指令流水(计算机组成)
文章目录
-
- 1、如何提高机器速度
- 2、指令流水原理
-
- 2.1、指令的串行执行
- 2.2、指令的二级流水
- 3、指令的五级流水
- 4、流水线的冒险
-
- 4.1、结构冒险
- 4.2、数据冒险
- 4.3、控制冒险
- 5、流水线性能
-
- 5.1、吞吐率
- 5.2、加速比
- 5.3 效率
- 6、引用
1、如何提高机器速度
-
提高访存速度
- 提高存储芯片的性能
- 多体、cache等分级存储
-
提高I/O与主机之间的传输速度
- DMA方式
- 多总线结构
-
提高运算速度
- 高速芯片
- 快速进位链
- 改进算法
-
提高整机处理能力
- 提高器件的性能
- 改进系统的结构,开发系统的并行性
2、指令流水原理
2.1、指令的串行执行
![]()
取指令的操作可由指令部件完成,执行指令的部件可由执行部件完成。顺序执行虽然控制简单,但执行中各部件的利用率不高,如指令部件工作时,执行部件基本空闲,而执行部件工作时,指令部件基本空闲。
2.2、指令的二级流水
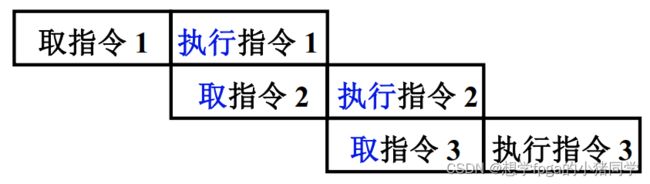
由指令部件取出一条指令,并将它暂存起来,如果执行部件空闲,就将暂存的指令传给执行部件执行,与此同时,指令部件又可以取出下一条指令并暂存起来,这称为指令预取。若取指和执行阶段在时间上完全重叠,指令周期减半。速度提升一倍。
3、指令的五级流水
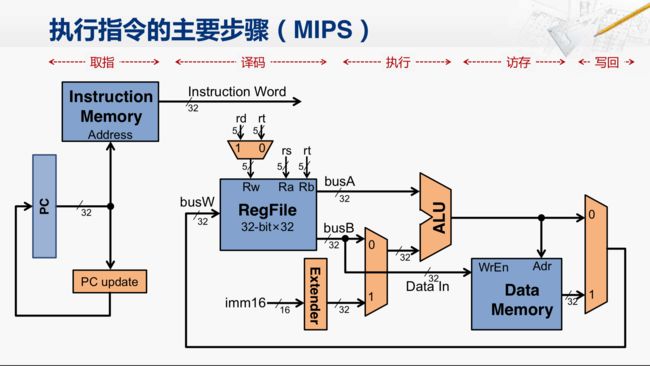
指令执行的主要步骤(mips):
| 1、取指(Fetch) | 从存储器取指令,更新PC |
|---|---|
| 2、译码(Decode) | 指令译码,从寄存器堆读出寄存器的值 |
| 3、执行(Execute) | 运算指令:进行算术逻辑运算;访存指令:计算存储器地址 |
| 4、访存(Memory) | Load指令:从存储器读数据;Store指令:将数据写入存储器 |
| 5、写回(Write-Back) | 将数据写入寄存器堆 |
第一步取指,就是用PC的值去访问指令存储器,从而得到指令的编码,同时还需要生成PC的更新值。
第二步译码,不仅需要把指令编码进行分解,而且还需要从寄存器堆当中读出所需的寄存器的值。
第三步执行,主要在 ALU 当中完成。对于算术逻辑运算指令,就是完成对应的运算;而对于访存指令,则是计算出访存的地址。
第四步是访存,对于load指令,是从数据存储器当中读出对应的数据;而对于store指令,则是将数据送到数据存储器当中去;而其他指令在这一步没有实质的操作。
最后一步是写回,对于要改写寄存器的指令,在这一步会将数据写入到寄存器堆当中指定的位置。
我们要注意的是,虽然分成了这五步,但只是为了便于描述而已。所有的信号都必须要在这条指令执行的过程中保持稳定,例如从PC寄存器送到指令存储器的 这个地址信号,如果在指令执行完成前,它就发生了改变,那指令存储器送出的指令编码(Instruction Word)也就会发生改变,从而造成寄存器堆选取了不同编号的寄存器,送出了不同的值,ALU也可能执行了不同的操作,那这条指令就可能执行错误了。所以,对于单周期处理器来说,这一条指令执行的过程中,所有的信号都是必须要保持稳定的。
而我们要进行流水线的改造的话,我们同样也会发现,这不同阶段所用到的硬件资源基本上是相互独立的。如果我们能把指令存储器输出的指令编码事先保存下来,那我们就可以提前更新PC寄存器的值,并用这新的值去指令存储器当中取出一个新的指令,而在取新指令的同时,刚才取出的那条指令的编码就会被分解成不同位域,而寄存器堆也会根据输入送出对应寄存器的内容。所以,跟刚才的流水线原理的分析类似,如果我们想把这些硬件资源充分地利用起来,我们就需要把它拆分成若干个阶段。
那在这个电路的结构上要进行拆分,我们就在每一个阶段之间添加上寄存器,这就被称为流水线寄存器,这些寄存器用于保存前一个阶段要向后一个阶段传送的所有的信息。
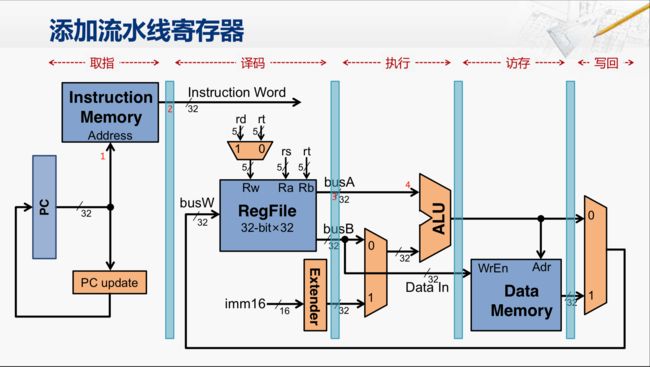
我们还是以取指到译码的这个阶段为例,我们将指令存储器的输出接到一个寄存器上(图中标号2处),那当一个时钟上升沿来临的时候,指令存储器输出的指令编码就会被保存到这个寄存器当中。那么在这个上升沿之后,指令存储器的地址输入(1处)如果发生改变,随之影响的指令存储器的输出,也不会被存到这个寄存器当中去(2处)。所以,在这个时候,我们可以用新的PC来访问这个指令存储器,从而得到下一条指令的二进制编码。而在这个同时,前一条指令的编码已经在这个(2处)流水线寄存器的输出上,并且经过相应的电路,切分成不同的位域。那其中有一个位域就会通过rs连到了寄存器堆,并且选中对应的寄存器,把其中的内容放到busA这根信号上,而这根信号也会被接到一个流水线的寄存器上(3处)。那么当下一个时钟上升沿来临的时候, 当前这条指令所需要的rs寄存器的值,就会被保存到这个(3处)流水线寄存器当中。与此同时,下一条指令的二进制编码也会保存到这个(2处)流水线寄存器中。那么在很短的
Clock-to-Q 时间之后,译码阶段所看到的指令的编码(Instruction Word)就已经变成第二条指令了。所以很快,寄存器堆得到的rs的寄存器编号也发生了改变,但是这没有关系,第一条指令所需的寄存器的值已经保存到了这个(3处)流水线寄存器当中,而且在这个时候,也应该会被送到了ALU的输入端(4处)。所以,这样通过添加流水线寄存器,我们就先从大体上把这个单周期处理器改造成了一个流水线的处理器。
4、流水线的冒险
冒险(Hazard):在流水线中我们希望当前每个时钟周期都有一条指令进入流水线可以执行。但在某些情况下,下一条指令无法按照预期开始执行,这种情况就被称为冒险。
冒险分为三种:
结构冒险:如果一条指令需要的硬件部件还在为之前的指令工作,而无法为这条指令提供服务,那就导致了结构冒险。(这里结构是指硬件当中的某个部件也称为资源冲突)
数据冒险:当指令在流水线中重叠执行时,后面的指令需要用到前面的指令的执行结果,而前面的指令尚未写回导致的冲突,称为数据冒险(也称为数据相关性)。
控制冒险:如果现在要执行哪条指令,是由之前指令的运行结果决定,而现在那条之前指令的结果还没产生,就导致了控制冒险。
4.1、结构冒险
示例一:如果指令和数据放在同一个存储器中,则不能同时读存储器
解决方案一:我们有一个方便又简便的方法,即流水线停顿(stall),产生空泡(bubble)。
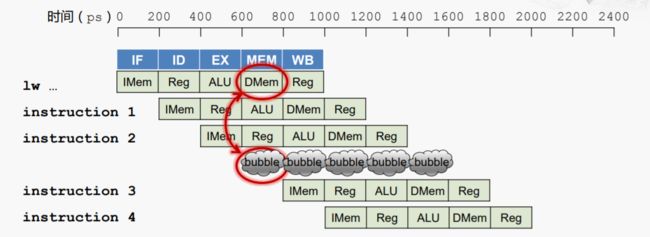
虽然流水线停顿能用来解决各种冒险,但它的效率低下,应尽量避免。
解决方案二:在存储器中设置单独的指令高速缓存和数据高速缓存。(要强调的在计算机中主存储器也就是内存是统一存放指令和数据的,这也是冯诺依曼结构的要求,只是在CPU当中 的一级高速缓存会采用指令和数据分别存放的方式)
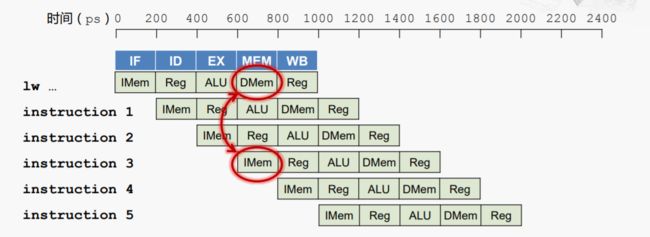
示例二:如果读寄存器和写寄存器同时发生,如何处理?
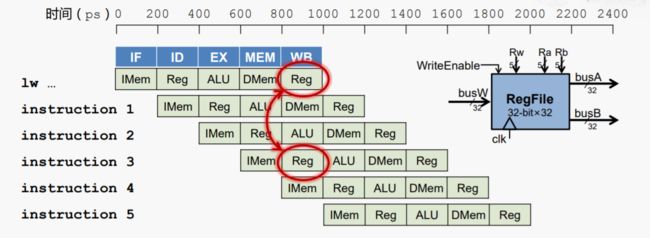
解决方案:前半个周期写,后半个周期读,并且设置独立的读写端口。
相对来说寄存器堆的读写速度比较快, 我们假设读或者写寄存器的延迟为100ps,而其他部件比如说ALU的延迟就就比较大,视为200ps, 那么我们就可以在前半个时钟周期用于完成寄存器堆的写,后半个时钟周期用来完成读操作,并且在寄存器堆上设置独立的读写口。这样就可以在一个时钟周期内同时完成了读和写的操作。
要设计一个新的处理器,结构冒险仍然是我们优先要考虑并解决的问题。但结构冒险在设计处理器时就考虑并解决好了,我们在使用时就不必考虑。
4.2、数据冒险
发生数据相关性的三种情况:
RAW(read after write):又称先写后读相关性。比如下面指令序列,如果第二条指令,在第一条指令写x5之前,第二条指令先读x5,就会引起逻辑错误。
add x5, x4, x6
add x4, x5, x2
WAW(write after write):又称先写后写相关性。比如下面指令序列,如果第二条指令,在第一条指令写x5之前,第二条指令先写x5寄存器,就会引起逻辑错误。
add x5, x4, x6
add x5, x3, x2
WAR(write after read):又称先读后写相关性。比如下面的指令序列,第一条指令会读取x4,第二条指令会写x4。在流水线中,如果第二条指令比第一条指令先写x4,则第一条指令就会读出错误的值。
add x5, x4, x6
add x4, x3, x2
示例一:一条指令需要使用之前指令的结果,但是结果还没有写回。
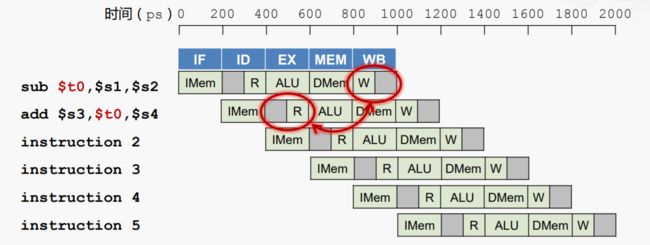
软件解决方案:插入nop指令

但这种方法有个很大的问题,首先,插入nop指令的个数与流水线的结构相关,例如在5级流水线上正确运行的程序,在8级流水线上就不能正确运行。其次,我们希望对软件屏蔽硬件尽可能多的细节。
那么既然两条nop指令就能解决的问题,我们可以尝试在硬件上完成相同的工作。
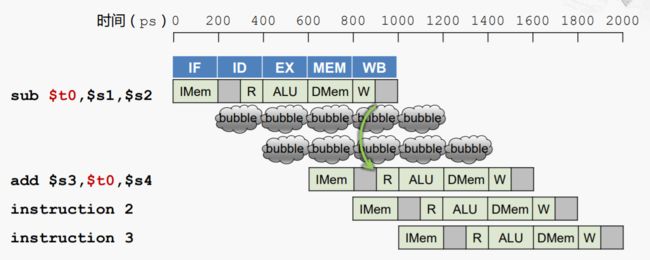
解决方案一:流水线停顿,增加气泡
解决方案二:数据前递(Forwarding)或数据旁路
t0在EX阶段就被计算出,所以可将它送到下一条指令ALU的输入,而不需要添加气泡。

在电路上的实现如下:在过600ps后,t0的值会被保存到EX/MEM这个流水线寄存器中,与此同时,加法指令正在执行,它需要将t0的值传到ALU的输入,显然它直接从t0寄存器读的值不是最新的,最新的在访存阶段的连线上,我们从硬件连线上把这个信号引回来,作为ALU的输入端。是否使用前递的信号,我们需要根据是否出现数据冒险,来控制一个二路选择器。
当然加法指令,也有可能是第二个源操作数使用t0的值,所以前递信号也要连接到第二个输入端,同样这里也要添加二路选择器。
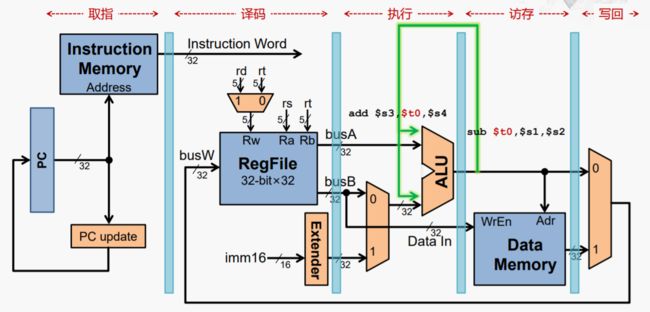
这样的方式就被成为前递。它还有个名称叫作旁路。那从根本上来说,前递和旁路指的都是这件事情。只不过是观察和描述的角度不同而已。前递是从指令执行顺序的角度来描述的,而旁路则是从电路的结构角度来描述。 本来前一条指令应该将运行的结果写入到寄存器堆,然后再交给后一条指令使用,而我们现在搭建来一条新堆通路,相当于绕过了寄存器堆,直接进行了数据堆传递,所以从硬件时限的角度来看,这是一个旁路。那这就是前递和旁路的关系。
那我们进一步来看,其实不仅仅在这个点可以建立旁路,我们在下一个流水级也可以建立旁路。
示例二:从MEM/WB阶段前递到ALU的情况
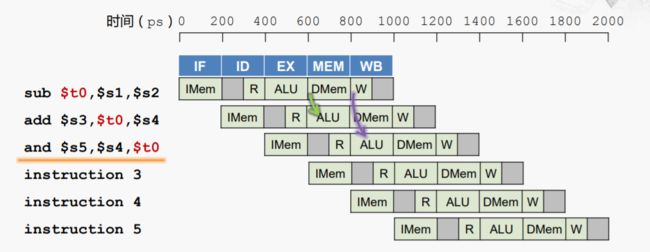
所以,再添加一条旁路
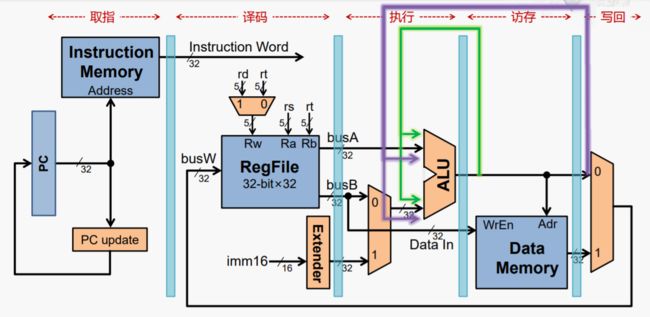
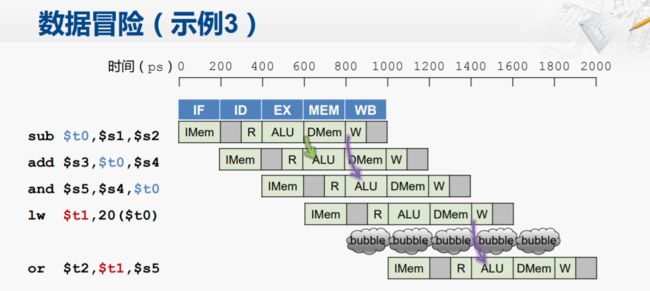
示例三:访存指令出现数据冒险
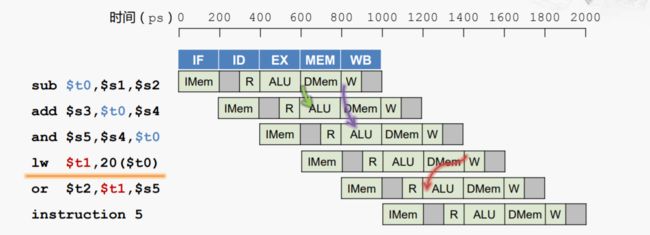
这个单纯的前递也无法解决(前递的箭头方向正向下或者左下)
解决方案:流水线停顿+数据前递
4.3、控制冒险
示例:尚未确定是否发生分支,如何进行下一次取指
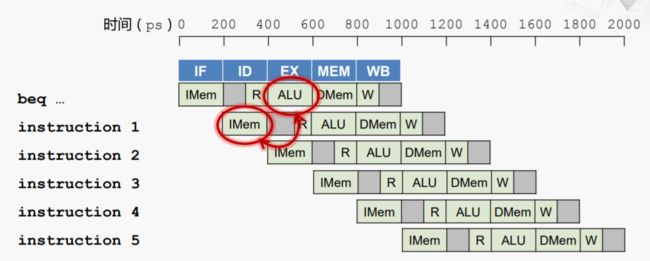
解决方案一:流水线停顿,添加气泡

前面说过添加气泡效率很低,并不是一种较好的方法。我们可以从一下两方面考虑:
一、假设分支不发生
例如,假设经过beq指令分支不发生,最坏情况是其实分支总是发生,所以执行两条错误的lw、sw指令,又执行两条正确的指令,这样导致50%的性能浪费。

这也是因为转移指令本身和流水线的模式是冲突的,因为转移指令会改变指令的流向, 而流水线则希望能够依次地取回指令,将流水线填满。那如果这种情况是非常罕见的,也许我们还可以容忍,但实际上转移指令是非常常用的指令。
二、缩短分支延迟
转移指令的分类:
- 直接转移:j target和beq rs,rt,imm两种
- 间接转移:jr t0
无条件直接跳转(j target)
这种情况跳转是确定发生的,且跳转地址在取指阶段就能得到,所以流水线不停顿。
这条指令的编码当中,带有一个26位的立即数,这个数就是要转移的目标地址的主体部分, 但是我们的目标地址应该是32位的,所以还差6位,在差的6位当中,低两位我们用0补上,因为目标地址肯定是四字节对齐的,地址的低两位肯定是0,然后还缺4位,我们通过当前的PC寄存器计算而得。先将PC寄存器的内容加4,得到的这个32位数,取其高4位,和26位地址以及最低的两位的0连接起来,构成了一个32位的数,这就是转移的目标地址。这些工作和取指可在一个时钟周期内完成。

无条件间接跳转(jr rs)
在译码阶段得出跳转地址,流水线需停顿一个周期。

条件跳转(beq rs,rt,imm16)
不做优化,需要根据EX阶段的结果,判断是否跳转,需要等待2个周期。
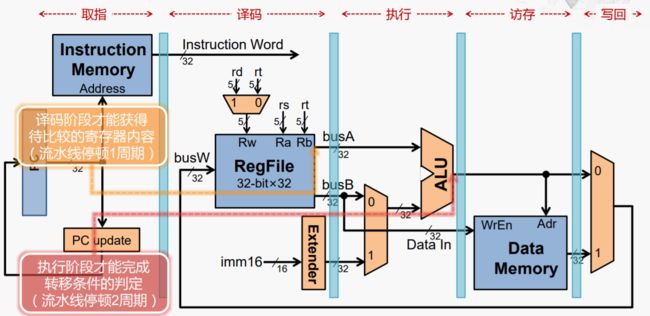
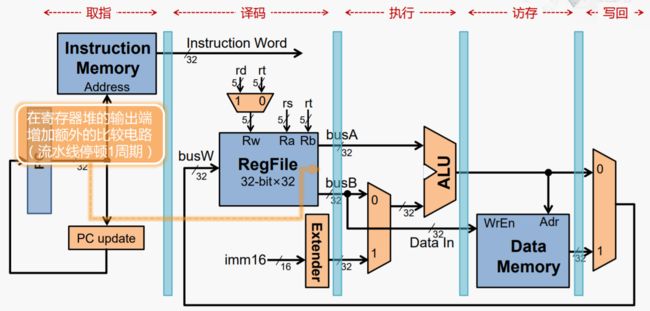
而实际上,比较两个数是否相等是十分简单的,只需在译码阶段对寄存器的两个输出进行比较,这样流水线停顿周期缩减为1个周期
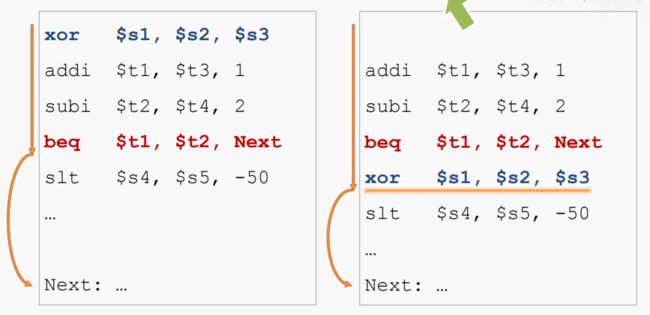
三、 延迟转移技术
就是调整指令的顺序,将一定会执行的指令放在分支指令后面,这样流水线不停顿。注意,不能改变这段代码原来的意义。
例如:可以将xor指令放到beq后面,经过xor指令后,beq不用等待正好可以执行,但是不能将addi或subi放到beq后面,因为beq指令需要这两个。
5、流水线性能
5.1、吞吐率
吞吐率(Throughput Rate):单位时间内流水线所完成指令或输出结果的数量。
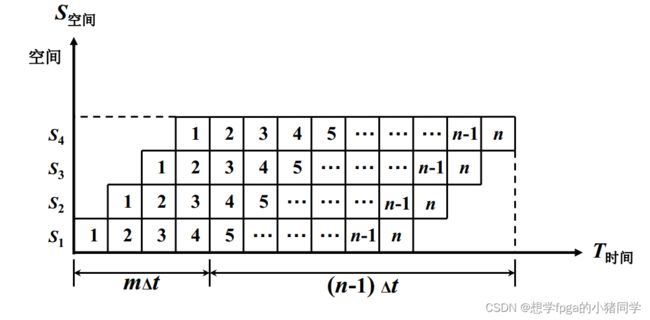
设 m 段的流水线各段时间为Δt。
最大吞吐率:
T p m a x = 1 Δ t T_{pmax}=\frac1 {Δt} Tpmax=Δt1
实际吞吐率:
连续处理 n 条指令的吞吐率为
T p = n m ⋅ Δ t + ( n − 1 ) ⋅ Δ t T_p=\frac{n}{m \cdotΔt+(n-1)\cdotΔt} Tp=m⋅Δt+(n−1)⋅Δtn
5.2、加速比
加速比(Speedup Ratio):m 段的流水线的速度与等功能的非流水线的速度之比
设流水线各段时间为 Δ t,
完成 n 条指令在 m 段流水线上共需
T = m ⋅ Δ t + ( n − 1 ) ⋅ Δ t T = m\cdotΔt+(n-1)\cdotΔt T=m⋅Δt+(n−1)⋅Δt
完成 n 条指令在等效的非流水线上共需
T ′ = n m ⋅ Δ t T'=nm\cdotΔt T′=nm⋅Δt
则加速比:
S p = T ′ T = n m m + n − 1 S_p=\frac{T'}T=\frac{nm}{m+n-1} Sp=TT′=m+n−1nm
可以看出,在n>m时,Sp接近于m,即当流水线各段时间相等时,其最大加速比等于流水线的段数。
5.3 效率
效率(Efficiency):流水线中各功能段的利用率
由于流水线有 建立时间和排空时间,因此各功能段的设备不可能 一直处于工作状态
流水线中各功能段的利用率
效率 = 流水线各段处于工作时间的时空区 流水线中各段总的时空区 = m n Δ t m ( m + n − 1 ) Δ t 效率=\frac{流水线各段处于工作时间的时空区}{流水线中各段总的时空区}=\frac{mnΔt}{m(m + n -1) Δt} 效率=流水线中各段总的时空区流水线各段处于工作时间的时空区=m(m+n−1)ΔtmnΔt
6、引用
1、计算机组成与设计(十)—— 流水线的冒险 - Rogn - 博客园 (cnblogs.com)
2、7.1 流水线的基本原理 - houhaibushihai (cnblogs.com)
3、计算机组成原理(第二版) 唐朔飞
4、北京大学 《计算机组成》 陆俊林 课程
5、计算机组成原理(唐朔飞)课程