论文阅读:Cross Attention Network for Few-shot Classification
论文:Cross Attention Network for Few-shot Classification
地址:https://arxiv.org/abs/1910.07677v1
code:https://github.com/blue-blue272/fewshot-CAN
来源:NeurIPS 2019
Abstract
小样本分类的目标是根据少数标注的样本去识别该类别,其中未知类别(训练类别和测试类别的不一致)和少样本数据是两个关键问题。针对这两个问题,我们提出了一个新的交互注意力网络。首先,我们引进了一个交互注意力模块去处理未知类别的问题。该模块对于每个输入的图像对生成一对注意力图去强调目标物体所在的区域,从而使提取的特征更具有判别性。其次,我们引进了一个新的直推式推理算法去缓解小样本问题。我们提出的直推式算法迭代地利用未标注的数据去扩充标注的数据,从而使提取的类别特征更加鲁邦。在现有的多个数据集上,我们提出的框架都优于当前最好的方法。
少样本分类任务目的在于从没有见过的类别中通过少量带有标签的数据对无标签的数据进行分类。两个主要的挑战为:一是类别没有见过,二是数据非常少。目前的存在的方法主要是分别从带标签样本和无标签样本中进行特征提取,导致特征并不具有很强的区分性。作者提出了新的Cross Attention Network。针对第一个挑战作者提出了CAM(Cross Attention Module),通过support set和query set生产交叉注意力,为了更好的将注意力集中在目标物体上。针对第二个问题,作者提出了transductive inference 算法,通过重复使用无标签的query set 来增强support set,是的类特征更加具有表现性。作者在miniimagenet和tieredImageNet数据集上进行了实验,取得了sota的效果。
Introduction
少样本分类任务具有两大挑战:一是,训练集和测试集的类别是不重合的,在一部分类别上进行训练,然后在另一部分类别中测试。二是,support set里面带标签数据是比较少的。因此需要在一部分类别里训练模型,使得模型有足够好的泛化性,在未见过的测试集中仍然可以实现较好的效果。使用预训练的模型进行微调会导致过拟合,正则化和数据增强可以缓解过拟合,但是无法完全解决。现在的主流方法是采用元学习(Meta-Learning)。在meta-learning中,可以迁移的meta-knowledge包括:优化策略(optimization strategy),初始化条件(initial condition),度量空间(metric space)。可以很好的从训练任务中归纳到新的测试任务中。在训练和测试阶段通常采用相同的设置来提高泛化性。

第一个问题:在训练阶段识别的是人和椅子,在测试阶段实际预测的是窗帘,由于窗帘在训练阶段没有出现过,因此在预测的时候通常把注意力放在了人和椅子上面,注意力很难在目标物体上。第二个问题:测试阶段带标签数据较少,难以反映真实的类别分布。
作者在论文中提出了CAN(cross attention network),其中CAM(cross attention module)针对第一个问题处理未知类别问题。CAM为了强调目标可以生成交互注意力图。如图e所示,将注意力放在了窗帘上。第二点,作者提出了直推式算法(transductive inferemce algorithm)利用未标注数据去扩充标注数据以缓解数据少的问题。
Related Work
作者分别介绍了few-shot 分类,transductive 算法和attention。
Cross Attention Module
少样本学习分类任务的关键就是如何表示support set中的每一类 S K S^K SK和查询样例 x b q x_b^q xbq,以及他们之间的相似度。

P k P^k Pk代表一类样本的特征图, Q b Q^b Qb代表一个查询样本的特征图。
Correlation Layer:
将 P k P^k Pk和 Q b Q^b Qb reshape成KaTeX parse error: Undefined control sequence: \time at position 4: (c \̲t̲i̲m̲e̲ ̲m),其中KaTeX parse error: Undefined control sequence: \time at position 5: m=h \̲t̲i̲m̲e̲ ̲w,m表示特征图的空间点。将 P P P和 Q Q Q中对应的点利用cos距离计算语义相关性。
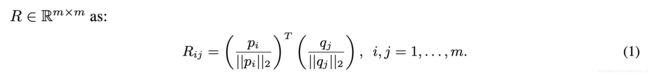
class correlation map: R p = R T = [ r 1 p , r 2 p , … , r m p ] R^p = R^T = [r_1^p,r_2^p,\dots,r_m^p] Rp=RT=[r1p,r2p,…,rmp]
query correlation map: R q = R = [ r 1 q , r 2 q , … , r m q ] R^q = R = [r_1^q,r_2^q,\dots,r_m^q] Rq=R=[r1q,r2q,…,rmq]
Meta Fusion Layer
这里主要神根据上面交互attention ( R R R)分别生成类和查询的attention map( A p A^p Ap and A q A^q Aq)。
Meta Fusion Layer使用了核为 m × 1 m \times 1 m×1的卷积操作,然后通过softmax生成相应的attention map。

A i p A_i^p Aip为第i个位置的attention值。本文的加权聚合应该将注意力吸引到目标对象上,而不是简单地突出显示支持集和查询集之间在视觉上相似的区域。
![]()
GAP: global average pooling
W 1 W_1 W1是通过卷积操作吧通道数减少, W 2 W_2 W2是通过卷积操作把通道数变回来, σ \sigma σ是ReLU。
对于任意一对类特征和查询特征,元学习器期望通过 w w w将交互注意力放在目标对象上。
Cross Attention Network
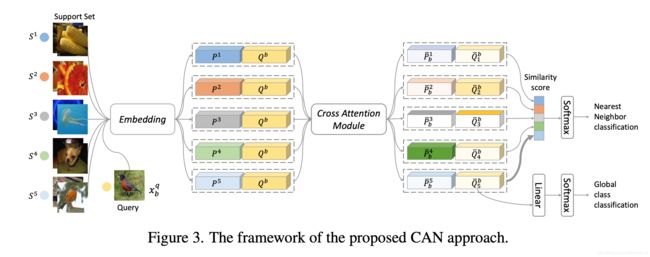
网络结构主要分为3个模块,分别是embedding模块,交互注意力模块和分类模块。
Loss 设计
Loss的设计分为两部分,一部分是局部loss,也就是在一个task中分类的loss,另一部分是全局loss,也就是所对应的全部标签的loss。
L = λ L 1 + L 2 L = \lambda L_1+L_2 L=λL1+L2
局部Loss
为了保证注意力映射的正确性,这里通过相似度计算特征图中的每一个点所对应的分类。查询特征中第 i i i个位置分为 k k k类的概率计算如下:

L1 loss计算如下:

全局Loss

其中 z i b = s o f t m a x ( W c ( Q y b q b ) i ) z_i^b =softmax(W_c(Q^b_{y^q_b})_i) zib=softmax(Wc(Qybqb)i), l b q ∈ { 1 , 2 , … , l } l_b^q \in \{1,2,\dots,l \} lbq∈{1,2,…,l}为真实的标签, z i b z_i^b zib为预测的标签的概率。 W c ∈ R l × c W_c \in \mathbb{R^{l \times c}} Wc∈Rl×c为全连接层的参数。
Transductive Inference
使用部分未标注数据来表示类特征。在一个task中,未标注数据的类别属于标注数据中的类别,因此可以现将未标注数据进行分类,这样就相当于所有的数据都是标注的,然后利用全部的数据表示类特征。
之前的类特征表示如下所示:

使用了未标注数据之后的类特征表示如下:

与之前的改变就是利用了未标注数据中置信度高的数据,这里为候选集 D D D。具体细节大家可以参考论文。
Experiments
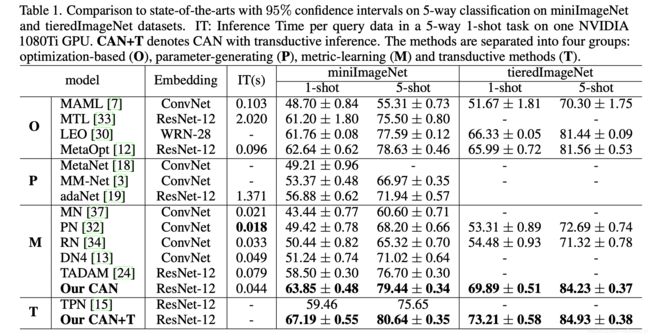
作者在miniImageNet和tieredImageNet数据集上进行了实验。
参考
小样本学习-Cross Attention Network