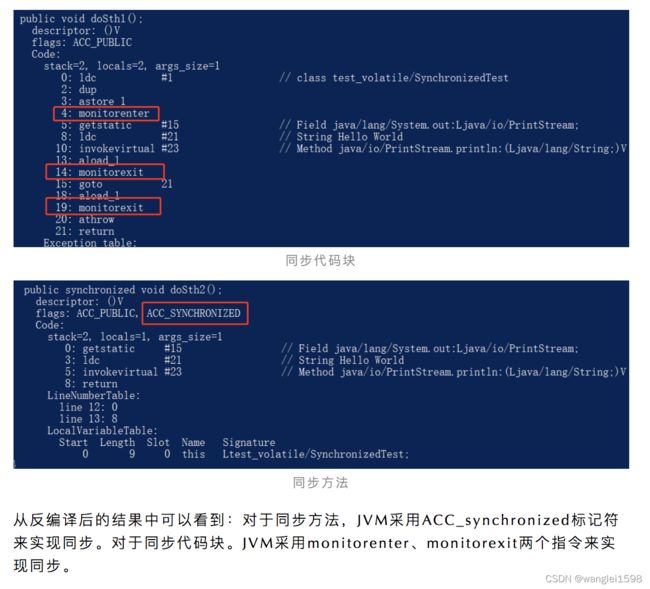
synchronize的实现
同步代码块
JVM采用monitorenter、monitorexit两个指令来实现同步代码块。
查询JVM规范
The Java® Virtual Machine Specification [1]中关于monitorenter和monitorexit的介绍:

大致内容如下:
-
可以把执行monitorenter指令理解为加锁,执行monitorexit理解为释放锁。
-
每个对象维护着一个记录着被锁次数的计数器。
-
未被锁定的对象的该计数器为0,当一个线程获得锁(执行monitorenter)后,该计数器自增变为1,当同一个线程再次获得该对象的锁的时候,计数器再次自增。当同一个线程释放锁(执行monitorexit指令)的时候,计数器再自减。
-
当计数器为0的时候。锁将被释放,其他线程便可以获得锁。
monitorenter
每一个对象都有一个monitor,一个monitor只能被一个线程拥有。当一个线程执行到monitorenter指令时会尝试获取相应对象的monitor,获取规则如下:
-
如果monitor的进入数为0,则该线程可以进入monitor,并将monitor进入数设置为1,该线程即为monitor的拥有者。
-
如果当前线程已经拥有该monitor,只是重新进入,则进入monitor的进入数加1,所以synchronized关键字实现的锁是可重入的锁。
-
如果monitor已被其他线程拥有,则当前线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor。
monitorexit
只有拥有相应对象的monitor的线程才能执行monitorexit指令。每执行一次该指令monitor进入数减1,当进入数为0时当前线程释放monitor,此时其他阻塞的线程将可以尝试获取该monitor。
同步方法
JVM采用ACC_synchronized标记符来实现同步方法。
查询JVM规范
The Java® Virtual Machine Specification [2]中关于方法级同步的介绍:

大致内容如下:
-
方法级的同步是隐式的。同步方法的常量池中会有一个ACC_synchronized标志。
-
当某个线程要访问某个方法的时候,会检查是否有ACC_synchronized,如果有设置,则需要先获得监视器锁(monitor),然后开始执行方法,方法执行之后再释放监视器锁。这时如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住。
-
值得注意的是,如果在方法执行过程中,发生了异常,并且方法内部并没有处理该异常,那么在异常被抛到方法外面之前监视器锁会被自动释放。
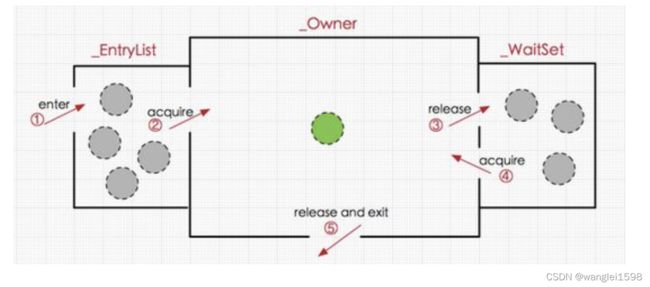
Monitor
无论是同步方法还是同步代码块都是基于监视器Monitor实现的。
Monitor是什么?
所有的Java对象是天生的Monitor,每一个Java对象都有成为Monitor的潜质,因为在Java的设计中,每一个Java对象自打娘胎里出来就带了一把看不见的锁,它叫做内部锁或者Monitor锁。
每个对象都存在着一个Monitor与之关联,对象与其Monitor之间的关系有存在多种实现方式,如Monitor可以与对象一起创建销毁。
Moniter如何实现线程的同步?
在Java虚拟机(HotSpot)中,monitor是由ObjectMonitor实现的(位于HotSpot虚拟机源码ObjectMonitor.hpp文件,C++实现的)。
ObjectMonitor中有几个关键属性:
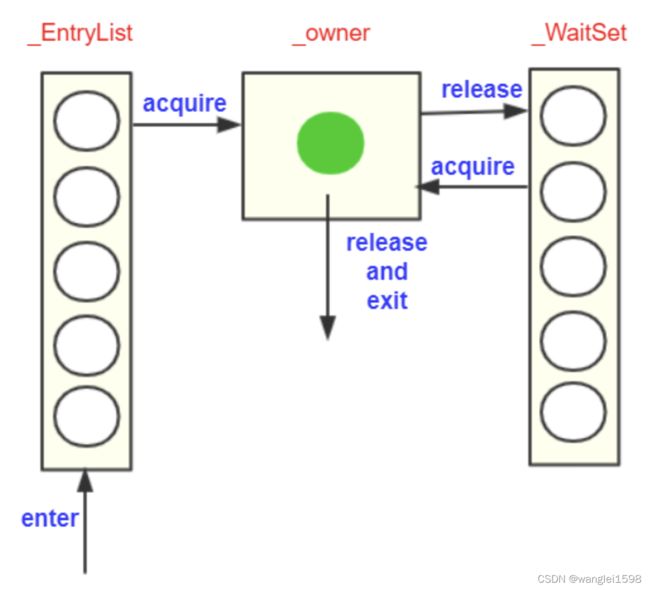
_owner:指向持有ObjectMonitor对象的线程
_WaitSet:存放处于wait状态的线程队列
_EntryList:存放处于等待锁block状态的线程队列
_recursions:锁的重入次数
_count:用来记录该线程获取锁的次数
-
线程T等待对象锁:_EntryList中加入T。
-
线程T获取对象锁:_EntryList移除T,_owner置为T,计数器_count加1。
-
线程T 中锁对象调用wait():_owner置为null,计数器_count减1,_WaitSet中加入T等待被唤醒。
-
持有对象锁的线程T执行完毕:复位变量的值,以便其他线程进入获取monitor。
Monitor从两个方面来支持线程之间的同步:
1、Java 使用对象锁 ( 使用 synchronized 获得对象锁 ) 保证工作在共享的数据集上的线程互斥执行。
2、使用 notify/notifyAll/wait 方法来协同不同线程之间的工作。
3、Class和Object都关联了一个Monitor。
Monitor 的工作机理
-
线程进入同步方法中。
-
为了继续执行临界区(critical section)代码,线程必须获取 Monitor 锁。如果获取锁成功,将成为该监视者对象的拥有者。任一时刻内,监视者对象只属于一个活动线程(The Owner)
-
拥有监视者对象的线程可以调用 wait() 进入等待集合(Wait Set),同时释放监视锁,进入等待状态。
-
其他线程调用 notify() / notifyAll() 接口唤醒等待集合中的线程,这些等待的线程需要 重新获取监视锁后 才能执行 wait() 之后的代码。
-
同步方法执行完毕了,线程退出临界区,并释放监视锁。
参考文档: https://www . ibm.com/developerworks/cn/java/j-lo-synchronized
可重入性
synchronized 的可重入性就是当一个线程已经持有锁对象的临界资源,当该线程再次请求对象的临界资源,可以请求成功,这种情况属于重入锁。
实现的底层原理就是 synchronized 底层维护一个 计数器 ,当线程获取该锁时,计数器 +1 ,再次获取锁时继续 +1 ,释放锁时,计数器-1,当计数器值为0时,表明该锁未被任何线程所持有,其它线程可以竞争获取锁。
synchronized关键字可以实现一个简单的策略来防止线程干扰和内存一致性错误,如果一个对象对多个线程是可见的,那么对该对象的所有读或者写都将通过同步的方式来进行,具体表现如下。
1.synchronized关键字提供了一种锁的机制,能够确保共享变量的互斥访问,从而防止数据不一致问题的出现。
2.synchronized关键字包括monitor enter和monitor exit两个JVM指令,它能够保证在任何时候任何线程执行到monitor enter成功之前都必须从主内存中获取数据,而不是从缓存中,在monitor exit运行成功之后,共享变量被更新后的值必须刷入主内存(在本书的第三部分会重点介绍)。
3.synchronized的指令严格遵守java happens-before规则,一个monitor exit指令之前必定要有一个monitor enter(在本书的第三部分会详细介绍)
Synchronize 解决的三大问题
保证原子性
在并发编程中的原子性:一段代码,或者一个变量的操作,在一个线程没有执行完之前,不能被其他线程执行。
synchronized修饰的代码在同一时间只能被一个线程访问,在锁未释放之前,无法被其他线程访问到。
即使在执行过程中,CPU时间片用完,线程放弃了CPU,但并没有进行解锁。而由于synchronized的锁是可重入的,下一个时间片还是只能被他自己获取到,还是会由同一个线程继续执行代码,直到所有代码执行完。从而保证synchronized修饰的代码块在同一时间只能被一个线程访问。
保证有序性
如果在本线程内观察,所有操作都是天然有序的。
——《深入理解Java虚拟机》
单线程重排序要遵守as-if-serial语义,不管怎么重排序,单线程程序的执行结果都不能被改变。因为不会改变执行结果,所以无须关心这种重排的干扰,可以认为单线程程序是按照顺序执行的。
synchronized修饰的代码,同一时间只能被同一线程访问。那么也就是单线程执行的。所以,可以保证其有序性。
保证可见性
加锁的含义不仅仅局限于互斥行为,还包括可见性。
——《Java并发编程实战》
JMM关于synchronized的两条语义规定保证了可见性: (对没有synchronized修饰的访问不生效)
synchronized锁优化
synchronized监视器锁在互斥同步上对性能的影响很大。
Java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统的帮忙,这就要从用户态转换到内核态,状态转换需要花费很多的处理器时间。
所以频繁的通过Synchronized实现同步会严重影响到程序效率,这种锁机制也被称为重量级锁,为了减少重量级锁带来的性能开销,JDK对Synchronized进行了种种优化。
偏向锁、轻量级锁、重量锁
HotSpot虚拟机中具体的锁实现
24张图带你彻底理解Java中的21种锁
看Java虚拟机JVM故障诊断与性能优化
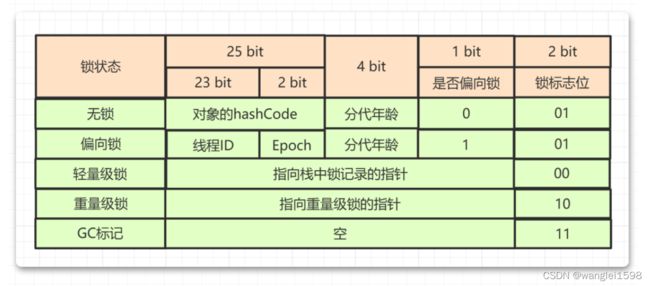
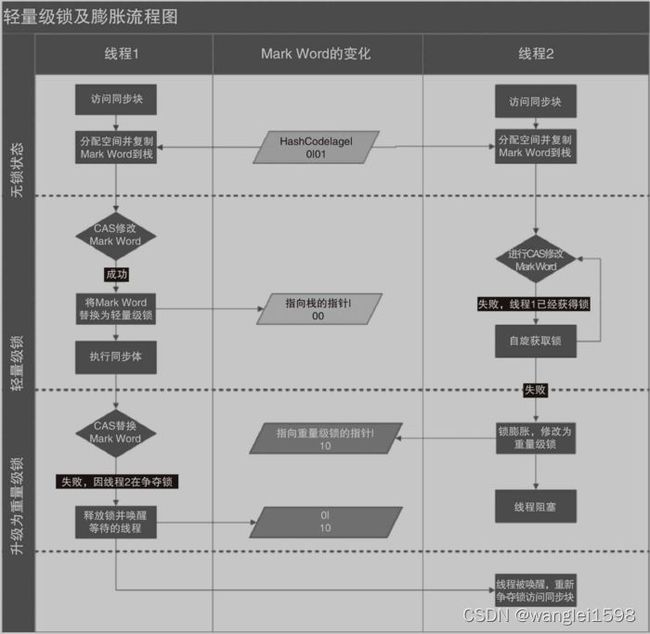
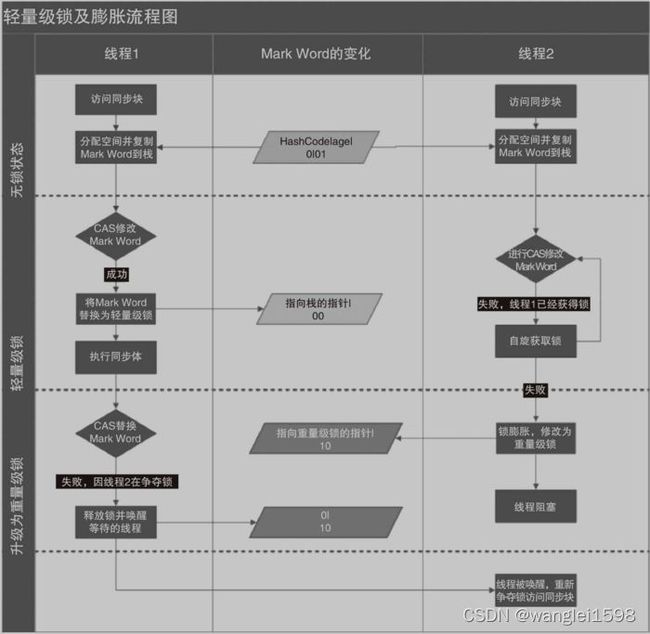
从Java对象头的Mark word中可以看到,synchronized锁一共具有四种状态:无锁、偏向锁、轻量级锁、重量级锁。
偏向锁、轻量级锁、重量级锁三种形式,分别对应了锁只被一个线程持有、不同线程交替持有锁、多线程竞争锁三种情况。
一、偏向锁
偏向锁背后的原理:如果一个线程最近用了某个锁,那么线程下一次执行由同一把锁保护的代码所需的数据可能仍然在处理器的缓存中。如果给这个线程优先获得这把锁的权利, 缓存命中率可能会更加。如果实现了这一点,性能会有所改进。但是因为偏向锁也需要一些薄记信息,故有时性能可能会更糟。
偏向锁认为环境中不存在竞争情况,锁只被一个线程持有, 一旦有不同的线程获取或竞争锁对象,偏向锁就升级为轻量级锁。
偏向锁在无多线程竞争的情况下可以减少不必须要的轻量级锁执行路径。
大多数情况,锁不仅不存在多线程竞争,而且总由同一线程多次获得。当一个线程访问同步块并获取锁时,会在 对象头和栈帧中记录存储锁偏向的线程ID,以后该线程在进入和退出同步块时 不需要进行 cas操作来加锁和解锁,只需测试一下对象头 Mark Word里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁,如果失败,则需要测试下Mark Word中偏向锁的标示是否已经设置成1(表示当前时偏向锁),如果没有设置,则使用cas竞争锁,如果设置了,则尝试使用cas将对象头的偏向锁只想当前线程。
关闭偏向锁延迟
java6和7中默认启用,但是会在程序启动几秒后才启用,如果需要关闭延迟,-XX:BiasedLockingStartupDelay=0,默认为4秒。
如何关闭偏向锁
偏向锁在锁竞争激烈的场合没有太强的优化效果,因为大量的竞争会导致持有锁的线程不停地切换,锁也很难一直保持在偏向模式,此时使用锁偏向不仅得不到性能优化,反而有可能降低系统西性能。因此在竞争激烈的场合,可以尝试使用-XX:-UseBiasedLocking参数禁用偏向锁。
偏向锁也是JDK 6中引入的一项锁优化措施,它的目的是消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能。如果说轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连CAS操作都不去做了。
偏向锁中的“偏”,就是偏心的“偏”、偏袒的“偏”。它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁一直没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。
如果读者理解了前面轻量级锁中关于对象头Mark Word与线程之间的操作过程,那偏向锁的原理就会很容易理解。假设当前虚拟机启用了偏向锁(启用参数-XX:+UseBiased Locking,这是自JDK 6起HotSpot虚拟机的默认值),那么当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位设置为“01”、把偏向模式设置为“1”,表示进入偏向模式。同时使用CAS操作把获取到这个锁的线程的ID记录在对象的Mark Word之中。如果CAS操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如加锁、解锁及对Mark Word的更新操作等)。
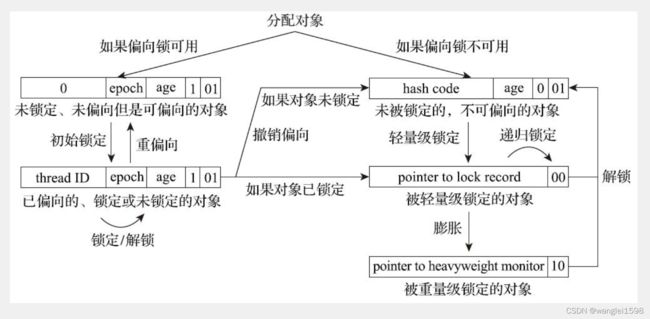
一旦出现另外一个线程去尝试获取这个锁的情况,偏向模式就马上宣告结束。根据锁对象目前是否处于被锁定的状态决定是否撤销偏向(偏向模式设置为“0”),撤销后标志位恢复到未锁定(标志位为“01”)或轻量级锁定(标志位为“00”)的状态,后续的同步操作就按照上面介绍的轻量级锁那样去执行。偏向锁、轻量级锁的状态转化及对象Mark Word的关系如图13-5所示。
细心的读者看到这里可能会发现一个问题:当对象进入偏向状态的时候,Mark Word大部分的空间(23个比特)都用于存储持有锁的线程ID了,这部分空间占用了原有存储对象哈希码的位置,那 原来对象的哈希码怎么办呢?
在Java语言里面一个对象如果计算过哈希码,就应该一直保持该值不变(强烈推荐但不强制,因为用户可以重载hashCode()方法按自己的意愿返回哈希码),否则很多依赖对象哈希码的API都可能存在出错风险。而作为绝大多数对象哈希码来源的Object::hashCode()方法,返回的是对象的一致性哈希码(Identity Hash Code),这个值是能强制保证不变的,它通过在对象头中存储计算结果来保证第一次计算之后,再次调用该方法取到的哈希码值永远不会再发生改变。因此, 当一个对象已经计算过一致性哈希码后,它就再也无法进入偏向锁状态了;而当一个对象当前正处于偏向锁状态,又收到需要计算其一致性哈希码请求时,它的偏向状态会被立即撤销,并且锁会膨胀为重量级锁。在重量级锁的实现中,对象头指向了重量级锁的位置,代表重量级锁的ObjectMonitor类里有字段可以记录非加锁状态(标志位为“01”)下的Mark Word,其中自然可以存储原来的哈希码。
偏向锁可以提高带有同步但无竞争的程序性能,但它同样是一个带有效益权衡(Trade Off)性质的优化,也就是说它并非总是对程序运行有利。如果程序中大多数的锁都总是被多个不同的线程访问,那偏向模式就是多余的。在具体问题具体分析的前提下,有时候使用参数-XX:-UseBiasedLocking来禁止偏向锁优化反而可以提升性能
二、轻量级锁(通过自旋实现)
轻量级锁是JDK 6时加入的新型锁机制,它名字中的“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的,因此传统的锁机制就被称为“重量级”锁。不过,需要强调一点,轻量级锁并不是用来代替重量级锁的,它设计的初衷是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
如果偏向锁失败,Java虚拟机会让线程申请轻量级锁。轻量级锁在虚拟机内部使用一个成为BasicObjectLock的对象实现(sa-jdi包),这个对象内部由一个BasicLock对象和一个持有该锁的Java对象指针组成。BasicObjectLock对象放置在Java栈的栈帧中。在BasicLock对象内部还维护者displace_header字段,它用于备份对象头不的Mark Word。
轻量级锁认为环境中线程几乎没有对锁对象的竞争,即使有竞争也只需要稍微等待( 自旋)下就可以获取锁,但是自旋次数有限制,如果超过该次数,则会升级为重量级锁。
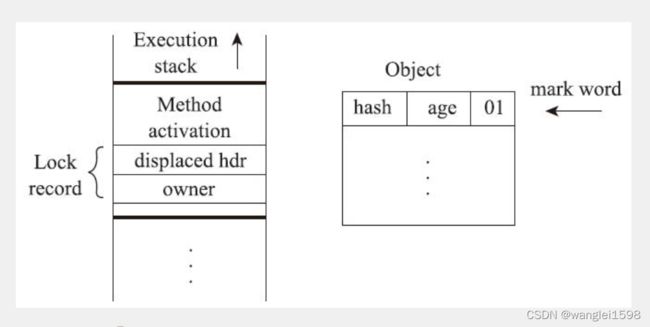
我们简单回顾了对象的内存布局后,接下来就可以介绍轻量级锁的工作过程了:在代码即将进入同步块的时候,如果此同步对象没有被锁定(锁标志位为“01”状态),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝(官方为这份拷贝加了一个Displaced前缀,即Displaced Mark Word),这时候线程堆栈与对象头的状态如图13-3所示
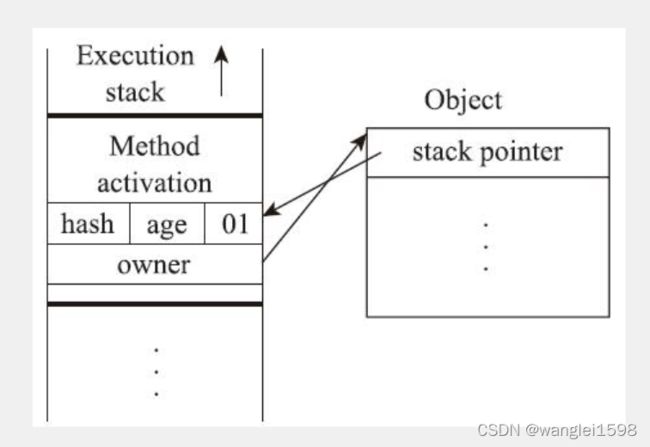
然后,虚拟机将使用CAS操作尝试把对象的Mark Word更新为指向Lock Record的指针。如果这个更新动作成功了,即代表该线程拥有了这个对象的锁,并且对象Mark Word的锁标志位(Mark Word的最后两个比特)将转变为“00”,表示此对象处于轻量级锁定状态。这时候线程堆栈与对象头的状态如图13-4所示。
如果这个更新操作失败了,那就意味着至少存在一条线程与当前线程竞争获取该对象的锁。虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是,说明当前线程已经拥有了这个对象的锁,那直接进入同步块继续执行就可以了,否则就说明这个锁对象已经被其他线程抢占了。如果出现两条以上的线程争用同一个锁的情况,那轻量级锁就不再有效,必须要膨胀为重量级锁,锁标志的状态值变为“10”,此时MarkWord中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也必须进入阻塞状态。
上面描述的是轻量级锁的加锁过程,它的解锁过程也同样是通过CAS操作来进行的,如果对象的Mark Word仍然指向线程的锁记录,那就用CAS操作把对象当前的Mark Word和线程中复制的DisplacedMark Word替换回来。假如能够成功替换,那整个同步过程就顺利完成了;如果替换失败,则说明有其他线程尝试过获取该锁,就要在释放锁的同时,唤醒被挂起的线程。
轻量级锁能提升程序同步性能的依据是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”这一经验法则。如果没有竞争,轻量级锁便通过CAS操作成功避免了使用互斥量的开销;但如果确实存在锁竞争,除了互斥量的本身开销外,还额外发生了CAS操作的开销。因此在有竞争的情况下,轻量级锁反而会比传统的重量级锁更慢。
三、重量级锁
轻量级锁失败,虚拟机就会使用重量级锁。
锁膨胀
synchronized锁膨胀过程就是无锁 → 偏向锁 → 轻量级锁 → 重量级锁的一个过程。这个过程是随着多线程对锁的竞争越来越激烈,锁逐渐升级膨胀的过程。
如下分析,从一个没有线程访问的锁逐渐升级到重量级锁的过程:
1)一个锁对象刚刚开始创建的时候,没有任何线程来访问它,此时线程状态为无锁状态。Mark word(锁标志位-01 是否偏向-0)
2)当线程A来访问这个对象锁时,它会偏向这个线程A。线程A检查Mark word(锁标志位-01 是否偏向-0)为无锁状态。此时, 有线程访问锁了,无锁升级为偏向锁 ,Mark word(锁标志位-01,是否偏向-1,线程ID-线程A的ID)
3)当线程A执行完同步块时,不会主动释放偏向锁。 持有偏向锁的线程执行完同步代码后不会主动释放偏向锁,而是等待其他线程来竞争才会释放锁。 Mark word不变(锁标志位-01,是否偏向-1,线程ID-线程A的ID)
4)当线程A再次获取这个对象锁时,检查Mark word(锁标志位-01,是否偏向-1,线程ID-线程A的ID),偏向锁且偏向线程A,可以直接执行同步代码。这样 偏向锁保证了总是同一个线程多次获取锁的情况下,每次只需要检查标志位就行,效率很高 。
5)当线程A执行完同步块之后,线程B获取这个对象锁 检查Mark word(锁标志位-01,是否偏向-1,线程ID-线程A的ID),偏向锁且偏向线程A。 有不同的线程获取锁对象,偏向锁升级为轻量级锁 ,并由线程B获取该锁。
6)当线程A正在执行同步块时,也就是正持有偏向锁时,线程B获取来这个对象锁。
检查Mark word(锁标志位-01,是否偏向-1,线程ID-线程A的ID),偏向锁且偏向线程A。
线程A撤销偏向锁 :
-
等到全局安全点执行撤销偏向锁,暂停持有偏向锁的线程A并检查程A的状态;
-
如果线程A不处于活动状态或者已经退出同步代码块,则将对象锁设置为无锁状态,然后再升级为轻量级锁。由线程B获取轻量级锁。
-
如果线程A还在执行同步代码块,也就是线程A还需要这个对象锁,则偏向锁膨胀为轻量级锁。
线程A膨胀为轻量级锁过程:
-
在升级为轻量级锁之前,持有偏向锁的线程(线程A)是暂停的
-
线程A栈帧中创建一个名为锁记录的空间(Lock Record)
-
锁对象头中的Mark Word拷贝到线程A的锁记录中
-
Mark Word的锁标志位变为00,指向锁记录的指针指向线程A的锁记录地址,Mark word(锁标志位-00,其他位-线程A锁记录的指针)
-
当原持有偏向锁的线程(线程A)获取轻量级锁后,JVM唤醒线程A,线程A执行同步代码块
7)线程A持有轻量级锁,线程A执行完同步块代码之后,一直没有线程来竞争对象锁,正常释放轻量级锁。 释放轻量级锁操作:CAS操作将线程A的锁记录(Lock Record)中的Mark Word替换回锁对象头中。
8)线程A持有轻量级锁,执行同步块代码过程中,线程B来竞争对象锁。
Mark word(锁标志位-00,其他位-线程A锁记录的指针)
-
线程B会先在栈帧中建立锁记录,存储锁对象目前的Mark Word的拷贝
-
线程B通过CAS操作尝试将锁对象的Mark Word的指针指向线程B的Lock Record,如果成功,说明线程A刚刚释放锁,线程B竞争到锁,则执行同步代码块。
-
因为线程A一直持有锁,大部分情况下CAS是会失败的。CAS失败之后,线程B尝试使用自旋的方式来等待持有轻量级锁的线程释放锁。
-
线程B不会一直自旋下去,如果自旋了一定次数后还是失败,线程B会被阻塞,等待释放锁后唤醒。此时轻量级锁就会膨胀为重量级锁。Mark word(锁标志位-10,其他位-重量级锁monitor的指针)
-
线程A执行完同步块代码之后,执行释放锁操作,CAS 操作将线程A的锁记录(Lock Record)中的Mark Word 替换回锁对象对象头中,因为对象头中已经不是原来的轻量级锁的指针了,而是重量级锁的指针,所以CAS操作会失败。
-
释放轻量级锁CAS操作替换失败之后,需要在释放锁的同时需要唤醒被挂起的线程B。线程B被唤醒,获取重量级锁monitor
自旋锁与适应自旋锁
大多数情况下,线程持有锁的时间都不会太长,为了这一段很短的时间频繁地阻塞和唤醒线程是非常不值得的。所以引入自旋锁。
1)自旋锁
当锁被占用时,当前想要获取锁的线程不会被立即挂起(为了防止膨胀为重量级锁而最后努力),而是做几个空循环,看持有锁的线程是否会很快释放锁。
在经过若干次循环后,如果得到锁,就顺利进入临界区;如果还不能获得锁,那就会将线程在操作系统层面挂起。
2)自旋锁和阻塞最大的区别
主要区别:是不是放弃处理器的执行时间。
阻塞放弃了CPU时间,进入了等待区,等待被唤醒。响应慢。自旋锁一直占用CPU时间,时刻检查共享资源是否可以被访问,所以 响应速度更快 。
3)缺点
如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好。但是如果持有锁的线程占用锁时间较长,等待锁的线程自旋一定次数后还是拿不到锁而被阻塞,那么自旋就白白浪费了CPU的资源。
4)自适应自旋锁
所谓自适应就意味着自旋的次数不再是固定的,它是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。
如果对于某个锁,很少有自旋能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
参数设置
JDK1.6中:
-XX:+UseSpinning参数来开启自旋锁。
-XX:PreBlockSpin参数来设置自旋锁的等待次数。
JDK1.7后的版本,自旋锁的参数被取消,虚拟机不再支持由用户配置自旋锁。自旋锁总是被执行,自旋次数也是由虚拟机自行调整。
锁消除
锁消除是Java虚拟机在JIT编译时,通过对运行上下文的扫描,去除不可能存在的共享资源竞争的锁。通过锁消除,可以节省毫无意义的请求时间。
开发人员使用StringBuffer Vector时,同步方法可以被优化掉。
在动态编译同步块的时候,JIT编译器可以借助一种被称为逃逸分析(Escape Analysis)的技术来判断同步块所使用的锁对象是否只能够被一个线程访问而没有被发布到其他线程。
如果同步块所使用的锁对象通过这种分析被证实只能够被一个线程访问,那么JIT编译器在编译这个同步块的时候就会取消对这部分代码的同步。
-XX:+DoEscapeAnalysis 开启逃逸分析
-XX:EliminateLocks 开启锁消除
锁粗化
很多时候,我们提倡尽量减小锁的粒度,可以避免不必要的阻塞。 让同步块的作用范围尽可能小,仅在共享数据的实际作用域中才进行同步,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。但是如果在一段代码中连续的用同一个监视器锁反复的加锁解锁,甚至加锁操作出现在循环体中的时候,就会导致不必要的性能损耗,这种情况就需要锁粗化。
虚拟机在遇到一连串连续地 对同一锁不断进行请求和释放对的操作时,变会把所有的锁操作整合成对锁的一次请求,从而减少对锁的请求同步次数,这个操作叫做锁粗化。
锁粗化就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。
syncronized 非公平锁 可重入锁
称为内部锁(instrinsic locks)或监视器锁(monitor locks)
是互斥锁(mutual exclusion lock,也称作mutex,至多只有一个线程可以拥有锁。
是可重入锁。
syncronized(obj){//代码块}. 如果其他线程没有加synchronize关键字访问次obj,不受任何锁限制。
Object类中的wait和notify函数使用
代码块中调用obj.wait() 释放锁。
调用obj.notify()随机唤醒一个线程.调用obj.notifyAll()唤醒所有线程(但还需要这些线程重新获取锁对象)。 https://mp.weixin.qq.com/s/dEhu1N4RbmVxnqVPQFWKNA
wait notify方法 必须在syncronized代码块里。否者抛出 IllegalMonitorStateException
(1)调用wait方法后,线程是会释放对monitor对象的所有权的。
(2)一个通过wait方法阻塞的线程,必须同时满足以下两个条件才能被真正执行:
Wait nofity 可以看看java并发编程实践第14章
可能存在 虚假唤醒
syncronized关键字作用: https://docs.oracle.com/javase/tutorial/essential/concurrency/syncmeth.html
-
First, it is not possible for two invocations of synchronized methods on the same object to interleave. When one thread is executing a synchronized method for an object, all other threads that invoke synchronized methods for the same object block (suspend execution) until the first thread is done with the object.
-
Second, when a synchronized method exits, it automatically establishes a happens-before relationship with any subsequent invocation of a synchronized method for the same object. This guarantees that changes to the state of the object are visible to all threads.
对象内部锁 https://docs.oracle.com/javase/tutorial/essential/concurrency/locksync.html
Java中的锁[原理、锁优化、CAS、AQS] - 简书
syncronized(obj) 可以拿到obj的对象内部锁,与obj内部的synchronized方法相互阻塞。
synchronized 还可以保证内存可见性,用到的变量直接读写主存。不需要volatile关键字。
见Java并发编程实践第3章。
原子性和可见性 JMM关于synchronized的两条规定:
2.2.3 synchronized的锁优化
JavaSE1.6为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”。
在JavaSE1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。
锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
偏向锁:无锁竞争的情况下为了减少锁竞争的资源开销,引入偏向锁。
轻量级锁: 轻量级锁所适应的场景是线程交替执行同步块的情况。
**锁粗化(Lock Coarsening):**也就是减少不必要的紧连在一起的unlock,lock操作,将多个连续的锁扩展成一个范围更大的锁。
**锁消除(Lock Elimination):**锁削除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行削除。
**适应性自旋(Adaptive Spinning):**自适应意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而它将允许自旋等待持续相对更长的时间,比如100个循环。另一方面,如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。
2.2.4 锁的优缺点对比
jvm锁 相关:
java 中的锁 -- 偏向锁、轻量级锁、自旋锁、重量级锁_朱清震的博客-CSDN博客_java偏向锁
有助于提高"锁"性能的几点建议 - 掘金
可重入锁(Reentrancy)与非可重入锁之间的区别:所谓重入锁,指的是以线程为单位,当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他的线程是不可以的。
HotSpot虚拟机中具体的锁实现
竞态条件(Race Condition):当多个线程同时访问同一个资源,其中的一个或者多个线程对这个资源进行了写操作,对资源的访问顺序敏感,就称存在竞态条件。多个线程同时读同一个资源不会产生竞态条件。
临界区:导致竞态条件发生的代码区称作临界区。在临界区中使用适当的同步就可以避免竞态条件
线程安全类: 当多个线程访问一个类时,如果不用考虑这些线程在运行时环境下的调度和交替执行,并且不需要额外的同步及在调用方式代码不必其他的协助,这个类的行为仍是正确的,那么称这个类是线程安全的。
基本上所有的并发模式在解决线程安全问题时,都采用“序列化访问临界资源”的方案,即在同一时刻,只能有一个线程访问临界资源,也称作同步互斥访问。通常来说,是在访问临界资源的代码前面加上一个锁,当访问完临界资源后释放锁,让其他线程继续访问。
在Java中,提供了两种方式来实现同步互斥访问:synchronized和Lock。
死锁:多个线程同时但以不同的顺序请求同一组锁的时候,线程之间互相循环等待锁导致线程一直阻塞。
如何避免死锁?
1)按顺序加锁
多个线程请求的一组锁按顺序加锁可以避免死锁。
死锁:如果线程1锁住了A,然后尝试对B进行加锁,同时线程2已经锁住了B,接着尝试对A进行加锁,发生死锁。
解决:规定锁A和锁B的顺序,某个线程需要同时获取锁A和锁B时,必须先拿锁A再拿锁B。线程1和线程2都先锁A再锁B,不会发生死锁。
问题:需要事先知道所有可能会用到的锁,并对这些锁做适当的排序。
2)加锁时限(超时重试机制)
设置一个超时时间,在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求,回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。
这段随机的等待时间让其它线程有机会尝试获取相同的这些锁,并且让该应用在没有获得锁的时候可以继续运行干点其它事情。
问题:
-
当线程很多时,等待的这一段随机的时间会一样长或者很接近,因此就算出现竞争而导致超时后,由于超时时间一样,它们又会同时开始重试,导致新一轮的竞争,带来了新的问题。
-
不能对synchronized同步块设置超时时间。需要创建一个自定义锁,或使用java.util.concurrent包下的工具。
3)死锁检测
主要是针对那些不可能实现按序加锁并且锁超时也不可行的情况。
每当一个线程获得了锁,会在线程和锁相关的数据结构中(比如map)将其记下。当一个线程请求锁失败时,这个线程可以遍历锁的关系图看看是否有死锁发生。
例如:线程1请求锁A,但是锁A这个时候被线程2持有,这时线程1就可以检查一下线程2是否已经请求了线程1当前所持有的锁。
如果线程2确实有这样的请求,那么就是发生了死锁(线程1拥有锁B,请求锁A;线程B拥有锁A,请求锁B)。
当检测出死锁时,可以有两种做法:
-
释放所有锁,回退,并且等待一段随机的时间后重试。(类似超时重试机制)
-
给这些线程设置优先级,让一个(或几个)线程回退,剩下的线程就像没发生死锁一样继续保持着它们需要的锁。
嵌套管程锁死。感觉管程就是monitor
举例:
线程1调用lock()方法,Lock对象锁和monitorObject锁,调用monitorObject.wait()阻塞,但仍然持有Lock对象锁。
线程2调用unlock()方法解锁时,无法获取Lock对象锁,因为线程1一直持有Lock锁,造成嵌套管程锁死。
重入锁死
如果一个线程持有某个对象上的锁,那么它就有权访问所有在该对象上同步的块,这就叫可重入。synchronized、ReentrantLock都是可重入锁。
如果一个线程持有锁A,锁A是不可重入的,该线程再次请求锁A时被阻塞,就是重入锁死。
重入锁死举例:
如果一个线程两次调用lock()间没有调用unlock()方法,那么第二次调用lock()就会被阻塞,这就出现了重入锁死。
饥饿与公平
如果一个线程因为CPU时间全部被其他线程抢走而得不到CPU运行时间,这种状态被称之为饥饿。
导致线程饥饿原因:
-
高优先级线程吞噬所有的低优先级线程的CPU时间。
-
线程始终竞争不到锁。
-
线程调用object.wait()后没有被唤醒。
解决饥饿的方案被称之为公平性,即所有线程均能公平地获得运行机会。
活跃度问题 是指线程或进程长时间得不到cpu占用。
活跃度失败:当一个活动进入某种它永远无法再继续执行的状态时,活跃度失败就发生了。
包括死锁、活锁、饥饿
活性失败(Liveness Failure): 多线性并发时,如果 A 线程修改了共享变量,此时 B 线程感知不到此共享变量的变化,叫做活性失败。
线程之活跃度失败(死锁、活锁、饥饿) - 简书
在JVM中到底可以创建多少个线程,与堆内存、栈内存的大小有着直接的关系,只不过栈内存更加明显一些,前文中我们说过在操作系统中一个进程的内存大小是有限制的,这个限制称为地址空间,比如32位的Windows操作系统最大的地址空间约为2G多一点,操作系统则会将进程内存的大小控制在最大地址空间以内,下面的公式是一个相对比较精准的计算线程数量的公式,其中ReservedOsMemory是系统保留内存,一般在136MB左右:
线程数量=(最大地址空间(MaxProcessMemory)-JVM堆内存-ReservedOsMemory)/ThreadStackSize(XSS)
当然线程数量还与操作系统的一些内核配置有很大的关系,比如在Linux下,下面三个内核配置信息也可以决定线程数量的大小。
·/proc/sys/kernel/threads-max
·/proc/sys/kernel/pid_max
·/proc/sys/vm/max_map_coun
线程状态
线程的创建方式
1.继承Thread类,实现public void run()方法 Thread (Java Platform SE 7 )
2.实现Runnable接口,将其作为参数构造Thread类,实现public void run()方法。 比继承Thread 更灵活。
3.实现Callable接口,实现T call() 方法(T为返回值类型)。将其作为参数构造FutureTask(实现Future接口)。
Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。
Future的不足之处
Future的不足之处包括如下几项内容。
▪ 无法被动接收异步任务的计算结果:
虽然我们可以主动将异步任务提交给线程池中的线程来执行,但是待异步任务结束后,主(当前)线程无法得到任务完成与否的通知(关于这一点,5.2.4节中将会给出解决方案),它需要通过get方法主动获取计算结果。
▪ Future间彼此孤立:
有时某一个耗时很长的异步任务执行结束以后,你还想利用它返回的结果再做进一步的运算,该运算也会是一个异步任务,两者之间的关系需要程序开发人员手动进行绑定赋予,Future并不能将其形成一个任务流(pipeline),每一个Future彼此之间都是孤立的,但5.5节将要介绍的CompletableFuture就可以将多个Future串联起来形成任务流(pipeline)。
▪ Future没有很好的错误处理机制:
截至目前,如果某个异步任务在执行的过程中发生了异常错误,调用者无法被动获知,必须通过捕获get方法的异常才能知道异步任务是否出现了错误,从而再做进一步的处理。
Google Guava的Future
Future虽然为我们提供了一个凭据,但是在未来某个时间节点进行get()操作时仍然会使当前线程进入阻塞,显然这种操作方式并不是十分完美,因此在Google Guava并发包中提供了对异步任务执行的回调支持,它允许你注册回调函数而不用再通过get()方法苦苦等待异步任务的最终计算结果(Don't Call Us, We'll Call You!)
FutureTask是Future接口的唯一子类。 用于异步获取执行结果或取消执行任务的场景。(实现基于AQS)
FutureTask代表了一个可被取消的异步计算任务,该类实现了Future接口,比如提供了启动和取消任务、查询任务是否完成、获取计算结果的接口。
FutureTask任务的结果只有当任务完成后才能获取,并且只能通过get系列方法获取,当结果还没出来时,线程调用get系列方法会被阻塞。另外,一旦任务被执行完成,任务将不能重启,除非运行时使用了runAndReset方法。FutureTask中的任务可以是Callable类型,也可以是Runnable类型(因为FutureTask实现了Runnable接口),FutureTask类型的任务可以被提交到线程池执行。
FutureTask的局限性
FutureTask虽然提供了用来检查任务是否执行完成、等待任务执行结果、获取任务执行结果的方法,但是这些特色并不足以让我们写出简洁的并发代码,比如它并不能清楚地表达多个FutureTask之间的关系。另外,为了从Future获取结果,我们必须调用get()方法,而该方法还是会在任务执行完毕前阻塞调用线程,这明显不是我们想要的。
我们真正想要的是:
·可以将两个或者多个异步计算结合在一起变成一个,这包含两个或者多个异步计算是相互独立的情况,也包含第二个异步计算依赖第一个异步计算结果的情况。
·对反应式编程的支持,也就是当任务计算完成后能进行通知,并且可以以计算结果作为一个行为动作的参数进行下一步计算,而不是仅仅提供调用线程以阻塞的方式获取计算结果。
·可以通过编程的方式手动设置(代码的方式)Future的结果;FutureTask不能实现让用户通过函数来设置其计算结果,而是在其任务内部来进行设置。
·可以等多个Future对应的计算结果都出来后做一些事情。
为了克服FutureTask的局限性,以及满足我们对异步编程的需要,JDK8中提供了CompletableFuture
CompletableFuture Java8 实现Future和 CompletionStage接口
看Java异步编程实战3.3
编程老司机带你玩转 CompletableFuture 异步编程
20个使用 Java CompletableFuture的例子
Future的缺陷
使用Future确实可以获取异步任务的执行结果,但是获取其结果还是会阻塞调用线程的,并没有实现完全异步化处理,所以在JDK8中提供了CompletableFuture来弥补其缺点。CompletableFuture类允许以非阻塞方式和基于通知的方式处理结果,其通过设置回调函数方式,让主线程彻底解放出来,实现了实际意义上的异步处理。
CompletableFuture是一个可以通过编程方式显式地设置计算结果和状态以便让任务结束的Future,并且其可以作为一个CompletionStage(计算阶段),当它的计算完成时可以触发一个函数或者行为;当多个线程企图调用同一个CompletableFuture的complete、cancel方式时只有一个线程会成功。
CompletableFuture除了含有可以直接操作任务状态和结果的方法外,还实现了CompletionStage接口的一些方法,这些方法遵循:
·当CompletableFuture任务完成后,同步使用任务执行线程来执行依赖任务结果的函数或者行为。
·所有异步的方法在没有显式指定Executor参数的情形下都是复用 ForkJoinPool.commonPool()线程池来执行。
·所有CompletionStage方法的实现都是相互独立的,以便一个方法的行为不会因为重载了其他方法而受影响。
一个CompletableFuture任务可能有一些依赖其计算结果的行为方法,这些行为方法被收集到一个无锁基于CAS操作来链接起来的链表组成的栈中;当Completable-Future的计算任务完成后,会自动弹出栈中的行为方法并执行。需要注意的是,由于是栈结构,在同一个CompletableFuture对象上行为注册的顺序与行为执行的顺序是相反的。
由于默认情况下支撑CompletableFuture异步运行的是ForkJoinPool,所以这里我们有必要简单讲解下ForkJoinPool。ForkJoinPool本身也是一种ExecutorService,与其他ExecutorService(比如ThreadPoolExecutor)相比,不同点是它使用了工作窃取算法来提高性能,其内部每个工作线程都关联自己的内存队列,正常情况下每个线程从自己队列里面获取任务并执行,当本身队列没有任务时,当前线程会去其他线程关联的队列里面获取任务来执行。这在很多任务会产生子任务或者有很多小的任务被提交到线程池来执行的情况下非常高效。
ForkJoinPool中有一个静态的线程池commonPool可用且适用大多数情况。commonPool会被任何未显式提交到指定线程池的ForkJoinTask执行使用。使用commonPool通常会减少资源使用(其线程数量会在不活跃时缓慢回收,并在任务数比较多的时候按需增加)。默认情况下,commonPool的参数可以通过system properties中的三个参数来控制:
· java.util.concurrent.ForkJoinPool.common.parallelism:并行度级别,非负整数。
· java.util.concurrent.ForkJoinPool.common.threadFactory:ForkJoinWorker ThreadFactory的类名。
· java.util.concurrent.ForkJoinPool.common.exceptionHandler:Uncaught ExceptionHandler的类名。
对于需要根据不同业务对线程池进行隔离或者定制的情况,可以使用ForkJoinPool的构造函数显式设置线程个数,默认情况下线程个数等于当前机器上可用的CPU个数。
ForkJoinPool中提供了任务执行、任务生命周期控制的方法,还提供了任务状态监测的方法,比如getStealCount可以帮助调整和监控fork/join应用程序。另外,toSring方法会非常方便地返回当前线程池的状态(运行状态、线程池线程个数、激活线程个数、队列中任务个数)。
另外,当线程池关闭或者内部资源被耗尽(比如当某个队列大小大于67108864时),再向线程池提交任务会抛出RejectedExecutionException异常。
CompletableFuture是自JDK1.8版本中引入的新的Future,常用于异步编程之中,所谓异步编程,简单来说就是:“程序运算与应用程序的主线程在不同的线程上完成,并且程序运算的线程能够向主线程通知其进度,以及成功失败与否的非阻塞式编码方式”,这句话听起来与前文中学习的ExecutorService提交异步执行任务并没有多大的区别,但是别忘了,无论是ExecutorService还是CompletionService,都需要主线程主动地获取异步任务执行的最终计算结果,如此看来,Google Guava所提供的ListenableFuture更符合这段话的描述,但是 ListenableFuture无法将计算的结果进行异步任务的级联并行运算,甚至构成一个异步任务并行运算的pipeline,但是这一切在CompletableFuture中都得到了很好的支持。
CompletableFuture实现自CompletionStage接口,可以简单地认为,该接口是同步或者异步任务完成的某个阶段,它可以是整个任务管道中的最后一个阶段,甚至可以是管道中的某一个阶段,这就意味着可以将多个CompletionStage链接在一起形成一个异步任务链,前置任务执行结束之后会自动触发下一个阶段任务的执行。另外,CompletableFuture还实现了Future接口,所以你可以像使用Future一样使用它。
CompletableFuture中包含了50多个方法,这一数字在JDK1.9版本中还得到了进一步的增加,这些方法可用于Future之间的组合、合并、任务的异步执行,多个Future的并行计算以及任务执行发生异常的错误处理等。
CompletableFuture的方法中,大多数入参都是函数式接口,比如Supplier、Function、BiFunction、Consumer等,因此熟练理解这些函数式接口是灵活使用CompletableFuture的前提和基础,同时CompletableFuture之所以能够异步执行任务,主要归功于其内部的ExecutorService,默认情况下为 ForkJoinPool.commonPool(),当然也允许开发者显式地指定
CompletableFuture的基本用法
不管怎么说,CompletableFuture首先是一个Future,因此你可以将它当作普通的Future来使用,这也没有什么不妥,比如我们在前文中学到,ExecutorService如果提交了Runnable类型的任务却又期望得到运算结果的返回,则需要在submit方法中将返回值的引用也作为参数传进去。笔者不是很喜欢这种API的设计方式,下面的代码将借助CompletableFuture来优雅地解决该问题。
任务的异步运行
当然,CompletableFuture除了具备Future的基本特性之外,还可以直接使用它执行异步任务,通常情况下,任务的类型为Supplier和Runnable,前者非常类似于Callable接口,可返回指定类型的运算结果,后者则仍旧只是关注异步任务运行本身。
异步任务链
CompletableFuture还允许将执行的异步任务结果继续交由下一级任务来执行,下一级任务还可以有下一级,以此类推,这样就可以形成一个异步任务链或者任务pipeline。
合并多个Future
CompletableFuture还允许将若干个Future合并成为一个Future的使用方式,可以通过thenCompose方法或者thenCombine方法来实现多个Future的合并。
多Future的并行计算
如果想要多个独立的CompletableFuture同时并行执行,那么我们还可以借助于allOf()方法来完成,其有点类似于ExecutorService的invokeAll批量提交异步任务。
如果只想运行一批Future中的一个任务,那么我们又该怎么办呢?只需要用anyOf方法替代allOf方法即可(这一点非常类似于ExecutorService的invokeAny方法),无论是allOf方法还是anyOf方法返回的CompletableFuture类型都是Void类型,如果你试图使用合并后的Future获取异步任务的计算结果,那么这将是不可能的,必须在每一个单独的Future链中增加上游任务结果的消费或下游处理任务才可以(详见5.5.3节“异步任务链”)
错误处理
CompletableFuture对于异常的处理方式比普通的Future要优雅合理很多,它提供了handle方法,可用于接受上游任务计算过程中出现的异常错误,这样一来,我们便可以不用将错误的处理逻辑写在try...catch...语句块中了,更不需要只能通过Future的get方法调用才能得知异常错误的发生。
JDK 9对CompletableFuture的进一步支持
在JDK 9中,Doug Lea继续操刀Java并发包的开发,为CompletableFuture带来了更多新的改变,比如增加了新的静态工厂方法、实例方法,提供了任务处理的延迟和超时支持等。已经在使用JDK1.9及其以上版本的读者可以快速体验。
▪ 新的实例方法
· Executor defaultExecutor()
· CompletableFuture newIncompleteFuture()
· CompletableFuture copy()
· CompletionStage minimalCompletionStage()
· CompletableFuture completeAsync(Supplier supplier, Executor executor)
· CompletableFuture completeAsync(Supplier supplier)
· CompletableFuture orTimeout(long timeout, TimeUnit unit)
· CompletableFuture completeOnTimeout(T value, long timeout, TimeUnit unit)
▪ 新的类方法
· Executor delayedExecutor(long delay, TimeUnit unit, Executor executor)
· Executor delayedExecutor(long delay, TimeUnit unit)
· CompletionStage completedStage(U value)
· CompletionStage failedStage(Throwable ex)
· CompletableFuture failedFuture(Throwable ex)
▪ 为了解决超时问题,Java 9还引入了另外两个新功能
· orTimeout()
· completeOnTimeout()
状态
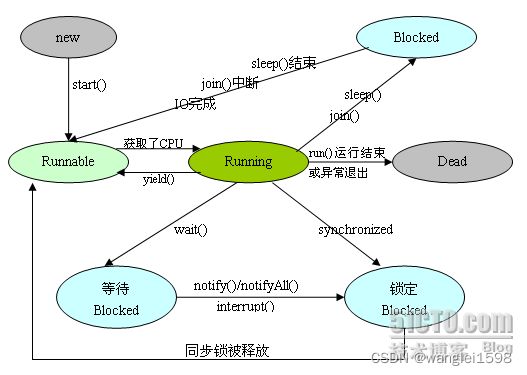
1. 新建状态(NEW)
当程序使用 new 关键字创建了一个线程之后,线程就处于新建状态,此时的线程情况如下:
-
此时 JVM 为其分配内存,并初始化其成员变量的值;
-
此时线程对象没有表现出任何线程的动态特征,程序也不会执行线程的线程执行体;
2. 就绪状态(RUNNABLE)
当线程对象调用了 start()方法之后,线程处于就绪状态。此时的线程情况如下:
-
此时 JVM 会为其创建方法调用栈和程序计数器;
-
线程并没有开始运行,而是等待系统为其分配 CPU 时间片;
3. 运行状态(RUNNING)
当线程获得了 CPU 时间片,CPU 调度处于就绪状态的线程并执行 run()方法的线程执行体,则该线程处于运行状态。
如果计算机只有一个CPU,那么在任何时刻只有一个线程处于运行状态;
如果在一个多处理器的机器上,将会有多个线程并行执行,处于运行状态;
当线程数大于处理器数时,依然会存在多个线程在同一个CPU上轮换的现象;
对于采用抢占式策略的系统而言,系统会给每个可执行的线程分配一个时间片来处理任务;当该时间片用完后,系统就会剥夺该线程所占用的资源,让其他线程获得执行的机会。此时线程就会又从运行状态变为就绪状态,重新等待系统分配资源。
4. 阻塞状态(BLOCKED)
处于运行状态的线程在某些情况下,让出 CPU 并暂时停止自己的运行,进入阻塞状态。如:线程阻塞于 synchronized 锁。
5. 等待状态(WAITING)
线程处于无限制等待状态,等待一个特殊的事件来重新唤醒,唤醒线程之后进入就绪状态,如:
通过wait()方法进行等待的线程等待一个notify()或者notifyAll()方法;
通过join()方法进行等待的线程等待目标线程运行结束而唤醒;
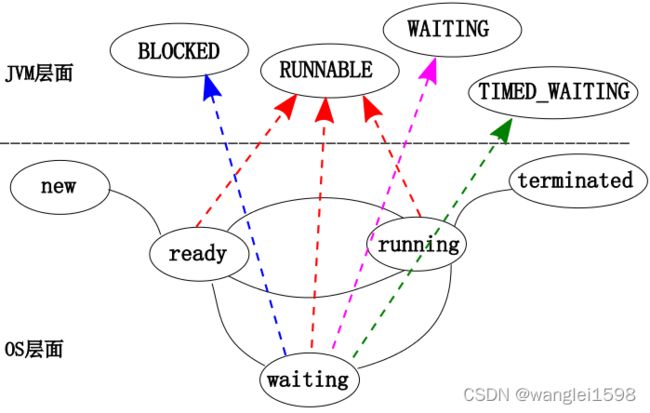
阻塞在 java.concurrent 包中 Lock 接口的线程状态不是 BLOCK 状态,而是 WAITING 等待状态,因为 java.concurrent 包中 Lock 接口对于阻塞的实现均使用了 LockSupport 类中的相关方法。
6. 超时等待状态(TIMED_WAITING)
线程进入了一个时限等待状态,如:sleep(3000),等待 3 秒后线程重新进入就绪状态。
7. 死亡状态(DEAD)
线程会以如下 3 种方式结束,结束后就处于死亡状态:
① run()或 call()方法执行完成,线程正常结束;
② 线程抛出一个未捕获的 Exception 或 Error;
③ 直接调用该线程 stop()方法来结束该线程—该方法容易导致死锁,通常不推荐使用;
线程的状态图
jstack 线程状态:Thread类的getState方法返回Thread.Stat枚举.
Thread.State (Java Platform SE 8 ) API文档介绍的很清楚
1. NEW 状态是指线程刚创建, 尚未启动
2. RUNNABLE 状态是线程正在正常运行中, 当然可能会有某种耗时计算/IO等待的操作/CPU时间片切换等, 这个状态下发生的等待一般是其他系统资源, 而不是锁, Sleep等
3. BLOCKED 这个状态下, 是在多个线程有同步操作的场景, 比如正在等待另一个线程的synchronized 块的执行释放, 也就是这里是线程在等待进入临界区
4. WAITING 这个状态下是指线程拥有了某个锁之后, 调用了他的wait方法, 等待其他线程/锁拥有者调用 notify / notifyAll 一遍该线程可以继续下一步操作, 这里要区分 BLOCKED 和 WATING 的区别, 一个是在临界点外面等待进入, 一个是在理解点里面wait等待别人notify, 线程调用了join方法 join了另外的线程的时候, 也会进入WAITING状态, 等待被他join的线程执行结束
5. TIMED_WAITING 这个状态就是有限的(时间限制)的WAITING, 一般出现在调用wait(long), join(long)等情况下, 另外一个线程sleep后, 也会进入TIMED_WAITING状态
6. TERMINATED 这个状态下表示 该线程的run方法已经执行完毕了, 基本上就等于死亡了(当时如果线程被持久持有, 可能不会被回收)
线程状态转换:
RUNNABLE与BLOCKED的状态转换
只有一种场景会触发这种转换,就是线程等待synchronized隐式锁。synchronized修饰的方法、代码块同一时刻只允许一个线程执行,其他的线程则需要等待。此时,等待的线程就会从RUNNABLE状态转换到BLOCKED状态。当等待的线程获得synchronized隐式锁时,就又会从BLOCKED状态转换到RUNNABLE状态。
这里,需要大家注意:线程调用阻塞API时,在操作系统层面,线程会转换到休眠状态。但是在JVM中,Java线程的状态不会发生变化,也就是说,Java线程的状态仍然是RUNNABLE状态。JVM并不关心操作系统调度相关的状态,在JVM角度来看,等待CPU使用权(操作系统中的线程处于可执行状态)和等待IO操作(操作系统中的线程处于休眠状态)没有区别,都是在等待某个资源,所以,将其都归入了RUNNABLE状态。
我们平时所说的Java在调用阻塞API时,线程会阻塞,指的是操作系统线程的状态,并不是Java线程的状态。
RUNNABLE与WAITING状态转换
线程从RUNNABLE状态转换成WAITING状态总体上有三种场景。
场景一
获得synchronized隐式锁的线程,调用无参的Object.wait()方法。此时的线程会从RUNNABLE状态转换成WAITING状态。
场景二
调用无参数的Thread.join()方法。其中join()方法是一种线程的同步方法。例如,在threadA线程中调用threadB线程的join()方法,则threadA线程会等待threadB线程执行完。而threadA线程在等待threadB线程执行的过程中,其状态会从RUNNABLE转换到WAITING。当threadB执行完毕,threadA线程的状态则会从WAITING状态转换成RUNNABLE状态。
场景三
调用LockSupport.park()方法,当前线程会阻塞,线程的状态会从RUNNABLE转换成WAITING。调用LockSupport.unpark(Thread thread)可唤醒目标线程,目标线程的状态又会从WAITING状态转换到RUNNABLE。
RUNNABLE与TIMED_WAITING状态转换
总体上可以分为五种场景。
场景一
调用带超时参数的Thread.sleep(long millis)方法;
场景二
获得synchronized隐式锁的线程,调用带超时参数的Object.wait(long timeout)参数;
场景三
调用带超时参数的Thread.join(long millis)方法;
场景四
调用带超时参数的LockSupport.parkNanos(Object blocker, long deadline)方法;
场景五
调用带超时参数的LockSuppor.parkUntil(long deadline)方法。
从NEW到RUNNABLE状态
Java刚创建出来的Thread对象就是NEW状态,创建Thread对象主要有两种方法,一种是继承Thread对象,重写run()方法;另一种是实现Runnable接口,重写run()方法。
注意:这里说的是创建Thread对象的方法,而不是创建线程的方法,创建线程的方法包含创建Thread对象的方法。
继承Thread对象
public class ChildThread extends Thread {
@Override
public void run () {
//线程中需要执行的逻辑
}
}
//创建线程对象
ChildThread childThread = new ChildThread();
实现Runnable接口
public class ChildRunnable implements Runnable {
@Override
public void run () {
//线程中需要执行的逻辑
}
}
//创建线程对象
Thread childThread = new Thread( new ChildRunnable());
处于NEW状态的线程不会被操作系统调度,因此也就不会执行。Java中的线程要执行,就需要转换到RUNNABLE状态。从NEW状态转换到RUNNABLE状态,只需要调用线程对象的start()方法即可。
//创建线程对象
Thread childThread = new Thread( new ChildRunnable());
//调用start()方法使线程从NEW状态转换到RUNNABLE状态
childThread.start();
RUNNABLE到TERMINATED状态
线程执行完run()方法后,或者执行run()方法的时候抛出异常,都会终止,此时为TERMINATED状态。如果我们需要中断run()方法,可以调用interrupt()方法。
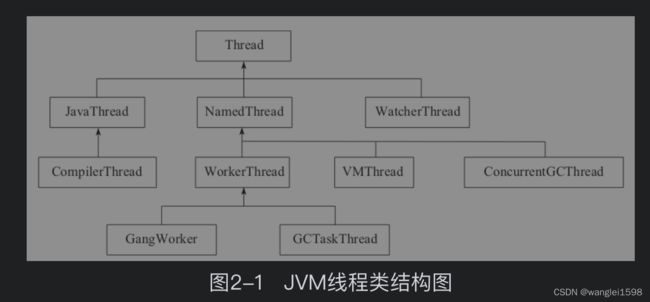
这里只介绍G1中涉及的几类线程:·JavaThread:就是要执行Java代码的线程,比如Java代码的启动会创建一个JavaThread运行;对于Java代码的启动,可以通过JNI_CreateJavaVM[插图]来创建一个JavaThread,而对于一般的Java线程,都是调用java.lang.thread中的start方法,这个方法通过JNI调用创建JavaThread对象,完成真正的线程创建。
·CompilerThread:执行JIT的线程。
·WatcherThread:执行周期性任务,JVM里面有很多周期性任务,例如内存管理中对小对象使用了ChunkPool,而这种管理需要周期性的清理动作ChunkPoolCleaner;JVM中内存抽样任务MemProfilerTask等都是周期性任务。
·NameThread:是JVM内部使用的线程,分类如图2-1所示。
·VMThread:JVM执行GC的同步线程,这个是JVM最关键的线程之一,主要是用于处理垃圾回收。简单地说,所有的垃圾回收操作都是从VMThread触发的,如果是多线程回收,则启动多个线程,如果是单线程回收,则使用VMThread进行。VMThread提供了一个队列,任何要执行GC的操作都实现了VM_GC_Operation,在JavaThread中执行VMThread::execute(VM_GC_Operation)把GC操作放入到队列中,然后再用VMThread的run方法轮询这个队列就可以了。当这个队列有内容的时候它就开始尝试进入安全点,然后执行相应的GC任务,完成GC任务后会退出安全点。
·ConcurrentGCThread:并发执行GC任务的线程,比如G1中的ConcurrentMarkThread和ConcurrentG1RefineThread,分别处理并发标记和并发Refine,这两个线程将在混合垃圾收集和新生代垃圾回收中介绍。
·WorkerThread:工作线程,在G1中使用了FlexibleWorkGang,这个线程是并行执行的(个数一般和CPU个数相关),所以可以认为这是一个线程池。线程池里面的线程是为了执行任务(在G1中是G1ParTask),也就是做GC工作的地方。VMThread会触发这些任务的调度执行(其实是把G1ParTask放入到这些工作线程中,然后由工作线程进行调度)。
线程的实现
我们知道,线程是比进程更轻量级的调度执行单位,线程的引入,可以把一个进程的资源分配和执行调度分开,各个线程既可以共享进程资源(内存地址、文件I/O等),又可以独立调度。目前线程是Java里面进行处理器资源调度的最基本单位,不过如果日后Loom项目能成功为Java引入纤程(Fiber)的话,可能就会改变这一点。
主流的操作系统都提供了线程实现,Java语言则提供了在不同硬件和操作系统平台下对线程操作的统一处理,每个已经调用过start()方法且还未结束的java.lang.Thread类的实例就代表着一个线程。我们注意到Thread类与大部分的Java类库API有着显著差别,它的所有关键方法都被声明为Native。在Java类库API中,一个Native方法往往就意味着这个方法没有使用或无法使用平台无关的手段来实现(当然也可能是为了执行效率而使用Native方法,不过通常最高效率的手段也就是平台相关的手段)。正因为这个原因,本节的标题被定为“线程的实现”而不是“Java线程的实现”,在稍后介绍的实现方式中,我们也先把Java的技术背景放下,以一个通用的应用程序的角度来看看线程是如何实现的。
实现线程主要有三种方式:使用内核线程实现(1:1实现),使用用户线程实现(1:N实现),使用用户线程加轻量级进程混合实现(N:M实现)。
1.内核线程实现
使用内核线程实现的方式也被称为1:1实现。 内核线程(Kernel-Level Thread,KLT)就是直接由操作系统内核(Kernel,下称内核)支持的线程,这种线程由内核来完成线程切换,内核通过操纵调度器(Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就称为多线程内核(Multi-Threads Kernel)。
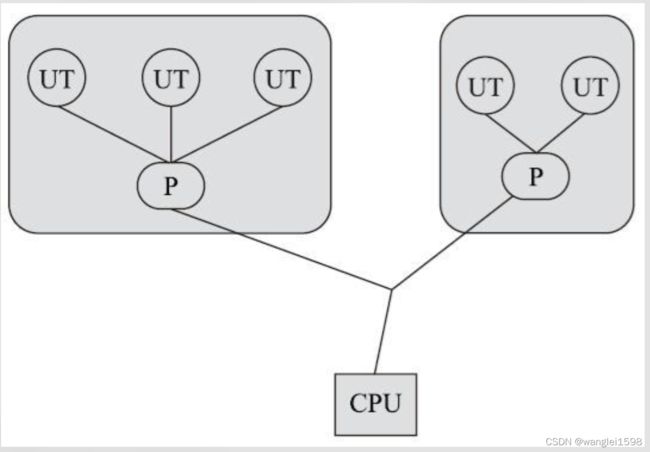
程序一般不会直接使用内核线程,而是使用内核线程的一种高级接口—— 轻量级进程(Light Weight Process,LWP),轻量级进程就是我们通常意义上所讲的线程,由于每个轻量级进程都由一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。这种轻量级进程与内核线程之间1:1的关系称为一对一的线程模型,如图12-3所示。
由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使其中某一个轻量级进程在系统调用中被阻塞了,也不会影响整个进程继续工作。轻量级进程也具有它的局限性:首先,由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。其次,每个轻量级进程都需要有一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。
2.用户线程实现
使用用户线程实现的方式被称为1:N实现。广义上来讲,一个线程只要不是内核线程,都可以认为是用户线程(User Thread,UT)的一种,因此从这个定义上看,轻量级进程也属于用户线程,但轻量级进程的实现始终是建立在内核之上的,许多操作都要进行系统调用,因此效率会受到限制,并不具备通常意义上的用户线程的优点。
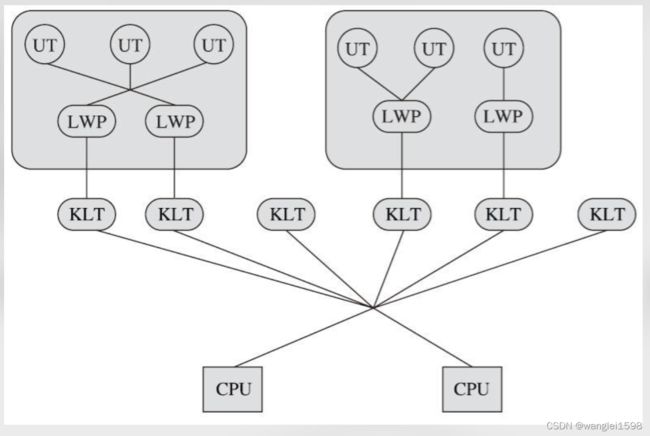
而狭义上的用户线程指的是完全建立在用户空间的线程库上,系统内核不能感知到用户线程的存在及如何实现的。用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助。如果程序实现得当,这种线程不需要切换到内核态,因此操作可以是非常快速且低消耗的,也能够支持规模更大的线程数量,部分高性能数据库中的多线程就是由用户线程实现的。这种进程与用户线程之间1:N的关系称为一对多的线程模型,如图12-4所示。
用户线程的优势在于不需要系统内核支援,劣势也在于没有系统内核的支援,所有的线程操作都需要由用户程序自己去处理。线程的创建、销毁、切换和调度都是用户必须考虑的问题,而且由于操作系统只把处理器资源分配到进程,那诸如“阻塞如何处理”“多处理器系统中如何将线程映射到其他处理器上”这类问题解决起来将会异常困难,甚至有些是不可能实现的。因为使用用户线程实现的程序通常都比较复杂,除了有明确的需求外(譬如以前在不支持多线程的操作系统中的多线程程序、需要支持大规模线程数量的应用),一般的应用程序都不倾向使用用户线程。Java、Ruby等语言都曾经使用过用户线程,最终又都放弃了使用它。但是近年来许多新的、以高并发为卖点的编程语言又普遍支持了用户线程,譬如Golang、Erlang等,使得用户线程的使用率有所回升.
3.混合实现
线程除了依赖内核线程实现和完全由用户程序自己实现之外,还有一种将内核线程与用户线程一起使用的实现方式,被称为N:M实现。在这种混合实现下,既存在用户线程,也存在轻量级进程。用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、析构等操作依然廉价,并且可以支持大规模的用户线程并发。而操作系统支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程调度功能及处理器映射,并且用户线程的系统调用要通过轻量级进程来完成,这大大降低了整个进程被完全阻塞的风险。在这种混合模式中,用户线程与轻量级进程的数量比是不定的,是N:M的关系,如图12-5所示,这种就是多对多的线程模型。
线程调度
优先级
优先级相关内容 可以看看 Java线程 第六章
优先级有多大效果,要看JVM实现和平台
每个线程执行时都有一个优先级的属性,优先级高的线程可以获得较多的执行机会,而优先级低的线程则获得较少的执行机会。
操作系统采用时分的形式调度运行的线程,操作系统会分出一个个时间片,线程会分配到若干时间片,当线程的时间片用完了就会发生线程调度,并等待着下次分配。线程分配到的时间片多少也就决定了线程使用处理器资源的多少,而线程优先级就是决定线程需要多或者少分配一些处理器资源的线程属性。
Thread 类通过一个整型成员变量 priority 来控制优先级,优先级的范围从 1 ~ 10,默认优先级是 5。
虽然 Java 提供了 10 个优先级别,但这些优先级别需要操作系统的支持,所以需要注意:
-
操作系统的优先级可能不能很好的和 Java 的 10 个优先级别对应,所以最好使用 MAX_PRIORITY、MIN_PRIORITY 和 NORM_PRIORITY 三个静态常量来设定优先级,以保证程序更好的可移植性。
-
线程优先级不能作为程序正确性的依赖,因为操作系统可以完全不用理会 Java 线程对于优先级的设定。
daemon线程
Daemon 线程是一种支持型线程,在后台守护一些系统服务,比如 JVM 的垃圾回收、内存管理等线程都是守护线程。
与之对应的就是用户线程,用户线程就是系统的工作线程,它会完成整个系统的业务操作。
用户线程结束后就意味着整个系统的任务全部结束了,因此系统就没有对象需要守护的了,守护线程自然而然就会退出。所以 当一个 Java 应用只有守护线程的时候,虚拟机就会自然退出 。
Thread 类 boolean 类型的 daemon 属性标志守护线程,通过 setDaemon(boolean on)方法设置守护线程。
守护线程退出时,线程中的finally块并不会执行。
jvm的垃圾回收线程就是守护线程
默认会出现的守护进程有:服务守护进程、编译守护进程、windows下监听Ctrl break的守护进程,Finalizer守护进程,引用处理守护进程、GC守护进程
当线程只剩下守护线程的时候,JVM就会退出.但是如果还有其他的任意一个用户线程还在,JVM就不会退出.
前台线程创建的线程默认是前台线程。后台线程创建的线程默认是后台线程。
中断
中断代表线程状态,每个线程都关联了一个中断状态,用 boolean 值表示,初始值为 false。中断一个线程,其实就是设置了这个线程的中断状态 boolean 值为 true。
注意区分字面意思,中断只是一个状态,处于中断状态的线程不一定要停止运行。
Thread 类线程中断的方法:
自动感知中断
以下方法会自动感知中断:
Object 类的 wait()、wait(long)、wait(long, int)
Thread 类的 join()、join(long)、join(long, int)、sleep(long)、sleep(long, int)
当一个线程处于 sleep、wait、join 这三种状态之一时,如果此时线程中断状态为 true,那么就会抛出一个 InterruptedException 的异常,并将中断状态重新设置为 false。
中断相关内容 可以看看Java并发编程实践第7章
InterruptedException
InterruptedException的解读 - neverend的日志 - BlogJava
Java正确处理InterruptedException的方法_Randy的博客-CSDN博客_interruptedexception
IBM Developer
Thrown when a thread is waiting, sleeping, or otherwise occupied, and the thread is interrupted, either before or during the activity. Occasionally a method may wish to test whether the current thread has been interrupted, and if so, to immediately throw this exception.
意思是说当一个线程处于等待,睡眠,或者占用,也就是说阻塞状态,而这时线程被中断就会抛出这类错误。Java6之后结束某个线程A的方法是A.interrupt()。如果这个线程正处于非阻塞状态,比如说线程正在执行某些代码的时候,不过被interrupt,那么该线程的interrupt变量会被置为true,告诉别人说这个线程被中断了(只是一个标志位,这个变量本身并不影响线程的中断与否),而且线程会被中断,这时不会有interruptedException。但如果这时线程被阻塞了,比如说正在睡眠,那么就会抛出这个错误。请注意,这个时候变量interrupt没有被置为true,而且也没有人来中断这个线程。
当一个方法能够抛出InterruptedException的时候,是告诉你这个方法是一个可阻塞的方法,进一步看,如果它被中断,则可以提前结束阻塞状态。
中断变量
每个线程都会维护一个bool变量,表示线程处于中断(true)或者非中断状态(false)。在线程初始的情况下中断变量为false。
这个变量的bool值可以通过Thread.isInterrupted()方法来读取,通过Thread.interrupted()方法来清除中断(即将中断变量置为false)。
线程中断
一个线程可以通过调用Thread#interrupt()方法来中断另外一个线程,具体过程如下:
1. 中断变量被设置为true。
2. 如果线程执行到了阻塞方法,那么该方法取消阻塞,并将中断变量重新置为false。
boolean Thread.interrupted()(Thread类的静态方法)
它仅能够清除当前线程的中断状态,并返回它之前的值;这是清除中断状态的唯一方法。
测试当前线程是否已经中断。线程的中断状态 由该方法清除。换句话说,如果连续两次调用该方法,则第二次调用将返回 false(在第一次调用已清除了其中断状态之后,且第二次调用检验完中断状态前,当前线程再次中断的情况除外)。
线程中断被忽略,因为在中断时不处于活动状态的线程将由此返回 false 的方法反映出来。
返回:
如果当前线程已经中断,则返回 true;否则返回 false。
另请参见:
isInterrupted()
void Thread#interrupt()(Thread类的非静态方法)
不会中断一个正常运行的线程。他的作用是使阻塞线程抛出一个异常,捕获该异常,结束阻塞状态。 https://docs.oracle.com/javase/tutorial/essential/concurrency/interrupt.html
中断线程。
如果当前线程没有中断它自己(这在任何情况下都是允许的),则该线程的 checkAccess 方法就会被调用,这可能抛出 SecurityException。
如果线程在调用 Object 类的 wait()、 wait(long) 或 wait(long, int) 方法,或者该类的 join()、 join(long)、 join(long, int)、 sleep(long) 或 sleep(long, int) 方法过程中受阻,则其中断状态将被清除,它还将收到一个 InterruptedException。
如果该线程在 可中断的通道上的 I/O 操作中受阻,则该通道将被关闭,该线程的中断状态将被设置并且该线程将收到一个 ClosedByInterruptException。
如果该线程在一个 Selector 中受阻,则该线程的中断状态将被设置,它将立即从选择操作返回,并可能带有一个非零值,就好像调用了选择器的 wakeup 方法一样。
如果以前的条件都没有保存,则该线程的中断状态将被设置。
中断一个不处于活动状态的线程不需要任何作用。
抛出:
SecurityException - 如果当前线程无法修改该线程
中断是一种协作机制。一个线程不能迫使其他线程停止正在做的事情,或者去做其他事情;当线程A中断B时,A仅仅是要求B在达成某个方便停止的关键点时,停止正在做的事情——如果他这样做是正确的。
每一个线程都有一个boolean类型的中断状态;在中断的时候这个状态被设置为true
阻塞函数库,比如:Thread.sleep和Object.wait,试图监控线程何时被中断,并提前返回。它们对中断的响应表现为:清楚中断状态,抛出InterruptedExcetion;这表示阻塞操作因为中断的缘故提前结束。JVM并没有阻塞方法发现中断的速度做出保证,不过现实中这样的响应速度还是比较迅速的。
调用interrupt并不意味着必须停止目标线程正在进行的工作;它仅仅传递了请求中断的信息。
我们对中断本身最好的理解是应该是:他并不会真正中断一个正在运行的线程;它发出中断请求,线程自己会在下一个方便的时刻中断(这些时刻被称为取消点)。有一些方法对这样的请求很重视,比如wait、sleep和join方法,当它们接到中断请求时会抛出一个异常,或者进入时中断状态就已经被设置了。
join方法
join某个线程A,会使当前线程B进入等待,直到线程A结束生命周期,或者到达给定的时间,那么在此期间B线程是处于BLOCKED的,
Thread#join throws InterruptException。当前线程等待该线程执行完毕。前当前线程将处于阻塞状态 join(),join(long millis),join(long millis,int nanos) However, as with sleep , join is dependent on the OS for timing, so you should not assume that join will wait exactly as long as you specify.
Thread 类中的三个 join 方法:
// 当前线程加入该线程后面,等待该线程终止。
void join()
// 当前线程等待该线程终止的时间最长为 millis 毫秒。如果在millis时间内,该线程没有执行完,那么当前线程进入就绪状态,重新等待cpu调度
void join(long millis)
// 等待该线程终止的时间最长为 millis 毫秒 + nanos 纳秒。如果在millis时间内,该线程没有执行完,那么当前线程进入就绪状态,重新等待cpu调度
void join(long millis,int nanos)
join是指把指定的线程加入到当前线程,比如join某个线程a,会让当前线程b进入等待,直到a的生命周期结束,此期间b线程是处于blocked状态。
Sleep方法
sleep 方法是 Thread 的静态方法,sleep 让线程进入到阻塞状态,交出 CPU,让 CPU 去执行其他的任务。
sleep 方法不会释放锁。
yield方法 任何重要的调度都不应该依赖于yield。它只是一种暗示,没有任何机制保证它将会被采纳(取决于平台和JVM实现)。
yield 方法是 Thread 的静态方法,yield 方法让当前正在执行的线程进入到就绪状态,让出 CPU 资源给其他的线程。
注意:
yield 方法只是让当前线程暂停一下,重新进入就绪线程池中,让系统的线程调度器重新调度器重新调度一次,完全可能出现这样的情况:当某个线程调用 yield()方法之后,线程调度器又将其调度出来重新进入到运行状态执行。
wait notify notifyAll 方法
先来复习一下 synchronized 监视器锁 monitor 的实现原理。
Monitor 中有几个关键属性:
_owner:指向持有ObjectMonitor对象的线程
_WaitSet:存放处于wait状态的线程队列
_EntryList:存放处于等待锁block状态的线程队列
_recursions:锁的重入次数
_count:用来记录该线程获取锁的次数
同步队列(锁池/_EntryList):由于线程没有竞争到锁,只能等待锁释放之后再去竞争,此时线程就处于该对象的同步队列(锁池)中,线程状态为 BLOCKED。
等待队列(等待池/_WaitSet):线程调用了 wait 方法后被挂起,等待 notify 唤醒或者挂起时间到自动唤醒,此时线程就处于该对象的等待队列(等待池)中,线程状态为 WAITING 或者 TIMED_WAITING。
wait 方法:释放持有的对象锁,线程状态由 RUNNING 变为 WAITING,并将当前线程放置到对象的等待队列;
notify 方法:在目标对象的等待集合中随意选择一个线程 T,将线程 T 从等待队列移到同步队列重新竞争锁,线程状态由 WAITING 变为 BLOCKED。
notifyAll 方法:notifyAll 方法与 notify 方法的运行机制是一样的,只是将等待队列中所有的线程全部移到同步队列。
设置线程上下文类加载器 看Java高并发编程详解:多线程和架构设计
·public ClassLoader getContextClassLoader()获取线程上下文的类加载器,简单来说就是这个线程是由哪个类加器加载的,如果是在没有修改线程上下文类加载器的情况下,则保持与父线程同样的类加载器。
·public void setContextClassLoader(ClassLoader cl)设置该线程的类加载器,这个方法可以打破JAVA类加载器的父委托机制,有时候该方法也被称为JAVA类加载器的后门
如何退出线程:
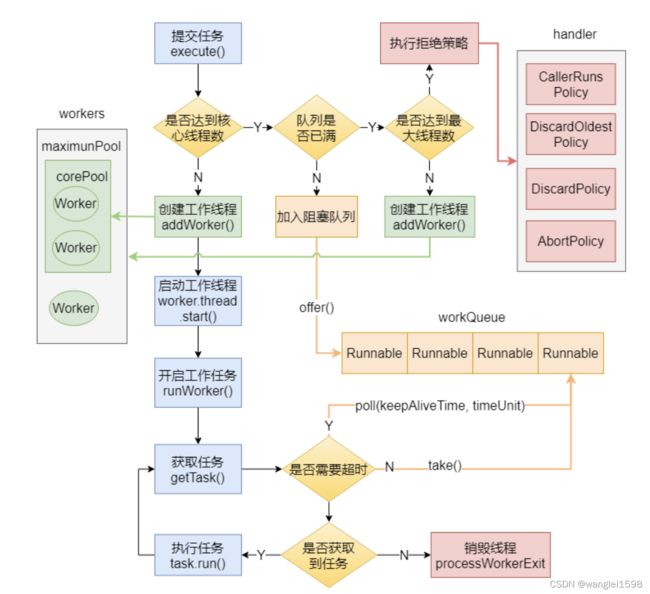
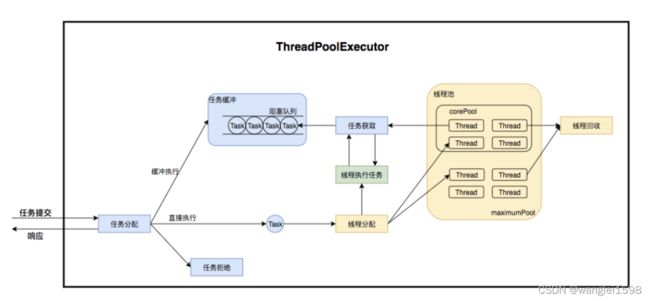
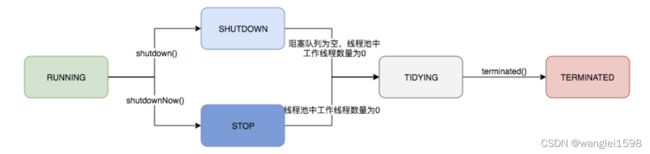
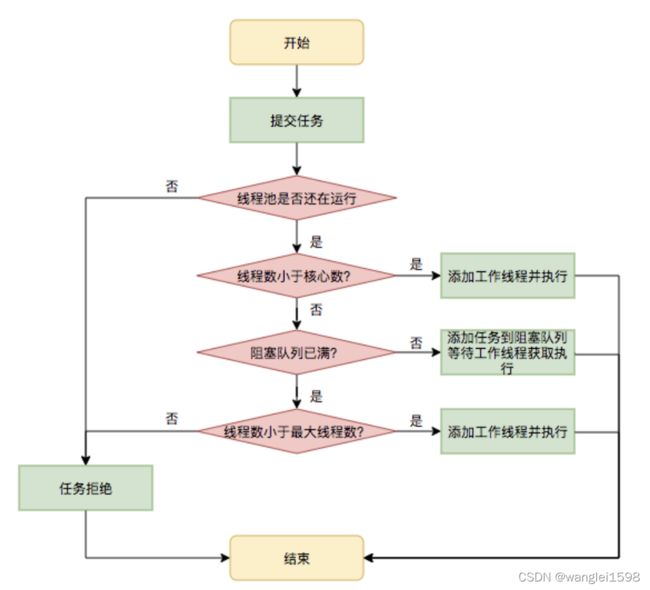
一、正常关闭
1.线程结束生命周期正常结束
线程运行结束,完成了自己的使命之后,就会正常退出,如果线程中的任务耗时比较短,或者时间可控,那么放任它正常结束就好了。
2.捕获中断信号关闭线程
我们通过new Thread的方式创建线程,这种方式看似很简单,其实它的派生成本是比较高的,因此在一个线程中往往会循环地执行某个任务,比如心跳检查,不断地接收网络消息报文等,系统决定退出的时候,可以借助中断线程的方式使其退出,示例代码如下:
上面的代码是通过检查线程interrupt的标识来决定是否退出的,如果在线程中执行某个可中断方法,则可以通过捕获中断信号来决定是否退出。
上面的代码执行结果都会导致线程正常的结束,程序输出如下:
I will start work
System will be sh
utdown.I will be exiting
3.使用volatile开关控制
由于线程的interrupt标识很有可能被擦除,或者逻辑单元中不会调用任何可中断方法,所以使用volatile修饰的开关flag关闭线程也是一种常用的做法,具体如下:
上面的例子中定义了一个closed开关变量,并且是使用volatile修饰(关于volatile关键字会在本书的第3部分中进行非常细致地讲解,volatile关键字在Java中是一个革命性的关键字,非常重要,它是Java原子变量以及并发包的基础)运行上面的程序同样也可以关闭线程。
二、异常退出
在一个线程的执行单元中,是不允许抛出checked异常的,不论Thread中的run方法,还是Runnable中的run方法,如果线程在运行过程中需要捕获checked异常并且判断是否还有运行下去的必要,那么此时可以将checked异常封装成unchecked异常(RuntimeException)抛出进而结束线程的生命周期。
CAS
在硬件层间,大部分现代处理器都已经支持原子化的CAS算法。在JDK1.5以后,虚拟机便可以使用这个指令来实现并发操作和并发数据结构,并且这种操作在虚拟机中可以说无处不在。
CAS 核心 【原创】Java并发编程系列12 | 揭秘CAS
CAS 比较交换的过程 CAS(V,A,B):
V-一个内存地址存放的实际值、A-旧的预期值、B-即将更新的值,当且仅当预期值 A 和内存值 V 相同时,将内存值修改为 B 并返回 true,否则什么都不做,并返回 false。
CAS,Compare And Swap,即比较并交换。Doug lea 大神在同步组件中大量使用 CAS 技术鬼斧神工地实现了 Java 多线程的并发操作。整个 AQS 同步组件、Atomic 原子类操作等等都是以 CAS 实现的。可以说 CAS 是整个 J.U.C 的基石。
Unsafe 是 CAS 的核心类,由于 Java 方法无法直接访问底层系统,需要通过本地(native)方法来访问,Unsafe 相当于一个后门,基于该类可以直接操作特定内存的数据。
CAS VS synchronized
synchronized 是线程获取锁是一种悲观锁策略,即假设每一次执行临界区代码都会产生冲突,所以当前线程获取到锁的之后会阻塞其他线程获取该锁。
CAS(无锁操作)是一种乐观锁策略,它假设所有线程访问共享资源的时候不会出现冲突,所以出现冲突时就不会阻塞其他线程的操作,而是重试当前操作直到没有冲突为止
sun.misc.Unsafe JNI类(CAS的核心) C++实现
Java是一种安全的开发语言,Java的设计者在设计之初就想将一些危险的操作屏蔽掉。比如对内存的手动管理,但是本章所学习的原子类型,甚至在接下来的章节中将要学习到的并发工具、并发容器等在其底层都依赖于一个特殊的类sun.misc.Unsafe,该类是可以直接对内存进行相关操作的,甚至还可以通过汇编指令直接进行CPU的操作。
sun.misc.Unsafe提供了非常多的底层操作方法,这些方法更加接近机器硬件(CPU/内存),因此效率会更高。不仅Java本身提供的很多API都对其有严重依赖,而且很多优秀的第三方库/框架都对它有着严重的依赖,比如LMAX Disruptor,不熟悉系统底层,不熟悉C/C++汇编等的开发者没有必要对它进行深究,但是这并不妨碍我们直接使用它。在使用的过程中,如果使用不得当,那么代价将是非常高昂的,因此该类被命名为Unsafe也就在情理之中了,总之一句话,你可以用,但请慎用!
如何获取Unsafe
使用的前提是首先要进行获取,本节先从如何获取入手,为大家展示一下如何实例化Unsafe,既然说原子包下面的原子类型都依赖于Unsafe,那么我们参考它就可以了,随便打开一个原子类型的源码(以AtomicInteger源码为例),如下。
...
private static final Unsafe unsafe = Unsafe.getUnsafe();...
看起来很简单,通过调用静态方法Unsafe.getUnsafe()就可以获取一个Unsafe的实例,但是在我们自己的类中执行同样的代码却会抛出SecurityException异常。
Exception in thread "main" java.lang.SecurityException: Unsafe
at sun.misc.Unsafe.getUnsafe(Unsafe.java:90) at com.wangwenjun.concurrent.juc.automic.UnsafeExample.mai
n(UnsafeExample.java:9)
为什么在AtomicInteger中可以,在我们自己的代码中就不行呢?下面深入源码一探究竟。
@CallerSensitive
public static Un
safe getUnsafe() { Class var0 =
Reflection.getCallerClass(); // 如果对getUns
afe方法的调用类不是由系统类加载器加载的,则会抛出异常 if (!VM.isSy
stemDomainLoader(var0.getClassLoade
r())) { throw ne
w SecurityException("Unsafe"); } else { return t
heUnsafe; }}
通过getUnsafe()
方法的源码,我们可以得知,如果调用该方法的类不是被系统类加载器加载的就会抛出异常,通常情况下开发者所开发的Java类都会被应用类加载器进行加载。
在Unsafe类中存在一个Unsafe的实例theUnsafe
,该实例是类私有成员,并且在Unsafe类的静态代码块中已经被初始化了,因此我们可以通过反射的方式尝试获取该成员的属性,代码如下所示。
private static Unsafe getUnsafe()
{ try { Field f = Unsafe.class.ge
tD
eclaredF
ield("
theUnsafe"); f.setAccessible(true); return (Unsafe) f.get(nul
l)
; } catch (Exception e) { throw new RuntimeExceptio
n(
"can't i
nitial
the unsafe instance.", e); }
危险的Unsafe
Unsafe非常强大,它可以帮助我们获得某个变量的内存偏移量,获取内存地址,在其内部更是运行了汇编指令,为我们在高并发编程中提供Lock Free的解决方案,提高并发程序的执行效率。但是Unsafe正如它的名字一样是很不安全的,如果使用错误则会出现很多灾难性的问题(本地代码所属的内存并不在JVM的堆栈中),本节就来看一下借助于Unsafe可以实现哪些功能呢?
1. 绕过类构造函数完成对象创建
我们都知道,主动使用某个类会引起类的加载过程发生直到该类完成初始化,最典型的例子是当我们通过关键字new进行对象的创建时,对应的构造函数肯定会被执行,这是毫无疑问的,但是Unsafe可以绕过构造函数完成对象的创建,我们来看下面的例子。
public static void main(String[] args)
throws IllegalAccessException,
InstantiationException{ // ①new 关键字 Example example1 = new Example(); assert example1.getX() == 10; // ② 反射 Example example2 = Example.class.n
ewInstance(); assert example2.getX() == 10; // ③使用Unsafe Example example3 = (Example) getUnsafe().allo
cateInstance(Example.class); assert example3.getX() == 0;}static class Example{ private int x; public Example() { this.x = 10; } private int getX() { return x; }}
▪ 注释①和注释②处,我们分别使用new关键字以及反射获得了Example对象的实例,这会触发无参构造函数的执行,x的值将会被赋予10,因此断言肯定能够顺利通过。
▪ 在注释③处,我们借助于Unsafe的allocateInstance
方法获得了Example的实例,该操作并不会导致Example构造函数的执行,因此x将不会被赋予10。
2. 直接修改内存数据
我们来看下面这样一段程序代码。
public static void main(String[] args)
{ Guard guard = new Guard(); assert !guard.canAccess(10);}static class Guard{ private int accessNo = 1; public boolean canAccess(int no) { return this.accessNo == no; }}
非常简单,是吧?没错!Guard提供了一个方法canAccess()
用于校验传入的数值是否与accessNo相等,如果不相等则我们会拒绝某些事情的发生,通常情况下,为了使得canAccess()
返回true,我们只需要传入与accessNo相等的数值即可,但是Unsafe可以直接修改accessNo在内存中的值。
Guard guard = new Guard();
assert !guard.canAccess(10
);assert guard.canAccess(1);
Unsafe unsafe = getUnsafe(
);// 获取accessNoField f = guard.getClass()
.getDeclaredField("accessNo")
;// 使用unsafe首先获得f的内存偏移量// 然后直接进行内存操作,将accessNo的值修
改为20unsafe.putInt(guard, unsaf
e.objectFieldOffset(f), 20);// 断言成功assert guard.canAccess(20)
;
3. 类的加载
借助于Unsafe还可以实现对类的加载,下面我们先来看一个比较简单的类,然后将其编译生成class字节码文件。
package com.wangwenjun.concurrent.juc.automic;
public class A{ private int i = 0; public A(){ this.i = 10; } public int getI() { return i; }}
使用Unsafe的defineClass方法完成对类的加载,代码如下。
程序代码:HelloExample.java
package com.wangwenjun.concurrent.juc.automic;
import java.io.File;import java.io.FileInputStream;import static com.wangwenjun.concurrent.juc.au
t
omic.UnsafeExample1.g
etUnsafe;public class UnsafeExample3{ public static void main(String[] args) throws Exception { byte[] classContents = getClassContent
(
); // 调用defineClass方法完成对A的加载 Class c = getUnsafe().defineClass(null
,
classContents, 0, classContents.length, null
,
null); Object result = c.getMethod("getI").in
v
oke(c.newInstance(), null); assert (Integer) result == 10; }// 读取class文件的二进制数组 private static byte[] getClassContent() th
r
ows Exception { File f = new File("C:\\Users\\wangwenj
u
n\\IdeaProjects\\java
-concurrency-book2\\target\\clas
s
es\\com\\wangwenjun\\concurrent\\juc\\automic\\A.class"); try (FileInputStream input = new FileI
n
putStream(f)) { byte[] content = new byte[(int) f.
l
ength()]; input.read(content); return content; } }}
Java无法直接访问底层操作系统,而是通过本地(native)方法来访问。不过尽管如此,JVM还是开了一个后门,JDK中有一个类Unsafe,它提供了硬件级别的 原子操作 。
1.通过Unsafe类可以分配内存,可以释放内存;类中提供的3个本地方法allocateMemory、reallocateMemory、freeMemory分别用于分配内存,扩充内存和释放内存,与C语言中的3个方法对应。
2.可以定位对象某字段的内存位置,也可以修改对象的字段值,即使它是私有的;
3.挂起与恢复:将一个线程进行挂起是通过park方法实现的,调用 park后,线程将一直阻塞直到超时或者中断等条件出现。unpark可以终止一个挂起的线程,使其恢复正常。整个并发框架中对线程的挂起操作被封装在 LockSupport类中,LockSupport类中有各种版本pack方法,但最终都调用了Unsafe.park()方法。
4.cas
CAS,Compare and Swap即比较并交换,设计并发算法时常用到的一种技术,java.util.concurrent包全完建立在CAS之上,没有CAS也就没有此包,可见CAS的重要性。
CAS也是通过Unsafe实现的
CAS,在Java并发应用中通常指CompareAndSwap或CompareAndSet,即比较并交换。
1、CAS是一个原子操作,它比较一个内存位置的值并且只有相等时修改这个内存位置的值为新的值,保证了新的值总是基于最新的信息计算的,如果有其他线程在这期间修改了这个值则CAS失败。CAS返回是否成功或者内存位置原来的值用于判断是否CAS成功。
2、JVM中的CAS操作是利用了处理器提供的CMPXCHG指令实现的。
优点:
缺点:
-
循环时间长开销大。
-
ABA问题。
-
只能保证一个共享变量的原子操作。
Java中的原子类:
util.cocurrent.atomic 原子变量类 基于CAS实现
提供了一组原子变量类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。可以对基本数据、数组中的基本数据、对类中的基本数据进行操作。原子变量类相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。
java.util.concurrent.atomic中的类可以分成4组:
-
标量类(Scalar):AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference
-
数组类:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
-
更新器类: AtomicLongFieldUpdater, AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
-
复合变量类:AtomicMarkableReference,AtomicStampedReference
http://chenzehe.iteye.com/blog/1759884
The java.util.concurrent.atomic package defines classes that support atomic operations on single variables. All classes have get and set methods that work like reads and writes on volatile variables. That is, a set has a happens-before relationship with any subsequent get on the same variable. The atomic compareAndSet method also has these memory consistency features, as do the simple atomic arithmetic methods that apply to integer atomic variables.
AtomicLong(性能差)与LongAdder(性能好) 可以看Java虚拟机JVM故障判断与性能优化8.4.3
-
Java内存模型要求lock、unlock、read、load、assign、use、store、write这8个操作都是具有原子性,但是对于64位的数据类型(long、double),允许虚拟机将没有被volatile修饰的64位数据的读写操作划分为两次32位的操作来进行,即允许虚拟机实现选择可以不保证64位数据类型的load、store、read和write这四个原子操作,但是可以视为原子性操作。
-
AtomicLong CAS中如果并发量大,则会不断进行循环调用,效率会比较低。
-
LongAdder实现热点数据的分离、更快,如果有并发更新可能会出现误差。底层用数组实现,其结果为数组的求和累加。性能高。
AtomicFieldUpdater们
在Java的原子包中提供了三种原子性更新对象属性的类,分别如下所示。
▪ AtomicIntegerFieldUpdater:
原子性地更新对象的int类型属性,该属性无须被声明成AtomicInteger。
▪ AtomicLongFieldUpdater:
原子性地更新对象的long类型属性,该属性无须被声明成AtomicLong。
▪ AtomicReferenceFieldUpdater:
原子性地更新对象的引用类型属性,该属性无须被声明成AtomicReference
以原子性更新对象中某一个属性,这属性需要用volatile进行修饰。
AtomicStampedReference Java并发必知必会第三弹:用积木讲解ABA原理
原子更新引用类型,这种更新方式会带有版本号。 解决CAS的ABA问题
作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子的方式将该引用和该标志的值设置为给定的更新值。
我们举个AtomicStampedReference的例子:
AtomicStampedReference的compareAndSet方法,多出了两个参数,分别是expectedStamp和newStamp,两个参数都是int型的,需要我们手动传入。
AtomicArray们
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray(引用类型数组) 维护数组
以 AtomicIntegerArray 来总结下常用的方法:
addAndGet(int i, int delta):以原子更新的方式将数组中索引为i的元素与输入值delta相加;
getAndIncrement(int i):以原子更新的方式将数组中索引为i的元素自增加1;
compareAndSet(int i, int expect, int update):将数组中索引为i的位置的元素进行更新;
用法:
AtomicIntegerArray 与 AtomicInteger 的方法基本一致,只不过在 AtomicIntegerArray 的方法中会多一个指定数组索引位 I。
LockSupport
java.util.concurrent 中源码频繁使用的 LockSupport 来阻塞线程和唤醒线程,如 AQS 的底层实现用到 LockSupport.park()方法和 LockSupport.unpark()方法。
方法介绍
LockSupport 提供 park()和 unpark()方法实现阻塞线程和解除线程阻塞。
阻塞线程:
-
void park():阻塞当前线程,如果调用 unpark 方法或者当前线程被中断,才能从 park()方法中返回
-
void park(Object blocker):功能同方法 1,入参增加一个 Object 对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
-
void parkNanos(long nanos):阻塞当前线程,最长不超过 nanos 纳秒,增加了超时返回的特性;
-
void parkNanos(Object blocker, long nanos):功能同方法 3,入参增加一个 Object 对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
-
void parkUntil(long deadline):阻塞当前线程,直到 deadline;
-
void parkUntil(Object blocker, long deadline):功能同方法 5,入参增加一个 Object 对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
每个 park 方法都对应有一个带有 Object 阻塞对象的重载方法。增加了一个 Object 对象作为参数,此对象在线程受阻塞时被记录,以允许监视工具和诊断工具确定线程受阻塞的原因。
唤醒线程:
void unpark(Thread thread):唤醒处于阻塞状态的指定线程
原理
每个线程都会与一个许可关联,这个许可对应一个 Parker 的实例,Parker 有一个 int 类型的属性_count。
park()方法:
-
将_count 变为 0
-
如果原_count==0,将线程阻塞
unpark()方法:
-
将_count 变为 1
-
如果原_count==0,将线程唤醒
LockSupport的特殊之处:
-
Object 的 wait()/notify 方法需要获取到对象锁之后在同步代码块里才能调用,而 LockSupport 不需要获取锁。所以使用 LockSupport 线程间不需要维护一个共享的同步对象,从而实现了线程间的解耦。
-
unark()方法可提前 park()方法调用,所以不需要担心线程间执行的先后顺序。
-
多次调用 unpark()方法和调用一次 unpark()方法效果一样,因为 unpark 方法是直接将_counter 赋值为 1,而不是加 1。
-
许可不可重入,也就是说只能调用一次 park()方法,如果多次调用 park()线程会一直阻塞。
Lock
Lock 和synchronize区别
1. 用法不同。synchronized既可以加在方法上,也可以加在特定代码块中,括号表示需要锁的对象。Lock需要显式地指定起始位置和终止位置。synchronized托管给JVM执行,Lock的锁定是通过代码实现的,有比synchronized更精准的线程语义;
2.性能不同。JDK5中新加入了一个Lock接口的实现类ReetrantLock. 它不仅拥有和synchronized相同的并发性和内存语义,还多了锁投票、定时锁、等候和中断锁等。竞争不是很激烈的时候,synchronized性能优于ReetrantLock;但是资源竞争激烈的时候,synchronized性能下降很快,ReetrantLock性能基本不变;
3. synchronized 同步块执行完成或者遇到异常是锁会自动释;Lock需要手动解锁,而且必须在finally块中释放,否则会引起死锁。
性能对比可以看Java高并发编程详解:深入理解并发核心库。
Lock 接口具有以下主要方法:
lock() 将 Lock 实例锁定。如果该 Lock 实例已被锁定,调用 lock() 方法的线程将会阻塞,直到 Lock 实例解锁。
lockInterruptibly() 方法将会被调用线程锁定,除非该线程被打断。此外,如果一个线程在通过这个方法来锁定 Lock 对象时进入阻塞等待,而它被打断了的话,该线程将会退出这个方法调用。
tryLock() 方法试图立即锁定 Lock 实例。如果锁定成功,它将返回 true,如果 Lock 实例已被锁定该方法返回 false。这一方法永不阻塞。
tryLock(long timeout, TimeUnit timeUnit) 类似于 tryLock() 方法,除了它在放弃锁定 Lock 之前等待一个给定的超时时间之外。
unlock() 对 Lock 实例解锁。一个 Lock 实现将只允许锁定了该对象的线程来调用此方法。其他(没有锁定该 Lock 对象的线程)线程对 unlock() 方法的调用将会抛一个未检查异常(RuntimeException)。
-
可重入锁。可重入锁是指同一个线程可以多次获取同一把锁。ReentrantLock和synchronized都是可重入锁。
-
可中断锁。可中断锁是指线程尝试获取锁的过程中,是否可以响应中断。synchronized是不可中断锁,而ReentrantLock则提供了中断功能。
-
公平锁与非公平锁。公平锁是指多个线程同时尝试获取同一把锁时,获取锁的顺序按照线程达到的顺序,而非公平锁则允许线程“插队”。 s ynchronized是非公平锁,而ReentrantLock的默认实现是非公平锁,但是也可以设置为公平锁 。
-
CAS操作(CompareAndSwap)。CAS操作简单的说就是比较并交换。CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。CAS 有效地说明了“我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。” Java并发包(java.util.concurrent)中大量使用了CAS操作,涉及到并发的地方都调用了sun.misc.Unsafe类方法进行CAS操作。
Lock接口的实现类
ReentrantLock 可重入锁 实现原理: 帐号已迁移 【原创】Java并发编程系列15 | 重入锁ReentrantLock
#lock()方法,加锁。#unlock()方法释放锁
newCondition 条件
ReentranReadWriteLock 读写锁
分为读锁(readlock())和写锁(writelock()).
进入读锁的前提:
1.其他线程没有写锁
2.其他线程没有获取写锁的请求
进入写锁的前提:
1.其他线程没有写锁
2.没有读锁
写锁内可以获取读锁,读锁内想获取写锁会死锁
不足:ReentrantReadWriteLock是读写锁,在多线程环境下,大多数情况是读的情况远远大于写的操作,因此可能导致写的饥饿问题。
Synchronzied 和 Lock 的主要区别如下:
-
存在层面 : Syncronized 是Java 中的一个关键字,存在于 JVM 层面,Lock 是 Java 中的一个接口
-
锁的释放条件 : 1. 获取锁的线程执行完同步代码后,自动释放; 2. 线程发生异常时,JVM会让线程释放锁; Lock 必须在 finally 关键字中释放锁,不然容易造成线程死锁
-
锁的获取 : 在 Syncronized 中,假设线程 A 获得锁,B 线程等待。 如果 A 发生阻塞,那么 B 会一直等待。 在 Lock 中,会分情况而定,Lock 中有尝试获取锁的方法,如果尝试获取到锁,则不用一直等待
-
锁的状态 : Synchronized 无法判断锁的状态,Lock 则可以判断
-
锁的类型 : Synchronized 是可重入,不可中断,非公平锁; Lock 锁则是 可重入,可判断,可公平锁
-
锁的性能 : Synchronized 适用于少量同步的情况下,性能开销比较大。 Lock 锁适用于大量同步阶段:
Lock 锁可以提高多个线程进行读的效率(使用 readWriteLock)
-
在竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
-
ReetrantLock 提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等
StampedLock(Java 8 新增)
是ReentrantReadWriteLock 的增强版,是为了解决ReentrantReadWriteLock的一些不足。
StampedLock读锁并不会阻塞写锁,设计思路也比较简单,就是在读的时候发现有写操作,再去读多一次。StampedLock有两种锁,一种是悲观锁,另外一种是乐观锁,如果线程拿到乐观锁就读和写不互斥,如果拿到悲观锁就读和写互斥。
Java8对读写锁的改进:StampedLock_单曲循环的寂寞的博客-CSDN博客
读写锁的饥饿写问题
我们曾经在3.7节中进行过基准测试,发现读写锁的性能并不是最佳的,当然更有甚者,如果对读写锁使用不得当,则还会引起饥饿写的情况发生,那么什么是饥饿写呢?所谓的饥饿写是指在使用读写锁的时候,读线程的数量远远大于写线程的数量,导致锁长期被读线程霸占,写线程无法获得对数据进行写操作的权限从而进入饥饿的状态(当然可以在构造读写锁时指定其为公平锁,读写线程获得执行权限得到的机会相对公平,但是当读线程大于写线程时,性能效率会比较低下)。因此在使用读写锁进行数据一致性保护时请务必做好线程数量的评估(包括线程操作的任务类型)。
针对这样的问题,JDK1.8版本引入了StampedLock,该锁由一个long型的数据戳(stamp)和三种模型构成,当获取锁(比如调用readLock(),writeLock())的时候会返回一个long型的数据戳(stamp),该数据戳将被用于进行稍后的锁释放参数。如果返回的数据戳为0(比如调用tryWriteLock()),则表示获取锁失败,同时StampedLock还提供了一种乐观读的操作方式,稍后会有相关的示例。
需要注意的一点是,StampedLock是不可重入的,不像前文中介绍的两种锁类型(ReentrantLock、ReentrantReadWriteLock)都有hold计数器,每一次对StampedLock锁的获取都会生成一个数据戳,即使当前线程在获得了该锁的情况下再次获取也会返回一个全新的数据戳,因此如果使用不当则会出现死锁的问题。
Condition
总结下 Condition 和 wait/notify 的比较:
-
Condition 可以精准的对多个不同条件进行控制,wait/notify 只能和 synchronized 关键字一起使用,并且只能唤醒一个或者全部的等待队列;
-
Condition 需要使用 Lock 进行控制,使用的时候要注意 lock() 后及时的 unlock(),Condition 有类似于 await 的机制,因此不会产生加锁方式而产生的死锁出现,同时底层实现的是 park/unpark 的机制,因此也不会产生先唤醒再挂起的死锁,一句话就是不会产生死锁,但是 wait/notify 会产生先唤醒再挂起的死锁。
多线程非常难但是很经典的问题: 一个困扰我122天的技术问题,我好像知道答案了。
提升(hoisting):
处理器亲和性。ProcessorAffinity 将线程或者进程绑定到特定的CPU核上。这意味着只要是某个特定的线程,他就肯定只会在某个特点的CPU核上执行。充分利用缓存。
可以看看Java-Thread-Affinity 这个库
Netty.docs: Thread Affinity
https://github.com/OpenHFT/Java-Thread-Affinity
如何优雅的终止一个线程 如何停止一个正在运行的线程?
Thread API Thread (Java Platform SE 7 )
转换方法 #非静态方法 .静态方法
5.Thread#stop,Tread#suspend,Tread#resume方法 Deprecated
7.Thread#isAlive() 判断一个线程是不是活动的,从定义上来说,一个线程从其真正启动前一段时间到其真正停止后一段时间都被认为是活动的。
8.Thread#setUncaughtExceptionHandler(UncaughtExceptionHandler eh)
Thread.setDefaultUncaughtExceptionHandler(UncaughtExceptionHandler eh)
没有Catch住RuntimeException的线程会退出。
在Thread类中,关于处理运行时异常的API总共有四个,如下所示:
·public void setUncaughtExceptionHandler(UncaughtExceptionHandler eh):为某个特定线程指定UncaughtExceptionHandler。
·public static void setDefaultUncaughtExceptionHandler(UncaughtExceptionHandler eh):设置全局的UncaughtExceptionHandler。
·public UncaughtExceptionHandler getUncaughtExceptionHandler():获取特定线程的UncaughtExceptionHandler。
·public static UncaughtExceptionHandler getDefaultUncaughtExceptionHandler():获取全局的UncaughtExceptionHandler
9.Thread.enumerate(Thread[] tarray) Copies into the specified array every active thread in the current thread's thread group and its subgroups.
将当前线程的线程组及其子组中的每一个活动线程复制到指定的数组中。该方法只调用当前线程的线程组的 enumerate 方法,且带有数组参数。
首先,如果有安全管理器,则 enumerate 方法调用安全管理器的 checkAccess 方法,并将线程组作为其参数。这可能导致抛出 SecurityException。
参数:
tarray - 要复制到的线程对象数组
返回:
放入该数组的线程数
抛出:
SecurityException - 如果安全管理器存在,并且其 checkAccess 方法不允许该操作。
10.Thread.activeCount() 返回当前线程的线程组中活动线程的数目。
11.Thread.currentThread() 获取当前线程对象。
置线程上下文类加载器
获取线程上下文类加载器
public ClassLoader getContextClassLoader ()
设置线程类加载器(可以打破Java类加载器的父类委托机制)
public void setContextClassLoader (ClassLoader cl)
如何正确的停止一个线程: 如何正确地停止一个线程? - 王晓符 - 博客园
线程上下文切换
Java多线程的上下文切换_孙悟空2015的博客-CSDN博客
线程组 一个线程必然有所属线程组
TreadGroup类 ThreadGroup (Java Platform SE 7 )
可以获得子线程的信息
可以一次性修改所有子线程的信息
Java管道: java io系列04之 管道(PipedOutputStream和PipedInputStream)的简介,源码分析和示例 - 如果天空不死 - 博客园
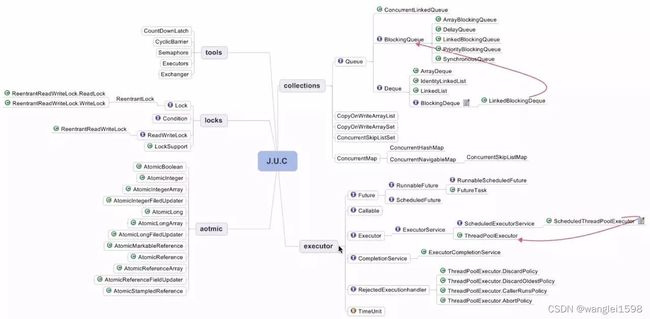
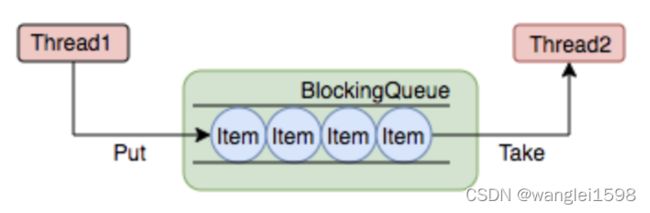
java.util.concurrent包 又称J.U.C
线程同步方法
4. Semaphore 信号量 一般的用法是, 用于限制对于某一资源的同时访问
构造的时候传入可供管理的信号量的数值,总数就是控制并发的数量。我们需要控制并发的代码,执行前先获取信号(acquire)
,执行后归还信号(release)。每次acquire成功返回后,Semaphore可用的信号量就会减少一个,如果没有可用的信号,
acquire就会阻塞,等待release调用释放信号后,acquire才会得到信号返回。
semaphore.acquire()
try{
}
finally{
semaphore.release();
}
如果初始数值为1,Semaphore就变成了互斥锁、不可重入。
▪ boolean isFair():
对Semaphore许可证的争抢采用公平还是非公平的方式,对应到内部的实现类为FairSync(公平)和NonfairSync(非公平)。
▪ int availablePermits():
当前的Semaphore还有多少个可用的许可证。
▪ int drainPermits():
排干Semaphore的所有许可证,以后的线程将无法获取到许可证,已经获取到许可证的线程将不受影响。
▪ boolean hasQueuedThreads():
当前是否有线程由于要获取Semaphore许可证而进入阻塞?(该值为预估值。)
▪ int getQueueLength():
如果有线程由于获取Semaphore许可证而进入阻塞,那么它们的个数是多少呢?(该值为预估值。
5. CountDownLatch
CountDownLatch这个类能够使一个线程等待其他线程完成各自的工作后再执行。例如,应用程序的主线程希望在负责启动框架服务的线程已经启动所有的框架服务之后再执行。
CountDownLatch (Java Platform SE 7 )
一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
用给定的计数 初始化 CountDownLatch。由于调用了 countDown()
方法,所以在当前计数到达零之前,await
方法会一直受阻塞。之后,会释放所有等待的线程,await
的所有后续调用都将立即返回。这种现象只出现一次——计数无法被重置。
CountDownLatch 很适合用来将一个任务分为n个独立的部分,等这些部分都完成后继续接下来的任务,
CountDownLatch 只能出发一次,计数值不能被重置
不可以循环使用
7. CyclicBarrier 关卡 可以循环使用
CyclicBarrier (Java Platform SE 7 )
一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定
大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrier 在释放等待线程
后可以重用,所以称它为循环 的 barrier。CyclicBarrier 支持一个可选的 Runnable 命令,在一组线程中的最后一
个线程到达之后(但在释放所有线程之前),该命令只在每个屏障点运行一次。若在继续所有参与线程之前更新共享
状态,此屏障操作 很有用。
主要方法:
-
//设置parties、count及barrierCommand属性。
-
CyclicBarrier(int):
-
-
//当await的数量到达了设定的数量后,首先执行该Runnable对象。
-
CyclicBarrier(int,Runnable):
-
-
//通知barrier已完成线程
-
await():
应用场景
在某种需求中,比如一个大型的任务,常常需要分配好多子任务去执行,只有当所有子任务都执行完成时候,才能执行主任务,这时候,就可以选择CyclicBarrier了。
8.Exchanger
Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点两个线程可以交换彼此的数据。这两个线程通过exchange方法交换数据, 如果第一个线程先执行exchange方法,它会一直等待第二个线程也执行exchange,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
Exchanger (Java Platform SE 7 )
9.容器 Java 并发工具包 java.util.concurrent 用户指南_Defonds的博客-CSDN博客_java.util.concurrent
CopyOnWrite开头:更改容器的时候,把容器写一份进行修改,保护正在读的线程不受影响。 适合的场景:读操作远大于写操作,并且不要求实时数据一致性的情况
核心思想是利用读写分离,因为高并发往往是读多写少。进行读操作的时候,不加锁以保证性能;对写操作则要加ReentrantLock锁,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性。
既然CopyOnWrite在进行写操作的时候要进行数组的复制,性能和内存开销比较大,因此它更适用于读多写少的操作,例如缓存
CopyOnWrite分析_登天蚂蚁的博客-CSDN博客_copyonwrite
不能保证实时数据一致性,只能保证最终一致性。
CopyOnWrite容器,简称COW,该容器的基本实现思路是在程序运行的初期,所有的线程都共享一个数据集合的引用。所有线程对该容器的读取操作将不会对数据集合产生加锁的动作,从而使得高并发高吞吐量的读取操作变得高效,但是当有线程对该容器中的数据集合进行删除或增加等写操作时才会对整个数据集合进行加锁操作,然后将容器中的数据集合复制一份,并且基于最新的复制进行删除或增加等写操作,当写操作执行结束以后,将最新复制的数据集合引用指向原有的数据集合,进而达到读写分离最终一致性的目的。
我们在前面也提到过这样做的好处是多线程对CopyOnWrite容器进行并发的读是不需要加锁的,因为当前容器中的数据集合是不会被添加任何元素的(关于这一点,CopyOnWrite算法可以保证),所以CopyOnWrite容器是一种读写分离的思想,读和写不同的容器,因此不会存在读写冲突,而写写之间的冲突则是由全局的显式锁Lock来进行防护的,因此CopyOnWrite常常被应用于读操作远远高于写操作的应用场景中。CopyOnWrite算法的基本原理如图4-20所示。
图4-20 CopyOnWrite算法的基本原理
Java中提供了两种CopyOnWrite算法的实现类,具体如下,由于使用同样比较简单,在这里我们将不做过多讲述。
▪ CopyOnWriteArrayList:在JDK1.5版本被引入,用于高并发的ArrayList解决方案,在某种程度上可以替代Collections.synchronizedList。
▪ CopyOnWriteArraySet:也是自JDK1.5版本被引入,提供了高并发的Set的解决方案,其实在底层,CopyOnWriteArraySet完全是基于CopyOnWriteArrayList实现的
虽然COW算法为解决高并发读操作提供了一种新的思路(读写分离),但是其仍然存在一些天生的缺陷,具体如下。
▪ 数组复制带来的内存开销:因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的数据集合和新拷贝的数据集合,当然旧的数据集合在拷贝结束以后会满足被回收的条件,但是在某个时间段内,内存还是会有将近一半的浪费。
▪ CopyOnWrite并不能保证实时的数据一致性:CopyOnWrite容器只能保证数据的最终一致性,并不能保证数据的实时一致性。举个例子,假设A线程修改了数据复制并且增加了一个新的元素但并未将数据集合的引用指向最新复制,与此同时,B线程是从旧的数据集合中读取元素,因此A写入的数据并不能实时地被B线程读取。
既然CopyOnWrite并不是一个很完美的高并发线程安全解决方案,那么它的应用场景又该是怎样的呢?其实我们在本节中已经提到过了,对于读操作远大于写操作,并且不要求实时数据一致性的情况,CopyOnWrite容器将是一个很合理的选择,比如在规则引擎中对新规则的引入、在告警规则中对新规则的引入、在黑白名单中对新数据的引入,并不一定需要严格保证数据的实时一致性,我们只需要确保在单位时间后的最终一致性即可,在这种情况下,我们就可以采用COW算法提高数据的读取速度及性能
Coccurent开头:尽量保证读不加锁,并且修改时不影响读。
ConcurrentHashMap
ConcurrentHashMap 和 java.util.HashTable 类很相似,但 ConcurrentHashMap 能够提供比 HashTable 更好的并发性能。在你从中读取对象的时候 ConcurrentHashMap 并不会把整个 Map 锁住。此外,在你向其中写入对象的时候,ConcurrentHashMap 也不会锁住整个 Map。它的内部只是把 Map 中正在被写入的部分进行锁定。
另外一个不同点是,在被遍历的时候,即使是 ConcurrentHashMap 被改动,它也不会抛 ConcurrentModificationException。尽管 Iterator 的设计不是为多个线程的同时使用。
10.volatile 由Java引起的指令重排序思考_hyzhang98的博客-CSDN博客_java 重排序
volatile关键字保证了
1. 可见性——在多线程环境下,被修饰的变量在别修改后会马上同步到主存,这样该线程对这个变量的修改就是对所有其他线程可见的,其他线程能够马上读到这个修改后值。
2. 禁止指令重排序优化
volatile-可见性通过加入内存屏障和禁止重排序优化实现:
11.java.util.concurrent包
Java 并发工具包 java.util.concurrent 用户指南_Defonds的博客-CSDN博客_java.util.concurrent
阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
阻塞队列提供了四种处理方法:
|
方法\处理方式
|
抛出异常
|
返回特殊值
|
一直阻塞
|
超时退出
|
|
插入方法
|
add(e)
|
offer(e)
|
put(e)
|
offer(e,time,unit)
|
|
移除方法
|
remove()
|
poll()
|
take()
|
poll(time,unit)
|
|
检查方法
|
element()
|
peek()
|
不可用
|
不可用
|
-
抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException(“Queue full”)异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。
-
返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null
-
一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。
-
超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
JDK7提供了7个阻塞队列。分别是
-
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
-
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
-
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
-
DelayQueue:一个使用优先级队列实现的无界阻塞队列。 DelayQueue 是一个支持延时获取元素的无阻塞队列,其中的元素只能在延迟到期后才能使用,DelayQueue 中的队列头是延迟最长时间的元素,如果没有延迟,则没有 head 头元素,poll 方法会返回 null。判断的依据就是 getDelay(TimeUnit.NANOSECONDS) 方法返回一个值小于或者等于 0 就会发生过期。
-
SynchronousQueue:一个不存储元素的阻塞队列。
-
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
-
TransferQueue 继承于 BlockingQueue,它是一个接口,一个 BlockingQueue 是一个生产者可能等待消费者 接受 元素,TransferQueue 则更进一步,生产者会一直阻塞直到所添加到队列的元素 被某一个消费者所 消费 ,新添加的transfer 方法用来实现这种约束。
-
TransferQueue 有下面这些方法:两个 tryTransfer 方法,一个是非阻塞的,另一个是带有 timeout 参数设置超时时间的。还有两个辅助方法 hasWaitingConsumer 和 getWaitingConcusmerCount 。
8.1 Transfer怎么理解?
如果有消费者正在获取元素,则将队列中的元素传递给消费者。如果没有消费者,则等待消费者消费。我把它称作使命必达队列,必须将任务完成才能返回。
8.2 生活中的案例
-
针对TransferQueue的transfer方法
-
圆通快递员要将小明的2个快递送货到门,韵达快递员也想将小明的2个快递送货到门。小明一次只能拿一个,快递员必须等小明拿了一个后,才能继续给第二个。
-
针对TransferQueue的tryTransfer方法
-
圆通快递员要将小明的2个快递送货到门,韵达快递员也想将小明的2个快递送货到门。发现小明不在家,就把快递直接放到菜鸟驿站了。
-
针对TransferQueue的tryTransfer超时方法
-
圆通快递员要将小明的2个快递送货到门,韵达快递员也想将小明的2个快递送货到门。发现小明不在家,于是先等了5分钟,发现小明还没有回来,就把快递直接放到菜鸟驿站了。
8.3 TransferQueue的原理解析
-
transfer(E e)
原理如下图所示:
 transfer方法的原理
transfer方法的原理
-
原理图解释:生产者线程Producer Thread尝试将元素B传给消费者线程,如果没有消费者线程,则将元素B放到尾节点。并且生产者线程等待元素B被消费。当元素B被消费后,生产者线程返回。
-
如果当前有消费者正在等待接收元素(消费者通过take方法或超时限制的poll方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。
-
如果没有消费者等待接收元素,transfer方法会将元素放在队列的tail(尾)节点,并等到该元素被消费者消费了才返回。
-
tryTransfer(E e)
-
试探生产者传入的元素是否能直接传给消费者。
-
如果没有消费者等待接收元素,则返回false。
-
和transfer方法的区别是,无论消费者是否接收,方法立即返回。
-
tryTransfer(E e, long timeout, TimeUnit unit)
-
带有时间限制的tryTransfer方法。
-
试图把生产者传入的元素直接传给消费者。
-
如果没有消费者消费该元素则等待指定的时间再返回。
-
如果超时了还没有消费元素,则返回false。
-
如果在超时时间内消费了元素,则返回true。
-
getWaitingConsumerCount()
-
获取通过BlockingQueue.take()方法或超时限制poll方法等待接受元素的消费者数量。近似值。
-
返回等待接收元素的消费者数量。
-
hasWaitingConsumer()
-
获取是否有通过BlockingQueue.tabke()方法或超时限制poll方法等待接受元素的消费者。
-
返回true则表示至少有一个等待消费者。
8.3 TransferQueue接口继承了哪些接口?
8.4 哪些类实现了TransferQueue接口?
1.ArrayBlockingQueue
ArrayBlockingQueue是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证访问者公平的访问队列,所谓 公平访问队列 是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。
2.LinkedBlockingQueue
LinkedBlockingQueue是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
3.PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界队列。默认情况下元素采取自然顺序排列,也可以通过比较器comparator来指定元素的排序规则。元素按照升序排列。
4.DelayQueue DelayQueue = BlockingQueue + PriorityQueue + Delayed
DelayQueue也是一个实现了BlockingQueue接口的“无边界”阻塞队列,但是该队列却是非常有意思和特殊的一个队列(存入DelayQueue中的数据元素会被延迟单位时间后才能消费),在DelayQueue中,元素也会根据优先级进行排序,这种排序可以是基于数据元素过期时间而进行的(比如,你可以将最快过期的数据元素排到队列头部,最晚过期的数据元素排到队尾)。
对于存入DelayQueue中的元素是有一定要求的:元素类型必须是Delayed接口的子类,存入DelayQueue中的元素需要重写getDelay(TimeUnit unit)方法用于计算该元素距离过期的剩余时间,如果在消费DelayQueue时发现并没有任何一个元素到达过期时间,那么对该队列的读取操作会立即返回null值,或者使得消费线程进入阻塞
DelayQueue延时队列,当队列中的元素到达延迟时间时才会被取出。队列元素会按照最终执行时间在队列中进行排序。
DelayQueue是一个支持延时获取元素的无界阻塞队列。队列使 用PriorityQueue来实现 。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将DelayQueue运用在以下应用场景:
队列中的Delayed必须实现compareTo来指定元素的顺序。比如让延时时间最长的放在队列的末尾。
5.SynchronousQueue
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景,比如在一个线程中使用的数据,传递给另外一个线程使用,SynchronousQueue的吞吐量高于LinkedBlockingQueue 和 ArrayBlockingQueue。
SynchronousQueue
Java 6的并发编程包中的 SynchronousQueue 是一个没有数据缓冲的 BlockingQueue ,生产者线程对其的插入操作put必须等待消费者的移除操作take,反过来也一样。
不像ArrayBlockingQueue或LinkedListBlockingQueue,SynchronousQueue内部并没有数据缓存空间,你不能调用peek()方法来看队列中是否有数据元素,因为数据元素只有当你试着取走的时候才可能存在,不取走而只想偷窥一下是不行的,当然遍历这个队列的操作也是不允许的。队列头元素是第一个排队要插入数据的 线程 ,而不是要交换的数据。数据是在配对的生产者和消费者线程之间直接传递的,并不会将数据缓冲数据到队列中。可以这样来理解:生产者和消费者互相等待对方,握手,然后 一起 离开。
SynchronousQueue在日常的开发使用中并不是很常见,即使在JDK内部,该队列也仅用于ExecutorService中的Cache Thread Pool创建(在第5章会接触到相关知识),本节只是简单了解一下SynchronousQueue的基本使用方法即可
6.LinkedTransferQueue
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列LinkedTransferQueue多了tryTransfer和transfer方法。
transfer方法 。如果当前有消费者正在等待接收元素(消费者使用take()方法或带时间限制的poll()方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail节点,并等到该元素被消费者消费了才返回。
tryTransfer方法 。则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。和transfer方法的区别是tryTransfer方法无论消费者是否接收,方法立即返回。而transfer方法是必须等到消费者消费了才返回。
对于带有时间限制的tryTransfer(E e, long timeout, TimeUnit unit)方法,则是试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待指定的时间再返回,如果超时还没消费元素,则返回false,如果在超时时间内消费了元素,则返回true。
7.LinkedBlockingDeque
LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque多了addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast等方法,以First单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一个元素。以Last单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法add等同于addLast,移除方法remove等效于removeFirst。但是take方法却等同于takeFirst,不知道是不是Jdk的bug,使用时还是用带有First和Last后缀的方法更清楚。在初始化LinkedBlockingDeque时可以初始化队列的容量,用来防止其再扩容时过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式中。
12.线程池
线程池的优点
-
降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
-
提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
-
增加线程的可管理型。线程是稀缺资源,使用线程池可以进行统一分配,调优和监控。
减少创建和销毁线程的次数,每个工作线程可以多次使用
可根据系统情况调整执行的线程数量,防止消耗过多内存
根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;少了浪费了系统资源,多了造成系统拥挤效率不高。用线程池控制线程数量,其他线程排队等候。一个任务执行完毕,再从队列的中取最前面的任务开始执行。若队列中没有等待进程,线程池的这一资源处于等待。当一个新任务需要运行时,如果线程池中有等待的工作线程,就可以开始运行了;否则进入等待队列。
为什么要用线程池 :
1.减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
2. 可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下 ( 每个线程需要大约 1MB 内存,线程开的越多,消耗的内存也就越大,最后死机 ) 。
线程池线程复用的原理
首先,线程池会有一个管理任务的队列,这个任务队列里存放的就是各种任务,线程池会一直不停循环的去查看消息队里有没有接到任务,如果没有,则继续循环,如果有了则开始创建线程,如果给这个线程池设定的容量是10个线程,那么当有任务的时候就会调用创建线程的函数方法去根据当前任务总数量依次创建线程(这里创建线程的函数方法都是你提前些好了的,在此提醒脑子没转弯过来的童鞋),线程中会写好循环获取任务队列里任务的逻辑、判断是否销毁该线程的逻辑、进入等待的逻辑,这样线程一旦创建出来就会循环的去查询任务队列里的任务,拿到任务后就执行,执行任务完毕后判断是否销毁该线程,如果不销毁就进入等待(sleep),等待时间过后继续查询消息是否有任务,如此循环,直到逻辑判断需要销毁该线程为止(一般都是根据设定时间去判断是否销毁,例如在线程创建的时候设置一个计时器去控制,如果180秒都没有接到新的任务,则销毁该线程)。
设置线程池名字是个好习惯
线程池的类继承关系:
Executor 接口 Executor (Java Platform SE 8 )
ExcutorService 线程池类 submit 比 execute 方法支持更多类型
ExecutorService (Java Platform SE 7 )
1. 提交Runnable类型任务
Submit方法除了可以提交执行Callable类型的任务之外,还可以提交Runnable类型的任务并且有两种重载形式,具体如下。
▪ public Future submit(Runnable task):提交Runnable类型的任务并且返回Future,待任务执行结束后,通过该future的get方法返回的结果始终为null。
▪ public Future submit(Runnable task, T result):前一个提交Runnable类型的任务虽然会返回Future,但是任务结束之后通过future却拿不到任务的执行结果,而通过该submit方法则可以。
2. invokeAny
ExecutorService允许一次性提交一批任务,但是其只关心第一个完成的任务和结果.
3. invokeAll
invokeAll方法同样可用于异步处理批量的任务,但是该方法关心所有异步任务的运行,invokeAll方法同样也是阻塞方法,一直等待所有的异步任务执行结束并返回结果。
ThreadPoolExecutor (Java Platform SE 7 )
ThreadPoolExecuotor 源码分析: 帐号已迁移 看Java异步编程实战2.2.2
-
ctl
ctl 代表当前线程池状态和线程池线程数量的结合体,高3位标识当前线程池运行状态,后29位标识线程数量。ctlOf方法就是rs(线程池运行状态)和wc(线程数量)按位或操作
-
COUNT_BITS
COUNT_BITS = Integer.SIZE - 3 = 29,在ctl中,低29位用于存放当前线程池中线程的数量
-
CAPACITY
CAPACITY = (1 << COUNT_BITS) - 1
我们来计算一下:
1 << 29 = 0010 0000 0000 0000 0000 0000 0000 0000
(1 << 29) - 1 = 0001 1111 1111 1111 1111 1111 1111 1111
这个属性是用来线程池能装载线程的最大数量,也可以用来做一些位运算操作。
-
线程池几种状态
RUNNING:
(1) 状态说明:线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。
(2) 状态切换:线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0
SHUTDOWN:
(1) 状态说明:线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。
(2) 状态切换:调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN
STOP:
(1) 状态说明:线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
(2) 状态切换:调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP
TIDYING:
(1) 状态说明:当所有的任务已终止,ctl记录的"任务数量"为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
(2) 状态切换:当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。
当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING
TERMINATED:
(1) 状态说明:线程池彻底终止,就变成TERMINATED状态。
(2) 状态切换:线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED
状态的变化流转:
-
runStateOf()
计算线程池运行状态的,就是计算ctl前三位的数值。`unStateOf() = c & ~CAPACITY,CAPACITY = 0001 1111 1111 1111 1111 1111 1111 1111,那么~CAPACITY = 1110 0000 0000 0000 0000 0000 0000 0000,它与任何数按位与的话都是只看这个数前三位
-
workerCountOf()
计算线程池的线程数量,就是看ctl的后29位,workerCountOf() = c & CAPACITY, CAPACITY = 0001 1111 1111 1111 1111 1111 1111 1111与任何数按位与,就是看这个数的后29位
-
ctlOf(int rs, int wt)
在获取当前线程池ctl的时候会用到,在后面源码中会有很多地方调用, 传递的参数rs代表线程池状态,wt代表当前线程次线程(worker)的数量
-
runStateLessThan(int c, int s)
return c < s,c一般传递的是当前线程池的ctl值。比较当前线程池ctl所表示的状态是否小于某个状态s
-
runStateAtLeast(int c, int s)
return c >= s,c一般传递的是当前线程池的ctl值。比较当前线程池ctl所表示的状态,是否大于等于某个状态s
-
isRunning(int c)
c < SHUTDOWN, 判断当前线程池是否是RUNNING状态,因为只有RUNNING的值小于SHUTDOWN
-
compareAndIncrementWorkerCount()/compareAndDecrementWorkerCount()
使用CAS方式 让ctl值分别加一减一 ,成功返回true, 失败返回false
-
decrementWorkerCount()
将ctl值减一,这个方法用了do…while循环,直到成功为止
-
completedTaskCount
记录线程池所完成任务总数 ,当worker退出时会将 worker完成的任务累积到completedTaskCount
-
Worker
线程池内部类,继承自AQS且实现Runnable接口。 Worker内部有一个Thread thread是worker内部封装的工作线程。 Runnable firstTask用来接收用户提交的任务数据。 在初始化Worker时候 会 设置state为-1(初始化状态),通过threadFactory创建一个线程。
-
ThreadPoolExecutor初始化参数
corePoolSize: 核心线程数限制
maximumPoolSize: 最大线程限制
keepAliveTime: 非核心的空闲线程等待新任务的时间 unit: 时间单位。配合allowCoreThreadTimeOut也会清理核心线程池中的线程。
workQueue: 任务队列,最好选用有界队列,指定队列长度
threadFactory: 线程工厂,最好自定义线程工厂,可以自定义每个线程的名称
handler: 拒绝策略,默认是AbortPolicy
ThreadPoolExecutor ExcutorService的实现类
构造函数
ThreadPoolExecutor提供了四个构造函数
//五个参数的构造函数public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue)
//六个参数的构造函数-1public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory)
//六个参数的构造函数-2public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler)
//七个参数的构造函数public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize - 池中所保存的线程数,包括空闲线程。
maximumPoolSize-池中允许的最大线程数。
keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
unit - keepAliveTime 参数的时间单位。
workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。如果使用LinkedBlockedingQueue这种无界队列。那相当于maximumPoolSize没有设置,只能用到corePoolSize个线程。
threadFactory - 执行程序创建新线程时使用的工厂。可以捕获线程抛出的异常
Java多线程——<七>多线程的异常捕捉 - brightshi - 博客园
通过这个设置UncaughtExecptionHander.
handler - 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
RejectedExecutionHandler接口
1.CallerRunsPolicy : 线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
这个策略显然不想放弃执行任务。但是由于池中已经没有任何资源了,那么就直接使用调用该 execute 的线程本身来执行。
2.AbortPolicy( 默认 ) : 处理程序遭到拒绝将抛出运行时 RejectedExecutionException
这种策略直接抛出异常,丢弃任务。
3.DiscardPolicy : 不能执行的任务将被删除
这种策略和 AbortPolicy 几乎一样,也是丢弃任务,只不过他 不抛出异常 。
4.DiscardOldestPolicy : 如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)
该策略就稍微复杂一些,在 pool 没有关闭的前提下首先丢掉缓存在队列中的最早的任务,然后重新尝试运行该任务。这个策略需要适当小心。
设想 : 如果其他线程都还在运行,那么新来任务踢掉旧任务,缓存在 queue 中,再来一个任务又会踢掉 queue 中最老任务。
5.实现RejectedExecutionHandler接口,可自定义处理器
工厂类 Executors
Executors (Java Platform SE 8 )
Executors中创建ThreadPoolExecutor的方法
newFixedThreadPool(int) 固定大小的线程池
corePoolSize N
maximumPoolSize N
线程keepAliveTime为0不会退出
缓冲的队列为LinkedBlockingQueue,大小为最大的整数。
AbortPolicy
newSingleThreadExecutor()
corePoolSize 1
maximumPoolSize 1
线程keepAliveTime为0不会退出
LinkedBlockingQueue,大小为最大的整数。
AbortPolicy
newCachedThreadPool()
corePoolSize 为0
maximumPoolSize 最大整数
KeepAliveTime为1分钟。 靠TTL来删除线程
缓存任务的队列为 SynchronousQueue 不存储元素
AbortPolicy
进阶篇:定时任务执行之ScheduledThreadPoolExecuter(十六)_打着吊瓶写代码的博客-CSDN博客
ScheduledExecutorService 延时周期执行线程池
ScheduledExecutorService (Java Platform SE 7 )
newScheduledThreadPool(int) 支持定时及周期性任务执行
corePoolSize N
maximumPoolSize 最大整数
线程keepAliveTime为0会退出
缓存任务的队列为DelayWorkQueue(最小堆)的线程池。在实际业务中,通常会有一些需要定时或延迟执行的任务。
当要执行的Runnable或Callable的task加入时,ScheduledThreadPoolExecutor会将其放入内部的DelayedWorkQueue中,DelayWorkQueue又基于DelayQueue来实现;当有新的task加入时,DelayQueue会将其加入内部的数组对象中,并进行排序。对于ScheduleThreadPoolExcecutor而言,排序的规则为执行时间,并执行时间越近的排在越前面,线程池中的线程在获取要执行的task时,方式为获取最近要执行的task,并调用condition的awaitNanos来等待唤醒。
newWorkStealingPool (int parallelism)
WorkStealingPool中的工作线程会处理任务队列中与之对应的任务分片(Divide and conquer:分而治之),如果某个线程处理的任务执行比较耗时,那么它所负责的任务将会被其他线程“窃取”执行,进而提高并发处理的效率
扩展ThreadPoolExecutor
钩子方法:
1)beforeExecute()/afterExecute():runWorker()中线程执行前和执行后会调用的钩子方法
2)terminated:线程池的状态从TIDYING状态流转为TERMINATED状态时terminated方法会被调用的钩子方法。
3)onShutdown:当我们执行shutdown()方法时预留的钩子方法。
「核心线程相关:」
-
getCorePoolSize() :获取核心线程数。
-
setCorePoolSize() :重新设置线程池的核心线程数。
-
prestartCoreThread() :预启动一个核心线程,当且仅当工作线程数量小于核心线程数量。
-
prestartAllCoreThreads() :预启动所有核心线程。
「线程池容量相关:」
「线程存活周期相关:」
「其他监控统计相关方法:」
-
getTaskCount() :获取所有已经被执行的任务总数的近似值。
-
getCompletedTaskCount() :获取所有已经执行完成的任务总数的近似值。
-
getLargestPoolSize() :获取线程池的峰值线程数(最大池容量)。
-
getActiveCount() :获取所有活跃线程总数(正在执行任务的工作线程)的近似值。
-
getPoolSize() :获取工作线程集合的容量(当前线程池中的总工作线程数)。
「任务队列操作相关方法:」
ThreadPoolExecutor支持动态调整核心线程数、最大线程数、队列长度等一些列参数吗?怎么操作?
运行期间可动态调整参数的方法:
1)setCorePoolSize():动态调整线程池核心线程数
2)setMaximumPoolSize():动态调整线程池最大线程数
3)setKeepAliveTime(): 空闲线程存活时间,如果设置了allowsCoreThreadTimeOut=true,核心线程也会被回收,默认只回收非核心线程
4)allowsCoreThreadTimeOut():是否允许回收核心线程,如果是true,在getTask()方法中,获取workQueue就采用workQueue.poll(keepAliveTime),如果超过等待时间就会被回收。
ThreadPoolExecutor的运行机制:
线程池的运行状态:
生命周期转换:
任务执行机制
任务调度
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。
首先,所有任务的调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下:
-
首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
-
如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
-
如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
-
如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
-
如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
其执行流程如下图所示:
任务缓冲
任务缓冲模块是线程池能够管理任务的核心部分。线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
阻塞队列( BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
下图中展示了线程1往阻塞队列中添加元素,而线程2从阻塞队列中移除元素:
使用不同的队列可以实现不一样的任务存取策略。在这里,我们可以再介绍下阻塞队列的成员:
队列选择: ThreadPoolExecutor线程池的使用与理解 - 每一个程序员都有一个大梦想
使用SynchronousQueue也会触发拒绝策略
任务申请
由上文的任务分配部分可知,任务的执行有两种可能:一种是任务直接由新创建的线程执行。另一种是线程从任务队列中获取任务然后执行,执行完任务的空闲线程会再次去从队列中申请任务再去执行。第一种情况仅出现在线程初始创建的时候,第二种是线程获取任务绝大多数的情况。
线程需要从任务缓存模块中不断地取任务执行,帮助线程从阻塞队列中获取任务,实现线程管理模块和任务管理模块之间的通信。这部分策略由getTask方法实现,其执行流程如下图所示:
getTask这部分进行了多次判断,为的是控制线程的数量,使其符合线程池的状态。如果线程池现在不应该持有那么多线程,则会返回null值。工作线程Worker会不断接收新任务去执行,而当工作线程Worker接收不到任务的时候,就会开始被回收。
任务拒绝
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
拒绝策略是一个接口,其设计如下:
用户可以通过实现这个接口去定制拒绝策略,也可以选择JDK提供的四种已有拒绝策略,其特点如下:
ThreadPoolExecutor的策略
-
线程数量未达到corePoolSize,则新建一个线程(核心线程)执行任务
-
线程数量达到了corePools,则将任务移入队列等待
-
队列已满,新建线程(非核心线程)执行任务
-
队列已满,总线程数又达到了maximumPoolSize,就会由上面那位星期天(RejectedExecutionHandler)抛出异常
corePoolSize 一旦达到 不会因为超过keep-alive 达到而减小到少于这个值的线程数。
线程池的关闭
ThreadPoolExecutor提供了两个方法,用于线程池的关闭,分别是shutdown()和shutdownNow(),其中:
-
shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务
-
shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列, 返回尚未执行的任务
-
awaitTermination(long timeOut, TimeUnit unit) 当前线程阻塞,直到等所有已提交的任务(包括正在跑的和队列中等待的)执行完 或者等超时时间到或者线程被中断,抛出InterruptedException 然后返回true(shutdown请求后所有任务执行完毕)或false(已超时)
最大的区别就是shutdown()会将线程池状态变为SHUTDOWN,此时新任务不能被提交,workQueue中还存有的任务可以继续执行,同时会像线程池中空闲的状态发出中断信号。
shutdownNow()方法是将线程池的状态设置为STOP,此时新任务不能被提交,线程池中所有线程都会收到中断的信号。如果线程处于wait状态,那么中断状态会被清除,同时抛出InterruptedException。
推荐的线程池关闭方式: ExecutorService (Java Platform SE 8 )
通常情况下,为了确保线程池被尽可能安全地关闭,我们会采用两种关闭线程池的组合方式,以尽可能确保正在运行的任务被正常执行的同时又能提高线程池被关闭的成功率。
void shutdownAndAwaitTermination(ExecutorService executor,
long timeout, TimeUnit unit){ // 首先执行executor的立即关闭方法 executor.shutdown(); try { // 如果在指定时间内线程池仍旧未被关闭 if (!executor.awaitTermination(timeout, unit)) { // 则执行立即关闭方法,排干任务队列中的任务 executor.shutdownNow(); // 如果线程池中的工作线程正在执行一个非常耗时且不可中断的方法,则中断失败 if (!executor.awaitTermination(timeout, unit))
{ // print executor not terminated by normal
. } } } catch (InterruptedException e) { // 如果当前线程被中断,并且捕获了中断信号,则执行立即关闭方法 executor.shutdownNow(); // 重新抛出中断信号 Thread.currentThread().interrupt(); }}
线程池容量的动态调整
ThreadPoolExecutor提供了动态调整线程池容量大小的方法:setCorePoolSize()和setMaximumPoolSize(),
Worker线程管理
Worker线程
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker。我们来看一下它的部分代码:
Worker这个工作线程,实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务;firstTask用它来保存传入的第一个任务,这个任务可以有也可以为null。如果这个值是非空的,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况;如果这个值是null,那么就需要创建一个线程去执行任务列表( workQueue)中的任务,也就是非核心线程的创建。
Worker执行任务的模型如下图所示:
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。线程池使用一张Hash表去持有线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期。这个时候重要的就是如何判断线程是否在运行。
Worker是通过继承AQS,使用AQS来实现独占锁这个功能。没有使用可重入锁ReentrantLock,而是使用AQS,为的就是实现不可重入的特性去反应线程现在的执行状态。
-
lock方法一旦获取了独占锁,表示当前线程正在执行任务中。
-
如果正在执行任务,则不应该中断线程。
-
如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。
-
线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。
在线程回收过程中就使用到了这种特性,回收过程如下图所示:
Worker线程增加
增加线程是通过线程池中的addWorker方法,该方法的功能就是增加一个线程,该方法不考虑线程池是在哪个阶段增加的该线程,这个分配线程的策略是在上个步骤完成的,该步骤仅仅完成增加线程,并使它运行,最后返回是否成功这个结果。addWorker方法有两个参数:firstTask、core。firstTask参数用于指定新增的线程执行的第一个任务,该参数可以为空;core参数为true表示在新增线程时会判断当前活动线程数是否少于corePoolSize,false表示新增线程前需要判断当前活动线程数是否少于maximumPoolSize,其执行流程如下图所示:
Worker线程回收
线程池中线程的销毁依赖JVM自动的回收,线程池做的工作是根据当前线程池的状态维护一定数量的线程引用,防止这部分线程被JVM回收,当线程池决定哪些线程需要回收时,只需要将其引用消除即可。Worker被创建出来后,就会不断地进行轮询,然后获取任务去执行,核心线程可以无限等待获取任务,非核心线程要限时获取任务。当Worker无法获取到任务,也就是获取的任务为空时,循环会结束,Worker会主动消除自身在线程池内的引用。
线程回收的工作是在processWorkerExit方法完成的。
事实上,在这个方法中,将线程引用移出线程池就已经结束了线程销毁的部分。但由于引起线程销毁的可能性有很多,线程池还要判断是什么引发了这次销毁,是否要改变线程池的现阶段状态,是否要根据新状态,重新分配线程。
Worker线程执行任务
在Worker类中的run方法调用了runWorker方法来执行任务,runWorker方法的执行过程如下:
-
while循环不断地通过getTask()方法获取任务。
-
getTask()方法从阻塞队列中取任务。
-
如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态。
-
执行任务。
-
如果getTask结果为null则跳出循环,执行processWorkerExit()方法,销毁线程。
执行流程如下图所示:
http://www.importnew.com/17633.html
调整线程池的大小_云想慕尘的博客-CSDN博客
如何合理配置线程池大小
任务一般分为:CPU密集型、IO密集型、混合型,对于不同类型的任务需要分配不同大小的线程池
1、CPU密集型
尽量使用较小的线程池,一般Cpu核心数+1
因为CPU密集型任务CPU的使用率很高,若开过多的线程,只能增加线程上下文的切换次数,带来额外的开销
2、IO密集型
方法一:可以使用较大的线程池,一般CPU核心数 * 2
IO密集型CPU使用率不高,可以让CPU等待IO的时候处理别的任务,充分利用cpu时间
方法二:线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
下面举个例子:
比如平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为8,那么根据上面这个公式估算得到:((0.5+1.5)/0.5)*8=32。这个公式进一步转化为:
最佳线程数目 = (线程等待时间与线程CPU时间之比 + 1)* CPU数目
3、混合型
可以将任务分为CPU密集型和IO密集型,然后分别使用不同的线程池去处理,按情况而定
排队有三种通用策略:
直接提交。工作队列的默认选项是 SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
有界队列。 当使用有限的 maximumPoolSizes 时,有界队列(如 ArrayBlockingQueue )有助于 防止资源耗尽 ,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小, CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
最好使用ThreadPoolExecutor来创建线程,不要使用Executors类
Spring线程池 https://docs.spring.io/spring/docs/4.3.12.BUILD-SNAPSHOT/spring-framework-reference/htmlsingle/#scheduling-task-executor
TastExecutor 接口实现
-
SimpleAsyncTaskExecutor This implementation does not reuse any threads, rather it starts up a new thread for each invocation. However, it does support a concurrency limit which will block any invocations that are over the limit until a slot has been freed up. If you are looking for true pooling, see the discussions of SimpleThreadPoolTaskExecutor and ThreadPoolTaskExecutor below.
-
SyncTaskExecutor This implementation doesn’t execute invocations asynchronously. Instead, each invocation takes place in the calling thread. It is primarily used in situations where multi-threading isn’t necessary such as simple test cases.
-
ConcurrentTaskExecutor This implementation is an adapter for a java.util.concurrent.Executor object. There is an alternative, ThreadPoolTaskExecutor , that exposes the Executor configuration parameters as bean properties. It is rare to need to use the ConcurrentTaskExecutor , but if the ThreadPoolTaskExecutor isn’t flexible enough for your needs, the ConcurrentTaskExecutor is an alternative.
-
SimpleThreadPoolTaskExecutor This implementation is actually a subclass of Quartz’s SimpleThreadPool which listens to Spring’s lifecycle callbacks. This is typically used when you have a thread pool that may need to be shared by both Quartz and non-Quartz components.
-
ThreadPoolTaskExecutor This implementation is the most commonly used one. It exposes bean properties for configuring a java.util.concurrent.ThreadPoolExecutor and wraps it in a TaskExecutor . If you need to adapt to a different kind of java.util.concurrent.Executor , it is recommended that you use a ConcurrentTaskExecutor instead. ThreadPoolTaskExecutor 相比java的 ThreadPoolExecutor,感觉就是把参数从构造函数移动到了property上。waitForTasksToCompleteOnShutdown属性设置容器关闭时是否等待线程执行完毕。
-
WorkManagerTaskExecutor
CommonJ is a set of specifications jointly developed between BEA and IBM. These specifications are not Java EE standards, but are standard across BEA’s and IBM’s Application Server implementations.
This implementation uses the CommonJ WorkManager as its backing implementation and is the central convenience class for setting up a CommonJ WorkManager reference in a Spring context. Similar to the SimpleThreadPoolTaskExecutor , this class implements the WorkManager interface and therefore can be used directly as a WorkManager as well.
CompletionService
CompletionService很好地解决了异步任务的问题,在CompletionService中提供了提交异步任务的方法(真正的异步任务执行还是由其内部的ExecutorService完成的),任务提交之后调用者不再关注Future,而是从BlockingQueue中获取已经执行完成的Future,在异步任务完成之后Future才会被插入阻塞队列,也就是说调用者从阻塞队列中获取的Future是已经完成了的异步执行任务,所以再次通过Future的get方法获取结果时,调用者所在的当前线程将不会被阻塞。示例代码如下:
在了解了CompletionService的基本使用场景之后,我们再来看一下它的其他方法和构造方式。
▪ CompletionService的构造:CompletionService并不具备异步执行任务的能力,因此要构造CompletionService则需要ExecutorService,当然还允许指定不同的BlockingQueue实现。
· ExecutorCompletionService(Executor executor):BlockingQueue默认为LinkedBlockingQueue(可选边界)。
· ExecutorCompletionService(Executor executor,BlockingQueue> completionQueue):允许在构造时指定不同的BlockingQueue。
▪ 提交Callable类型的任务:已经通过示例进行了说明。
Future submit(Callable task)
▪ 提交Runnable类型的任务:除了提交Callable类型的任务之外,在CompletionService中还可以提交Runnable类型的任务,但是返回结果仍旧需要在提交任务方法时指定。
下面通过一段代码来了解下如何在CompletionService中提交Runnable类型的任务。
▪ 立即返回方法Future poll():从CompletionService的阻塞队列中获取已执行完成的Future,如果此刻没有一个任务完成则会立即返回null值。
▪ Future poll(long timeout, TimeUnit unit):同上,指定了超时设置。
▪ 阻塞方法Future take() throws InterruptedException:会使当前线程阻塞,直到在CompletionService中的阻塞队列有完成的异步任务Future。
ThreadLocal
JVM中维护着一个Map,key为当前线程对象,value 为TheadLocal set的变量。
ThreadLocal (Java Platform SE 7 )
面试官:听说你精通并发编程,来说说你对ThreadLocal的理解
源码分析: ThreadLocal到底有没有内存泄漏?从源码角度来剖析一波
ThreadLocal内存结构图:
由结构图是可以看出:
-
Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,即每个线程都有一个属于自己的ThreadLocalMap。
-
ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型值。
-
每个线程在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
InheritableThreadLocal 继承ThreadLoacal,它自动为子线程复制一份从父线程那里继承而来的本地变量。
ThreadLocal的问题:
在set方法中,有一个重要的作用就是 「防止内存泄漏」 ,在set中分别调用了 replaceStaleEntry() 和 cleanSomeSlots() 方法,两者的作用分别如下:
-
replaceStaleEntry :当判断到key为null,但是存在值说明,之前的key(ThreadLocal对象)被清除掉,但是内存一直占用着,就用新的元素替换掉旧的元素。
-
cleanSomeSlots :则清除掉原来key == null的Entry。
在说ThreadLocal内存泄漏的解决的方案之前,先来说说造成内存泄漏的原因,这里我画了一张图:
在Thread有一个ThreadLocalMap的引用,而ThreadLocalMap的key在源码中可以看出是ThreadLocal的对象。
但是ThreadLocal是一个弱引用,在垃圾回收的时候会被回收掉。 「什么是弱引用呢?」 弱引用就是被弱引用关联的对象只能存活到下一次垃圾收集发生之前。当垃圾收集器工作时,弱引用关联的对象都会被回收。
但是 「ThreadLocalMap的生命周期和Thread是一样」 的,它不会被回收掉,所以就会存在有引用指向Entry对象。
若是线程一直不结束,就会一直存在一条引用链: ThreadLocalRef->Thread->ThreadLocal->ThreadLocalMap->Entry->value , 「导致ThreadLocalMap中的key没有了,但是value还存在,这就造成了内存泄漏」 。
此时若是key值的引用ThreadLocal对象被回收掉,就无法通过key获取对象,就会存在内存中又无法使用。
在ThreadLocal里面为了防止内存泄漏的情况,在新增、移除、获取的时候,都会去查出key==null的entry对象。
所以为了避免内存的泄漏, 「每次使用完ThreadLocal时候都养成调用remove方法」 来擦出数据的习惯,即时的清理出干净的内存。
发布对象:使一个对象能够被当前范围之外代码所使用。
对象逸出:一种错误的发布。当一个对象还没有构造完成,就能被其它线程所见。
安全发布对象:
Fork/Join ForkJoinPool
有两个特型:
1.可以用于高效地处理细分任务。
2.它实现了工作窃取(work-strealing)算法。
并行执行任务,即把大任务分割成若干小任务并行执行,最后汇总成大任务结果的框架。
https://docs.oracle.com/javase/tutorial/essential/concurrency/forkjoin.html
JAVA并行框架:Fork/Join - 冬瓜蔡 - 博客园
谈谈ForkJoin框架的设计与实现
JDK用来执行Fork/Join任务的工作线程池大小等于CPU核心数。
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
if (任务足够小){
直接执行该任务;
} else{
将任务一分为二;
执行这两个任务并等待结果;
}
ForkJoinTask 的两个子类型: RecursiveTask(可以返回一个结果)或RecursiveAction
Phaser是在JDK 1.7版本中才加入的。Phaser同样也是一个多线程的同步助手工具,它是一个可被重复使用的同步屏障,它的功能非常类似于本章已经学习过的CyclicBarrier和CountDownLatch的合集,但是它提供了更加灵活丰富的用法和方法,同时它的使用难度也要略微大于前两者。相较于这两者,Phaser具有可动态改变的分片(partities)以及可被多次使用的特性等。
在《Java高并发编程详解:多线程与架构设计》一书中,曾详细介绍了Thread。Thread中存在着一定的层级关系,也就是说某一个Thread类会有一个父Thread,同样在定义Phaser的时候也可以为其指定父Phaser,当我们在创建某个Phaser的时候若指定了父Phaser,那么它将具有如下这些特性。