自动获取微信公众号微信文章信息(每日自动推送)
自动获取微信公众号微信文章信息
- 目录
-
前言
一、获取文章列表
1.影刀自动登录微信
1、安装mitmproxy
2、配合切换代理脚本,实现请求是否通过mitmproxy
4、脚本使用方法
总结
前言
使用工具:影刀、mitmproxy、飞书api
需求说明:每天自动监测所关注的公众号在前一天所发文章的信息(标题、发布时间、是否原创、阅读量、点赞数、在看等),推送至相应飞书群中。
接到需求是首先想到的是搜狗微信,但是发现搜狗微信现在已经没办法看到公众号文章的列表页了,同样的文章内容里,也无法看到点赞量、浏览量等数据,已经不能像几年前一样,通过搜狗微信获取数据了,此路不通。排雷!
文章中的浏览量等数据,目前只能在微信中打开链接才能看到,在浏览器中打开是看不到这些数据的。于是我尝试抓包。
最开始使用的是fiddler进行抓包
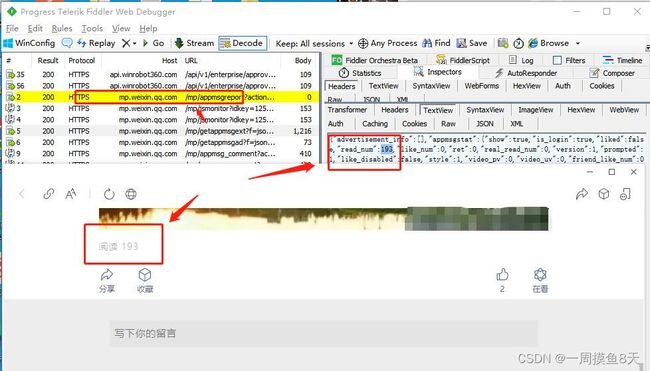
在微信的接口中发现了这些数据,于是思路就来了。
HTTPS协议,那么肯定是requests就能解决了哇~
在这之前还要找到获取公众号文章列表的页面,经过一系列摸索,发现可以通过拼接url的形式找到这个页面:
通过抓包也能找到文章列表,可以获取到文章url以及发布时间、标题等数据,如果不需要点赞数、阅读量等数据的话,到这里就可以结束了。
一、获取文章列表
代码如下(示例):
import json
import re
import time
import requests请求文章列表页:
通过拼接url进行访问公众号文章列表页,需要获取公众号biz值,可通过抓包,打开公众号的一篇文章,在该url中截取biz值,每个公众号的biz值不同。请求示例如下:(ua为PC端微信的ua)
url = 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz={}&scene=124#wechat_redirect'.format(biz)
headers = {
'Host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6307062c)',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': cookie,
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7'
}发送请求,打印出返回结果:
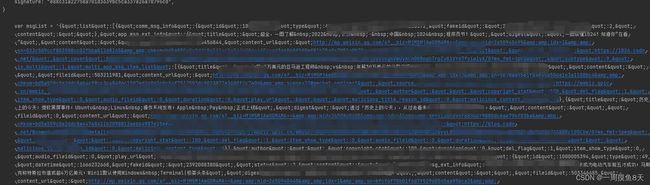
通过正则取出我们需要的数据:
str1 = re.findall("var msgList = '\{(.*?)]}';", response.text)[0]
str2 = '{' + str1 + ']}'发现在数据中掺杂了很多"、 这种html转义符,使用replace进行替换之后转为json:
str2 = str2.replace('"', '"')
str2 = str2.replace(' ', ' ')
str2 = str2.replace('&', '&')
str2 = str2.replace('&', '&')
str2 = str2.replace(''', "'")
json1 = json.loads(str2)接着就可以在json中进行数据提取了。
获取到需要的title、datetime、content_url(文章url)
二、自动化获取微信公众号cookie
1.影刀自动登录微信
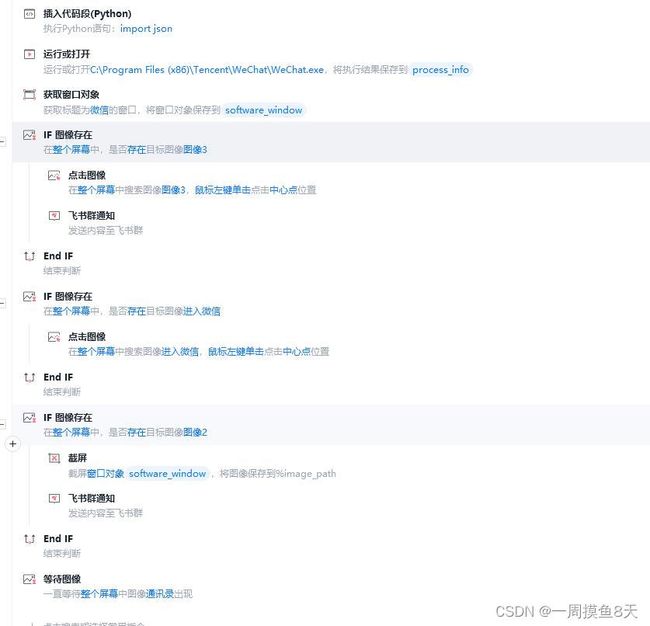
思路:自动打开微信.exe,通过图像识别判断需要的操作
新版微信可以免扫码登录,前提是扫码登录时勾选->自动登录该设备,且之后没有登录其他账号。

如果需要扫码登录,则截图,通过飞书机器人,将截图发送至联系人,远程扫码登录。
如果需要手机微信确认登录,则同理,通过飞书机器人发送信息至联系人,远程操作。
具体流程如下:(飞书发送消息指令,可使用影刀自带指令完成。)
2.获取公众号cookie
1、安装mitmproxy
下载方式:可以通过 pip instally mitmproxy 进行安装,也可以通过安装包进行安装,安装包下载地址:Downloads
具体安装步骤可以参考一下两个文章:
https://blog.csdn.net/agrapea/article/details/124660959?
https://blog.csdn.net/liujingliuxingjiang/article/details/121633927?
2、配合切换代理脚本,实现请求是否通过mitmproxy
因为如果要使用mitmproxy需要打开本地代理,127.0.0.1:8080,但是使用requests发送请求时,如果代理是打开状态,则会报错:
requests.exceptions.ProxyError:
HTTPSConnectionPool(host='mp.weixin.qq.com', port=443):
Max retries exceeded with url: /mp/profile_ext?action=home&__biz=&scene=124 (Caused by ProxyError('Cannot connect to proxy.', OSError('Tunnel connection failed: 502 Bad Gateway')))解决办法,在使用requests发送请求前,可以通过修改代理的办法,关闭代理,在发送请求即可,切换代理办法可以参考以下文章:Python 实现windows下自动切换代理IP_fengleitao的博客-CSDN博客
以及一个更简单的办法,设置proxy,不通过代理请求:
proxies = {
'http': None,
'https': None
}
response = requests.get(url, headers=headers, verify=False, proxies=proxies)3、使用mitmproxy脚本,截获公众号文章列表页请求的cookie,入库等待调用
注意:每个公众号的cookie都不一样,每个公众号都需要单独获取cookie。
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow):
self.num = self.num + 1
info = ctx.log.info
ctx.log.info("We've seen %d flows" % self.num)
if 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=' in flow.request.pretty_url:
info(flow.request.pretty_url)
cookies = str(flow.request.cookies)
cookie = cookies.replace('MultiDictView[', '')[:-1]
cookie1 = cookie.replace('], [', ';')
cookie = cookie1.replace("', '", "=")
cookie = cookie.replace("'", '').replace('[', '').replace(']', '')
info(str(cookie))
addons = [Counter()]4、脚本使用方法
控制台输入
mitmdump -s .\anatomy.py即可启用脚本,当你打开文章列表页时,会自动打印出该页面cookie,可自行增加入库方法进行入库。
5、通过影刀自动在微信端点击链接结合mitmproxy获取cookie
提前拼接好要点击的公众号的文章列表页url:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz={公众号的biz值}&scene=124

判断cookie是否入库,没有就点刷新即可。
获取到cookie就可以使用requests去获取数据啦~
获取点赞数和阅读量、在看数据的方法后边再说吧。。累了。。
总结
因为每天需要推送的公众号不多,所以可以写死的地方都写死了,只是提供一个思路,当然不是最优解,大佬们可以看着玩玩哈。