linux操作系统分析实验1:基于mykernel2.0编写一个操作系统内核
实验1
- 1.实验环境配置
- 2.基于mykernel 2.0编写一个操作系统内核,(参照https://github.com/mengning/mykernel 提供的范例代码)
- 3. 简要分析操作系统内核核心功能及运行工作机制。
-
- 3.1 进程控制块mypcb.h分析
- 3.2 mymain.c分析(负责初始化内核的各个组成部分)
- 3.3 myinterrupt.c分析
1.实验环境配置
wget https://raw.github.com/mengning/mykernel/master/mykernel-2.0_for_linux-5.4.34.patch(直接从GitHub拿,使用wget有可能失败)
sudo apt install axel
axel -n 20 https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/linux-5.4.34.tar.xz
xz -d linux-5.4.34.tar.xz
tar -xvf linux-5.4.34.tar
cd linux-5.4.34
patch -p1 < ../mykernel-2.0_for_linux-5.4.34.patch
sudo apt install build-essential libncurses-dev bison flex libssl-dev libelf-dev
make defconfig # Default configuration is based on 'x86_64_defconfig'
make -j$(nproc)
sudo apt install qemu # install QEMU
qemu-system-x86_64 -kernel arch/x86/boot/bzImage
配置结果如下:
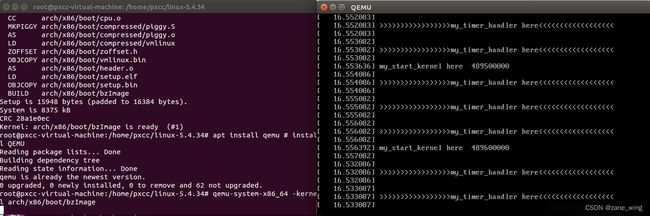
2.基于mykernel 2.0编写一个操作系统内核,(参照https://github.com/mengning/mykernel 提供的范例代码)
(1)接下来需要在 mymain.c 的基础上继续写进程描述PCB和进程链表管理等代码,在 myinterrupt.c 的基础上完成进程切换代码,才可以完成一个简单的操作系统内核从而进行进程调度。
(2)首先进入 mykernel 文件夹,然后通过使用 touch 命令新建一个mypcb.h文件, 并复制相应代码。同时利用 GitHub 上的 mymain.c 和 myinterrupt.c 文件替代原先文件。
(3)使用 make 指令重新编译,并运行 qemu-system-x86_64 -kernel arch/x86/boot/bzImage指令。即可观察到进程的切换调度过程。
实验结果:
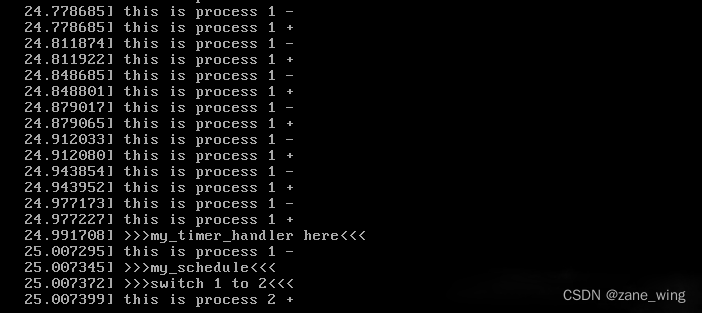
3. 简要分析操作系统内核核心功能及运行工作机制。
3.1 进程控制块mypcb.h分析
#define MAX_TASK_NUM 4 //进程数
#define KERNEL_STACK_SIZE 1024*2 //定义栈的大小
struct Thread {
unsigned long ip;
unsigned long sp;
};
typedef struct PCB{
int pid;
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned long stack[KERNEL_STACK_SIZE];
struct Thread thread;
unsigned long task_entry;
struct PCB *next;
}tPCB;
void my_schedule(void);
结构体Thread :用于存储当前进程中正在执行的线程的ip和sp
结构体PCB:(模拟进程控制块)
pid:进程号
state:进程状态,-1代表阻塞态,0代表可运行态,>0代表暂停状态
stack:进程使用的堆栈
thread:当前正在执行的线程信息(thread.ip和thread.sp)
task_entry:存储进程入口函数地址(本实验中为my_process函数)
next:指向下一个PCB,系统中所有的PCB是以环形链表的形式连接起来的
3.2 mymain.c分析(负责初始化内核的各个组成部分)
#include
#include
#include
#include
#include
#include "mypcb.h"
tPCB task[MAX_TASK_NUM];
tPCB * my_current_task = NULL;
volatile int my_need_sched = 0void my_process(void);
void __init my_start_kernel(void)
{
int pid = 0;
int i;
/* Initialize process 0*/
task[pid].pid = pid;
task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid];
/*fork more process */
for(i=1;ipid);
if(my_need_sched == 1)
{
my_need_sched = 0;
my_schedule();
}
printk(KERN_NOTICE "this is process %d +\n",my_current_task->pid);
}
}
}
首先初始化所有进程,定义my_current_task指针指向当前进程,定义全局变量my_need_sched = 0负责进程调度。
void __init my_start_kernel(void)函数是mykernel内核代码的⼊⼝,负责初始化内核的各个组成部分。在Linux内核源代码中,实际的内核⼊⼝是init/main.c中的start_kernel(void)函数。
首先pid=0,代表进程号为0的进程,在本实验中就是第一个进程。初始化进程task[0]的所有信息,值得一提的是,task[0]的next指针一开始指向的正是自己。
接下来的for循环用来构建进程环形链表。构建完毕后开始执行第一个进程,关于如何启动第一个进程的,关键代码分析如下:
asm volatile(
"movq %1,%%rsp\n\t" /* 将进程原堆栈栈顶的地址存⼊RSP寄存器 */
"pushq %1\n\t" /* 将当前RBP寄存器值压栈 */
"pushq %0\n\t" /* 将当前进程的RIP压栈 */
"ret\n\t" /* ret命令正好可以让压栈的进程RIP保存到RIP寄存器中 */
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/
);
ret命令执行后,RIP寄存器中就得到了my_process(void)函数的进入地址(task[0].thread.ip),开始执行my_process(void)函数,这样就完成了进程0的启动。
在my_process函数的while循环里面可见,会不断检测全局变量my_need_sched的值,当my_need_sched的值从0变成1的时候,就需要发生进程调度,全局变量my_need_sched重新置为0,执行my_schedule()函数进行进程切换。
3.3 myinterrupt.c分析
#include 主要就是my_schedule(void)分析
进程函数中每隔一定时间会执行一次调度,调度的代码在my_schedule(void)函数中实现,首先找到PCB链表中的下一个节点,然后切换到该进程,这部分代码由内嵌汇编实现。
进程切换过程中prev进程和next进程的堆栈和相关寄存器的变化过程大致如下:
1. pushq %%rbp 保存prev进程的当前RBP寄存器的值到prev进程的堆栈。
2. movq %%rsp,%0 保存prev进程的当前RSP寄存器的值到prev->thread.sp,实际上就是将prev进程的栈顶地址保存。
3. movq %2,%%rsp 将next进程的栈顶地址next->thread.sp放入RSP寄存器,完成了prev进程和next进程的堆栈切换。
4. movq $1f,%1 保存prev进程当前RIP寄存器值到prev->thread.ip,这里$1f是指标号1。
5. pushq %3 把即将执行的next进程的指令地址next->thread.ip入栈,这时的next->thread.ip可能是next进程的起点my_process(void)函数,也可能是$1f(标号1)。第一次被执行从头开始为next进程的起点my_process(void)函数,其余的情况均为$1f(标号1),因为next进程如果之前运行过那么它就一定曾经也作为prev进程被进程切换过。
6. ret 就是将压入栈中的next->thread.ip放入RIP寄存器,为什么不直接放入RIP寄存器呢?因为程序不能直接使用RIP寄存器,只能通过call、ret等指令间接改变RIP寄存器。
7. 标号1是一个特殊的地址位置,该位置的地址是$1f。
8. popq %%rbp 将next进程堆栈基地址从堆栈中恢复到RBP寄存器中。