基于飞桨解决交通标识检测与场景匹配问题
点击左上方蓝字关注我们

【飞桨开发者说】张冰洋,北京亮亮视野科技有限公司人工智能架构师,研究方向:人工智能算法在计算机视觉中的应用(如目标检测,人脸识别等)与算法落地部署

在地图数据中,道路交通设施对于缓解交通压力,改善道路通行能力,保障出行用户安全等具有至关重要的作用。如何智能发现现实世界交通设施的变化是一项非常有意义且极具挑战的任务。识别交通标识信息可以向驾驶员或自动驾驶车辆传递重要交通信息,有利于交通安全行驶。因此,智能地对交通数据识别是未来智能驾驶和自动驾驶的趋势所在。
飞桨PaddlePaddle作为一款优秀的国产开源深度学习平台,提供了大量的深度学习模型库,如目标检测开源套件PaddleDetection,图像分类套件PaddleClas,度量学习工具metric learning等,并提供AI开发平台AI Studio,使开发者能够快速高效地开发一个项目。本文基于飞桨PaddlePaddle开源套件和百度开源数据集,解决智能交通中的交通标识检测与场景匹配问题。
任务描述
任务:交通标识检测与场景匹配任务如下图所示,对于同一地点不同时间拍摄的两个图像序列,设计一个交通标志检测与匹配模型,识别出图像中交通标志的类别和位置信息并给出两组序列图像中交通标志的匹配关系。

项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/1281814
数据传送门:
https://aistudio.baidu.com/aistudio/competition/detail/39
评价指标:采用平均F1值(准确率和召回率的调和均值)评估交通标志匹配的效果,平均F1值越高,模型效果越好。
平均F1值:
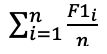
其中,TP 为给出的匹配正确的数量,FP为给出的匹配错误的数量,FN为漏给出的匹配的数量。
匹配正确的要求:
(1)交通标志检测结果与真值的IoU > 0.5,且检测目标类型(type)值一致;
(2)匹配上的2个sign为同一个目标实体。
数据分析
算法需依据数据集的特点和目标问题设计相应模型和配置合理的参数。对数据集的充分理解和深入分析对算法性能提升有至关重要的作用。本部分从检测目标的类别分布、宽高&高宽比、分辨率,和匹配目标的特性等方面对数据集进行分析。
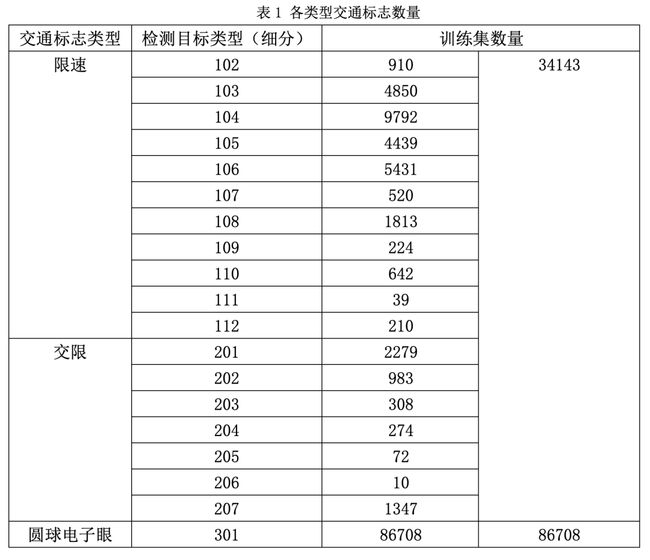
1. 类别数量分布
下图为检测目标的类别,第一行为限速标志,其类别id为102-112;第二行为交限标志,类别id为201-207;第三行为圆球电子眼标志,类别id为301。表1统计了个检测目标类别的数量。由表可知,不同类别的数目差异较大,如果直接使用目标检测算法,数据不平衡会给算法性能带来不利影响。设计合适算法解决类别不平衡问题将是提升算法准确性的关键一环。

2. 宽高&高宽比
检测目标宽高&高宽比最大值的数量分布在1.0-1.5,1.5-2.5和大于2.5区间的目标数量分别为103537,17212和84,宽高比接近于1:1(近似正方形)的目标占总体的大多数。因此,在检测模型参数配置中,锚框(anchor box)的aspect_ratios参数设置应尽可能多地考虑宽高比接近于1:1的数据。

3. 检测目标分辨率
yolov3算法提出了kmeans聚类的anchor计算方式。通过对训练集检测目标boundingbox聚类可以了解交通标识宽高的大致分布,对检测算法的anchor box设计具有指导意义。本部分使用kmeans方法对训练集数据根据检测目标的宽高进行分堆,数据被分为10个堆,如表2所示。其中,w,h是指kmeans分堆的宽高相对于整张图片的大小。为了更直观地了解检测目标分辨率的分布,表2右两列展示了10个分堆相对于1280*720图片取整数后的宽高(数据集图片大部分分辨率为1280*720)。由表可知,小目标占比比较大。可以通过使用较小值的anchor size和使用大分辨率输入提高检测模型准确率。
4. 匹配目标分析
下图匹配对1和2分别为圆球电子眼和限速标志的匹配对,由于图片信息有限,以及光照,模糊等因素的影响,仅凭交通标志本身很难判断两个目标是否匹配。匹配对3和4为上述匹配对加上周围环境后的效果。加上周围环境后,可以通过判断目标周围是否出现相似场景(如相似的交通灯,道路,树木等场景)判断两个目标是否匹配。因此,在目标匹配阶段,考虑进行匹配交通标识本身和周围环境综合匹配,而非仅仅针对交通标识本身做处理。

方法介绍
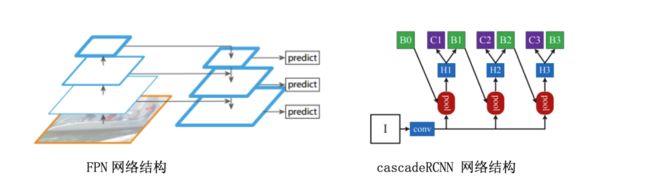
根据第3部分分析及实验,类别不均衡会影响检测算法的性能。限速和交限标志有相似背景,因此在设计目标检测算法时将其归为一类,并将圆球电子眼归为一类,限速交限类别合并后的类别分布如表1右侧所示。通过检测算法获得检测结果后,使用分类算法进一步对限速交限标志的18个类别进行细分类,最后,使用度量学习算法判断两个检测目标是否匹配。整体算法流程为目标检测+限速交限标志细分类+匹配,如下图所示。

1. 目标检测
本部分使用飞桨PaddleDetection套件中CascadeRCNN + FPN算法实现交通交限标志、圆球电子眼两种类别的目标检测。CascadeRCNN通过级联多个检测网络达到不断优化预测结果的目的;FPN通过构建特征金字塔的方式提升网络对多尺度目标尤其是小目标的检测性能。将CascadeRCNN与FPN的特性结合可以实现对不同尺度目标的精确检测。
参数设置:根据“宽高&高宽比”小节得知,大部分数据宽高比接近于1:1(正方形)。通过实验,其余条件不变的情况下,aspect_ratios值设置为[1.0]时算法在验证集上取得最高的map。根据3.3,数据集的检测目标大部分为小目标,提高输入图像的分辨率和设置较小的anchor_sizes值可以使网络尽可能地提高小目标检测准确率。本部分训练输入分辨率为从[640, 672, 704, 736, 768, 800, 832, 864, 896, 928, 960, 992, 1024,1280]中随机选择,anchor_sizes值为[8, 16, 32, 64, 128]。
在训练阶段,batch_size设置为6,使用余弦学习率,将基础学习率设置为0.01并每隔15000 iteration(训练完一轮训练集)更新一次学习率,每隔12000 iteration保存一次模型,总迭代次数为180000。在验证阶段,通过限速交限AP和圆球电子眼AP值选择最佳模型,在iteration = 108000时获得最佳模型。
2. 分类
本部分使用飞桨PaddleClas套件中的ResNet50_vd算法实现限速和交限交通标志分类,并通过对训练数据做形状,颜色变换等数据增强操作增强算法的鲁棒性。
在训练阶段,将训练集的限速交限标志(类别id:102-112,201-207)的检测目标以目标中心点(x+w/2,y+h/2)为中心,size = max(w,h)*2的长度(若长度超出原图片边界则将对应位置填充为0)裁剪图片作为分类任务的训练集。以下图为例,左图限速40标志在图中的左上坐标为(992,368),w=74,h= 64,可计算中心点:(1029,400),max(w,h) = 74,则截取图中左上(955,326)到右下(1103,474)的矩形区域作为一个训练样本。。训练输入图片时,对图片进行随机裁剪,平移操作,并随机对图片做颜色变换(随机光照,亮度,对比度,色相调整),最后对输入进行resize操作将其缩放到固定的尺寸。

在验证和预测阶段,以目标中心点(x+w/2,y+h/2)为中心,size = max(h,w)*1.2的长度从源图片中裁剪的图片作为输入。将size设置为max(h,w)*1.2增加适当的冗余信息以减小目标检测误差带来的影响。
为探索算法在模型轻量化方向的应用,本部分参考PaddleSlim知识蒸馏文档,以ResNet50_vd为教师网络,对轻量网络mobilenet v3蒸馏。以mobilenet v3名为“depthwise_conv2d_11.tmp_0”的变量拟合ResNet50_vd的变量“bn5c_branch2b.output.1.tmp_3”,最终使轻量网络mobilenet v3达到了与resnet50_vd接近的性能。
3. 匹配
本部分使用飞桨度量学习工具metric learning实现交通标识匹配算法,匹配网络以resnet50卷积+池化层+全连接层为骨干网络,后接分类网络以arcmargin作为损失函数训练,获得最终匹配模型。根据3.4的分析,在匹配阶段对目标进行匹配时需考虑目标周围的环境。
本项目实验了两种方案:
A.固定分辨率方案,此方案以固定的分辨率以目标的中心点为中心以固定的分辨率(224*224)将目标从图片中裁剪作为训练集;
B.等比例裁剪方案,以目标的中心为中心,以目标宽高最大值(max(w,h))的固定比例长度(12倍)将目标从原图中裁剪作为训练集。
通过实验,B方案在验证集上取得了较好的结果,所以最终结果采用了B方案。
在训练时,对输入图片进行随机裁剪,颜色变换和旋转等数据增强操作,以增加模型的鲁棒性。在验证和测试阶段,通过判断两个目标骨干网络输出embedding的cosine距离判断两个目标是否匹配。
训练分类网络时,类别映射方式对训练模型的收敛性以及算法的匹配准确率有重要影响。本项目的类别映射方式为:
(1) 对于训练集,如果匹配关系中目标和匹配目标类别不一致,或者匹配到空值,则删除该匹配。
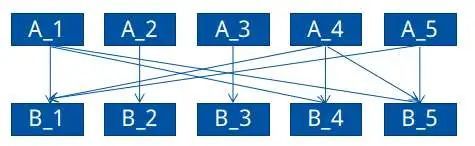
(2)对所有有直接或间接联系的目标,将其分为一类。以训练集json文件17851871183553063989.json为例,如下图所示,目标A_1和B_1匹配(直接匹配),目标A_1,A_4有共同的匹配目标(间接关系),因此上述目标归为一类。以此方法将17851871183553063989.json的检测目标分为3类:A_1,A_4,A_5,B_1,B_4和B_5为一类,A_2和B_2为一类,A_3和B_3为一类。
类别映射流程为:

训练完成后,对于待判断的两个目标,通过计算两个目标embeddiing(骨干网络全连接层输出)的cosine距离判断其是否匹配。
4. 后处理
同一模型,不同阈值可能得到不同的平均F1值结果;在模型训练的不同阶段,获得最佳平均F1值所需的阈值可能差别很大。不恰当的阈值可能导致检测模型准确率上升F1值反而下降的情况。因此,要想尽可能地挖掘算法潜能,需在验证集上通过阈值搜索的方式获得检测,分类和匹配模型的阈值。在匹配阶段,一个检测目标可能匹配到同一张待匹配图片的多个目标,为保证模型的准确率,需对匹配到的多个匹配目标进行去重操作。本部分为后处理部分,首先根据验证集搜索最佳阈值参数,然后对交通标志匹配到B序列一张图片的多个目标去重。
(1)阈值搜索
本部分主要搜索4个阈值:(1).检测阶段限速、交限标志thr_a和圆球电子眼阈值thr_b;(2).分类阶段分类阈值thr_c;(3).匹配阶段cosine距离thr_d,在验证集上搜索到获得最高f1 score时的4个阈值,将其应用于测试集。搜索方式为:将所有上述阈值大于0.3的结果保存,并采用循环搜索的方式对thr_a,thr_b,thr_c和thr_d搜索其在0.3-0.7的范围内每隔0.01计算一次平均F1值结果并保留最佳结果。
(2)去重
如果A序列的交通标志匹配到B序列一张图片的多个目标,则只保留B序列中cosine距离最大的目标。
提交结果时,根据阈值搜索得到的值,在目标检测阶段,保留限速、交限标志score大于thr_a,圆球电子眼score大于thr_b的目标;在分类阶段,对限速、交限标志细分类,并舍去分类score小于thr_c的目标;在匹配阶段,对A,B序列中相同类别的目标根据cosine判断其是否匹配,若目标无匹配则将其匹配空值;阈值大于thr_d算做一对匹配,经过去重处理,然后提交最终结果。
结果分析
在目标检测阶段,本文实验不同输入分辨率对目标检测结果的影响,随着分辨率的提高,模型的检测性能会有不同程度的提升,多分辨率融合可进一步提升检测算法的性能。

使用ResNet50_vd算法对限速交限标志分类在验证集准确率为98.01%。本文实验了小模型和模型蒸馏对分类准确率的影响,如下表所示。由表可知,使用模型蒸馏算法以Resnet50_vd为教师网络对轻量网络mobilenet v3蒸馏,可以提升小模型的分类性能。

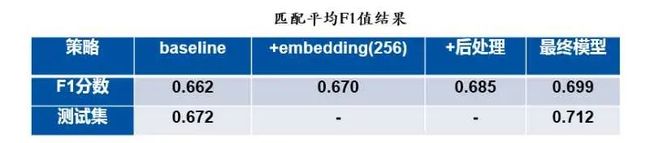
下表为不同程度优化策略在验证集和测试集获得的结果。Baseline检测模型输入分辨率为1920*1080,匹配算法以resnet50卷积+池化层作为骨干网络并采用4.3提到的A策略。在后续优化中,对匹配网络增加embedding(全连接层)和使用后处理方法对匹配性能均有一定的提升。最终模型将A策略改为B策略,将embedding的维度从256维升为512,对匹配时cosine距离阈值进行更加精细的搜索(从百分位变为千分位),并使用模型融合方法,在验证集和测试集均取得最高的平均F1值,达到最佳匹配性能。
代码运行
训练平台:AI Studio
开源工具:
PaddleDetection
https://github.com/PaddlePaddle/PaddleDetection
PaddleClas
https://github.com/PaddlePaddle/PaddleClas
metric learning
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/metric_learning
项目源码:
源码网址:http://pan.baidu.com/s/1fkpMmrR-6DJBCN1bf-oNCQ 提取码:vnfr,下载源码解压后将其解压至AI Studio的work文件夹下。
数据集处理:
数据集制作的流程为:拆分训练集验证集,制作目标检测,分类和匹配数据。
将训练初赛和复赛训练集图片拷贝至trainval文件夹,json标签拷贝至train_label,复赛测试集拷贝至test目录,完成后datasets目录应包含如下目录:

datasets/traffic下包含了目标检测,分类,匹配的数据集制作代码。
(1)数据集划分
将11178个json文件分为10000个训练集和1178个验证集,分别保存于
work/datasets/traffic/trainval/train.txt
和work/datasets/traffic/trainval/val.txt
源码:
cd ~/work/datasets/traffic
python split_train_val.py
(2)目标检测,分类和匹配数据集制作
#目标检测数据集
cd ~/work/datasets/traffic
python make_detection_labels.py
cd detection
python convert_to_voc.py
#分类数据集
cd work/datasets/traffic/classify
python make_dataset_train.py
python make_dataset_eval.py
python generate_cls_labels.py
#匹配数据集
cd work/datasets/traffic/match
python get_train_json.py
python get_val_json.py
模型训练:
#检测算法
cd ~/work/PaddleDetection
!sh train_rcnn_enhance.sh
#分类
%cd ~/work/PaddleClas
!sh train.sh
#匹配
%cd ~/work/metric_learning
!python train_elem.py
获得测试结果:
#获得检测结果
%cd ~/work/PaddleDetection
#多尺度
python tools/infer_1280.py -c configs/rcnn_enhance/cascade_rcnn_dcn_r50_vd_fpn_3x_server_side_1280.yml -o weights=output/cascade_rcnn_dcn_r50_vd_fpn_3x_server_side/108000.pdparams --infer_dir=../datasets/test/pic --output_dir=output
python tools/infer_640.py -c configs/rcnn_enhance/cascade_rcnn_dcn_r50_vd_fpn_3x_server_side_640.yml -o weights=output/cascade_rcnn_dcn_r50_vd_fpn_3x_server_side/108000.pdparams --infer_dir=../datasets/test/pic --output_dir=output
cd output
rm results/*.json
python multi_scale_fusion.py
python make_json_file.py
#单尺度1080
#python tools/infer.py -c configs/rcnn_enhance/cascade_rcnn_dcn_r50_vd_fpn_3x_server_side.yml
# -o weights=output/cascade_rcnn_dcn_r50_vd_fpn_3x_server_side/108000.pdparams --infer_dir=../datasets/test/pic --output_dir=output
#cd output
#python make_json_file.py
#分类每个epoch结束会输出其在验证集上的准确率,选择在验证集上准确率最高的模型用于测试集预测
cd ~/work/PaddleClas/output
make_cls_data.py
cd ..
sh test.sh
cd output
python make_results.py
#metric learning
cd ~/work/metric_learning_traffic
python test.py
#后处理
后处理在f1_score文件夹下生成的result即为最终结果
%cd ~/work/f1_score
!cp ../metric_learning_traffic/output/result/*.json result_org/
!python del_repeat.py
!python f1_score.py
小结
本文基于飞桨深度学习套件和AI Studio训练平台,使用目标检测+交通标志细分类+匹配的方案解决交通标识检测和场景匹配问题。在目标检测时,将限速和交限标志合为一类以减少数据不平衡带来的影响;在匹配阶段,通过合适的训练数据集制作方案和训练类别映射策略提高匹配模型性能,最后通过后处理策略进一步提升模型性能,最终形成本文所述的交通标识检测与场景匹配解决方案。
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨PaddleClass套件地址·
GitHub:
https://github.com/PaddlePaddle/PaddleClass
Gitee:
https://Gitee.com/PaddlePaddle/PaddleClass
·飞桨PaddleDetection地址·
GitHub:
https://github.com/PaddlePaddle/PaddleDetection
Gitee:
https://Gitee.com/PaddlePaddle/PaddleDetection

微信号 : PaddleOpenSource
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。