【漫漫转码路】Day 34 Pandas day02
第一节 分组操作
groupby
对DataFrame的数据进行分组
一般来讲,对列数据有重复的数据分组才有意义
用groupby方法
# 例如
import pandas as pd
import numpy as np
list1 = [{'name': '张三', 'age': 15, 'num': '001', 'score': 95},
{'name': '李四', 'age': 16, 'num': '002', 'score': 90},
{'name': '王五', 'age': 15, 'num': '003', 'score': 85},
{'name': '赵六', 'age': 17, 'num': '004', 'score': 85}]
df1 = pd.DataFrame(list1, index=["a", "b", "c", "d"])
print(df1)
print("=========================================")
result = df1.groupby("age")
print(result)
print(type(result))
print(result.groups) # 用groups来查看分组数据
print("=========================================")
print(result.get_group(15)) #调用get_group来查看年龄为15岁的分组情况
print("=========================================")
for age, groupdata in result: # 用哪个for循环遍历来查看分组数据
print(age)
print(groupdata)
# 显示
name age num score //原数据
a 张三 15 001 95
b 李四 16 002 90
c 王五 15 003 85
d 赵六 17 004 85
=========================================
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000025E7CE401F0> //groupby的结果是一个实例对象
<class 'pandas.core.groupby.generic.DataFrameGroupBy'> //groupby的类型
{15: ['a', 'c'], 16: ['b'], 17: ['d']} //可以调用groups来查看分组情况
=========================================
name age num score
a 张三 15 001 95
c 王五 15 003 85
=========================================
15 # 对应age
name age num score # 对应groupdata
a 张三 15 001 95
c 王五 15 003 85
16
name age num score
b 李四 16 002 90
17
name age num score
d 赵六 17 004 85
对groupby的结果调用groups方法可以查看具体分组情况
对groupby的结果调用get_group方法可以查看固定条件的分组情况
对groupby的结果调用for循环遍历方式也可以获取分组情况
groupby可以传多个参数,分组,用列表括起来
# 例如
dict1 = {"grade": [7, 7, 7, 8, 8, 9, 9, 9],
"class": [1, 1, 2, 1, 2, 1, 2, 2],
"num": ["00{}".format(i)for i in range(1, 9)],
"name": ["student_{}".format(i)for i in range(1, 9)],
"age": [12, 13, 12, 14, 13, 14, 15, 15],
"score": [80, 85, 90, 87, 75, 88, 91, 95]}
df1 = pd.DataFrame(dict1)
print(df1)
# 统计每个班级的平均分
print("=========================================")
result = df1.groupby(["grade", "class"])
print(result.groups)
print(result.get_group((7, 1))) # 获取(7,1)的数据,注意一定是元组的形式
print("=========================================")
for i, j in result: # 对result进行遍历循环,得到分组和数据,i是分组,j是数据
print(i)
print(j)
print(j["score"].mean()) # 每组数据的score列求均值
# 显示
grade class num name age score
0 7 1 001 student_1 12 80
1 7 1 002 student_2 13 85
2 7 2 003 student_3 12 90
3 8 1 004 student_4 14 87
4 8 2 005 student_5 13 75
5 9 1 006 student_6 14 88
6 9 2 007 student_7 15 91
7 9 2 008 student_8 15 95
=========================================
{(7, 1): [0, 1], (7, 2): [2], (8, 1): [3], (8, 2): [4], (9, 1): [5], (9, 2): [6, 7]} # 可以看到groupby的结果是字典的形式,字典的键是分组的两个依据,以元组的形式,grade和class,字典的值是行索引
grade class num name age score # 得到7年纪1班的数据
0 7 1 001 student_1 12 80
1 7 1 002 student_2 13 85
========================================= # 以下为for循环遍历得到的分组和数据
(7, 1)
grade class num name age score
0 7 1 001 student_1 12 80
1 7 1 002 student_2 13 85
82.5 # 均值
(7, 2)
grade class num name age score
2 7 2 003 student_3 12 90
90.0
(8, 1)
grade class num name age score
3 8 1 004 student_4 14 87
87.0
(8, 2)
grade class num name age score
4 8 2 005 student_5 13 75
75.0
(9, 1)
grade class num name age score
5 9 1 006 student_6 14 88
88.0
(9, 2)
grade class num name age score
6 9 2 007 student_7 15 91
7 9 2 008 student_8 15 95
93.0
采用聚合的方法做统计
# 例如
dict1 = {"grade": [7, 7, 7, 8, 8, 9, 9, 9],
"class": [1, 1, 2, 1, 2, 1, 2, 2],
"num": ["00{}".format(i)for i in range(1, 9)],
"name": ["student_{}".format(i)for i in range(1, 9)],
"age": [12, 13, 12, 14, 13, 14, 15, 15],
"score": [80, 85, 90, 87, 75, 88, 91, 95]}
df1 = pd.DataFrame(dict1)
result = df1.groupby(["grade", "class"])
score_maen = result["score"].agg(np.mean) # 用聚合的方式求均值
print(score_maen)
print(type(score_maen))
print(score_maen.index)
print(score_maen[(7, 1)]) # 可以直接得到7年级1班的平均值
print(score_maen.loc[(7, 1)]) # 用loc标签索引也可以得到
# 显示
grade class # 前面的两列graoup和class都是他的标签
7 1 82.5
2 90.0
8 1 87.0
2 75.0
9 1 88.0
2 93.0
Name: score, dtype: float64
<class 'pandas.core.series.Series'> # 这是一个series类型的数据
MultiIndex([(7, 1),
(7, 2),
(8, 1),
(8, 2),
(9, 1),
(9, 2)],
names=['grade', 'class']) # 标签是group和class
82.5
82.5
可以直接求取两个列的均值
# 例如
dict1 = {"grade": [7, 7, 7, 8, 8, 9, 9, 9],
"class": [1, 1, 2, 1, 2, 1, 2, 2],
"num": ["00{}".format(i)for i in range(1, 9)],
"name": ["student_{}".format(i)for i in range(1, 9)],
"age": [12, 13, 12, 14, 13, 14, 15, 15],
"score": [80, 85, 90, 87, 75, 88, 91, 95]}
df1 = pd.DataFrame(dict1)
result = df1.groupby(["grade", "class"])
result_maen = result["age", "score"].agg(np.mean)
print(result_maen)
print(type(result_maen))
print(result_maen.index)
print(result_maen.columns)
print("=========================================")
#print(result_maen[(7, 1)]) # DataFrame对象不能直接用行索引获取
print(result_maen["age"]) # 但是可以直接用列标签获取
print("=========================================")
print(result_maen.loc[(7, 1), "age"]) # 用loc标签索引也可以得到,这里也可以用一个7,获取7年级的数据
print(result_maen.iloc[0, 1]) # 获取result_mean的第0行第1列
# 显示
age score
grade class
7 1 12.5 82.5
2 12.0 90.0
8 1 14.0 87.0
2 13.0 75.0
9 1 14.0 88.0
2 15.0 93.0
<class 'pandas.core.frame.DataFrame'>
MultiIndex([(7, 1),
(7, 2),
(8, 1),
(8, 2),
(9, 1),
(9, 2)],
names=['grade', 'class'])
Index(['age', 'score'], dtype='object')
=========================================
grade class
7 1 12.5
2 12.0
8 1 14.0
2 13.0
9 1 14.0
2 15.0
Name: age, dtype: float64
=========================================
12.5
82.5
同时求取两个统计量
聚合统计不止可以统计一个
复合标签
# 例如
dict1 = {"grade": [7, 7, 7, 8, 8, 9, 9, 9],
"class": [1, 1, 2, 1, 2, 1, 2, 2],
"num": ["00{}".format(i)for i in range(1, 9)],
"name": ["student_{}".format(i)for i in range(1, 9)],
"age": [12, 13, 12, 14, 13, 14, 15, 15],
"score": [80, 85, 90, 87, 75, 88, 91, 95]}
df1 = pd.DataFrame(dict1)
result = df1.groupby(["grade", "class"])
result_maen = result["age", "score"].agg([np.mean, np.size]) # size求取个数
print(result_maen)
# 显示
age score # 这里标签得到的是复合标签
mean size mean size
grade class
7 1 12.5 2 82.5 2
2 12.0 1 90.0 1
8 1 14.0 1 87.0 1
2 13.0 1 75.0 1
9 1 14.0 1 88.0 1
2 15.0 2 93.0 2
第二节 表的连接合并操作
表连接(merge)
merge()
merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
left: 参与合并的左侧DataFrame;
right: 参与合并的右侧DataFrame;
how: 连接方式,有inner、left、right、outer,默认为inner;
on: 指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
left_on: 左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有 用;
right_on: 右侧DataFrame中用于连接键的列名;
left_index: 使用左侧DataFrame中的行索引作为连接键;
right_index: 使用右侧DataFrame中的行索引作为连接键;
sort: 默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes: 字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(‘_x’, ‘_y’);
copy: 默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator: 显示合并数据中数据的来源情况。
# 例如
left = pd.DataFrame({"id": [1, 2, 3, 4],
"name": ["张三", "李四", "王五", "赵六"],
"grade": [7, 7, 8, 9]})
right = pd.DataFrame({"id": [1, 2, 3, 4],
"name": ["张三", "李四", "王五", "赵六"],
"socre": [80, 86, 84, 90]})
print(left)
print(right)
print("===============================")
result = pd.merge(left, right, how="inner")
print(result)
# 显示
id name grade
0 1 张三 7
1 2 李四 7
2 3 王五 8
3 4 赵六 9
id name socre
0 1 张三 80
1 2 李四 86
2 3 王五 84
3 4 赵六 90
===============================
id name grade socre
0 1 张三 7 80
1 2 李四 7 86
2 3 王五 8 84
3 4 赵六 9 90
# 例如
left = pd.DataFrame({"id1": [1, 2, 3, 4], # id改成id1
"name": ["张三", "李四", "王五", "赵六"],
"grade": [7, 7, 8, 9]})
right = pd.DataFrame({"id2": [1, 2, 3, 4], # id改成id2
"name": ["张三", "李四", "王五", "赵六"],
"socre": [80, 86, 84, 90]})
result = pd.merge(left, right, how="inner")
print(result)
# 显示
id1 name grade id2 socre
0 1 张三 7 1 80
1 2 李四 7 2 86
2 3 王五 8 3 84
3 4 赵六 9 4 90
但是如果name分别改成name1和name2,则会报错,因为默认inner连接,找不到可以连接的键了
可用on参数指定列名连接,列名必须是两个表都有的,如果没有设置,则默认使用共同拥有的相同列名,可以指定多个键值,用列表形式,
inner:默认使用关联键的交集
outer:使用关联键的并集
left:左连接使用左表的key值
right:右连接,使用右表的key值
# 例如
left = pd.DataFrame({"id1": [1, 2, 3, 4],
"name": ["张三1", "李四", "王五", "赵六"],
"grade": [7, 7, 8, 9]})
right = pd.DataFrame({"id2": [1, 2, 3, 4],
"name": ["张三", "李四", "王五", "赵六"],
"socre": [80, 86, 84, 90]})
result = pd.merge(left, right, how="inner")
print(result)
print("===============================")
result2 = pd.merge(left, right, how="outer")
print(result2)
result3 = pd.merge(left, right, how="inner", on="id")
print(result3)
print("===============================")
result4 = pd.merge(left, right, how="inner", on="name")
print(result4)
print("===============================")
result5 = pd.merge(left, right, how="left", on="name")
print(result5)
print("===============================")
result6 = pd.merge(left, right, how="right", on="name")
print(result6)
# 显示
id name grade socre # inner连接方式当“张三”和“张三1”不一致的时候,会少一行
0 2 李四 7 86
1 3 王五 8 84
2 4 赵六 9 90
===============================
id name grade socre # outer连接方式当“张三”和“张三1”不一致的时候,会多一行
0 1 张三1 7.0 NaN
1 2 李四 7.0 86.0
2 3 王五 8.0 84.0
3 4 赵六 9.0 90.0
4 1 张三 NaN 80.0
id name_x grade name_y socre # 指定连接列的话,会发现左表和右表都有
0 1 张三1 7 张三 80
1 2 李四 7 李四 86
2 3 王五 8 王五 84
3 4 赵六 9 赵六 90
===============================
id_x name grade id_y socre # 只保留相同的,
0 2 李四 7 2 86
1 3 王五 8 3 84
2 4 赵六 9 4 90
===============================
id_x name grade id_y socre # 左连接,则不会出现右边的name
0 1 张三1 7 NaN NaN
1 2 李四 7 2.0 86.0
2 3 王五 8 3.0 84.0
3 4 赵六 9 4.0 90.0
===============================
id_x name grade id_y socre # # 右连接,则不会出现左边的name
0 NaN 张三 NaN 1 80
1 2.0 李四 7.0 2 86
2 3.0 王五 8.0 3 84
3 4.0 赵六 9.0 4 90
left_on / right_ on:当两表中两列的列名不一样,但是表达的意思一样的时候,的关联键
# 例如
left = pd.DataFrame({"id": [1, 0, 3, 4],
"name": ["张三1", "李四", "王五", "赵六"],
"grade": [7, 7, 8, 9]})
right = pd.DataFrame({"id": [1, 2, 3, 4],
"par_id":[1, 0, 3, 4],
"name": ["张三", "李四", "王五", "赵六"],
"socre": [80, 86, 84, 90]})
result = pd.merge(left, right, left_on="id", right_on="par_id")
print(result)
# 显示
id_x name_x grade id_y par_id name_y socre
0 1 张三1 7 1 1 张三 80
1 0 李四 7 2 0 李四 86
2 3 王五 8 3 3 王五 84
3 4 赵六 9 4 4 赵六 90
如果是三表联传的话,就需要先将两个连接,然后和第三个表连接
表合并(concat)
concat(objs, axis, join, ignore_index, keys, levels, names, verify_integrity, sort, copy)
objs: 系列或数据框架对象
axis: 连接的axis;默认=0,按照行索引的方向进行拼接,就是纵向上下拼接;axis=1是按照列索引的方向进行拼接,就是横向左右拼接
join: 处理其他axis上的索引的方式;默认=’outer’。
ignore_index: 如果为真,则不使用串联axis上的索引值;默认=假
keys: 序列,为结果索引添加一个标识符;默认 = 无
levels: 构建MultiIndex时使用的特定级别(唯一值);默认=无
names: 所产生的分层索引中的等级名称;默认 = None
verify_integrity: 检查新的串联axis是否包含重复的内容;默认 = False
sort: 当连接为 “外部 “时,如果非连接axis尚未对齐,则对其进行排序;默认 = False
copy: 如果是假的,就不要不必要地复制数据;默认 = True
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]})
b = pd.DataFrame({"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"]})
print(a)
print(b)
print("===============================")
result = pd.concat([a, b], axis=0)
print(result)
print(result.loc[0, "A"])
print("===============================")
result1 = pd.concat([a, b], axis=0, ignore_index=True)
print(result1)
print("===============================")
result2 = pd.concat([a, b], axis=1)
print(result2)
# 显示
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
A B C D
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7
===============================
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7
0 A0
0 A4
Name: A, dtype: object
===============================
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
===============================
A B C D A B C D
0 A0 B0 C0 D0 A4 B4 C4 D4
1 A1 B1 C1 D1 A5 B5 C5 D5
2 A2 B2 C2 D2 A6 B6 C6 D6
3 A3 B3 C3 D3 A7 B7 C7 D7
join:默认outer表示按照索引的并集拼接,inner表示按照索引的交集拼接,该参数对axis=0和axis=1都有用
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]},index=[0,1,2,3])
b = pd.DataFrame({"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"]},index=[1,2,3,4])
result = pd.concat([a, b], axis=1)
print(result)
result2 = pd.concat([a, b], axis=1, join="inner")
print(result2)
result3 = pd.concat([a, b], axis=1, join="inner", ignore_index=True) # 横向拼接的话,忽略列索引
print(result3)
# 显示
A B C D A B C D
0 A0 B0 C0 D0 NaN NaN NaN NaN
1 A1 B1 C1 D1 A4 B4 C4 D4
2 A2 B2 C2 D2 A5 B5 C5 D5
3 A3 B3 C3 D3 A6 B6 C6 D6
4 NaN NaN NaN NaN A7 B7 C7 D7
A B C D A B C D
1 A1 B1 C1 D1 A4 B4 C4 D4
2 A2 B2 C2 D2 A5 B5 C5 D5
3 A3 B3 C3 D3 A6 B6 C6 D6
0 1 2 3 4 5 6 7
1 A1 B1 C1 D1 A4 B4 C4 D4
2 A2 B2 C2 D2 A5 B5 C5 D5
3 A3 B3 C3 D3 A6 B6 C6 D6
两者区别
concat 只是 pandas 下的方法,而 merge 即是 pandas 下的方法,又是DataFrame 下的方法
concat 可以横向、纵向拼接,又起到关联的作用
merge 只能进行关联,也就是纵向拼接
concat 可以同时处理多个数据框DataFrame,而 merge 只能同时处理 2 个数据框
第三节 存储加载
sample
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n: 表示要抽取的行数。
frac: 表示抽取的比例,比如 frac=0.5,代表抽取总体数据的50%。
replace: 布尔值参数,表示是否以有放回抽样的方式进行选择,默认为 False,取出数据后不再放回。replace改为True之后,如果数据上限为4,有放回抽样可以抽取5条甚至更多;但是数据可能重复;
weights 可选参数,代表每个样本的权重值,参数值是字符串或者数组。
random_state 可选参数,控制随机状态,默认为 None,表示随机数据不会重复;若为 1 表示会取得重复数据。
axis 表示在哪个方向上抽取数据(axis=1 表示列/axis=0 表示行)。默认为0
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]}, index=[0, 1, 2, 3])
print(a)
print("===============================")
result = a.sample(n=2)
print(result)
print("===============================")
result1 = a.sample(n=2, random_state=1)
print(result1)
print("===============================")
result2 = a.sample(n=5, replace=True)
print(result2)
print("===============================")
result3 = a.sample(frac=1.5, replace=True)
print(result3)
print("===============================")
result4 = a.sample(frac=0.5, axis=1) # 对列索引采样
print(result4)
# 显示
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
===============================
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
===============================
A B C D
3 A3 B3 C3 D3
2 A2 B2 C2 D2
===============================
A B C D
0 A0 B0 C0 D0
0 A0 B0 C0 D0
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A0 B0 C0 D0
===============================
A B C D
3 A3 B3 C3 D3
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A0 B0 C0 D0
0 A0 B0 C0 D0
2 A2 B2 C2 D2
===============================
D B
0 D0 B0
1 D1 B1
2 D2 B2
3 D3 B3
choice和choices
random.choice()和random.choices()只能对数组序列进行采样,不能对DataFrame进行采样
random.choice(sequence, weights=None, cum_weights=None, k=1)
sequence是必填参数,可以是列表,元组或字符串。
weights权重是用于衡量每个值的可能性的可选参数。
cum_weights是一个可选参数,用于权衡每个值的可能性,但是在这种情况下,可能性被累加。
k是一个可选参数,用于定义返回列表的长度。
shample最终还是用的choice和choices
加载 / 写入文件
用open写入
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]}, index=[0, 1, 2, 3])
with open ("./a.txt", "w", encoding="utf-8") as file:
# file.write(a) # 如果直接写入,会发现,只能写入字符串,不能写入DataFrame
file.write(";".join(a.columns)+"\n")
for i in a.values:
print(i)
file.write(";".join(i)+"\n")
# 显示
A;B;C;D
A0;B0;C0;D0
A1;B1;C1;D1
A2;B2;C2;D2
A3;B3;C3;D3
to_csv写入
一般,文件写成csv格式
csv是轻量型的表格类型,可以用wps打开
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]}, index=[0, 1, 2, 3])
a.to_csv("./a1.txt")
a.to_csv("./a2.txt", index=False, header=False)
a.to_csv("./a3.txt", index=False, header=False,sep=";")
# 显示
,A,B,C,D
0,A0,B0,C0,D0
1,A1,B1,C1,D1
2,A2,B2,C2,D2
3,A3,B3,C3,D3
A0,B0,C0,D0 # 将行标签和列标签都设置为无
A1,B1,C1,D1
A2,B2,C2,D2
A3,B3,C3,D3
A0;B0;C0;D0 # 间隔符设置为;
A1;B1;C1;D1
A2;B2;C2;D2
A3;B3;C3;D3
写成csv格式
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]}, index=[0, 1, 2, 3])
a.to_csv("./a1.csv", index=False, header=False, sep=";")
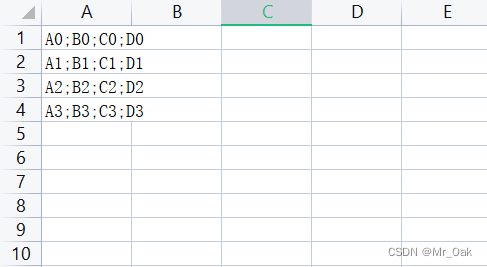
然后用分列,按分号分隔,可以分成四列
加载csv格式的数据
# 例如
b = pd.read_csv("./a.txt")
print(b)
print(type(b))
print(b.shape)
print("===============================")
c = pd.read_csv("./a.txt", sep=";")
print(c)
print(c.shape)
print("===============================")
d = pd.read_csv("./a1.txt", sep=",")
print(d)
print(d.shape)
print("===============================")
e = pd.read_csv("./a1.txt", sep=",", index_col=0)
print(e)
print(e.shape)
print("===============================")
f = pd.read_csv("./a1.csv", sep=";")
print(f)
print(f.shape)
print("===============================")
g = pd.read_csv("./a1.csv", sep=",", header=None, names=["x1", "x2", "x3", "x4"])
print(g)
print(g.shape)
# 显示
A;B;C;D # 直接读取数据
0 A0;B0;C0;D0
1 A1;B1;C1;D1
2 A2;B2;C2;D2
3 A3;B3;C3;D3
<class 'pandas.core.frame.DataFrame'>
(4, 1) # 发现形状是(4, 1)
===============================
A B C D # 用sep把数据分隔开之后
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
(4, 4)
===============================
Unnamed: 0 A B C D # 因为之前是用,号分隔的,所以在A前面有一个,号,在转换的时候自动补了一列,这个时候用index_col可以取消掉行标签
0 0 A0 B0 C0 D0
1 1 A1 B1 C1 D1
2 2 A2 B2 C2 D2
3 3 A3 B3 C3 D3
(4, 5)
===============================
A B C D #取消行标签之后
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
(4, 4)
===============================
A0,B0,C0,D0 # csv文件是没有行标签表头的,但是自动默认第一行是表头
0 A1,B1,C1,D1
1 A2,B2,C2,D2
2 A3,B3,C3,D3
(3, 1)
===============================
x1 x2 x3 x4 # 用header=0,然后用Name将表头重命名之后可以看到,数据恢复原状
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
(4, 4)
to_excel
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]}, index=[0, 1, 2, 3])
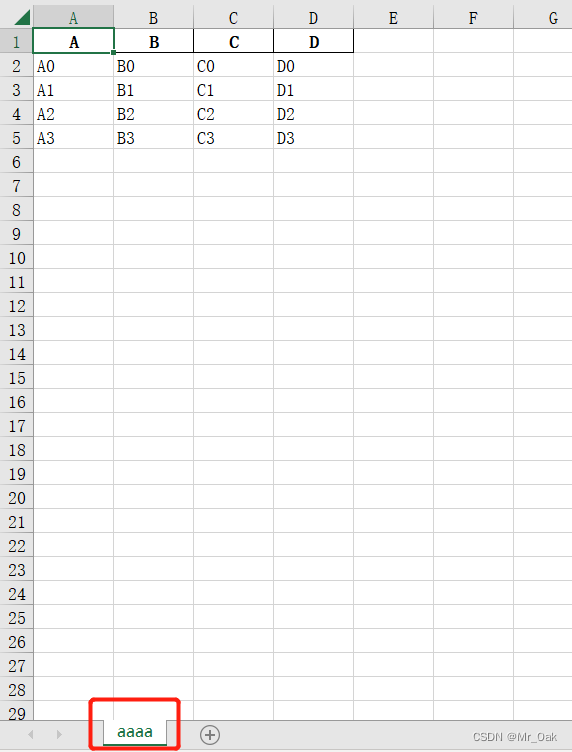
a.to_excel("./a.xlsx")
a.to_excel("./a1.xlsx",index=False, sheet_name="aaaa") # 行索引取消,sheet的名字改成aaaa
a.xlsx

a1.xlsx
read_excel
# 例如
result = pd.read_excel("./a1.xlsx") # 默认加载第一个sheet
print(result)
print("===============================")
result1 = pd.read_excel("./a1.xlsx",sheet_name="bbb") # 选择要加载的sheet
print(result1)
# 显示
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
===============================
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
json
字典转josn用json.dumps
# 例如
dict1 ={"a": "aaa"}
print(type(dict1))
print("===============================")
json01 = json.dumps(dict1)
print(json01)
print(type(json01)) # 类型是字符串,如果写入到文件中,是转成字符串写的
with open("./aaa.json","w",encoding="utf-8") as w:
# w.write(dict1) # 字典是写不进去的,只能转换成json格式写进去
w.write(json01)
# 显示
<class 'dict'>
===============================
{"a": "aaa"}
<class 'str'>
写入结果

json读取
json.load
# 例如
with open("./aaa.json","r",encoding="utf-8") as w:
aa = json.load(w) # 用json,load读取
print(aa)
print(type(aa))
# 显示
{'a': 'aaa'}
<class 'dict'> # 读取到的结果是字典形式
json就是字典对象的存储方式,但是并不是单纯的字典
如果aaa.json修改为

那么读取他
# 例如
with open("./aaa.json","r",encoding="utf-8") as w:
aa = json.load(w)
print(aa)
print(type(aa))
# 显示
[{'a': 'aaa'}, {'b': 'bbb'}]
<class 'list'> # list的结果
to_json / read_json
# 例如
a = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]}, index=[0, 1, 2, 3])
a.to_json("./a.json")
result = pd.read_json("./a.json")
print(result)
print("===============================")
result1 = pd.read_json("./aaa.json") # aaa。json是列表嵌套字典,和创建DataFrame的时候的形式是一样的,所以也能读出来
print(result1)
# 显示
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
===============================
a b
0 aaa NaN
1 NaN bbb