机器学习(二)决策树的比较以房屋价格预测为例续-----计算特征的相对重要性
以房屋价格预测为例续-----计算特征的相对重要性
-
- 实验内容
- 实验步骤
- 源代码
- 实验结果
- 总结
实验内容
在1.9节使用普通的决策树回归器和带AdaBoost算法的决策树回归器预测房屋价格的基础上,判断13个特征中哪个特征对结果的影响最大
实验步骤
(1) 创建一个新的Python文件housing.py,然后加入下面的代码
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn import datasets
from sklearn.metrics import mean_squared_error,explained_variance_score
from sklearn.utils import shuffle
import matplotlib.pyplot as plt
(2) 使用scikit-learn上数据接口加载网上的标准房屋价格数据库
housing_data = datasets.load_boston()# 加载数据
(3) 接下来把输入数据与输出结果分成不同的变量。我们可以通过shuffle函数把数据的顺 序打乱:
X, y = shuffle(housing_data.data, housing_data.target, random_state=7)# random_state 控制如何打乱数据
(4) 接下来把数据 分成训练数据集和测试数据集,其中80%的数据用于训练,剩余20%的数据用于测试:
num_training = int(0.8*len(X))
X_train, y_train = X[:num_training], y[:num_training]
X_test, y_test = X[num_training:], y[num_training:]
(5) 现在已经可以拟合一个决策树回归模型了。选一个最大深度为4的决策树,这样可以限制 决策树不变成任意深度:
dt_regressor = DecisionTreeRegressor(max_depth=4)
dt_regressor.fit(X_train, y_train)
(6) 再用带AdaBoost算法的决策树回归模型进行拟合
ab_regressor = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4),
n_estimators=400, random_state=7)
# 第一个参数是基分类器,n_estimators 基分类器循环次数,random_state随机种子设置
ab_regressor.fit(X_train, y_train)
(7) 定义一个函数plot_feature_importances来画出条形图
def plot_feature_importances(feature_importances, title, feature_names):
# Normalize the importance values
feature_importances = 100.0 * (feature_importances / max(feature_importances))
# Sort the values and flip them
index_sorted = np.flipud(np.argsort(feature_importances))
# Arrange the X ticks
pos = np.arange(index_sorted.shape[0]) + 0.5
# Plot the bar graph
plt.figure()
plt.bar(pos, feature_importances[index_sorted], align='center')
plt.xticks(pos, feature_names[index_sorted])
plt.ylabel('Relative Importance')
plt.title(title)
plt.show()
(8) 画出特征的相对重要性
# 画出特征的相对重要性
plot_feature_importances(dt_regressor.feature_importances_,
'Decision Tree regressor', housing_data.feature_names)
plot_feature_importances(ab_regressor.feature_importances_,
'AdaBoost regressor', housing_data.feature_names)
源代码
链接:https://pan.baidu.com/s/1HDGkKWiE3Sqig8ACBsLuOg
提取码:f64x
复制这段内容后打开百度网盘手机App,操作更方便哦
实验结果
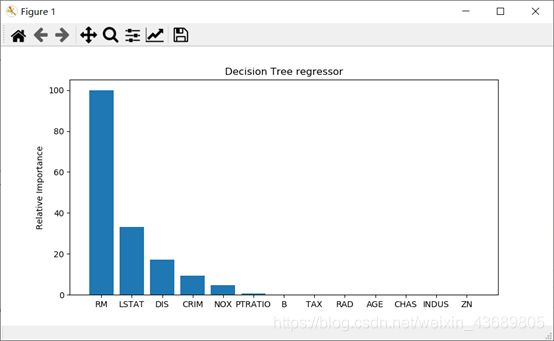

总结
- 可以看出两种决策树得出的最重要的特征不一样。在普通决策树中,RM是主要决定房屋价格的特征,而在AdaBoost决策树中,LSTAT是决定房屋价格的主要特征。
- 相比于普通的决策树,带AdaBoost的决策树得出的结论更符合实际情况。