MMYOLO | YOLO 系列算法开源工具箱推荐----玩转 MMYOLO 工具类第一期: 特征图可视化
轻松玩转 MMYOLO, YOU ONLY LOOK this ONE
MMYOLO 是一个基于 PyTorch 和 MMDetection 的 YOLO 系列算法开源工具箱。它是 OpenMMLab 项目的一部分。
项目链接:GitHub - open-mmlab/mmyolo: OpenMMLab YOLO series toolbox and benchmark
文章转载自:玩转 MMYOLO 工具类第一期: 特征图可视化 | 作者:深度眸
主要特性有:
-
统一便捷的算法评测
MMYOLO 统一了各类 YOLO 算法模块的实现, 并提供了统一的评测流程,用户可以公平便捷地进行对比分析。
-
丰富的入门和进阶文档
MMYOLO 提供了从入门到部署到进阶和算法解析等一系列文档,方便不同用户快速上手和扩展。
-
模块化设计
MMYOLO 将框架解耦成不同的模块组件,通过组合不同的模块和训练测试策略,用户可以便捷地构建自定义模型。
-
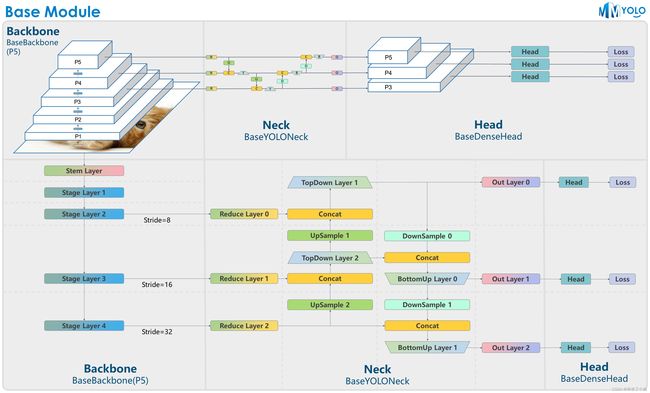
更多细节可以在GitHub链接查看,下面介绍 MMYOLO 里的强大工具之一,特征图可视化。
配套视频链接:玩转 MMYOLO 之工具篇(一):特征图可视化
如果觉得 MMYOLO 好用的话,欢迎 star !
本期讲解特征图可视化。
本教程对应代码: https://github.com/open-mmlab/mmyolo/blob/main/demo/featmap_vis_demo.py
本教程对应 jupter notebook
由于 MMYOLO 和 OpenMMLab 在不断更新迭代,如果未来直接运行本脚本出错,请及时更新到最新代码或者锁定版本。
MMYOLO 环境安装
pip install openmim
mim install "mmengine>=0.2.0"
mim install "mmcv>=2.0.0rc1,<2.1.0"
mim install "mmdet>=3.0.0rc1,<3.1.0"
git clone https://github.com/open-mmlab/mmyolo.git
cd mmyolo
# Install albumentations
pip install -r requirements/albu.txt # YOLOv5 需要
# Install MMYOLO
mim install -v -e .MMEngine 特征图可视化使用
MMEngine 官方地址:
https://github.com/open-mmlab/mmengine
特征图可视化功能较多,目前不支持 batch 输入,为了方便理解,将其对外接口梳理如下:
@staticmethod
def draw_featmap(featmap: torch.Tensor, # 输入格式要求为 CHW
overlaid_image: Optional[np.ndarray] = None,
# 如果同时输入了 image 数据,则特征图会叠加到 image 上绘制
channel_reduction: Optional[str] = 'squeeze_mean',
# 多个通道压缩为单通道的策略
topk: int = 10, # 可选择激活度最高的 topk 个特征图显示
arrangement: Tuple[int, int] = (5, 2), # 多通道展开为多张图时候布局
resize_shape:Optional[tuple] = None,
# 可以指定 resize_shape 参数来缩放特征图
alpha: float = 0.5) -> np.ndarray: # 图片和特征图绘制的叠加比例其功能可以归纳如下
- 输入的 Tensor 一般是包括多个通道的,channel_reduction 参数可以将多个通道压缩为单通道,然后和图片进行叠加显示
squeeze_mean将输入的 C 维度采用 mean 函数压缩为一个通道,输出维度变成 (1, H, W)select_max从输入的 C 维度中先在空间维度 sum,维度变成 (C, ),然后选择值最大的通道None表示不需要压缩,此时可以通过 topk 参数可选择激活度最高的 topk 个特征图显示
- 在 channel_reduction 参数为 None 的情况下,topk 参数生效,其会按照激活度排序选择 topk 个通道,然后和图片进行叠加显示,并且此时会通过 arrangement 参数指定显示的布局
- 如果 topk 不是 -1,则会按照激活度排序选择 topk 个通道显示
- 如果 topk = -1,此时通道 C 必须是 1 或者 3 表示输入数据是图片,否则报错提示用户应该设置
channel_reduction来压缩通道。
- 考虑到输入的特征图通常非常小,函数支持输入
resize_shape参数,方便将特征图进行上采样后进行可视化。
一个非常非常重要的点要强调:当图片和特征图尺度不一样时候,draw_featmap 函数会自动进行上采样对齐。如果你的图片在推理过程中前处理存在类似 Pad 的操作此时得到的特征图也是 Pad 过的,那么直接上采样就可能会出现不对齐问题。
常见用法如下: 以预训练好的 ResNet18 模型为例,你可以换成其他模型,通过提取 layer4 层输出进行特征图可视化
(1) 将多通道特征图采用 select_max 参数压缩为单通道并显示
下载图片备用:
wget https://raw.githubusercontent.com/jacobgil/pytorch-grad-cam/master/examples/both.png准备代码:
import numpy as np
from torchvision.models import resnet18
from torchvision.transforms import Compose, Normalize, ToTensor
import torch
import mmcv
from mmengine.visualization import Visualizer
def preprocess_image(img, mean, std):
preprocessing = Compose([
ToTensor(),
Normalize(mean=mean, std=std)
])
return preprocessing(img.copy()).unsqueeze(0)
model = resnet18(pretrained=True)
def _forward(x):
x = model.conv1(x)
x = model.bn1(x)
x = model.relu(x)
x = model.maxpool(x)
x1 = model.layer1(x)
x2 = model.layer2(x1)
x3 = model.layer3(x2)
x4 = model.layer4(x3)
return x4
model.forward = _forward
image = mmcv.imread('both.png', channel_order='rgb')
image_norm = np.float32(image) / 255
input_tensor = preprocess_image(image_norm,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
feat = model(input_tensor)[0]
visualizer = Visualizer()
drawn_img = visualizer.draw_featmap(feat, image, channel_reduction='select_max')
visualizer.show(drawn_img)效果如下所示:

(2) 利用 topk=5 参数选择多通道特征图中激活度最高的 5 个通道并采用 2x3 布局显示
drawn_img = visualizer.draw_featmap(feat, image, channel_reduction=None, topk=5, arrangement=(2, 3))
visualizer.show(drawn_img)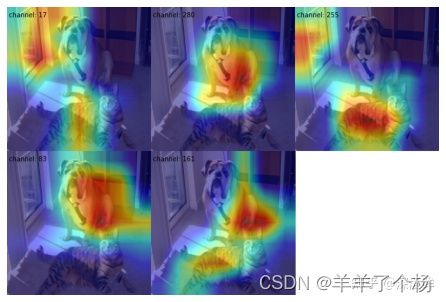
MMYOLO 特征图可视化使用
基于 MMEngine 的绘制特征图功能即可进行特征图可视化,接下来的核心问题是如何获取想要看的特征图层。一个比较常见的做法是使用 PyTorch 自带的 register_forward_hook
class ActivationsWrapper:
def __init__(self, model, target_layers):
self.model = model
self.activations = []
self.handles = []
self.image = None
for target_layer in target_layers:
self.handles.append(
target_layer.register_forward_hook(self.save_activation))
def save_activation(self, module, input, output):
self.activations.append(output)
def __call__(self, img_path):
self.activations = []
results = inference_detector(self.model, img_path)
return results, self.activations
def release(self):
for handle in self.handles:
handle.remove()先下载 YOLOv5-s 权重备用:
wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth案例 1:最大激活
可视化 backbone 输出的 3 个层的最大激活层
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers backbone \
--channel-reduction select_max效果如下所示:

不知道你发现没有:第三个图实际上图片和特征图没有对齐,这是因为 YOLOv5 前处理中不是简单的 Resize的,因此出现了我们前面说的图片和特征图不对齐问题。
解决办法有两个:
1. 修改 YOLOv5 配置,让后处理只是简单的 Resize 即可,这对于可视化是没有啥影响的
2. 可视化时候图片应该用前处理后的,而不能用前处理前的
两者可视化效果差异不大,为了简单,我们这里采用第一种解决办法,后续会采用第二种方案修复,让大家可以不修改配置即可使用。
打开 configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py 配置文件,将原先的 test_pipeline 换掉:
旧的写法为:
test_pipeline = [
dict(
type='LoadImageFromFile',
file_client_args={{_base_.file_client_args}}),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]新的写法为:
test_pipeline = [
dict(
type='LoadImageFromFile',
file_client_args={{_base_.file_client_args}}),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]正确的效果如下所示:
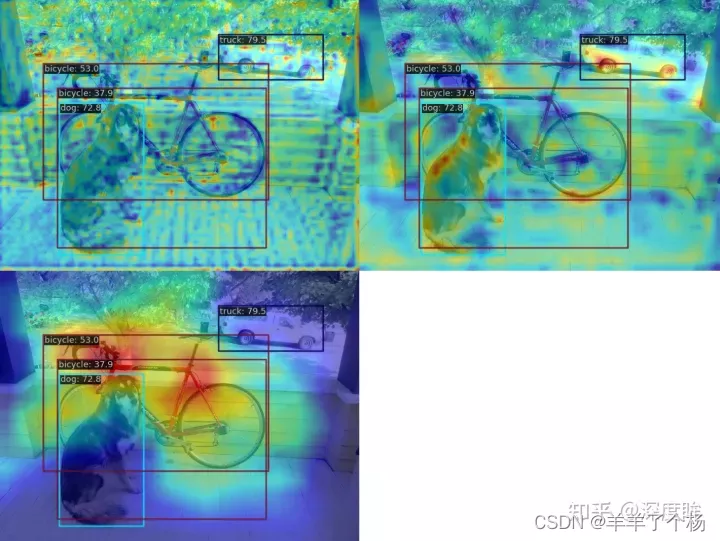
案例 2:平均激活
可视化 neck 输出的 3 个层的所有输出特征图的平均激活
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers neck \
--channel-reduction squeeze_mean
案例 3:多 target layer
可视化 backbone 输出的 backbone.stage4 和 backbone.stage3 2 个层的平均激活
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers backbone.stage4 backbone.stage3 \
--channel-reduction squeeze_mean
案例 4:布局重排
可视化 backbone 输出的 backbone.stage4层的 topk 激活层,利用 --topk 4 --arrangement 2 2 参数选择多通道特征图中激活度最高的 3 个通道并采用 2x2 布局显示
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers backbone.stage4 \
--channel-reduction None \
--topk 4 \
--arrangement 2 2 
案例 5:打印网络结构
如果不清楚网络结构,可以打印出来,然后自己写
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--preview-model效果如下:
local loads checkpoint from path: yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
YOLODetector(
(data_preprocessor): YOLOv5DetDataPreprocessor()
(backbone): YOLOv5CSPDarknet(
(stem): ConvModule(
(conv): Conv2d(3, 32, kernel_size=(6, 6), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(stage1): Sequential(
(0): ConvModule(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(1): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
。。。总结
本文主要分析了 MMYOLO 中特征可视化用法。